本文主要是介绍欧科云链:比特币现货ETF后时代,链上数据揭示真实供需关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

出品|欧科云链研究院
作者|Hedy Bi
本文于3月11日首发TechFlow深潮,原标题为《比特币现货ETF通过后的2个月:链上数据揭示BTC供不应求》。
文中观点纯属笔者基于链上数据进行分析,不构成对任何潜在投资目标的推荐或意见,亦不得视为投资建议。
3月伊始,美联储(FED)推出了半年度货币政策报告。随着市场对6月份降息的预期上升,黄金价格达到了2024年的最高水平。仅隔一天,BTC也创下了市值新高。比特币现货ETF通过后可以被视为一个分水岭,时隔两月,金融的推手正加速加密市场的成熟,也让这个市场更加复杂。
然而,作为反映市场真实情况的“诚实”指标,链上数据显示投资者的两极化趋势日益显现。正如欧科云链研究院在前文《》所说“新市场蓄势待发,原有市场更坚定”。本文结合OKLink、CryptoQuant和Glassnode三方链上数据从BTC的供需和市场分布的角度浅析BTC市场:
一、从链上数据分析BTC供需现状
从供给端来看,截至发文时间根据CryptoQuant数据统计显示,目前有超过30家中心化交易平台的BTC持仓处于流出状态,总额高达约71,934BTC。
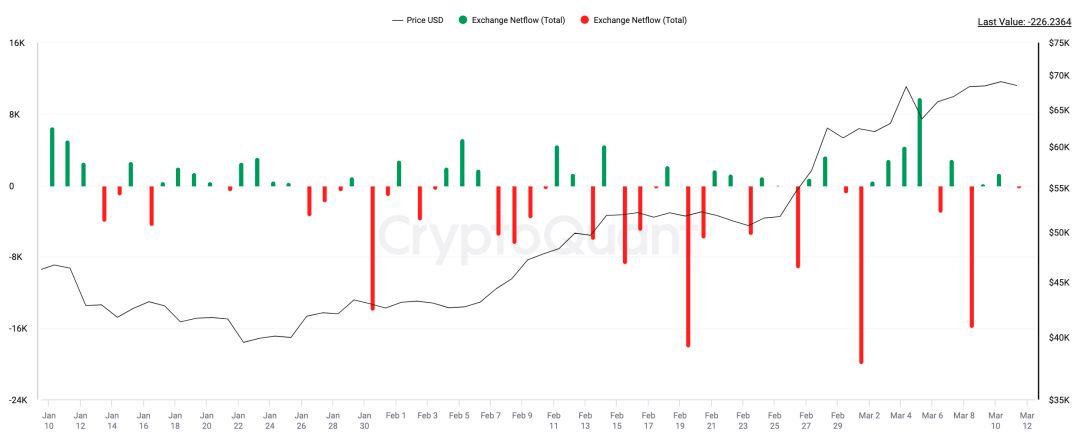 图 自2024年1月11日至今(3月10日完整数据)中心化交易平台BTC净流入/流出(单位:BTC)
图 自2024年1月11日至今(3月10日完整数据)中心化交易平台BTC净流入/流出(单位:BTC)
数据来源:CryptoQuant
此外,我们也可以看到矿工在持续抛售,原因主要是赶在下一次减半前进行清算。下一次挖矿减半会变成挖矿奖励从6.25BTC降至3.125BTC。截至发文时间,与加密货币矿工绑定的钱包计算得出在ETF通过至今这段期间内,地址上BTC净外流约8,530枚BTC。也就是说从交易所以及矿工两大供应端减少的BTC大概是80,464枚BTC。这里,我们已经用净外流的数量进行计算,因为净外流数据是包含矿工本身对囤币的需求和实际挖出BTC的差值。
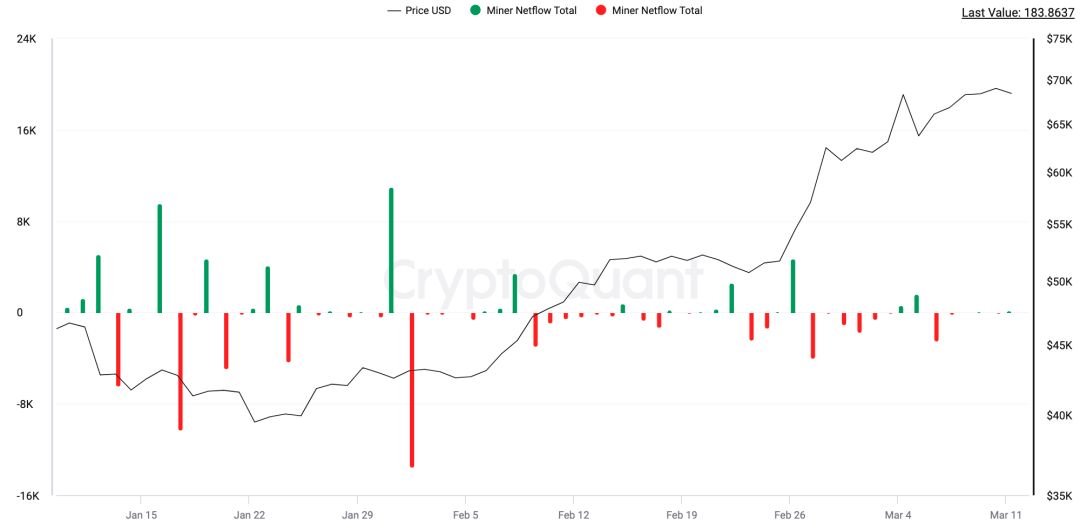
图 自2024年1月11日至今矿工钱包地址BTC净流入/流出(单位:BTC)
数据来源:CryptoQuant
在需求端,尽管市场上一直在讨论灰度不断抛售BTC的情况,由于各个数据来源的统计会有偏差以及各机构更新现货ETF的时间有所偏差,这里根据CryptoQuant以及Farside数据综合测算,通过BTC现货ETF这一渠道进入市场的资金规模累计已达到95.94亿美元,与BTC现货ETF被允许交易时相比,截至当地收盘时间3月8日净流入总量约为176,396枚BTC。仅BTC现货ETF一个通道,就让BTC在市场上达到了供不应求的状态,缺口目前来看达到了9.5万多枚BTC。然而,真正的BTC供给源头是矿工。尽管存在其他渠道如交易所的BTC流出,但这并非可持续的供给来源。
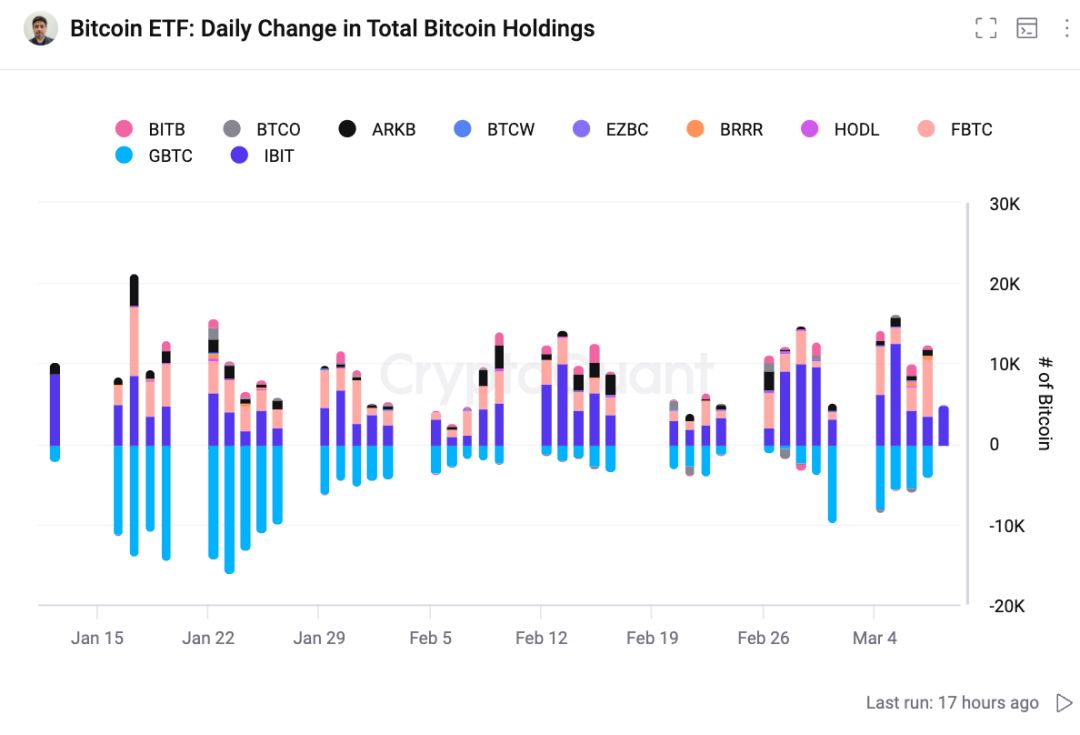 图 自2024年1月11日至今Bitcoin Spot ETF净流入/流出(单位:BTC)
图 自2024年1月11日至今Bitcoin Spot ETF净流入/流出(单位:BTC)
数据来源:CryptoQuant
而在约40天之后,BTC减半会让新产生的供应量减半。按照BTC的设定:每产生210,000个区块后奖励将减半一次,直至2140年出块奖励为0,所有BTC发行完毕,最终发行总量恒定为2100万枚。
并且与以往减半还有所不同,BTC生态系统内出现了一项开创性创新——铭文,据Dune链上数据统计,目前来自这一创新贡献给BTC生态的费用已经达到了6,290BTC,为矿工贡献了一部分收益。未来,随着BTC生态的创新应用的发展以及L2解决拓展性,矿工的收入也会增加,这也减缓了矿工为了挖矿成本不得不抛售BTC的实际压力,也就意味着供应端的情况与前几次减半还不同,抛售给市场的压力减小,矿工更愿意囤币,而不是拿出去对市场进行“供应”。

图 3月11日中午12点BTC减半一览图
数据来源:OKLink
二、BTC市场分布:转移至链上
如果我们假设新的投资者大部分是因BTC现货ETF而进入这个市场,那链上非零地址便可默认是以老投资者为主。根据OKLink数据,链上非零地址数显示出了一个明显上升的趋势,这意味着存储资产的地址数量在增加,而不仅仅是出于增加地址互动而新增的地址,也由此可以看出BTC转移的迹象。
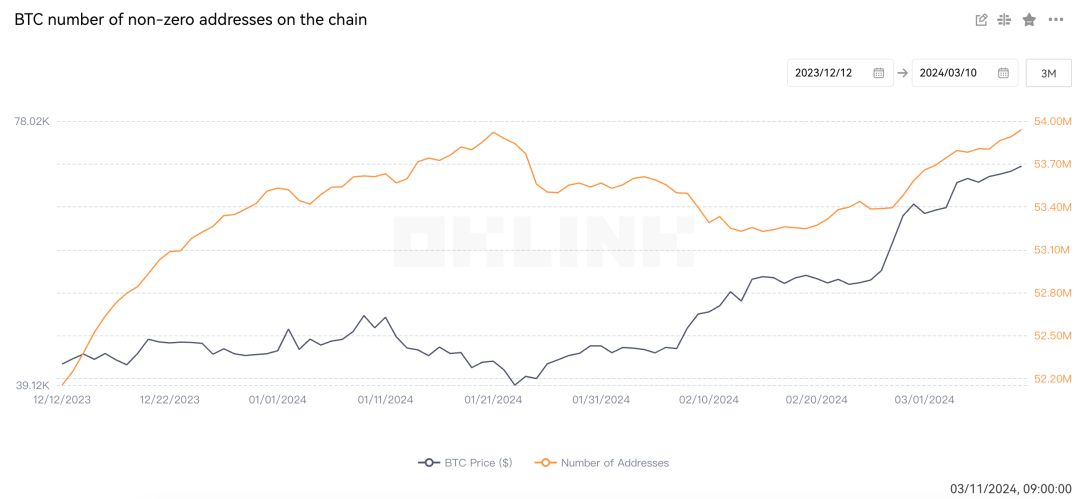
图 近3个月BTC非零资产的钱包地址数
数据来源:OKLink
更细致和具体的资产移动情况也可去区块链浏览器上查看实时动态以及大额转账。从OKLink数据可以看出,BTC在近几日的大额转账的出现频率也在增多。

图 BTC区块链浏览器大额资产转账
数据来源:OKLink
据Glassnode统计,转移到这种长期存储中的BTC数量正以每季度18万枚BTC的速度增加,是正在开采的新BTC数量的两倍。这种将BTC作为长期投资的转变进一步收紧了BTC的供应,并可能在减半临近时加强BTC的价格基础。
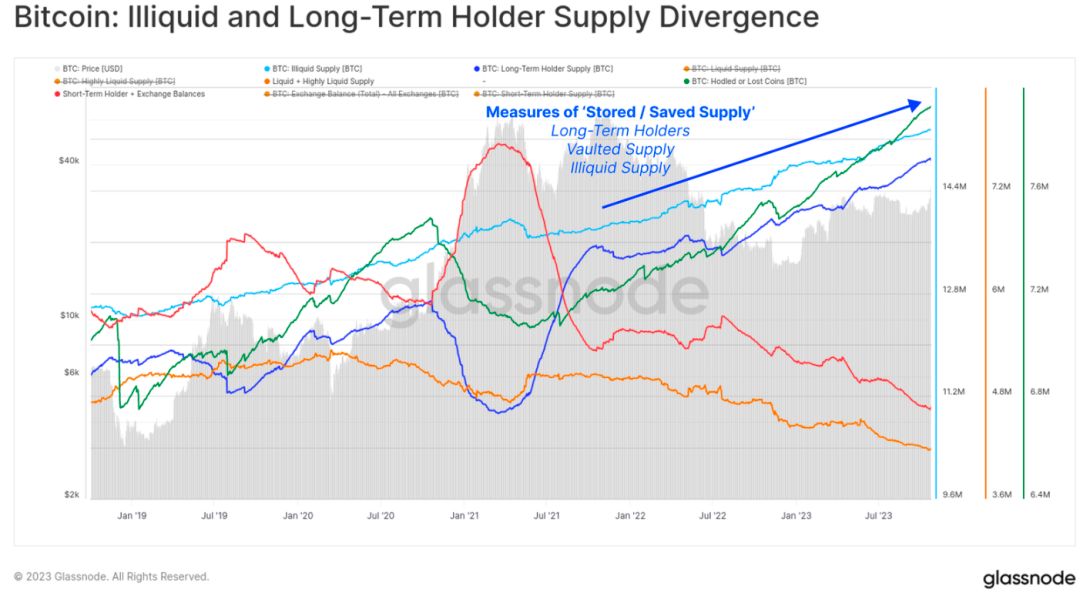
图 非流动性和长期持有者的供应分歧
数据来源:Glassnode
长期持有者转到链上无论从地址数还是从资金量两方来看均呈现一个扩大趋势。根据Glassnode近期报告称,用于长期投资的BTC锁定率已经超过了新增供应量的200%以上。这意味着,尽管新的BTC仍在不断被开采出来,但更多的BTC被投资者持有,而不是出售或交易。
三、VS黄金ETF?还看稀缺性
除了链上数据显示BTC目前处于一个供不应求的状态且BTC的稀缺性也让这一趋势持续。不同于法定货币供应依赖于中央银行和黄金在内的贵金属资产的供应受自然的限制,BTC的发行速度以及2100万的总供应量自其诞生以来就由其基础协议规定。
谈到稀缺性,就不得不提黄金。经常被用于与BTC进行类比的黄金,也因其开采成本高、自然资源有限等特点而被视为“供不应求”的资产。特别是在应对通胀和战乱等情况下,其稀缺性优点更加凸显,也因此会被称为恐惧交易的一个典范。也因此,黄金市场的历史表现也经常被用于对比BTC市场进行分析。
在ETF的表现上,自2004年第一支黄金现货ETF获批以来,黄金价格持续上升,不到10年时间涨幅达到了346%。然而,黄金花费了相当长的时间才被广泛认可。相比之下,BTC自诞生到2024年现货ETF通过仅用了15年时间。尽管市场持续升温,但我们需要考虑的是黄金在金融领域有着重要的历史地位。1717年,英国首次采用金本位制度,将黄金纳入货币体系的重要组成部分。
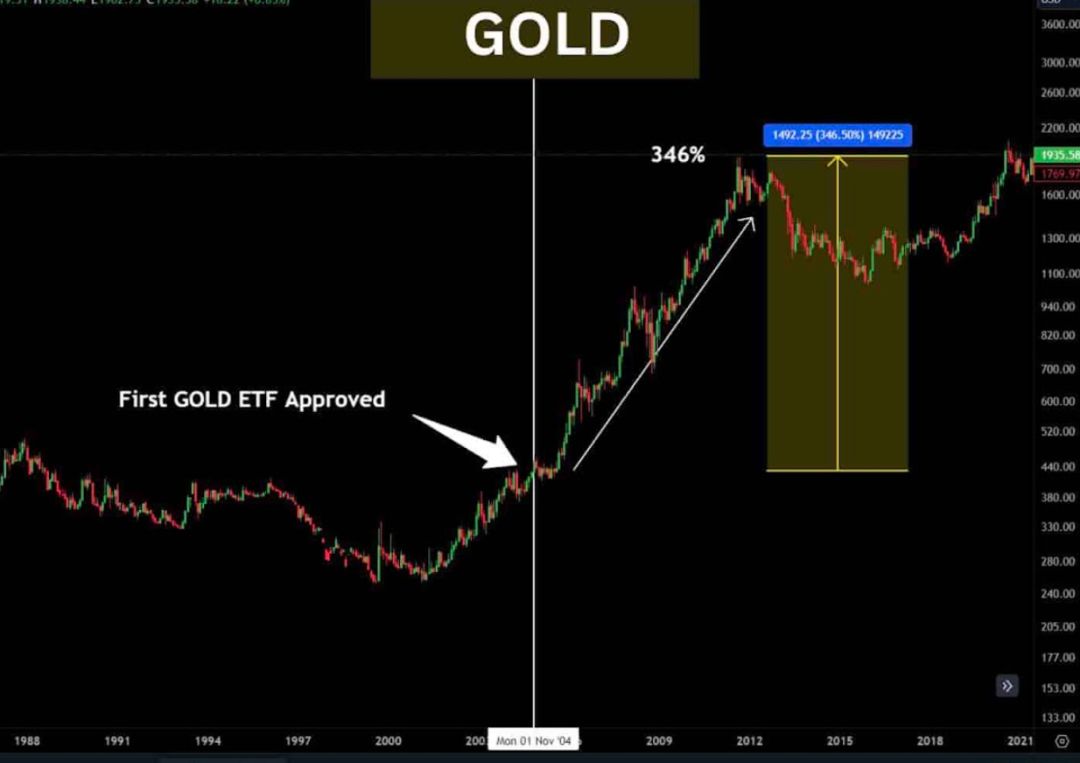
图 黄金在现货ETF前后对比
数据来源:Ash Crypto
在探讨BTC作为“数字黄金”的独特性时,除了其物质稀缺性外,其在金融系统中的独特性也值得关注。BTC的去中心化设计使其在传统金融体系之外可被持有,同时也为数十亿没有银行账户的人提供了进入全球金融系统的机会。
随着BTC市场的发展,BTC去中心化的特性使得参与者多元化,并与传统金融市场的关联日益加深。市场的复杂性与数据的获取之间存在密切关系。在这种背景下,链上数据的分析和获取相对于传统金融市场的数据信息更加便捷。链上数据来源于全球各地的节点网络,具有公开账本的特性,使得任何人都能实时进行市场分析和统计,无需依赖中心化机构。这种去中心化特性带来了数据的透明性、公正性,并且能够有效避免单点故障和篡改的风险。
在日益成熟且复杂的加密市场中,好在对于链上数据的分析和获取相比于其他金融市场的数据信息来说已然更触手可得。市场越复杂,链上数据优势越明显。链上数据因其独特性将会成为我们最为接近市场真相的独特存在。
这篇关于欧科云链:比特币现货ETF后时代,链上数据揭示真实供需关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






