本文主要是介绍读取txt文件并统计每行最长的单词以及长度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
读取txt文件并统计每行最长的单词以及长度
题目
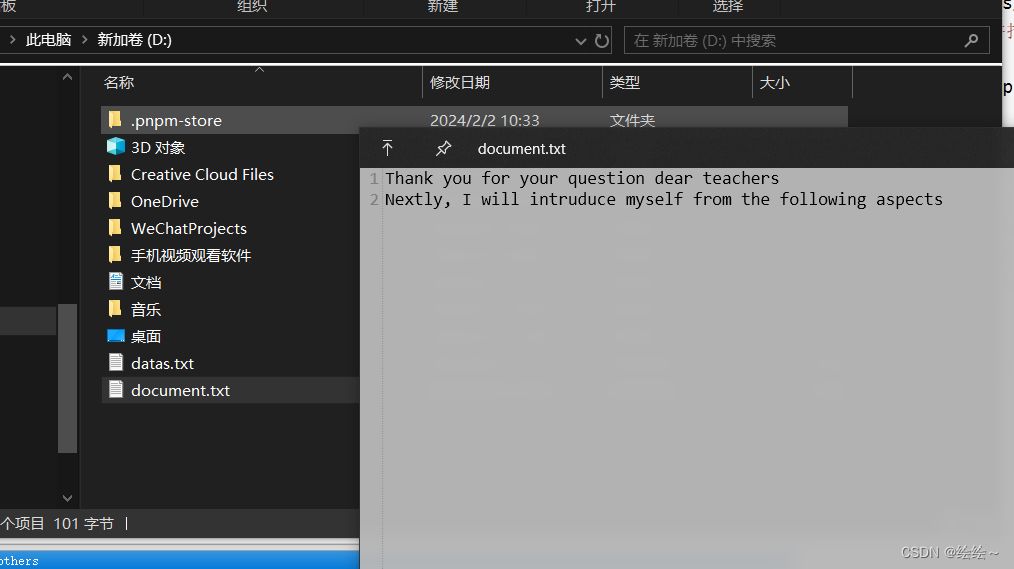
在 D:\\documant.txt 文本中,文件中有若干行英文文本,每行英文文本中有若干个单词,每个单词不会跨行出现每行至多包含100个字符,要求编写一个程序,处理文件,分析各行中的单词,找到每行中的最长单词,分别输出其长度。如:dictionary—>10。
思路
其实我本人对这类读取文件的题目接触时比较少的,所以记录一下解题流程
现在我是使用C++来进行程序设计,C++里面关于文件读取有一个库为ifstream
调用即可生成对应读取文件的可操作对象,之后判断文件是否打开成功;
对于读取每行,可以写在while循环的条件中,之后使用 stringstream
将读取到的行字符串变成流的形式,然后用一个字符串类型的word循环接受其中的单词,
流的形式可以天然进行空格分隔,这也是方便之处
参考代码
#include<bits/stdc++.h>using namespace std;int main() {ifstream input_file("D:\\document.txt");if(!input_file.is_open())cerr << "文件打开失败" << endl;string line;while(getline(input_file, line)) {stringstream iss(line);string word, res;int max_len = 0;while(iss >> word) {if(word.length() > max_len) {res = word;max_len = word.length();}}cout << res << "--->" << max_len << endl;}return 0;
}
结果测试
文件内容
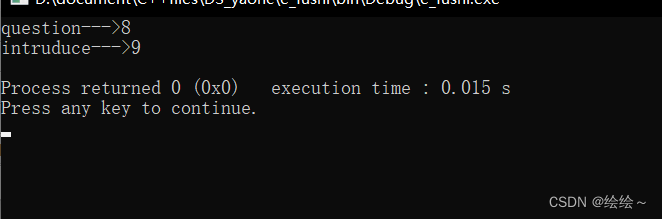
运行结果
最后保留节目:没有其他目的,只是为了身心愉悦

这篇关于读取txt文件并统计每行最长的单词以及长度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






