本文主要是介绍从根到叶:深入了解Map和Set,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
窗间映出一片高远的天空,
向晚的天际宁静而又清明。
我孤独的心灵在幸福地哭泣,
它在为天空如此美好而高兴。
恬静的晚霞一片火红,
晚霞灼烧着我的热情。
此刻的世界没有别人,
只有上帝,我和天空。
——(俄)吉皮乌斯《瞬间》

一.概念及场景
Map和Set是两种常见的数据结构,用于在编程中组织和存储数据。它们通常在不同的场景中使用,具有不同的特点和用途。
1.Map(映射)是一种将键(key)与值(value)相关联的数据结构。它提供了一种通过键快速查找值的方式。在Map中,每个键是唯一的,而值可以重复。
Map的场景:
- 数据索引和快速查找:Map允许通过键快速查找对应的值,因此在需要高效的数据检索和索引的场景中经常使用。例如,将学生的学号与其成绩关联起来,可以通过学号快速查找对应的成绩。
- 数据去重:由于Map中的键是唯一的,可以利用这个特性进行数据的去重操作。例如,可以使用Map来统计一段文本中不同单词的出现次数,只保留每个单词的一个实例。
2.Set(集合)是一种存储独特元素的数据结构,其中每个元素都是唯一的。Set通常用于判断元素是否存在,而不关心元素的顺序。Set的实现通常基于哈希表或树结构。
Set的场景:
- 数据去重:由于Set中的元素是唯一的,可以使用Set来去除重复的数据。例如,从一个数组中去除重复的元素,可以通过将数组元素添加到Set中来实现。
- 成员关系判断:Set提供了高效的成员关系判断操作。例如,可以使用Set来判断一个元素是否属于某个特定集合。
相关模型:
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以模型会有两种:
- 比如: 有一个英文词典,快速查找一个单词是否在词典中快速查找某个名字在不在通讯录中
- 比如: 统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
- 梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
总结:
Map适用于需要将键与值相关联的场景,提供了快速的查找和索引功能。Set适用于存储唯一元素的场景,并提供了高效的成员关系判断。两者都在去重操作中有应用,但在其他的具体应用场景中,选择使用Map还是Set取决于具体的需求和数据结构的特点。
二.Map的说明及使用
2.1关于Map说明
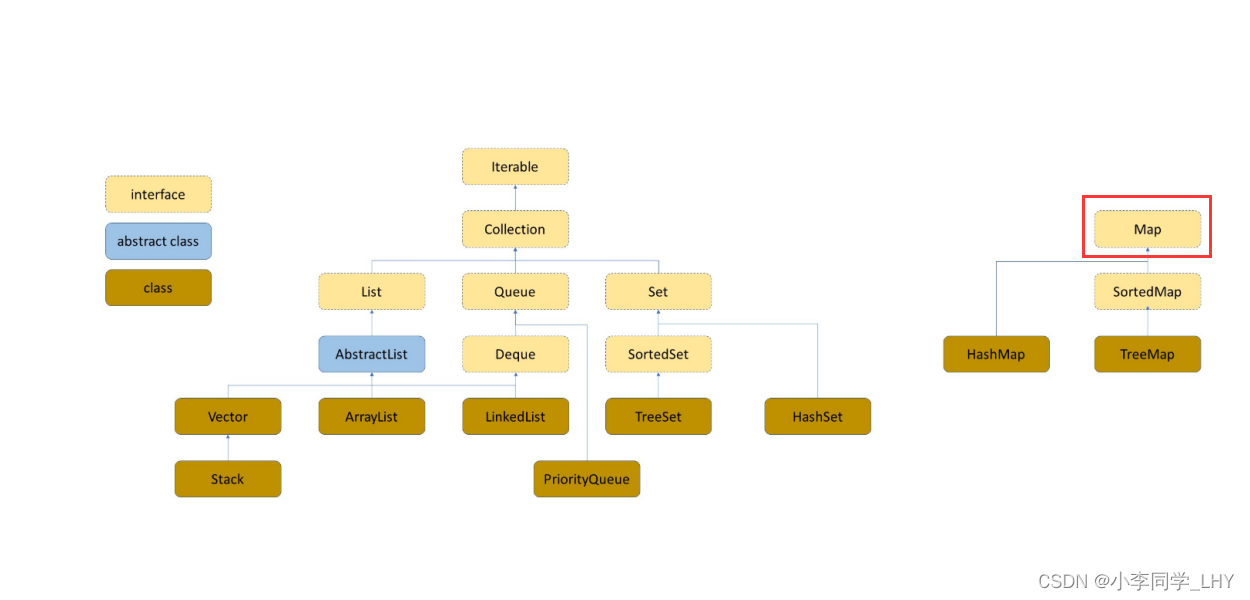
Map的特点和操作:
- 键-值对:Map中的数据以键-值对的形式进行存储。每个键都与一个特定的值相关联。
- 唯一键:Map中的键是唯一的,不允许重复。当尝试添加一个已经存在的键时,新的值会覆盖旧的值。
- 快速查找:Map提供了快速的查找功能,可以通过键来获取对应的值。这使得Map在需要高效的数据检索和索引的场景中非常有用。
- 增加和删除元素:可以向Map中添加新的键-值对,也可以删除已有的键-值对。
- 迭代:Map可以进行迭代操作,以便对其中的键-值对进行遍历和处理。
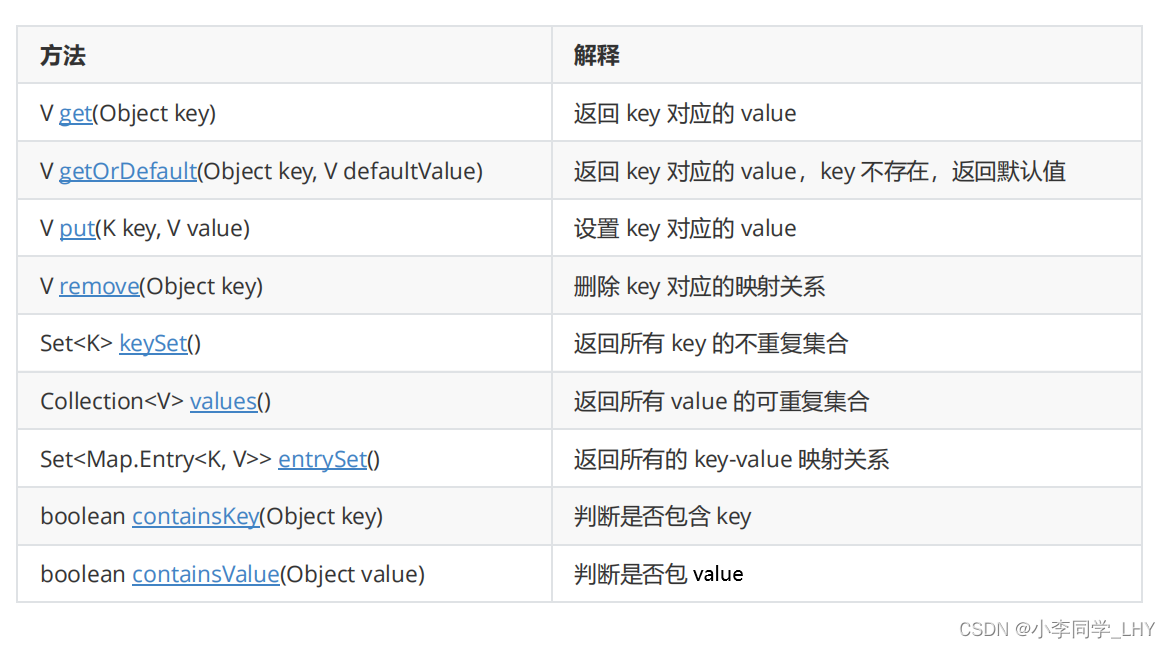
Map的常用方法说明:
2.2HashMap和TreeMap
HashMap和TreeMap是两种常见的Map实现,它们在底层数据结构和性能特点上有所区别。
HashMap:
- 底层数据结构:HashMap使用哈希表(Hash Table)作为底层数据结构,通过哈希函数将键映射到数组索引位置。
- 键的存储顺序:HashMap中的键是无序存储的,即键的顺序不受插入顺序的影响。
- 时间复杂度:平均情况下,HashMap提供常数时间复杂度(O(1))的查找、插入和删除操作。
- 适用场景:HashMap适用于需要快速查找、插入和删除键值对,并不关心顺序的场景。它在大多数情况下具有较高的性能。
HashMap的使用:
代码案例:
import java.util.HashMap;public class HashMapExample {public static void main(String[] args) {// 创建HashMap实例HashMap<String, Integer> hashMap = new HashMap<>();// 插入键值对hashMap.put("apple", 10);hashMap.put("banana", 5);hashMap.put("orange", 8);hashMap.put("grapes", 15);hashMap.put("kiwi", 20);hashMap.put("mango", 12);// 获取值int appleCount = hashMap.get("apple");System.out.println("Number of apples: " + appleCount);// 检查键是否存在boolean containsKey = hashMap.containsKey("banana");System.out.println("Contains banana: " + containsKey);// 删除键值对hashMap.remove("orange");// 迭代键值对for (String key : hashMap.keySet()) {int value = hashMap.get(key);System.out.println(key + ": " + value);}}
}运行如下:

TreeMap:
- 底层数据结构:TreeMap使用红黑树(Red-Black Tree)作为底层数据结构,保持键的有序性。
- 键的存储顺序:TreeMap中的键是按照键的自然顺序或自定义的比较器顺序进行排序的。
- 时间复杂度:TreeMap提供O(log n)的时间复杂度的查找、插入和删除操作,其中n是键值对的数量。
- 适用场景:TreeMap适用于需要按照键的顺序进行遍历和检索的场景。它可以用于范围查询,例如,查找最小键、最大键以及在两个键之间的键值对。
TreeMap的使用:
import java.util.TreeMap;public class TreeMapExample {public static void main(String[] args) {// 创建TreeMap实例TreeMap<String, Integer> treeMap = new TreeMap<>();// 插入键值对treeMap.put("apple", 10);treeMap.put("banana", 5);treeMap.put("orange", 8);treeMap.put("grapes", 15);treeMap.put("kiwi", 20);treeMap.put("mango", 12);// 获取值int appleCount = treeMap.get("apple");System.out.println("Number of apples: " + appleCount);// 检查键是否存在boolean containsKey = treeMap.containsKey("banana");System.out.println("Contains banana: " + containsKey);// 删除键值对treeMap.remove("orange");// 迭代键值对for (String key : treeMap.keySet()) {int value = treeMap.get(key);System.out.println(key + ": " + value);}}
}运行如下:

HashMap和TreeMap的区别:
底层数据结构:
- HashMap使用哈希表(数组+链表/红黑树)实现,通过哈希函数将键映射到数组索引位置,解决哈希冲突使用链表或红黑树。
- TreeMap使用红黑树实现,保持键的有序性,每个节点都遵循二叉搜索树的性质。
插入和查找操作性能:
- HashMap的插入和查找操作的平均时间复杂度为O(1),即常数时间复杂度。但在发生哈希冲突时,性能可能会下降,需要通过链表或红黑树进行顺序查找,最坏情况下的时间复杂度为O(n)。
- TreeMap的插入和查找操作的时间复杂度为O(log n),其中n是元素的数量。由于使用红黑树作为底层数据结构,保持有序性,因此查找操作更加高效。
排序特性:
- HashMap不保持键的有序性,键的顺序是不确定的。
- TreeMap根据键的自然顺序或自定义比较器对键进行排序,提供有序的键值对遍历。
存储空间:
- HashMap在内部使用数组来存储键值对,不保证顺序,因此通常占用较少的存储空间。
- TreeMap使用红黑树作为底层数据结构,保持键的有序性,因而在存储大量数据时占用的存储空间通常会更多。
参考下图:

2.3关于于Map.Entry<K, V>的说明

代码案例:
import java.util.HashMap;
import java.util.Map;public class MapExample {public static void main(String[] args) {// 创建一个HashMap实例Map<String, Integer> map = new HashMap<>();// 添加键值对到Map中map.put("apple", 10);map.put("banana", 5);map.put("orange", 8);// 遍历Map中的条目for (Map.Entry<String, Integer> entry : map.entrySet()) {String key = entry.getKey();Integer value = entry.getValue();System.out.println("Key: " + key + ", Value: " + value);}// 获取指定键的值int appleCount = map.get("apple");System.out.println("Number of apples: " + appleCount);// 使用setValue()方法更新值int newBananaCount = 7;map.entrySet().stream().filter(entry -> entry.getKey().equals("banana")).findFirst().ifPresent(entry -> entry.setValue(newBananaCount));// 输出更新后的值int updatedBananaCount = map.get("banana");System.out.println("Updated number of bananas: " + updatedBananaCount);}
}运行如下:

三.Set的说明及使用
3.1关于Set说明
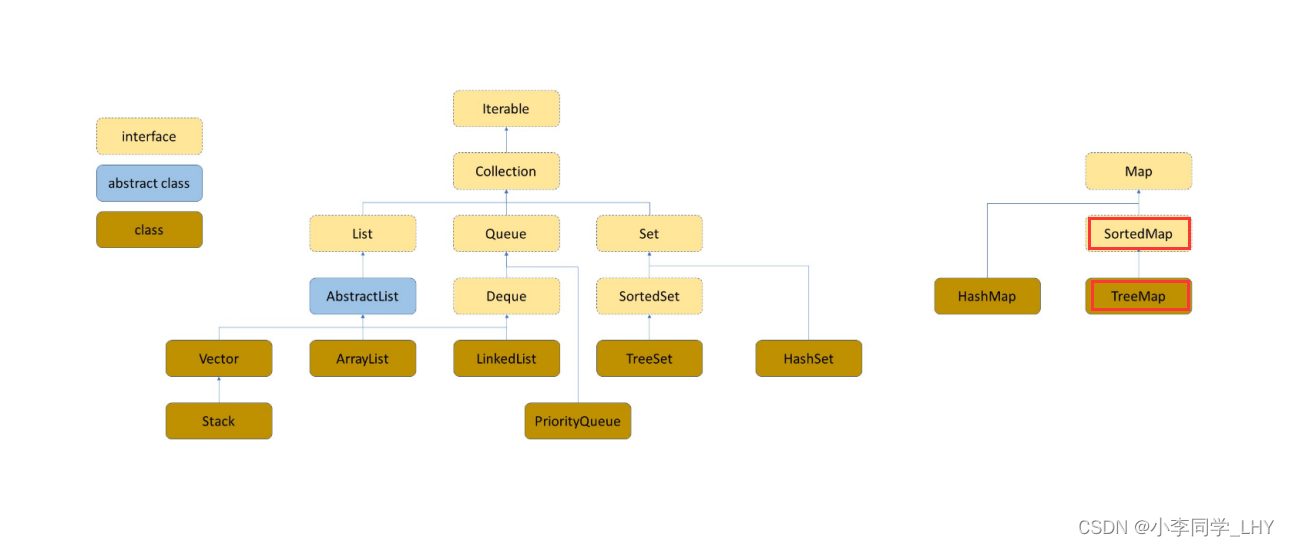
Set的特点和操作:
-
唯一性:Set中的元素是唯一的,不会出现重复的元素。如果尝试将重复的元素添加到Set中,它将被忽略。
-
无序性:Set中的元素没有特定的顺序。这意味着你不能通过索引来访问Set中的元素。如果需要按特定顺序遍历元素,可以将Set转换为列表或使用其他有序数据结构。
-
可变性:Set是可变的,可以添加或删除元素。可以通过添加新元素或删除现有元素来修改Set。
-
高效性:Set提供了高效的成员检查操作。由于Set使用了哈希表或类似的数据结构来实现,它可以在平均情况下以常量时间复杂度(O(1))执行插入、删除和查找操作。
-
迭代性:Set支持迭代操作,可以使用循环遍历Set中的所有元素。
-
数学集合操作:Set还支持常见的数学集合操作,例如并集、交集和差集。这些操作使得可以对Set进行合并、比较和筛选等操作。

- Set是继承自Collection的一个接口类
- Set中只存储了key,并且要求key一定要唯一
- TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
- TreeSet中不能插入null的key,HashSet可以
3.2TreeSet和HashSet
HashSet:
-
唯一性:HashSet中的元素是唯一的,不会存在重复元素。如果尝试将重复的元素添加到HashSet中,它将被忽略。
-
无序性:HashSet中的元素没有特定的顺序。元素在HashSet中的存储位置是根据元素的哈希码计算得出的,并不与插入顺序或值的大小相关。
-
元素存储:HashSet使用哈希表(Hash Table)来存储元素。哈希表通过哈希函数将元素的值映射到桶(bucket)中。每个桶可以包含一个或多个元素。通过哈希函数和桶的结构,HashSet实现了高效的插入、删除和查找操作。
-
性能:HashSet的插入、删除和查找操作的平均时间复杂度是常数时间复杂度(O(1)),在大多数情况下具有很高的性能。但是,在某些情况下,由于哈希冲突(多个元素映射到同一个桶),性能可能会下降,导致操作的时间复杂度变为O(n)。
-
迭代性:HashSet支持迭代操作,可以使用增强的for循环或迭代器来遍历HashSet中的所有元素。但是,由于HashSet是无序的,迭代顺序不可预测。
-
对象比较:为了正确地判断元素的相等性,HashSet要求元素类正确实现
equals()和hashCode()方法。equals()方法用于比较两个元素的内容是否相等,而hashCode()方法用于计算元素的哈希码,以确定元素在哈希表中的存储位置。
import java.util.HashSet;
import java.util.Set;public class HashSetExample {public static void main(String[] args) {// 创建一个HashSet实例Set<String> set = new HashSet<>();// 添加元素到HashSetset.add("apple");set.add("banana");set.add("orange");// 输出HashSet的大小System.out.println("HashSet size: " + set.size());// 检查元素是否存在boolean containsOrange = set.contains("orange");System.out.println("Set contains 'orange': " + containsOrange);// 移除元素set.remove("banana");// 遍历HashSet中的元素System.out.println("HashSet elements:");for (String element : set) {System.out.println(element);}// 清空HashSetset.clear();// 检查HashSet是否为空boolean isEmpty = set.isEmpty();System.out.println("HashSet is empty: " + isEmpty);}
}运行如下:

TreeSet:
-
唯一性:TreeSet中的元素是唯一的,不会存在重复元素。如果尝试将重复的元素添加到TreeSet中,它将被忽略。
-
排序性:TreeSet中的元素是有序的,根据元素的自然排序或指定的比较器排序。默认情况下,元素被按升序排序。
-
元素存储:TreeSet使用红黑树数据结构进行存储。红黑树是一种自平衡的二叉搜索树,它通过保持树的平衡性,提供了高效的插入、删除和查找操作。元素在红黑树中根据其排序顺序进行存储。
-
性能:TreeSet的插入、删除和查找操作的平均时间复杂度是O(log n),其中n是TreeSet中的元素数量。由于红黑树的平衡性,这些操作的性能相对稳定,不会受到元素的插入顺序的影响。
-
迭代性:TreeSet支持迭代操作,可以使用增强的for循环或迭代器来遍历TreeSet中的所有元素。由于TreeSet是有序的,迭代顺序将按照元素的排序顺序进行。
-
对象比较:为了正确地判断元素的相等性和排序顺序,TreeSet要求元素类实现Comparable接口或提供自定义的比较器。Comparable接口的
compareTo()方法用于比较两个元素的顺序。
import java.util.TreeSet;
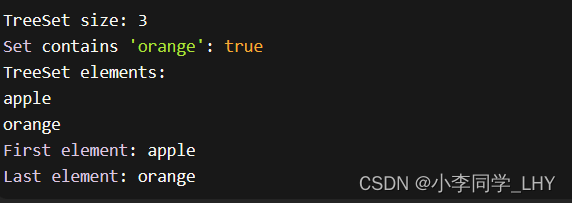
import java.util.Set;public class TreeSetExample {public static void main(String[] args) {// 创建一个TreeSet实例Set<String> set = new TreeSet<>();// 添加元素到TreeSetset.add("apple");set.add("banana");set.add("orange");// 输出TreeSet的大小System.out.println("TreeSet size: " + set.size());// 检查元素是否存在boolean containsOrange = set.contains("orange");System.out.println("Set contains 'orange': " + containsOrange);// 移除元素set.remove("banana");// 遍历TreeSet中的元素System.out.println("TreeSet elements:");for (String element : set) {System.out.println(element);}// 获取最小元素String firstElement = ((TreeSet<String>) set).first();System.out.println("First element: " + firstElement);// 获取最大元素String lastElement = ((TreeSet<String>) set).last();System.out.println("Last element: " + lastElement);}
}
TreeSet和HashSet的区别:

结语:Map和Set是Java集合框架中常用的数据结构。Map是一种键值对的数据结构,用于存储和操作具有唯一键和对应值的元素,适用于缓存、数据索引和快速查找等场景。Set是一种无序、不重复元素的集合,用于存储和操作独立的元素,适用于去重和判断元素是否存在的场景。它们提供了高效的操作和查找能力,并有多个实现类可供选择,如HashMap、TreeMap、HashSet和TreeSet等,根据具体需求选择合适的实现类。

这篇关于从根到叶:深入了解Map和Set的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





