本文主要是介绍分布式系统超详解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
常见概念
基本概念
应用/系统
模块/组件
分布式
集群
主/从
中间件
评价指标
可用性
响应时长
吞吐量/并发量
架构演进
单机架构
应用数据分离架构
引入更多的应用服务器结点
读写分离架构
引入缓存--冷热分离的结构
垂直分库
业务拆分--微服务
为了更好地学习Redis,我们将要在这里学习分布式系统.
常见概念
在正式引入分布式架构之前,为避免读者对架构中的概念完全不了解导致低效沟通,优先介绍一些重要的概念.
基本概念
应用/系统
为了完成一整套服务的一个程序或者一组相互配合的程序群.生活例子类比:为了完成一项任务,而搭建的由一个人或者一群互配的人组成的团队.
模块/组件
当应用比较复杂时,为了分离职责,将其中具有清晰职责的,内聚性强的部分,抽象出概念,便于理解.就比如军队为了攻克某据点,将人员分为突击小组,爆破小组,掩护小组,通信小组等.
分布式
系统中的多个模块被部署于不同服务器上,即可以将该系统称为分布式系统.如Web服务器与数据库分别工作在不同的服务器上,或者多台Web服务器被分别部署在不同服务器上.生活例子比如:为了更好地满足现实需要,一个在统一个办公场地的工作小组被分散到不同城市的不同工作场地中进行远程配合完成工作目标.跨主机之间的模块之间的通信基本要借助网络支撑完成.
集群
被部署于多台服务器上的,为了实现特定目标的一个/组特定的组件,整个整体被称为集群.比如多个MySQL工作在不同服务器上,共同提供数据库服务目标,可以成为一组数据库集群.比如:为了解决军队攻克防守坚固的大城市作战目标,指挥部将大批炮兵部队集中起来形成一个炮兵打击集群.
分布式VS集群
通常不用严格区分两者的细微概念,细究的话,分布式强调的是物理形态,即在工作在不同服务器上并且通过网络通信配合完成任务;而集群更加注重逻辑形态,即是否为了完成特定目标.
主/从
集群中,通常有一个程序需要承担更多的职责,被称为主;其它承担附属职责的称为从.比如MySQL集群中,只有一台服务器上的数据库允许数据的写入(增/删/改),其它数据库的数据修改全部要从这台数据库同步而来,把那台数据库称为主库,把其它数据库称为从库.
中间件
一类提供不同应用程序用于相互通信的软件,即处于不同技术,工具和数据库之间的桥梁.类比:一家酒店中,酒席类的业务往往比较大,会有一个采购部,由采购部专职于采买业务,称为厨房和菜市场之间的桥梁.
评价指标
可用性
单位时间内,系统可以正常提供服务的概率/期望. 比如一个系统在一年内,正常提供服务的时间有360天,因此它的可用性就是 360/365.
响应时长
指用户完成输入到系统给用户反应的时长. 通常我们需要衡量的是最长响应时长,平均响应时长和中位数响应时长.这个指标原则上是越小越好,但由于实现上的限制,需要根据具体情况衡量.
吞吐量/并发量
吞吐考察单位时间段内,系统可以成功处理请求的数量.并发量指系统同一时刻支持的请求最高量(衡量系统的处理能力).
架构演进
单机架构
注:以后皆以电商系统来举例子.
单机架构,只有一台服务器,这个服务器负责所有的工作.
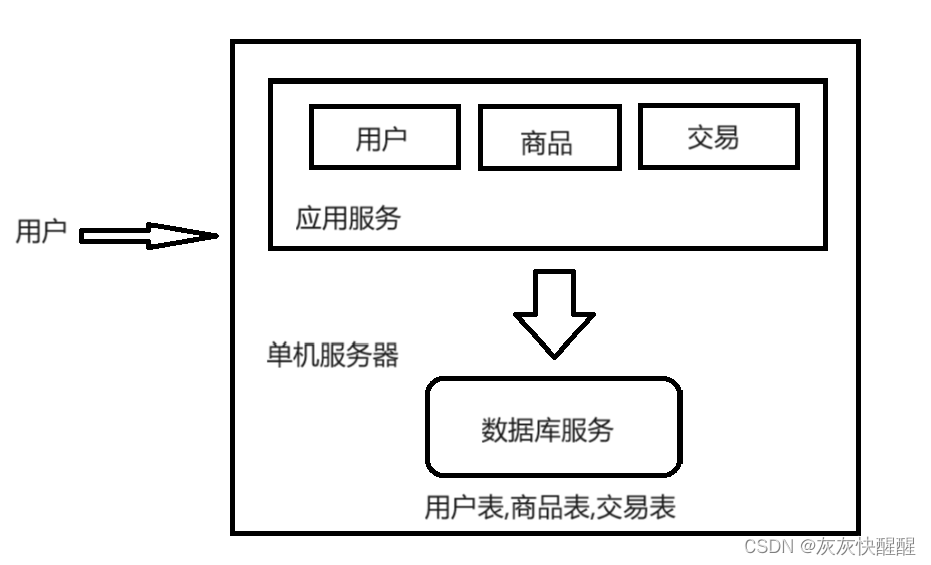
在应用服务中,就涉及到写的服务器程序(C++,Java等开发)写的HTTP服务器.
而在数据库服务中,就是如MySQL之类的. (MySQL是一个客户端服务器结构的程序,本体是MySQL服务器:存储和组织数据的部分).
注意!千万不要瞧不上这个东西. 绝大部分公司的产品,都是这种单机架构. 现在的计算机硬件,发展速度非常快.哪怕只有一台主机,这一台主机的性能也是很高的,可以支持非常高的并发 & 非常大的数据存储.
而如果业务进一步增长,用户量和数据量都水涨船高,一台主机难以应付的时候就需要引入更多的主机/更多的硬件资源.
一台主机的硬件资源是有上限的! 包括但不限于以下几种:(1.CPU 2.内存 3.硬盘 4.网络 5....)
服务器每收到一个请求,都是需要消耗一定的上述资源的. 如果同一时刻,处理的请求多了,此时就可能会导致服务器处理请求的时间变长,甚至出错.
如何处理?
1.开源(简单粗暴,增加更多的硬件资源. 一个主机上面能增加的应急资源也是有限的,取决于主办的能力. 如果一台主机扩展到极限了,但是还不够,就只能引入多台主机了! 不是说新的机器买来就直接可以解决问题了.也需要软件上做出对应的调整和适配. 一旦引入多台主机了,咱们的系统就可以称为是"分布式系统").
2.节流:软件上优化.(各凭本事了,需要通过性能测试,找到是哪个环节出了问题,再去对症下药).
这对于程序员的要求就比较高.
应用数据分离架构
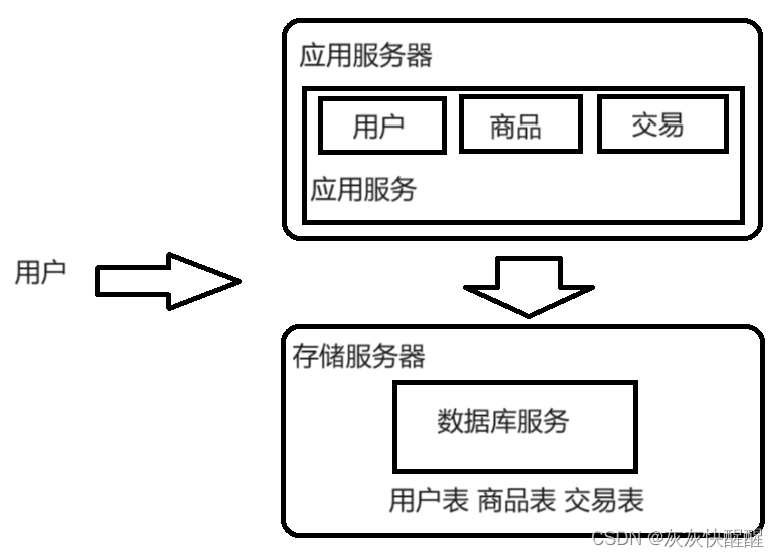
应用服务器:里面可能会包含很多的业务,可能会吃CPU和内存.
数据库服务器:需要更大的硬盘空间,更快的数据访问速度.(可以配置更大硬盘的服务器,甚至还可以上SSD硬盘(固态硬盘)). (1.机械硬盘:便宜,慢 2.固态硬盘:贵,快).
引入更多的应用服务器结点

负载均衡器:就像公司的一个组的领导一样,要负责管理.要负责把任务分配给每个组员.
应用服务器:之前只有一个应用服务器,很容易把CPU和内存吃没,此时应用服务器就顶不住了,引入更多应用服务器,就可以有效解决上述问题. 在上图中,应用服务器看似是两个,实际上可能是多个. 用户的请求, 先达到负载均衡器/网关服务器(单独的服务器). 假设有1w个用户请求,有两个应用服务器.此时按照负载均衡的方式,就可以让每个应用服务器承担5k的访问量.(和之前讲到的多线程有点像).
问题:负载均衡器看起来不是承担了所有的请求吗?这个东西能顶住吗?
负载均衡器,对于请求量的承担能力,要远超过应用服务器的. 负载均衡器,是领导,分配工作.
应用服务器,是组员,执行任务.
是否可能出现,请求量大到负载均衡器也扛不住了呢?
也是有可能的! 可以引入更多负载均衡器(引入多个机房).
读写分离架构
如上面所讨论的,增加应用服务器的数量,确实能够增加对请求的处理量. 但随之而来的,存储数据量也大大增加,因此我们也需要引入更多的存储服务器.

主数据库一般有一个,从数据库可以有多个(一主多从):因为在数据库操作中,写操作比较少,读操作比较多. 同时在数据库中通过负载均衡的方式,让应用服务器进行访问.
引入缓存--冷热分离的结构
数据库有一个天然的问题,那就是访问速度相对较慢. 因此,为了解决这个问题,我们就引入了缓存服务器(这也是Redis的存在位置).(因为缓存的速度比较快). 通过它把数据区分"冷热",热点数据放到缓存中.缓存的访问速度比数据库要快很多了.

存储服务器存储的仍然是完整的全量数据.
此时,缓存服务器就帮助数据库服务器负重前行!! 而缓存服务器只是放一部分热点数据(会被频繁访问到的数据). (二八原则:20%的数据,能够支持80%的访问量,甚至更极端的情况能够达到一九,). 缓存要想快,就要付出一定的代价--小.
垂直分库
引入分布式系统,不光要能够去应对更高的请求量(并发量),同时也要能应对更大的数据量. 那么是否可能出现,一台服务器已经存不下数据了呢? 当然会存在. 虽然一个服务器,存储的数据量可以达到几十个TB,即使如此也可能存储不下,就需要多台主机来存储.

垂直数据库就是针对数据库进行进一步的划分(分库分表). 本来一个数据库服务器.这个数据库服务器上有多个数据库(指的是逻辑上的数据集合,create database 创建的那个东西). 现在就可以引入多个数据库服务器.每个数据库服务器存储一个或者一部分数据库.
如果某个表特别大,大到一台主机存不下,也可以针对表进行划分. 而具体的分库分表如何实践?还是要结合具体业务场景展开.
业务拆分--微服务
之前的应用服务器,一个服务器程序里面做了很多的业务. 这就可能导致这一个服务器的代码越来越复杂. 为了更方便于代码的维护,就可以把这样的一个复杂的服务器,拆分成更多的,功能更单一,但是更小的服务器, 我们称之为微服务.(注意:微服务本质上是在解决"人的问题").
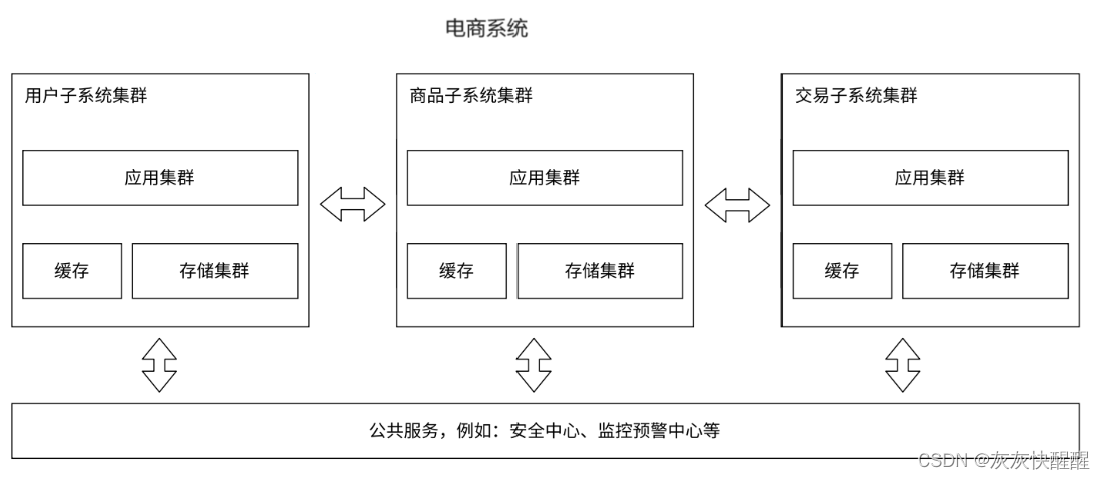
当应用服务器更复杂了,势必就需要更多的人来维护了,当人多了,就需要有配套的管理,把这些人组织好. 划分组织结构,分成多个组,每个组分别配备领导来进行管理. 按照功能,拆分成多组微服务,就可以利于上述人员组织结构的分配了.
引入微服务,解决了人的问题,付出的代价?
1.系统的性能下降:拆出来更多的服务,多个功能之间要更依赖网络通信,网络通信的速度可能是比硬盘还慢的.
2.系统的复杂程度提高,可用性受到影响. 服务器更多了,出现问题的概率就更大了. 这就需要一系列的手段,来保证系统的可用性.
微服务的优势:(1)解决了人的问题;(2)使用微服务,可以更方便于功能的复用.(3)可以给不同的服务进行部署.
这篇关于分布式系统超详解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





