本文主要是介绍猿创征文|GEDI数据下载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
什么是GEDI
GEDI的下载方式
1、什么是GEDI?
GEDI是美国国家航空航天局(NASA)发射的, 搭载于国际空间站,轨道高度约 400 km。其同时获取 8 条地面轨道数据,相邻轨道间距约 600 m,扫描幅宽达 4.2 km。GEDI 以 242 Hz 重复频率发射 1064 nm 红外波段,脉冲宽度为 14 ns,可以获取沿轨间隔约 60 m、直 径约 25 m 的光斑。此外 GEDI 观测覆盖范围为 51.6°S~51.6°N。根据数据处理阶段的不同,GEDI 产品划分为四个级 别。1 级产品即定位波形;2 级产品即足印级冠层高度和剖面度量; 3 级产品即格网冠层高度及其变化;4A 和 4B 级产品即足印以及格网地上碳估计。其中,初级产 品(L1 和 L2)由 LPDAAC 生产, 高级产 品(L3 和 L4) 由 ORNL DAAC 生产。GEDI 量化了地球植被中的生物量,从而量化了 植被中的碳储量,并估算了土地利用和气候变化产生的碳通量。由此,可以计算在未来气候和土地利用情景下森林的碳汇潜力。通过利用 GEDI 提供的植被垂直结构信息,可以表征大量生物的栖息地质量。。如此一来,GEDI 不仅 可以解决有关植被碳汇估算的问题,还可以通过垂直结构测量指导改善栖息地质量,最终实现生物多样性的保护。
2、GEDI的下载方式
2.1 注册EarthData账号,进入earthdata官网https://www.earthdata.nasa.gov/,点击用户注册,填写信息。
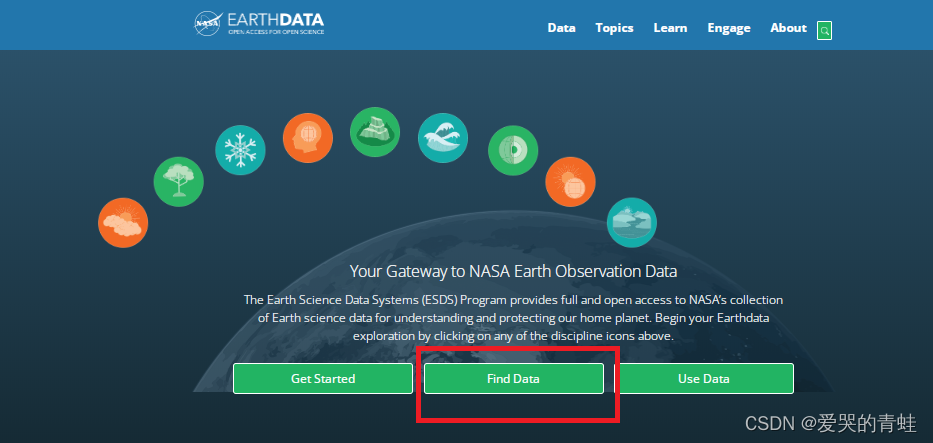
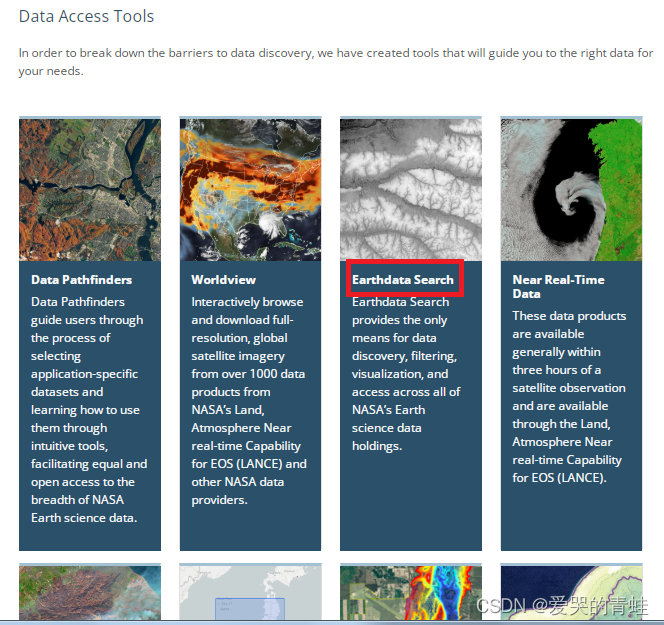
2.2 注册好以后返回页面,点击登录即可。在主页面选择Find Data,进入界面之后往下划,找到Data Access Tools,在数据获取工具下面选择Earthdata Search 即可。
3、 GEDI数据搜索和选择
登陆进去后就可以在搜索框里输入GEDI就可看见不同级别的GEDI数据,同时也可以设置数据筛选条件包括时间,区域等。
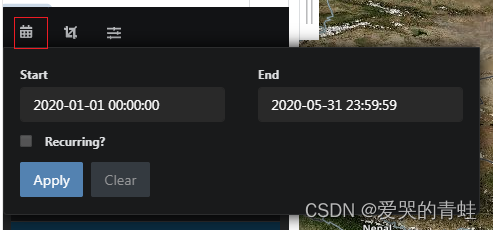
3.1 选择你所需要的时间,在左上角点击日历的标志就可以选择时间范围。这里选取了2020年1月1日至2020年5月31日的数据作为示例。
3.2 、选择感兴趣区域的方式有很多种,官网提供了多边形、方形、点、圆和文件等方式。这里使用多边形和矢量文件的方式作为示例。
3.2.1 按多边形选择只需要在地图上选择你需要的研究区域即可。
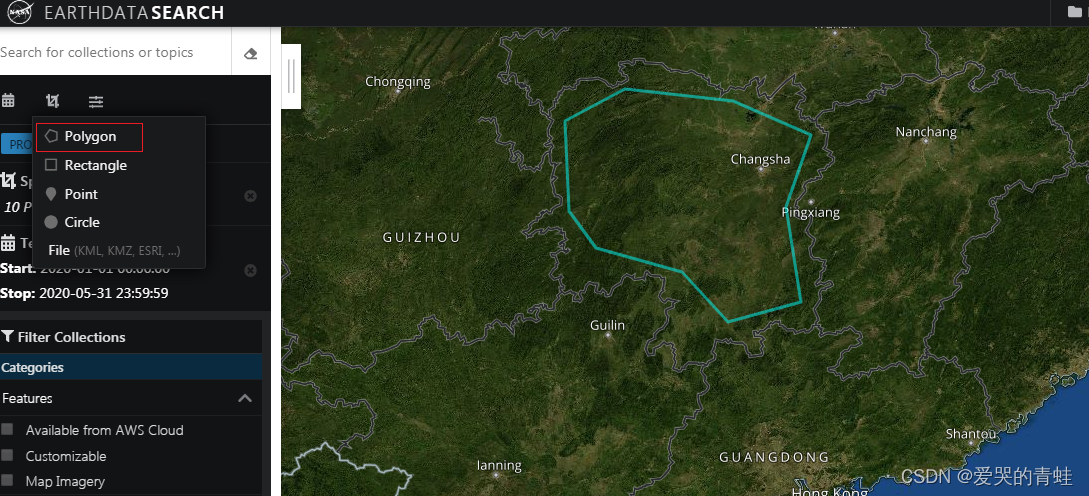
3.2.2 按矢量文件选择研究区,需要新建一个压缩包,里面包含研究区的shp、dbf、shx、prj文件,在左上角点击选择按钮下面的File,然后上传文件即可。


4 、 设定好条件后,右边数据框里面数据就搜索出来了,包括L4A,L4B、L2A、L2B等。可根据研究需要,选择不同等级的数据。
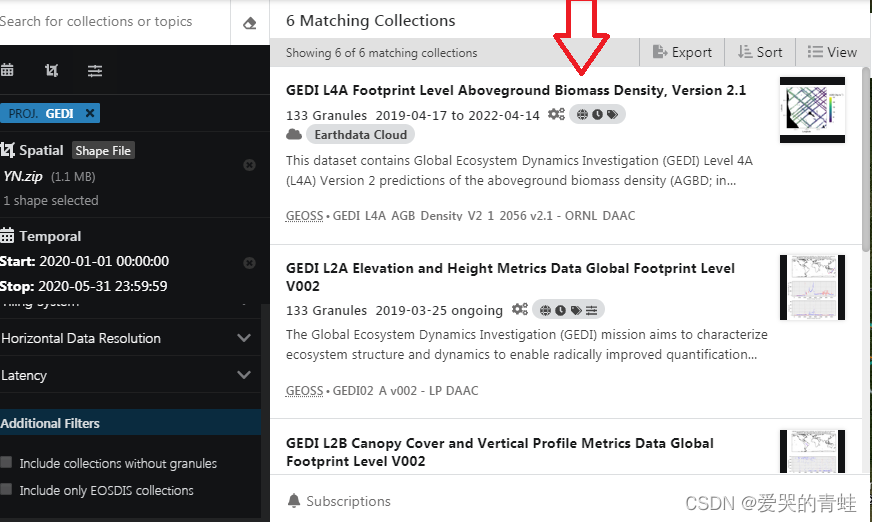
5 、这里以L2B数据为例,点击数据框里的GEDI L2B Canopy Cover and Vertical.....数据,点击进去以后,就可以看见在设定日期范围内可用的数据,从2020年1月到5月,这里有133条数据。你可以点击右下方的Download all,全部下载,也可以点击每条数据旁边的+号,加入到文件夹里面,对单条进行下载。
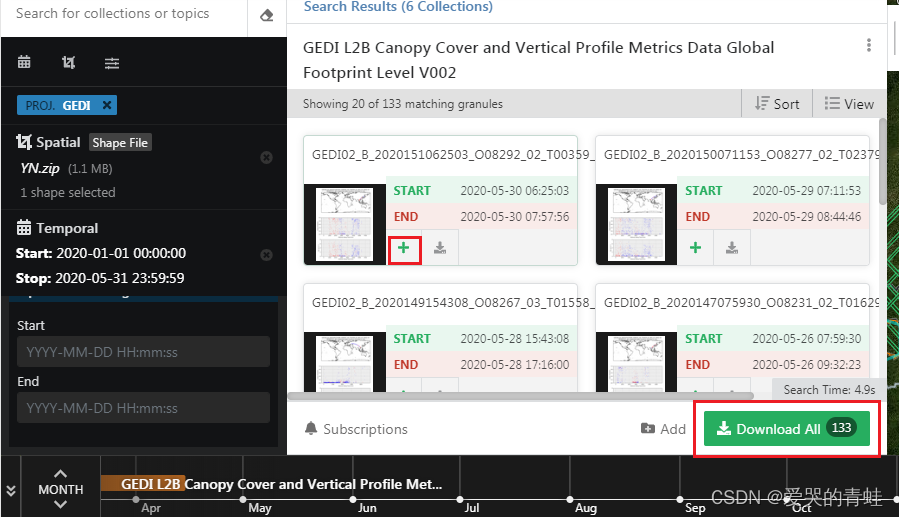
6 、选择好所需的数据后,点击DownLoad,就可以进入到下载页面,它会让你选择一种数据获取的方式, 系统提供了Customize、Stage For Delivery、Direct Download 三种方式,这里选择直接下载(Direct Download)。在数据量不多的情况下可以直接下载。如果数据量很多,可以选择其他下载方式。


7、 选择直接下载后,点击DownLoad Data,就会弹出以下界面,选择Download File,直接点击它提供的下载链接就可以下载了。
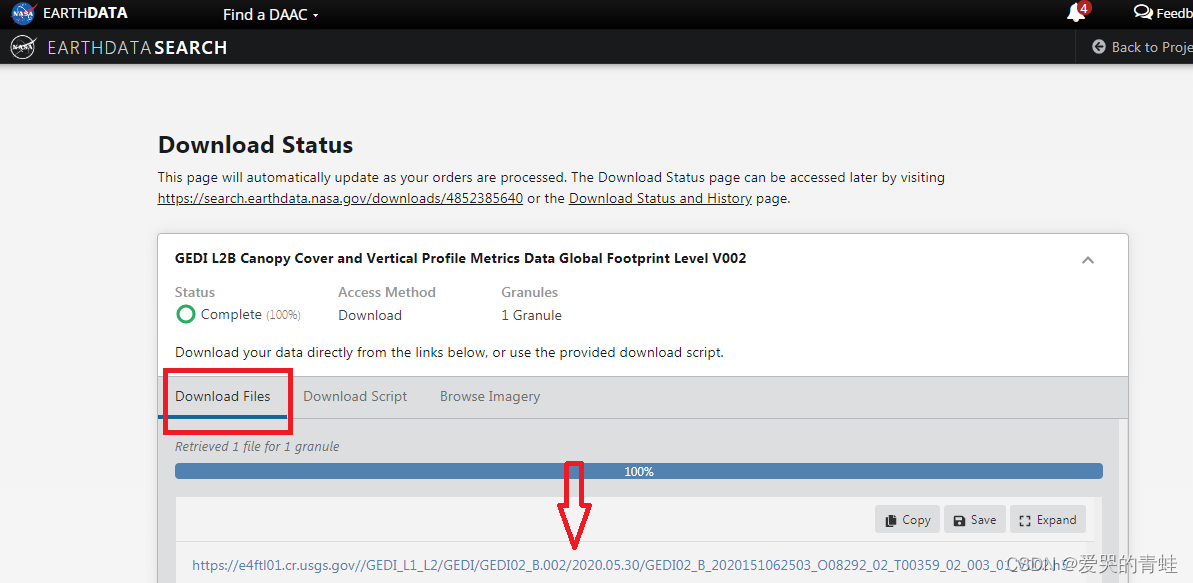
8、下载完成!
这篇关于猿创征文|GEDI数据下载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







