本文主要是介绍Go语言基础:闭包_defer_recover,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
主要借鉴七米的博客
文章目录
- 闭包
- defer关键字
- defer执行时机
- 练习
- 面试题
- 内置函数介绍
- panic/recover
- 练习
闭包
先看一个例子:
package mainimport "fmt"func sum012(x,y int)func()int{return func() int {return x+y}
}func main() {f:=sum012(5,6)fmt.Println(f()) //11fmt.Println(sum012(7,8)()) //15
}
再这个例子中,使用了sum012函数进行求和,而返回的是一个匿名函数
在该匿名函数中的作用域里面并没有x和y,于是匿名函数就向上寻找,在参数传递找到了x和y
把函数赋值给f,此时f就是一个闭包.
注意调用的时候的匿名函数的特殊性
变量f是一个函数并且它引用了其外部作用域中的x变量,此时f就是一个闭包。 在f的生命周期内,变量x也一直有效。 示例1
package mainimport "fmt"func sum013(x int)func(int)int{return func(y int)int{x+=yreturn x}
}func main() {var f=sum013(30)fmt.Println(f(20)) //50fmt.Println(f(30)) //80fmt.Println(f(40)) //120var s = sum013(10) //此时f生命周期暂停,s生命周期开始fmt.Println(s(10)) //20
}
实例2:
package mainimport ("fmt""strings"
)// 这是一个添加后缀名的例子
func add13(s string)func (string)string{return func(s2 string)string{if !strings.HasSuffix(s2,s){// 该函数判断的是s是否是在s2的尾部// s是后缀名,s2是文件名return s2+s}else{return s2}}
}
func main() {var f=add13(".jpg")fmt.Println(f("123"))fmt.Println(f("456.jpg"))var z=add13(".txt")fmt.Println(z("hhh.txt"))
}
//123.jpg
//456.jpg
//hhh.txt
示例三
本示例由于一个函数有两个返回值,所以需要两个变量来共同接收:
package mainimport "fmt"func calculate15(x int)(func (int)int,func(int)int){add:=func (y int)int{return x+y}sub:=func(y int)int{return x-y}return add,sub
}func main() {var f1,f2=calculate15(10)fmt.Println(f1(5),f2(10)) //15 0fmt.Println(f1(10),f2(20)) //20 -10
}
闭包其实并不复杂,只要牢记闭包=函数+引用环境。
defer关键字
Go语言中的defer语句会将其后面跟随的语句进行延迟处理。在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句,最先被执行。
package mainimport "fmt"func main() {fmt.Println("Start")defer fmt.Print(1)defer fmt.Print(2)defer fmt.Print(3)fmt.Println("End")
}
//Start
//End
//321
可见,GO是先执行没有defer的,再按照顺序逆序执行defer后面的语句
由于defer语句延迟调用的特性,所以defer语句能非常方便的处理资源释放问题。比如:资源清理、文件关闭、解锁及记录时间等。
defer执行时机
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示: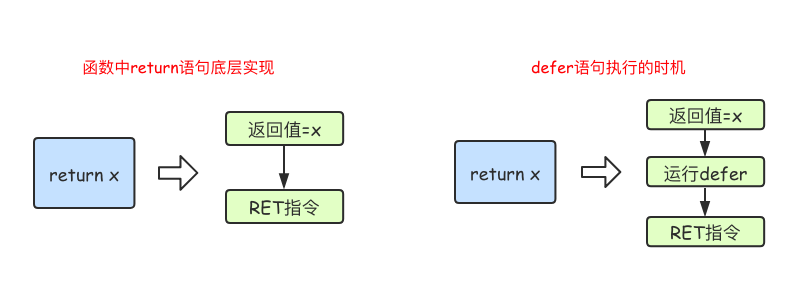
下面的例子
package mainimport "fmt"func test_defer()string{fmt.Println("这是没有defer的语句")defer fmt.Println("这是defer语句")return "这是return"
}
func main() {fmt.Println(test_defer())
}
由于返回值在函数定义的时候已经将该变量进行定义,在执行return的时候会先执行返回值保存操作,而后续的defer函数会改变这个返回值(虽然defer是在return之后执行的,但是由于使用的函数定义的变量,所以执行defer操作后对该变量的修改会影响到return的值
练习
判断,下面的结果:
package mainimport "fmt"func f1() int {x := 5defer func() {x++}()return x
}func f2() (x int) {defer func() {x++}()return 5
}func f3() (y int) {x := 5defer func() {x++}()return x
}
func f4() (x int) {defer func(x int) {x++}(x)return 5
}
func main() {fmt.Println(f1())fmt.Println(f2())fmt.Println(f3())fmt.Println(f4())
}
输出结果是5 6 5 5
先看f3,一开始y=0,x=5.之后被defer,return的是x=5,之后执行了func,但是y并没有被改变,仍然输出了值为5的y
面试题
func calc(index string, a, b int) int {ret := a + bfmt.Println(index, a, b, ret)return ret
}func main() {x := 1y := 2defer calc("AA", x, calc("A", x, y))x = 10defer calc("BB", x, calc("B", x, y))y = 20
}
问,上面代码的输出结果是?(提示:defer注册要延迟执行的函数时该函数所有的参数都需要确定其值)
A 1 2 3
B 10 2 12
BB 10 12 22
AA 1 3 4
内置函数介绍
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,、主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到数组、slice中 |
| panic和recover | 用来做错误处理 |
panic/recover
Go语言中目前(Go1.12)是没有异常机制,但是使用panic/recover模式来处理错误。 panic可以在任何地方引发,但recover只有在defer调用的函数中有效。 首先来看一个例子:
func funcA() {fmt.Println("func A")
}func funcB() {panic("panic in B")
}func funcC() {fmt.Println("func C")
}
func main() {funcA()funcB()funcC()
}
输出:
func A
panic: panic in Bgoroutine 1 [running]:
main.funcB(...).../code/func/main.go:12
main.main().../code/func/main.go:20 +0x98
程序运行期间funcB中引发了panic导致程序崩溃,异常退出了。这个时候我们就可以通过recover将程序恢复回来,继续往后执行。
recover()必须搭配defer使用。defer一定要在可能引发panic的语句之前定义。
例如
package mainimport "fmt"
func First_recover(){fmt.Println("Recover的使用")
}
func A_recover(){defer func() {error := recover()if error != nil {fmt.Println("程序出现了错误,现已恢复")}}()panic("程序有错")
}func main() {First_recover()A_recover()
}
练习
/*
你有50枚金币,需要分配给以下几个人:Matthew,Sarah,Augustus,Heidi,Emilie,Peter,Giana,Adriano,Aaron,Elizabeth。
分配规则如下:
a. 名字中每包含1个'e'或'E'分1枚金币
b. 名字中每包含1个'i'或'I'分2枚金币
c. 名字中每包含1个'o'或'O'分3枚金币
d: 名字中每包含1个'u'或'U'分4枚金币
写一个程序,计算每个用户分到多少金币,以及最后剩余多少金币?
程序结构如下,请实现 ‘dispatchCoin’ 函数
*/
var (coins = 50users = []string{"Matthew", "Sarah", "Augustus", "Heidi", "Emilie", "Peter", "Giana", "Adriano", "Aaron", "Elizabeth",}distribution = make(map[string]int, len(users))
)func main() {left := dispatchCoin()fmt.Println("剩下:", left)
}
答案:
/*
你有50枚金币,需要分配给以下几个人:Matthew,Sarah,Augustus,Heidi,Emilie,Peter,Giana,Adriano,Aaron,Elizabeth。
分配规则如下:
a. 名字中每包含1个'e'或'E'分1枚金币
b. 名字中每包含1个'i'或'I'分2枚金币
c. 名字中每包含1个'o'或'O'分3枚金币
d: 名字中每包含1个'u'或'U'分4枚金币
写一个程序,计算每个用户分到多少金币,以及最后剩余多少金币?
程序结构如下,请实现 ‘dispatchCoin’ 函数
*/
package mainimport "fmt"var (
coins = 50
users = []string{"Matthew", "Sarah", "Augustus", "Heidi", "Emilie", "Peter", "Giana", "Adriano", "Aaron", "Elizabeth",
}
distribution = make(map[string]int, len(users))
)
func dispatchCoin()int{summary:=0for _,s:=range users{sum:=0s_rune:=[]rune(s)for _,c:=range s_rune{f:=string(c)switch f{case "e","E":sum+=1case "i","I":sum+=2case "o","O":sum+=3case "u","U":sum+=4default:continue}}fmt.Printf("%s所花费的coins为:%v\n",s,sum)summary+=sum}return coins-summary
}
func main() {
left := dispatchCoin()
fmt.Println("剩下:", left)
}运行结果:
Matthew所花费的coins为:1
Sarah所花费的coins为:0
Augustus所花费的coins为:12
Heidi所花费的coins为:5
Emilie所花费的coins为:6
Peter所花费的coins为:2
Giana所花费的coins为:2
Adriano所花费的coins为:5
Aaron所花费的coins为:3
Elizabeth所花费的coins为:4
剩下: 10
这篇关于Go语言基础:闭包_defer_recover的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





