本文主要是介绍伯特斯卡斯_google ai嵌入的实验室语言不可知伯特句子,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
伯特斯卡斯
Multilingual Embedding Models are the ones that map text from multiple languages to a shared vector space (or embedding space). This implies that in this embedding space, related or similar words will lie closer to each other, and unrelated words will be distant (refer to the figure above).
多语言嵌入模型是将多种语言的文本映射到共享向量空间(或嵌入空间)的模型。 这意味着在这个嵌入空间中, 相关或相似的词将彼此靠近 ,而无关的词将变得遥远 (请参见上图)。
In this article, we will discuss LaBSE: Language-Agnostic BERT Sentence Embedding, recently proposed in Feng et. al. which is the state of the art in Sentence Embedding.
在这篇文章中,我们将讨论LaBSE:L anguage- 诺斯替乙 ERT 小号 entenceēmbedding,最近提出了Feng等。 等 这是Sentence Embedding中最先进的技术。
现有方法 (Existing Approaches)
The existing approaches mostly involve training the model on a large amount of parallel data. Models like LASER: Language-Agnostic SEntence Representations and m-USE: Multilingual Universal Sentence Encoder essentially map parallel sentences directly from one language to another to obtain the embeddings. They perform pretty well across a number of languages. However, they do not perform as good as dedicated bilingual modeling approaches such as Translation Ranking (which we are about to discuss). Moreover, due to limited training data (especially for low-resource languages) and limited model capacity, these models cease to support more languages.
现有的方法主要涉及在大量并行数据上训练模型。 模型,如LASER:L anguage- 诺斯替SE ntenceř对产权和M-USE:M ultilingualùniversal 小号 entenceËncoder基本上平行映射句子直接从一种语言到另获得的嵌入。 它们在多种语言中的表现都很好。 但是,它们的性能不如专用的双语建模方法(例如, 翻译排名 (我们将要讨论))好。 此外,由于训练数据有限(特别是对于资源匮乏的语言)和模型能力有限,这些模型不再支持更多的语言 。
Recent advances in NLP suggest training a language model on a masked language modeling (MLM) or a similar pre-training objective and then fine-tuning it on downstream tasks. Models like XLM are extended on the MLM objective, but on a cross-lingual setting. These work great on the downstream tasks but produce poor sentence-level embeddings due to the lack of a sentence-level objective.
NLP的最新进展表明,在掩盖语言建模(MLM)或类似的预训练目标上训练语言模型,然后在下游任务上对其进行微调。 像XLM这样的模型是在MLM目标上扩展的,但是是在跨语言环境下进行的。 这些在下游任务上效果很好,但是由于缺少句子级目标而产生的句子级嵌入效果很差 。
Rather, the production of sentence embeddings from MLMs must be learned via fine-tuning, similar to other downstream tasks.
而是,必须通过微调来学习来自传销的句子嵌入的产生,这与其他下游任务类似。
— LaBSE Paper
— LaBSE纸
与语言无关的BERT句子嵌入 (Language-Agnostic BERT Sentence Embedding)
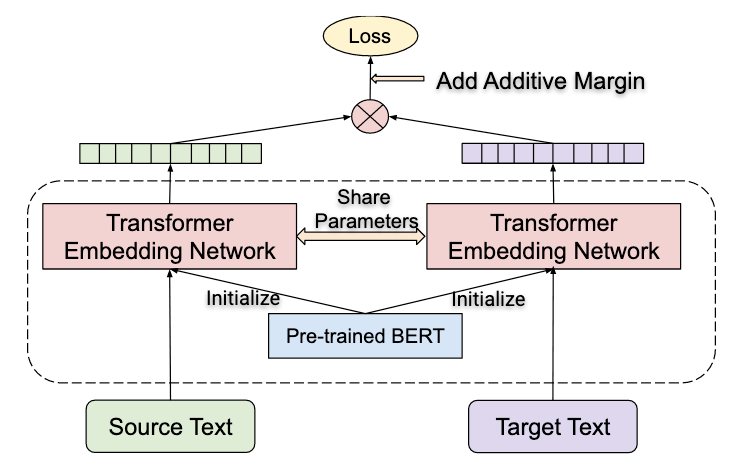
The proposed architecture is based on a Bidirectional Dual-Encoder (Guo et. al.) with Additive Margin Softmax (Yang et al.) with improvements. In the next few sub-sections we will decode the model in-depth:
所提出的体系结构是基于双向双编码器 (Guo等人 )和具有改进的加性余量Softmax( Yang等人 )的 。 在接下来的几个小节中,我们将对模型进行深入解码:
翻译排名任务 (Translation Ranking Task)

First things first, Guo et. al. uses a translation ranking task which essentially ranks all the target sentences in order of their compatibility with the source. This is usually not ‘all’ the sentences but some ‘K - 1’ sentences. The objective is to maximize the compatibility between the source sentence and its real translation and minimize it with others (negative sampling).
首先, 郭等。 等 使用翻译排序任务,该任务从本质上排序所有目标句子与源句子的兼容性 。 这通常不是“全部”句子,而是一些“ K-1 ”句子。 目的是最大程度地提高源句子与其实际翻译之间的兼容性,并使其与其他 句子 ( 负采样 ) 的兼容性 最小化 。
双向双编码器 (Bidirectional Dual Encoder)
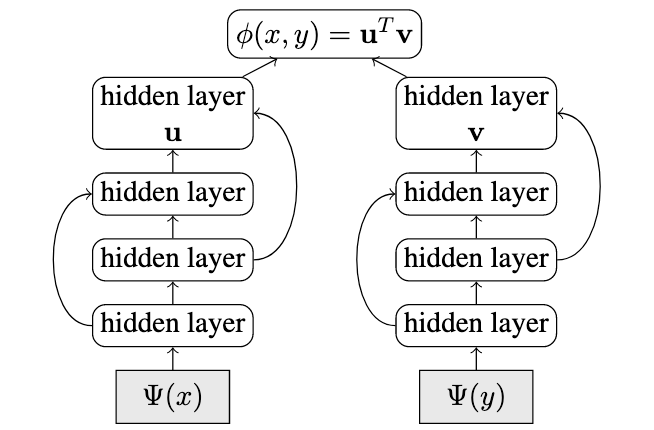
The dual-encoder architecture essentially uses parallel encoders to encode two sequences and then obtain a compatibility score between both the encodings using a dot-product. The model in Guo et. al. was essentially trained on a parallel corpus for the translation ranking task which was discussed in the previous section.
双编码器体系结构本质上使用并行编码器对两个序列进行编码,然后使用点积获得两种编码之间的兼容性得分 。 郭等人的模型。 等 基本上在并行语料库上接受了翻译排名任务的培训,这已在上一节中进行了讨论。
As far as ‘bidirectional’ is concerned; it basically takes the compatibility scores in both the ‘directions’, i.e. from source to target as well as from target to source. For example, if the compatibility from source x to target y is denoted by ɸ(x_i, y_i), then the score ɸ(y_i, x_i) is also taken into account and the individual losses are summed.
就“双向”而言; 它基本上在两个“方向”上取得兼容性评分,即从源到目标以及从目标到源 。 例如,如果从源x到目标y的兼容性 用ɸ(x_i,y_i)表示 ,然后得分ɸ(y_i,x_i) 还考虑了损失,并对各个损失进行了求和。
Loss = L + L′
损失= L + L'
附加保证金Softmax(AMS) (Additive Margin Softmax (AMS))
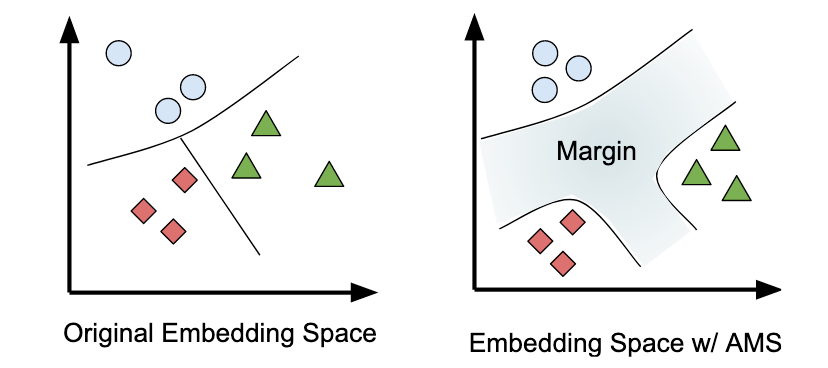
In vector spaces, classification boundaries can be pretty narrow, hence it can be difficult to separate the vectors. AMS suggests introducing a parameter m in the original softmax loss to increase the separability between the vectors.
在向量空间中,分类边界可能非常狭窄,因此可能难以分离向量 。 AMS建议引入参数m 原始softmax损失会增加向量之间的可分离性。
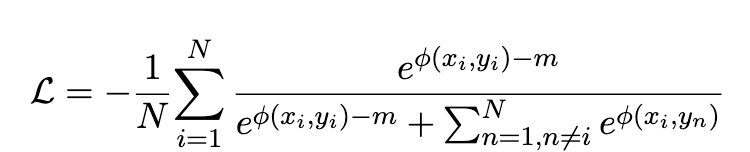
Notice how the parameter m is subtracted just from the positive sample and not the negative ones which is responsible for the classification boundary.
注意如何仅从正样本中减去参数m ,而不从负样本中减去负参数m ,这是分类边界的原因。
You can refer to this blog if you’re interested in getting a better understanding of AMS.
如果您有兴趣更好地了解AMS,可以参考此博客 。
跨加速器负采样 (Cross-Accelerator Negative Sampling)
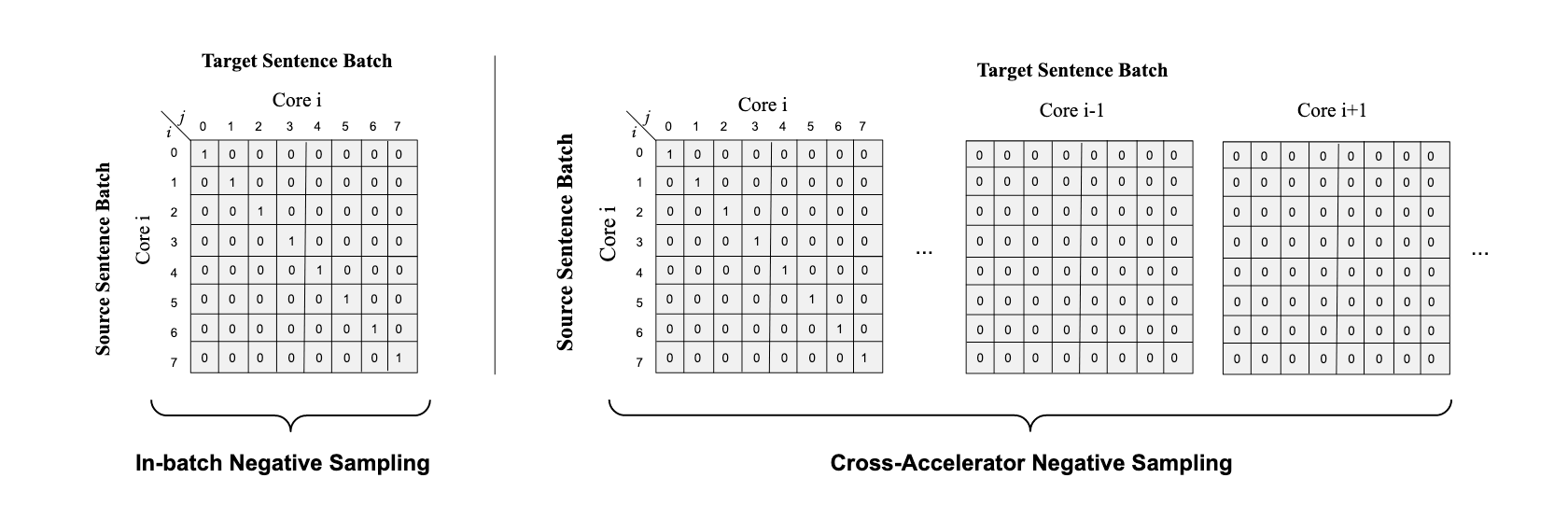
The translation ranking task suggests using negative sampling for ‘K - 1’ other sentences that aren’t potentially compatible translations of the source sentence. This is usually done by taking sentences from the rest of the batch. This in-batch negative sampling is depicted in the above figure (left). However, LaBSE leverages BERT as its encoder network. For heavy networks like these, it is infeasible to have batch sizes that are large enough to provide sufficient negative samples for training. Thus, the proposed approach leverages distributed training methods to share batches across different accelerators (GPUs) and broadcasting them in the end. Here, all the shared batches are considered as negative samples, and just the sentences in the local batch are considered for positive sampling. This is depicted in the above figure (right).
翻译排名任务建议对“ K-1 ”其他与源句潜在不兼容的译文使用否定采样。 这通常是通过从其余部分中提取句子来完成的。 上图( 左 )显示了批生产中的负采样。 但是,LaBSE利用BERT作为其编码器网络。 对于此类繁重的网络,批量大小足够大以提供足够的阴性样本进行训练是不可行的。 因此,提出的方法利用分布式训练方法在不同的加速器(GPU)之间共享批次并最终广播它们 。 在这里,所有共享批次都被视为否定样本,而仅将本地批次中的句子视为正样本。 上图( 右 )对此进行了描述。
预训练和参数共享 (Pre-Training and Parameter Sharing)
Finally, as mentioned earlier, the proposed architecture uses BERT encoders and are pretrained on Masked Language Model (MLM) as in Devlin et. al. and Translation Language Model (TLM) objective as in XLM (Conneau and Lample). Moreover, these are trained using a 3-stage progressive stacking algorithm i.e. an L layered encoder is first trained for L / 4 layers, then L / 2 layers and then finally L layers.
最后,如前所述,所提出的体系结构使用BERT编码器,并且像Devlin等人在Masked Language Model(MLM)上进行了预训练。 人 。 和XLM(Conneau和Lample)中的翻译语言模型(TLM)目标。 此外,使用三阶段渐进式堆栈算法对这些层进行训练,即首先对L层编码器进行L / 4层,然后L / 2层,最后L层的训练。
For more on BERT pre-training, you can refer to my blog.
有关BERT预培训的更多信息,请参阅我的博客 。
放在一起 (Putting it All Together)
LaBSE,
LaBSE,
- combines all the existing approaches i.e. pre-training and fine-tuning strategies with bidirectional dual-encoder translation ranking model. 结合了所有现有方法,即预训练和微调策略与双向双编码器翻译排名模型。
- is a massive model and supports 109 languages. 是一个大型模型,支持109种语言。
结果 (Results)

LaBSE clearly outperforms its competitors with a state of the art average accuracy of 83.7% on all languages.
LaBSE在所有语言上的平均准确度均达到83.7%,明显优于竞争对手。
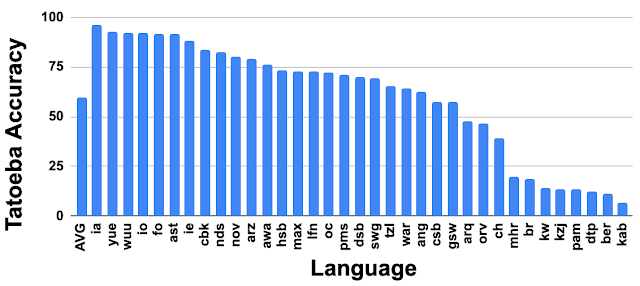
LaBSE was also able to produce decent results on the languages for which training data was not available (zero-shot).
LaBSE还能够在没有培训数据的语言(零射)上产生不错的成绩。
Fun Fact: The model uses a 500k vocabulary size to support 109 languages and provides cross-lingual support for even zero-shot cases.
有趣的事实:该模型使用500k的词汇量来支持109种语言,甚至为零击案例提供了跨语言支持。
结论 (Conclusion)
We discussed the Language-Agnostic BERT Sentence Embedding model and how pre-training approaches can be incorporated to obtain the state of the art sentence embeddings.
我们讨论了语言不可知的BERT句子嵌入模型,以及如何结合预训练方法来获取最新的句子嵌入状态。
The model is open-sourced at TFHub here.
该模型在TFHub开源 。
翻译自: https://towardsdatascience.com/labse-language-agnostic-bert-sentence-embedding-by-google-ai-531f677d775f
伯特斯卡斯
相关文章:
这篇关于伯特斯卡斯_google ai嵌入的实验室语言不可知伯特句子的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



