本文主要是介绍华为云DLI Flink作业生产环境推荐配置指导,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 首先客户需要在消息通知服务(SMN)中提前创建一个【主题】,并将客户指定的邮箱或者手机号添加到主题订阅中。这时候指定的邮箱或者手机会收到请求订阅的通知,点击链接确认订阅即可。
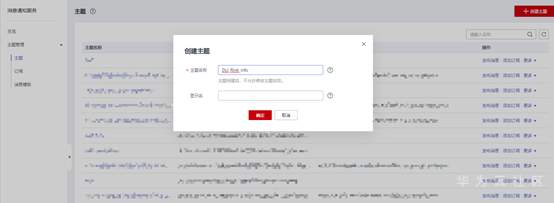
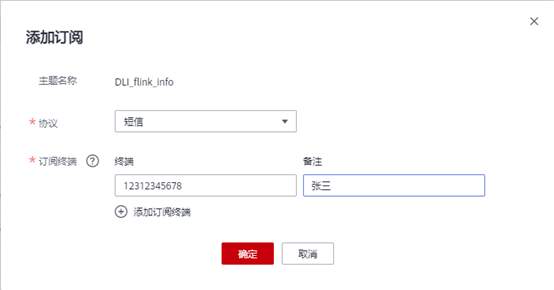
2. 创建Flink SQL作业,编写作业SQL完成后,配置【运行参数】。
2.1 配置作业的【CU数量】、【管理单元】与【最大并行数】,依据如下公式:
CU数量 = 管理单元 + (算子总并行数 / 单TM Slot数) * 单TM所占CU数例如:CU数量为9CU,管理单元为1CU,最大并行数为16,则计算单元为8CU。
如果不手动配置TaskManager资源,则单TM所占CU数默认为1,单TM slot数显示值为0,实际值依据上述公式计算结果为 16÷(9-1)=2。
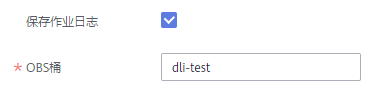
2.2 勾选【保存作业日志】按钮,选择一个OBS桶。如该桶未授权,需点击【立即授权】。此项配置可以在作业异常失败后将作业日志保存到客户的OBS桶下,方便客户定位故障原因。
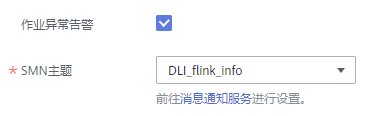
2.3 勾选【作业异常告警】选项,选择前述步骤创建的【SMN主题】。此项配置可以在作业异常情况下,向客户指定邮箱或者手机发送消息通知,方便客户及时感知异常。
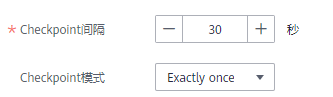
2.4 勾选【开启Checkpoint】选项,依据自身业务情况调整Checkpoint间隔和模式。Flink checkpoint机制可以保证Flink任务突然失败时,能够从最近的Checkpoint进行状态恢复重启。
说明:
- 此处的Checkpoint间隔为两次触发Checkpoint的间隔,执行checkpoint会影响实时计算性能,配置间隔时间需权衡对业务的性能影响及恢复时长,最好大于Checkpoint的完成时间,建议设置为5min。
- Exactly Once模式保证每条数据只被消费一次,At Least Once模式每条数据至少被消费一次,请依据业务情况选择。
2.5 勾选【异常自动恢复】与【从Checkpoint恢复】,根据自身业务情况选择重试次数。
2.6 配置【脏数据策略】,依据自身的业务逻辑和数据特征选择忽略、抛出异常或者保存脏数据。
选择【运行队列】,提交并运行作业。
Flink Jar作业可靠性配置与SQL作业相同,不再另行说明。
3. 登录【云监控服务CES】,在【云服务监控】列表中找到【数据湖探索】服务,在Flink作业中找到目标作业,点击【创建告警规则】。
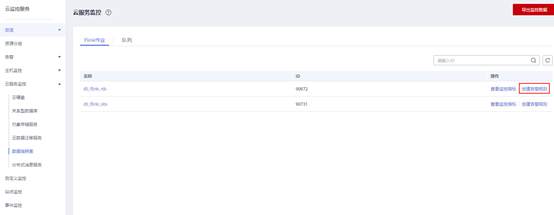
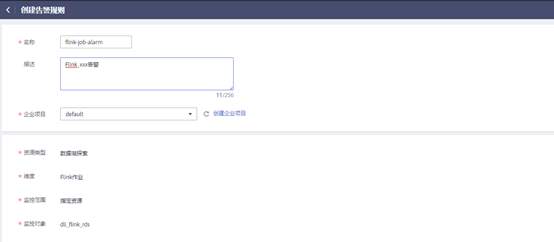
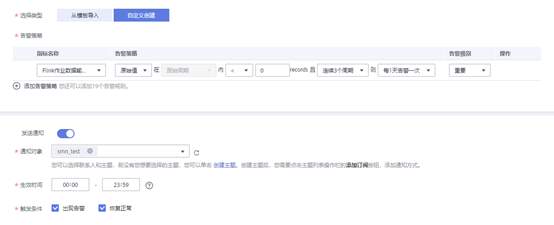
DLI 为Flink作业提供了丰富的监控指标,客户可以依据自身需求使用不同的监控指标定义告警规则,实现更细粒度的作业监控。
监控指标说明见链接
本文由华为云发布。
这篇关于华为云DLI Flink作业生产环境推荐配置指导的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







