本文主要是介绍【1688运营】如何拆解竞争对手店铺和单品数据?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注竞争对手数据是1688运营中不可或缺的一环,它有助于企业更好地了解市场环境、发现市场机会、学习成功经验、预测市场变化以及提升竞争力。以下是一些建议,帮助你全面、深入地分析竞争对手的店铺和单品数据:
1、监控店铺数据
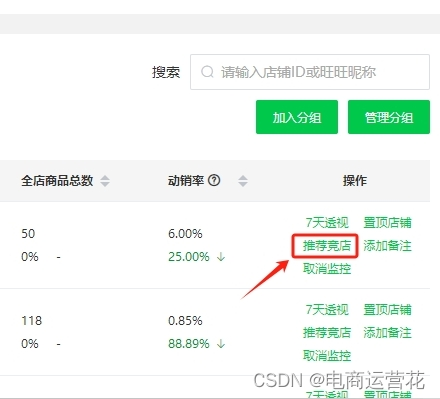
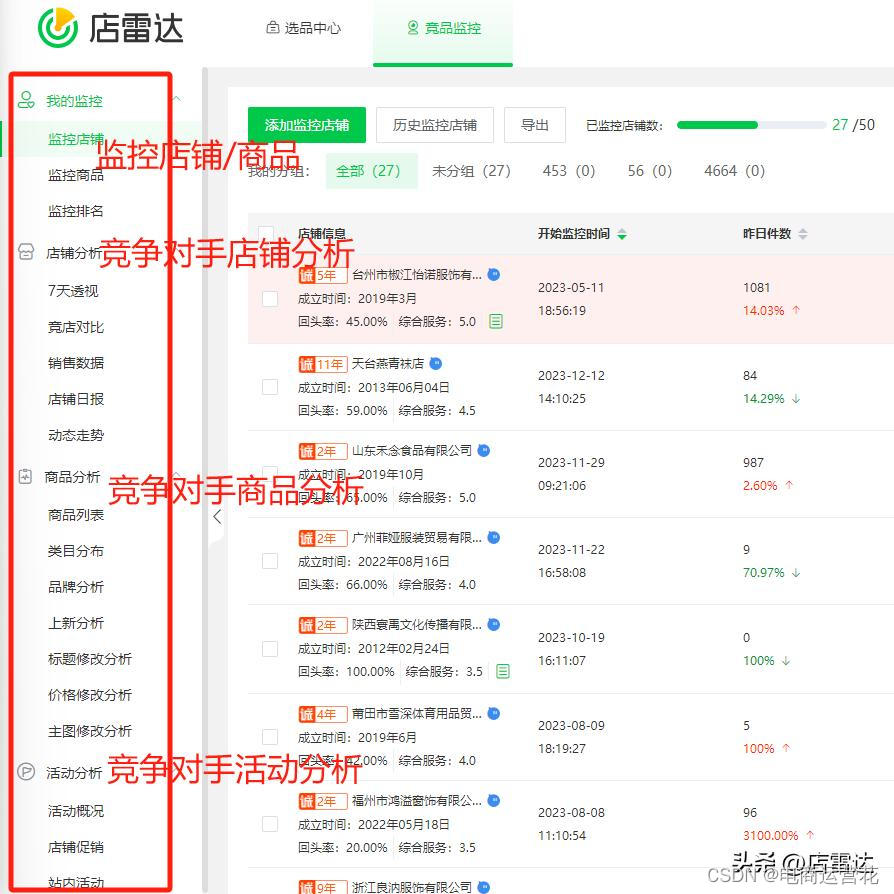
可以通过店雷达工具找到有竞争关系或值得学习的店铺都添加监控,实时查看竞品店铺的销售数据。

监控店铺---新增推荐竞店功能
根据您当前添加监控的店铺推荐近期销量好的同行竞店,帮助您了解更多竞争信息,选择不同时间后,会改变下方列表商品的销售笔数、销售件数、销售额的统计周期、
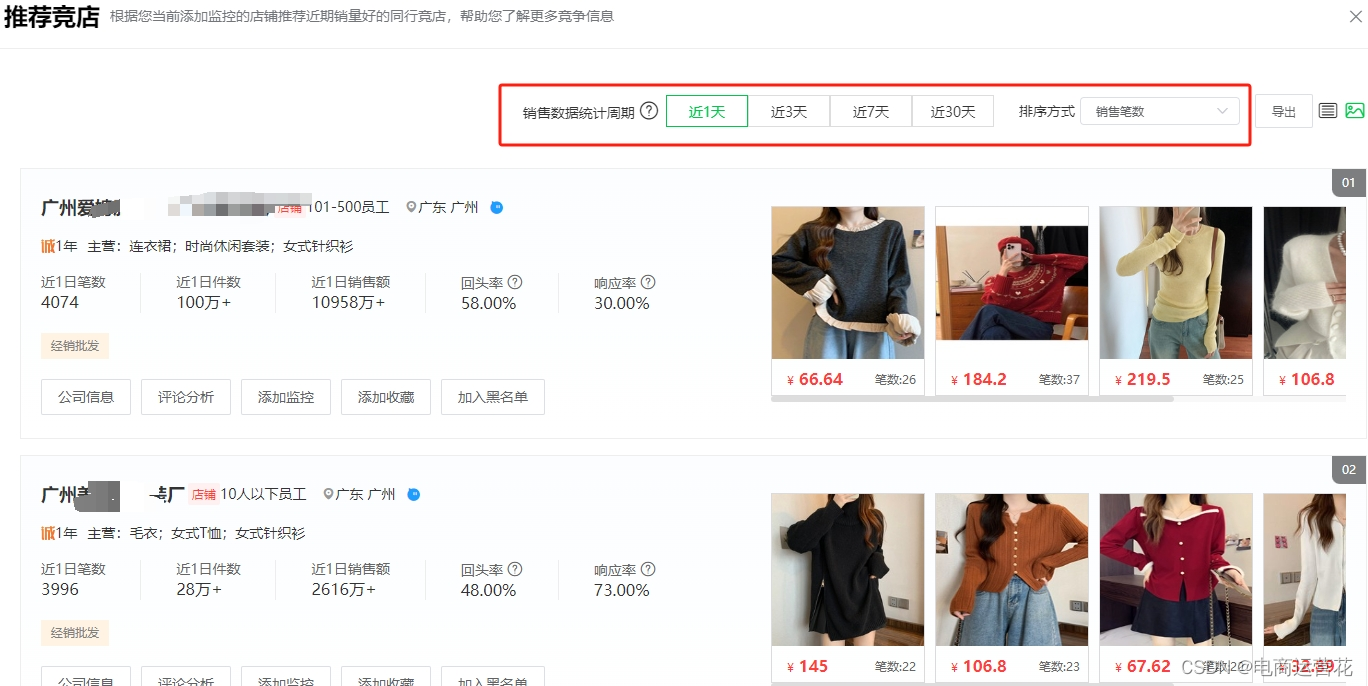
右上角可以改变视图列表,还可以直接导出列表信息查看。
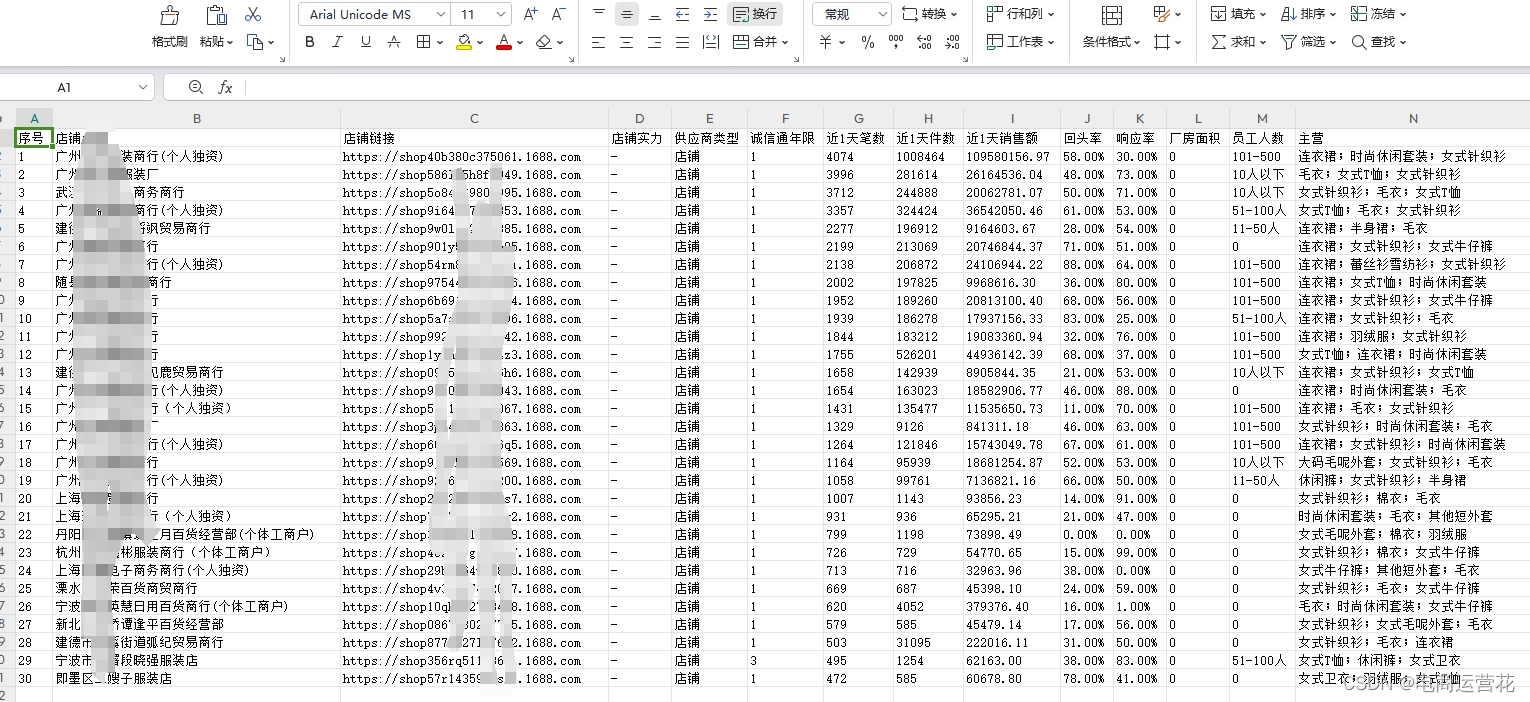
【竞对7天数据透视】竞店数据对比销售情况、自然引流、营销活动、宝贝日常操作监控统计;竞争对手卖家服务能力和交易情况数值变动跟踪。
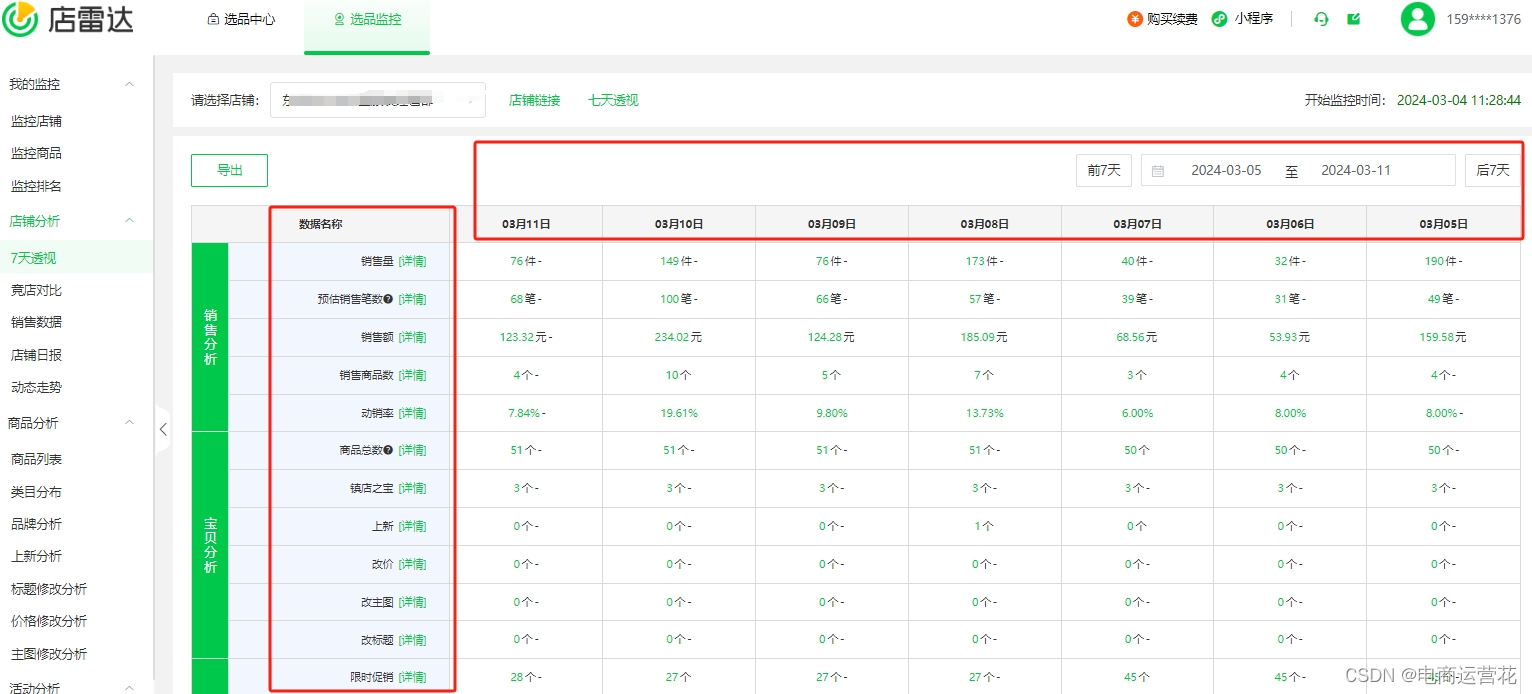
单品数据监控
对感兴趣的商品或者竞争对手卖的最好的品进行单独的商品监控,最多可以监控500个商品,添加商品监控以后可以看到商品昨日变化、售卖笔数、件数、7日销量、7日销售笔数、销售额等信息。
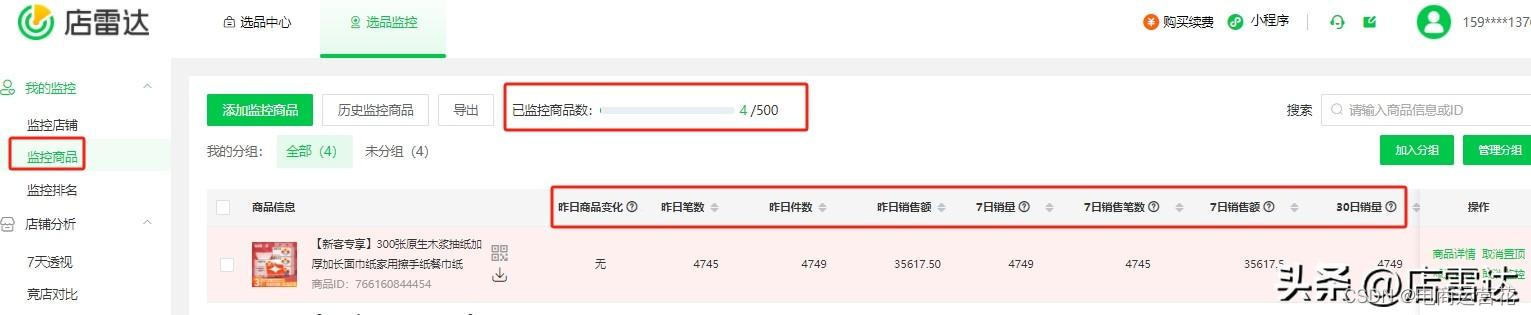
还可以添加自己想监控的关键词,实时监控商品的排名情况!

监控商品---新增推荐竞品功能
根据您当前添加监控的商品推荐近期销量好的同行竞品,帮助您了解更多竞争信息
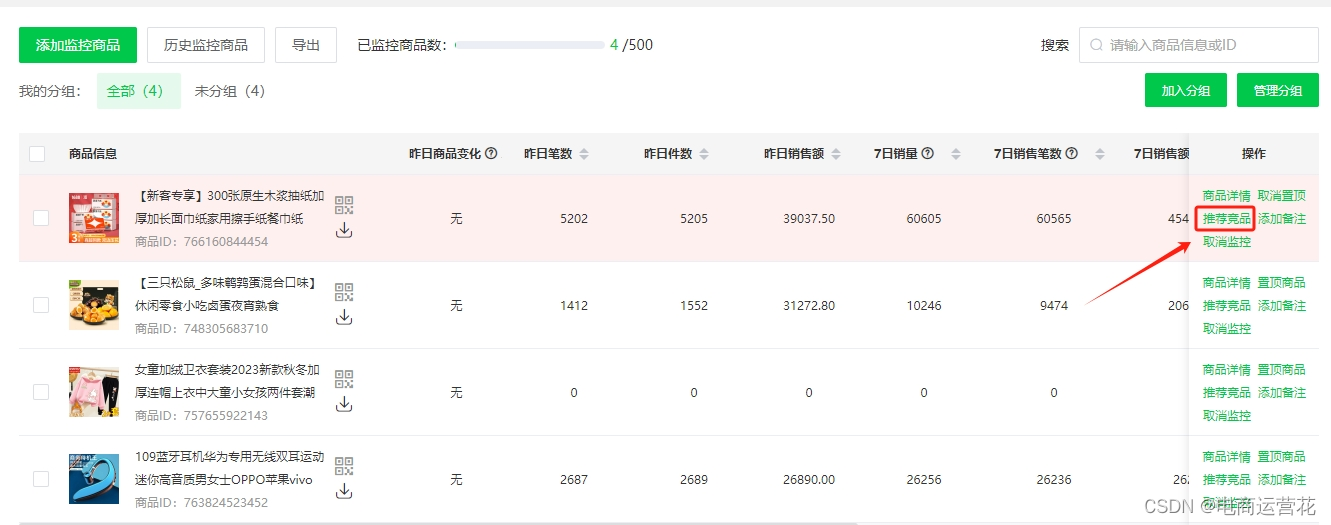
商品统计周期除了销售笔数、销售件数、销售额的统计周期以外还有总笔数、总件数、创建时间、复购率等可筛选条件,帮助大家多维度分析。

销售数据:还可以直接的看销售统计数据,了解厂家,近7天/14天/30天的销售情况
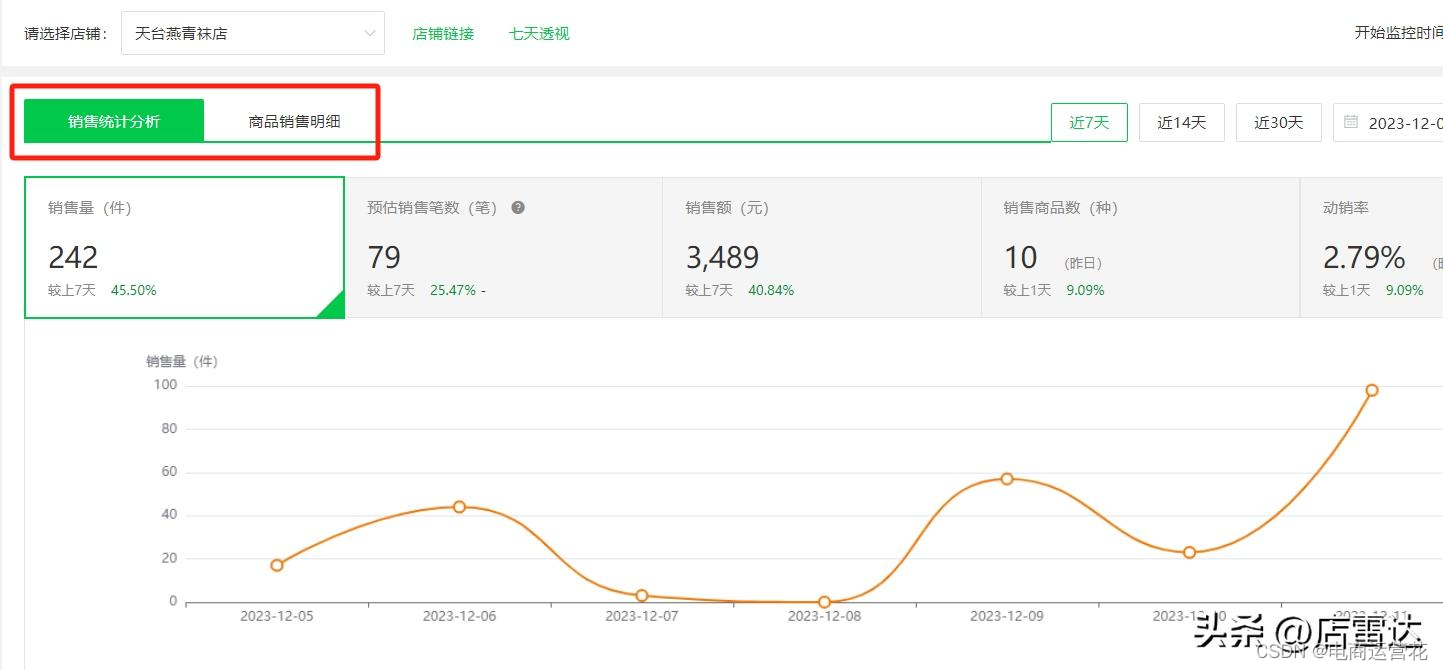
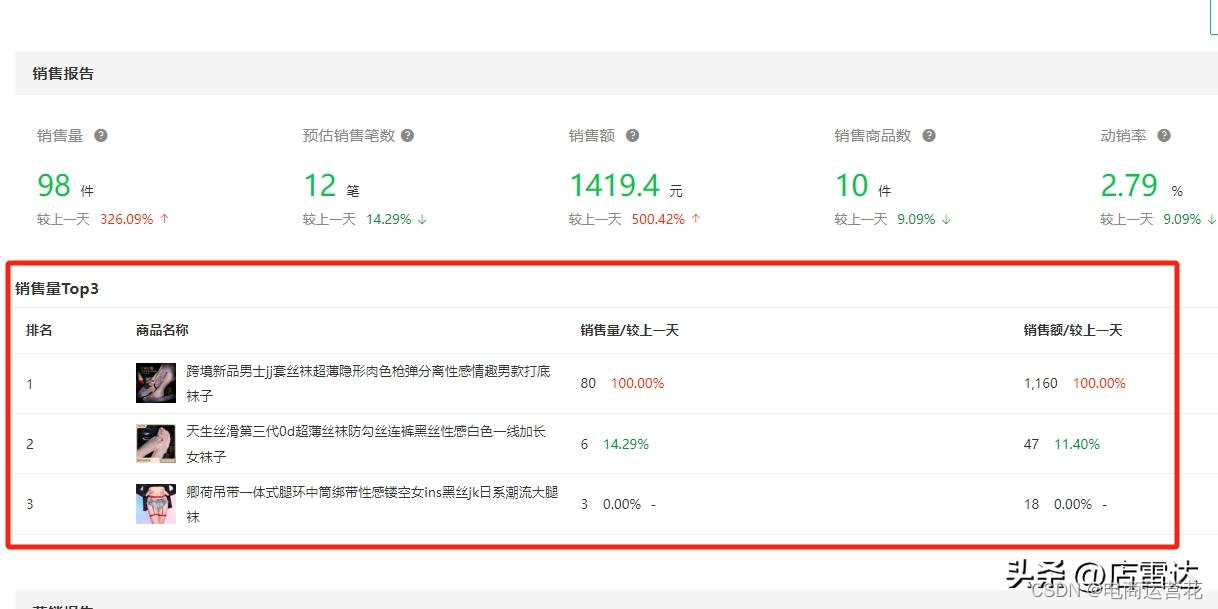
店铺日报:以及具体的销售报告和店内销售量TOP3的商品
当然不止只有这些功能,上面这些只是列出比较热门功能。还有其实很多针对竞争对手店铺的数据分析工具可以用。
最后,需要强调的是,分析竞争对手数据是一个持续的过程,商家应定期更新数据并调整策略,以适应不断变化的市场环境。
这篇关于【1688运营】如何拆解竞争对手店铺和单品数据?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






