本文主要是介绍内网穿透的应用-如何在Linux系统Docker安装JSON Crack并实现远程访问本地数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 在Linux上使用Docker安装JSONCrack
- 2. 安装Cpolar内网穿透工具
- 3. 配置JSON Crack界面公网地址
- 4. 远程访问 JSONCrack 界面
- 5. 固定 JSONCrack公网地址
JSON Crack 是一款免费的开源数据可视化应用程序,能够将 JSON、YAML、XML、CSV 等数据格式可视化为交互式图表。凭借其直观且用户友好的界面,JSON Crack 可以轻松探索、分析和理解即使是最复杂的数据结构。使用JSONCrack并结合cpolar内网穿透工具还能实现团队在公网上进行远程协作,能更好的提高工作效率!
1. 在Linux上使用Docker安装JSONCrack
下载JSONCrack源代码:
wget https://github.com/AykutSarac/jsoncrack.com/archive/refs/tags/v3.2.0.zip
进行解压缩
unzip v3.2.0.zip
本地编译容器
sudo docker build -t jsoncrack .
在本地运行端口号为8888的 JSONCrack
docker-compose up -d
浏览器访问 http://localhost:8888
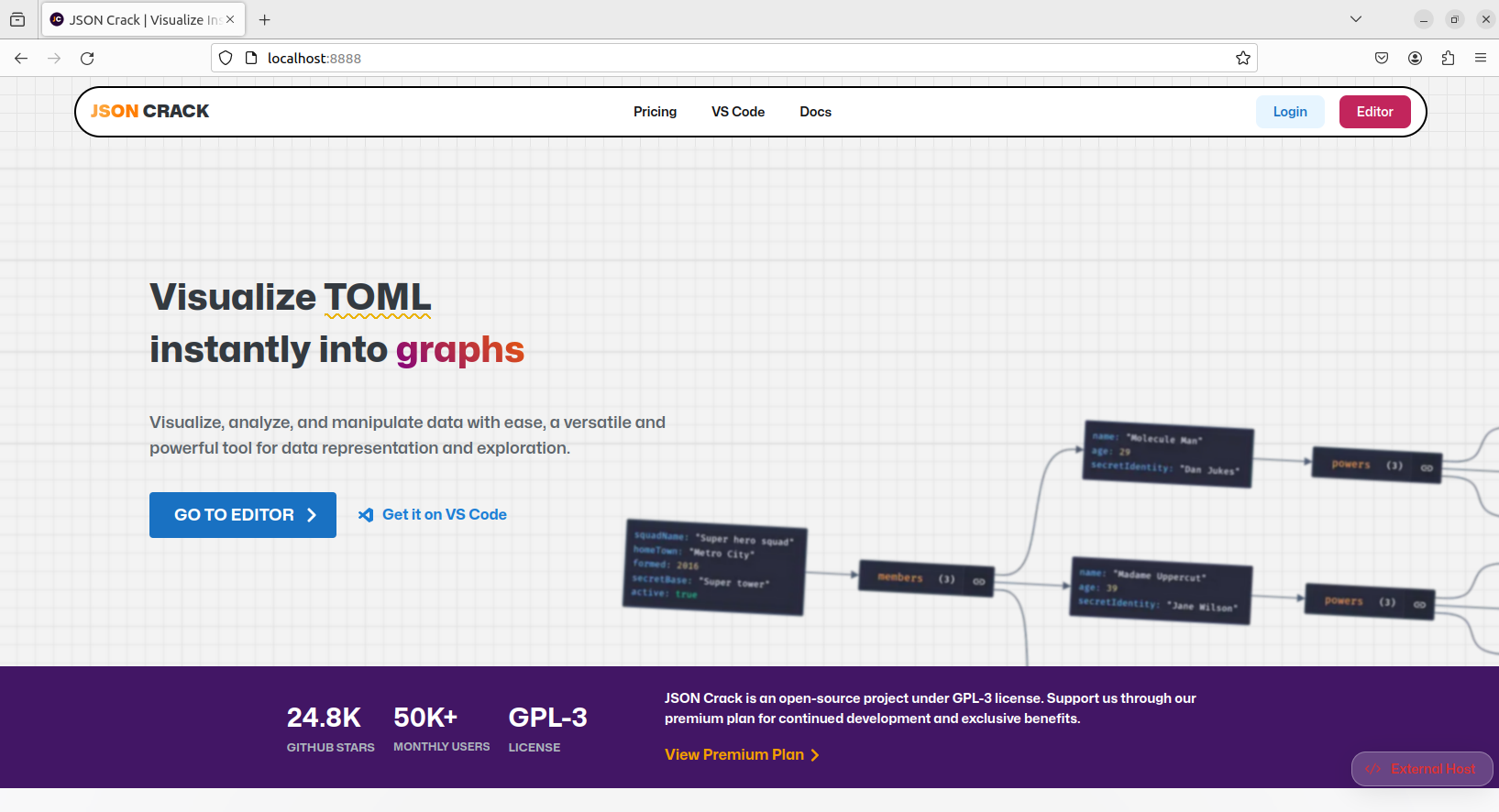
我们运行 JSON Crack 后,在浏览器输入Linux局域网IP加8888端口,即可成功访问 JSON Crack 管理界面,下面安装介绍安装Cpolar内网穿透工具,实现无公网也可以远程访问本地 JSON Crack 界面
2. 安装Cpolar内网穿透工具
上面在本地Docker中成功部署了 JSON Crack ,并局域网访问成功,下面我们在Linux安装Cpolar内网穿透工具,通过Cpolar 转发本地端口映射的http公网地址,我们可以很容易实现远程访问,而无需自己注册域名购买云服务器.下面是安装cpolar步骤
cpolar官网地址: https://www.cpolar.com
- 使用一键脚本安装命令
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
- 向系统添加服务
sudo systemctl enable cpolar
- 启动cpolar服务
sudo systemctl start cpolar
Cpolar安装成功后,在外部浏览器上访问Linux 的9200端口 即:【http://局域网ip:9200】,使用Cpolar账号登录,登录后即可看到cpolar web 配置界面,结下来在web 管理界面配置即可
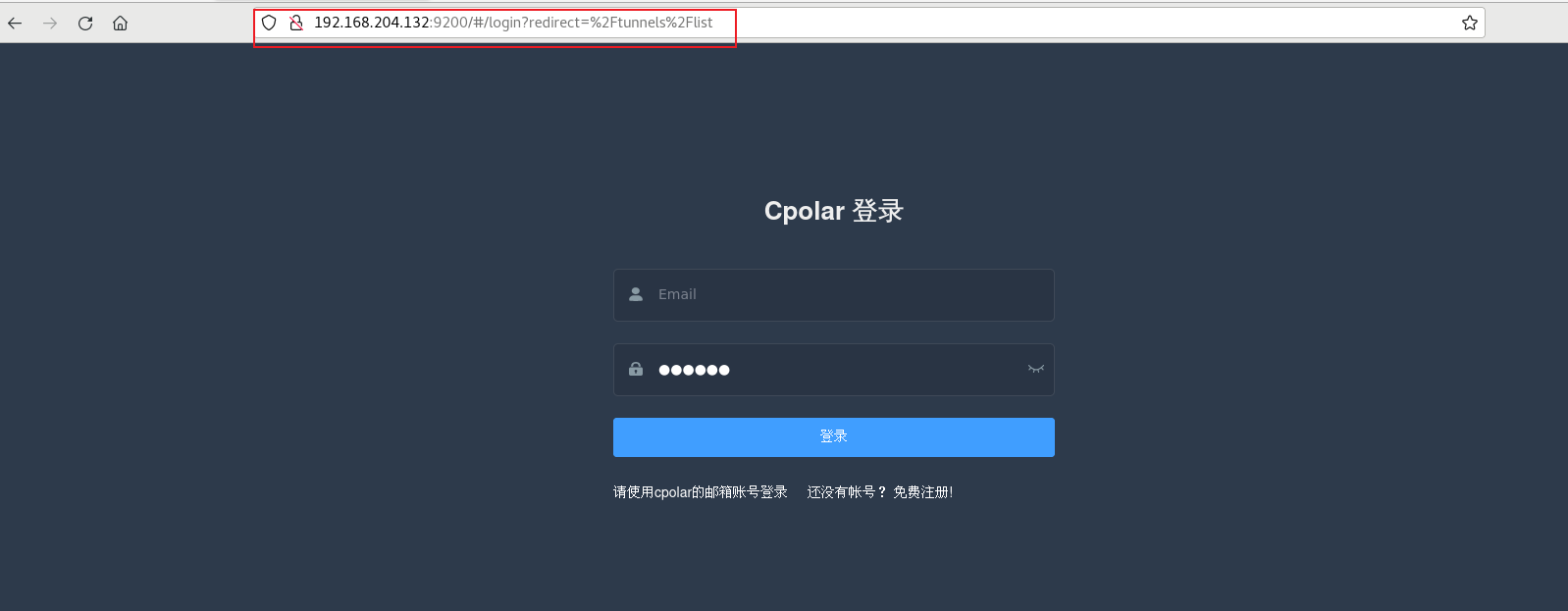
3. 配置JSON Crack界面公网地址
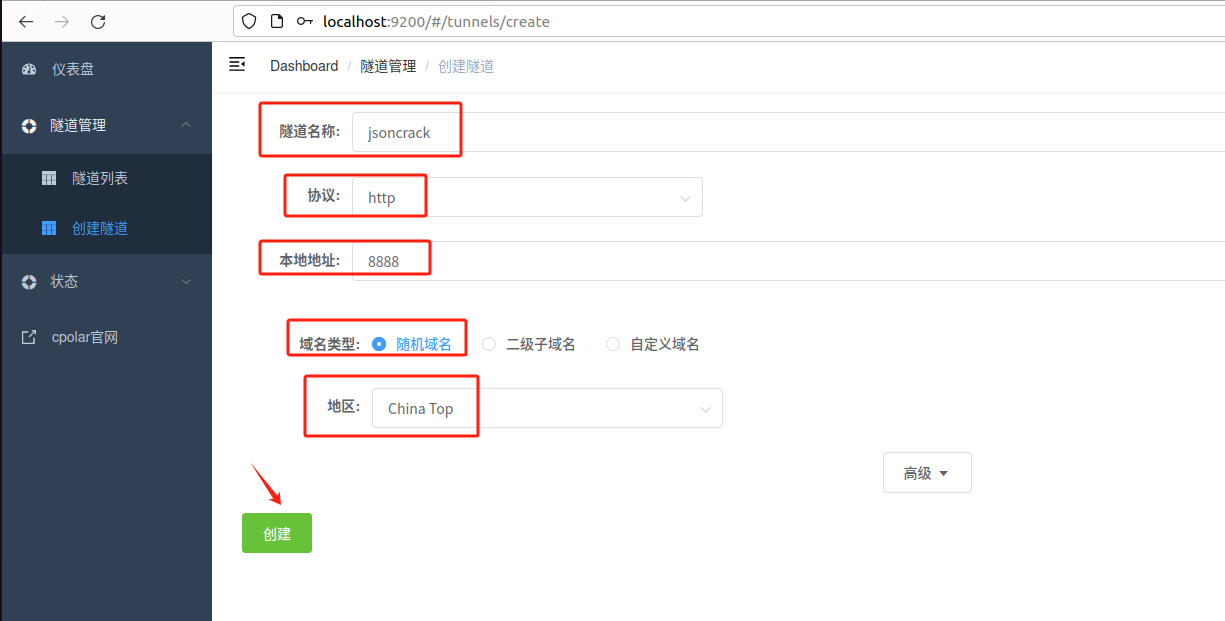
点击左侧仪表盘的隧道管理——创建隧道,创建一个JSONCrack的公网http地址隧道!
- 隧道名称:可自定义命名,注意不要与已有的隧道名称重复
- 协议:选择http
- 本地地址:8088(本地访问的地址)
- 域名类型:免费选择随机域名
- 地区:选择China Top
点击创建
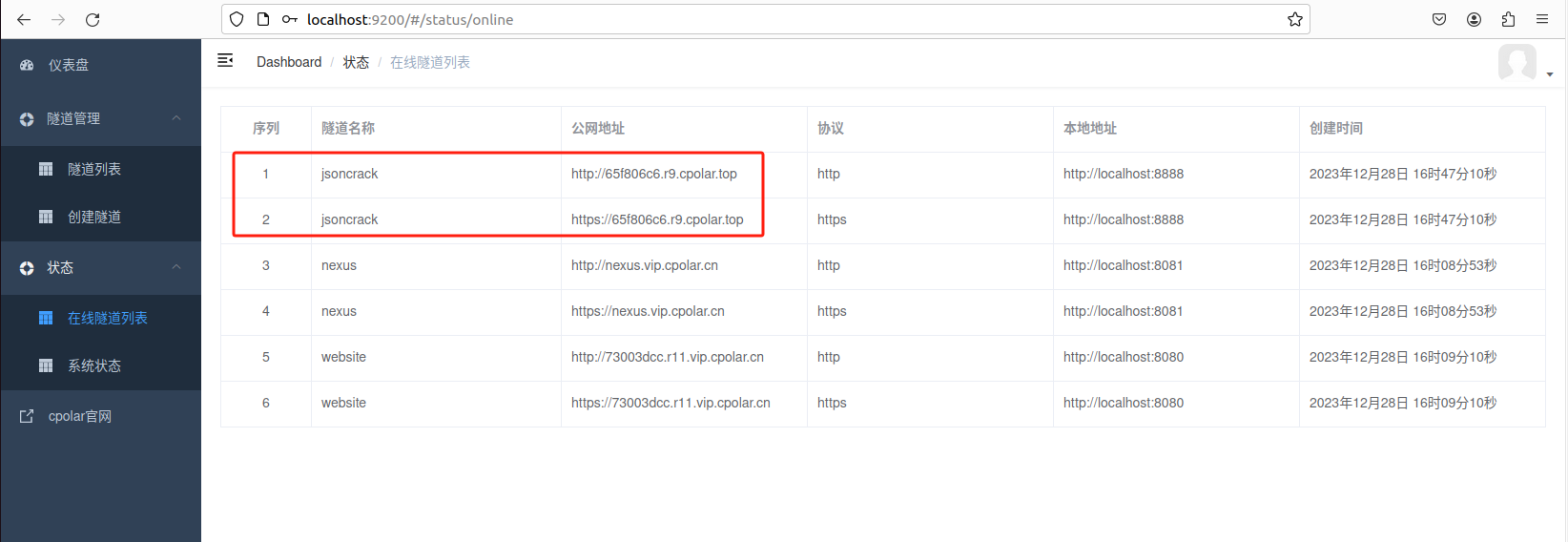
隧道创建成功后,点击左侧的状态——在线隧道列表,查看所生成的公网访问地址,有两种访问方式,一种是http 和https
4. 远程访问 JSONCrack 界面
使用上面的Cpolar https公网地址,在任意设备的浏览器进行访问,即可成功看到 JSONCrack 界面,这样一个公网地址且可以远程访问就创建好了,使用了Cpolar的公网域名,无需自己购买云服务器,即可发布到公网进行远程访问 !
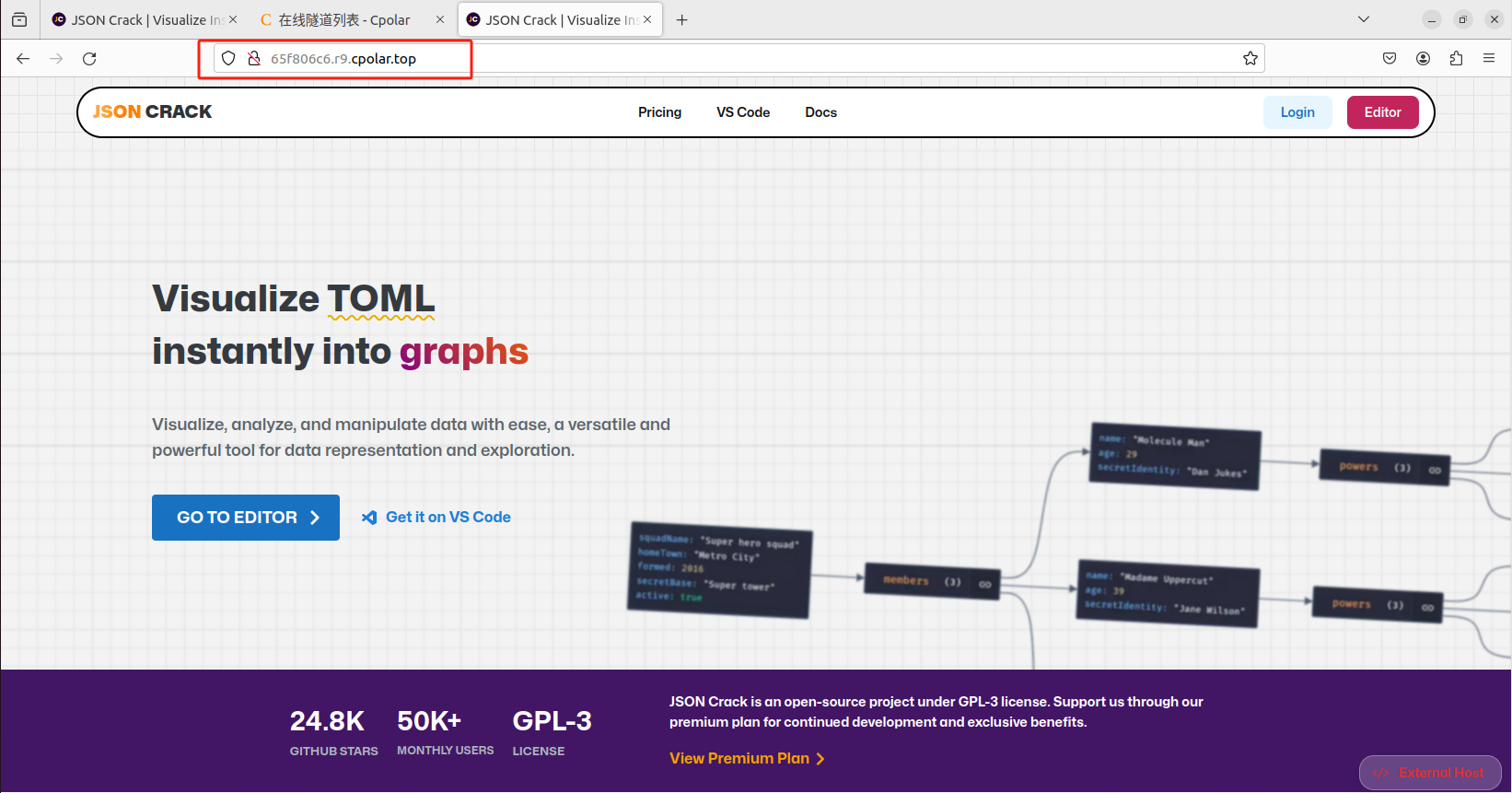
为了更好地演示,我们在前述过程中使用了cpolar生成的隧道,其公网地址是随机生成的。
这种随机地址的优势在于建立速度快,可以立即使用。然而,它的缺点是网址由随机字符生成,不太容易记忆(例如:234b53d8.r1.cpolar.top),另外这个地址在24小时内会发生随机变化,不利于团队长期协作,更适合于临时使用。
我一般会使用固定二级子域名,原因是我希望分享给身边的人时,它是一个固定、易记的公网地址(例如:JSONCrack.cpolar.cn),这样更显正式,便于交流协作。
5. 固定 JSONCrack公网地址
由于以上使用Cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化【ps:cpolar.cn已备案】
注意需要将cpolar套餐升级至基础套餐或以上,且每个套餐对应的带宽不一样。【cpolar.cn已备案】
登录cpolar官网,点击左侧的预留,选择保留二级子域名,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称
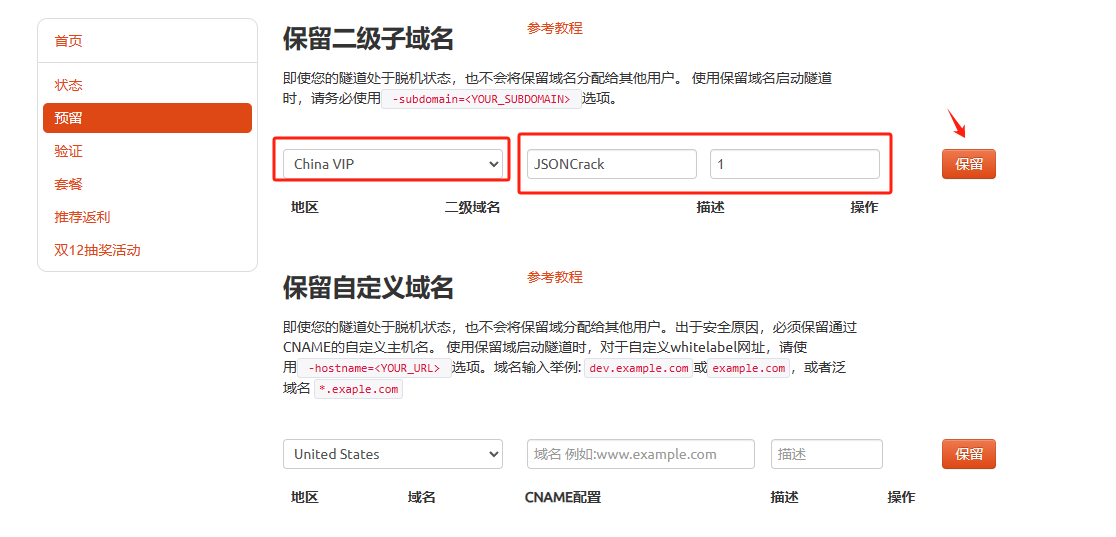
保留成功后复制保留成功的二级子域名的名称
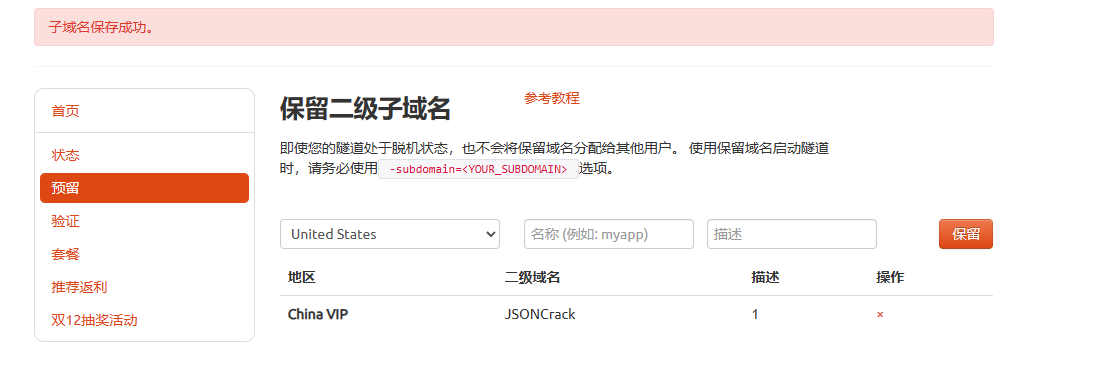
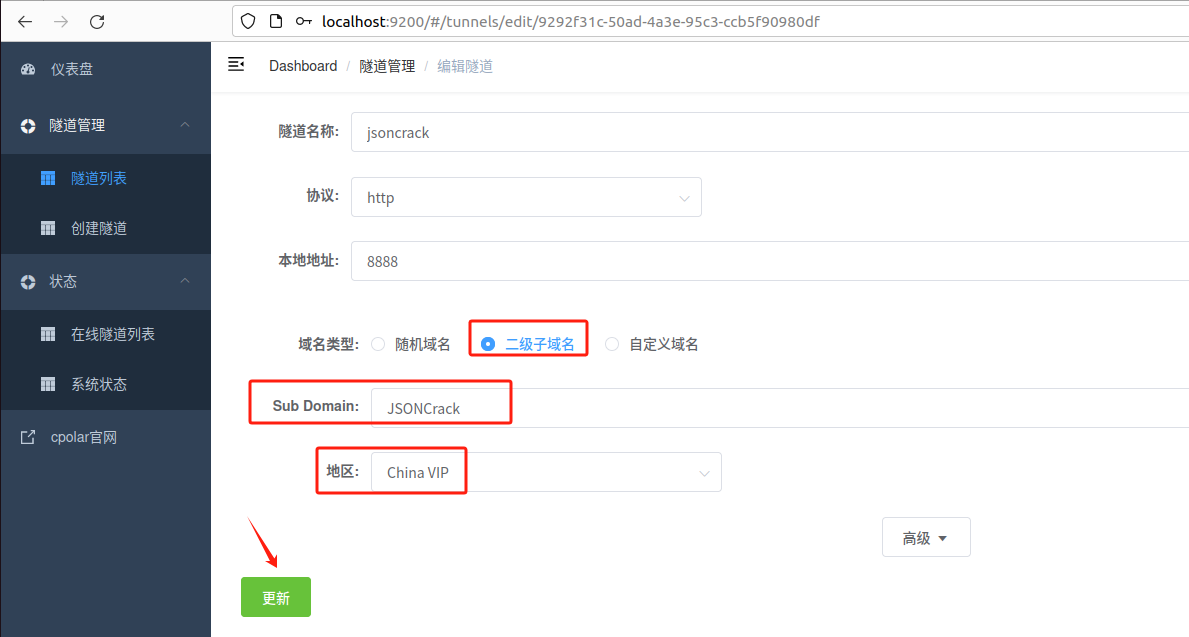
返回登录Cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
点击更新(注意,点击一次更新即可,不需要重复提交)
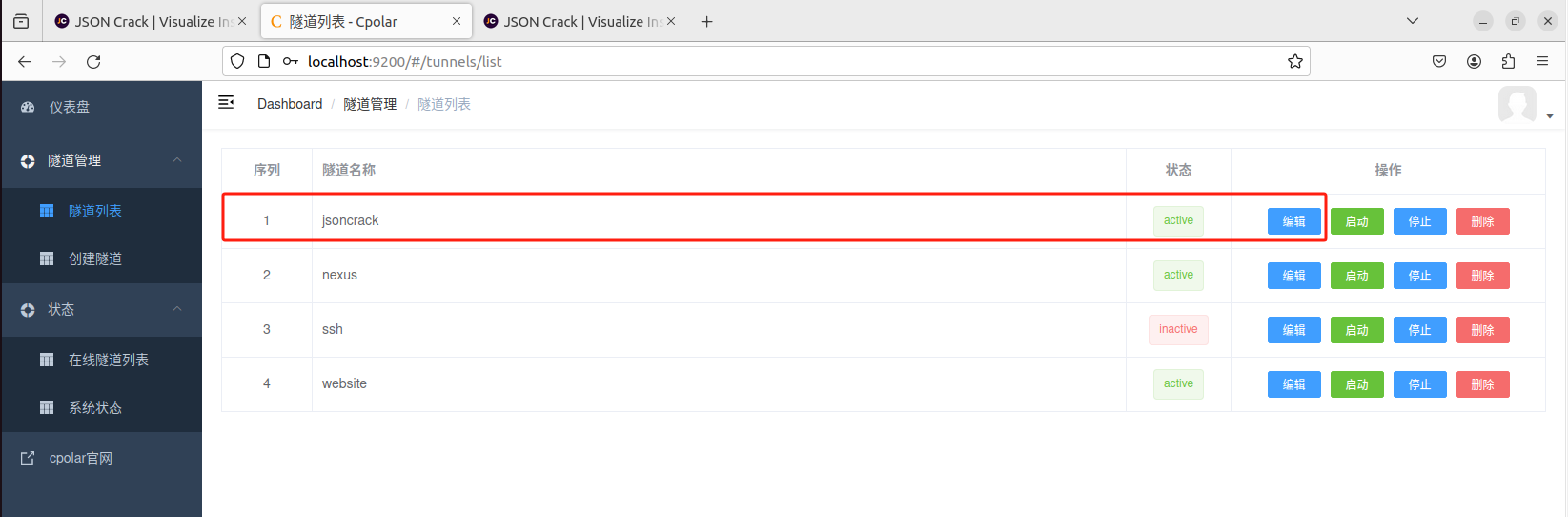
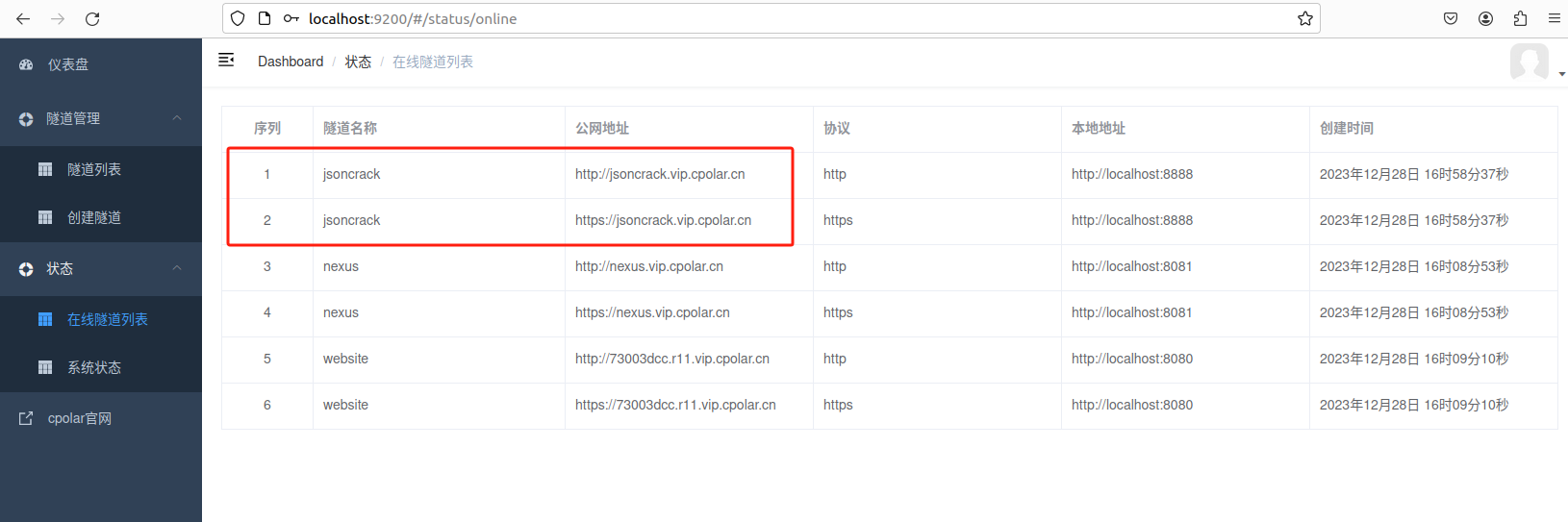
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了固定的二级子域名名称的域名
最后,我们使用固定的公网https地址访问,可以看到访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以远程访问本地 JSONCrack 界面进行数据可视化管理.
这篇关于内网穿透的应用-如何在Linux系统Docker安装JSON Crack并实现远程访问本地数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







