本文主要是介绍数澜数据中台系列(一):你的企业真的需要「数据中台」吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何理解数据中台
在解决你是否需要数据中台这个问题之前,让我们先理理它究竟是什么。
它是工具?是方法?还是组织架构?我的回答是:都不仅仅是。
数据中台包括平台、工具、数据、组织、流程、规范等一切与企业数据资产如何用起来所相关的。
企业所属行业不同,经营策略不同,从而数据场景也千差万别。再加上企业人员运用数据的能力参差不齐,这就导致了每一家企业的数据中台都是独一无二的,不是购买一个所谓的数据中台工具就能解决的。当然合适的工具是可以降低企业应用数据难度的,这是强调的是「合适的」,而不是「高级的」。
既然每一家企业的数据中台都不一样,那市面上是否有成功案例可以借鉴?
有,阿里巴巴是目前成功实施数据中台项目的企业,也是第一个提出数据中台概念的企业,这里有必要简单了解下这段历史: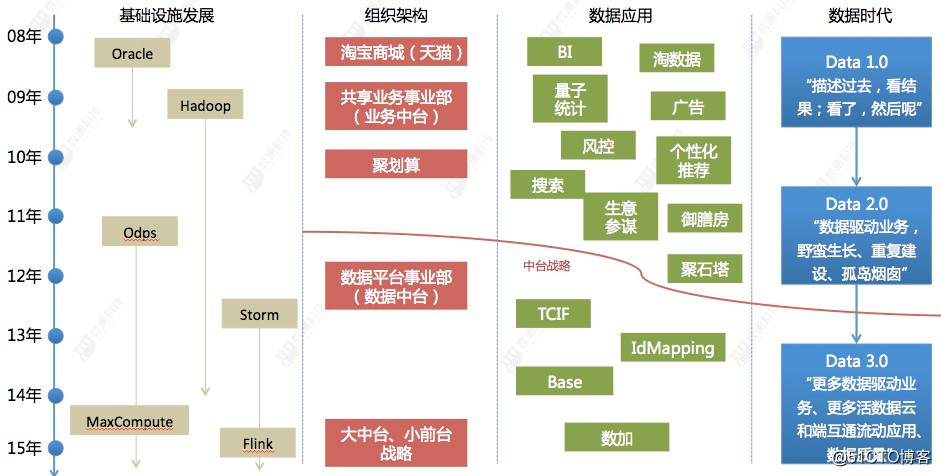
要通过四个维度回顾阿里巴巴在 2015 年之前在数据中台的建设演变,不能再说了
数据中台出现的前提
回顾这段经历你会发现,它的出现基于以下前提:
1)丰富的数据维度
TCIF & IDMAPPING,淘宝消费者信息工厂和用户识别,打通了阿里集团所有相关业务域,建立了几千个标签来刻画用户画像。比如:你的真实性别、购物性别、音乐风格偏爱是「R&B」、你的线上购物行为特征是「爱薅羊毛还是财大气粗」等等。
2)多个大数据场景
数据服务支撑了阿里妈妈、淘宝、天猫、支付宝等多个业务板块的场景,每天都有上亿的调用次数。通过业务效果反馈,进而不断优化调整数据和模型。
根据以上两点,下面列举几个简单的例子:
企业A
主要通过 APP 运营专业类内容收取广告费,提供免费的 WIFI 服务吸引顾客,随着 DAU 的增加,需要给用户提供个性化内容。
大数据场景:目前比较合适的是启动一个内容推荐类的算法项目,但在可见未来的情况下,没有看到更多数据场景。
企业B
主要通过在线下门店和线上互联网的方式进行水果销售,目前门店数量已超过 1000 家。需要用大数据来精细化运营用户和商品,目前已经搭建了大数据平台构建了数仓。
大数据场景:可视化报表(已)、商品猜你喜欢、个性化营销信息推送、商品库存优化、卡劵核销风控等。比较合适的是启动一个数据中台项目。
这里各位可能会有疑问:
1)数据中台和传统数仓的区别是什么?
详见如下:
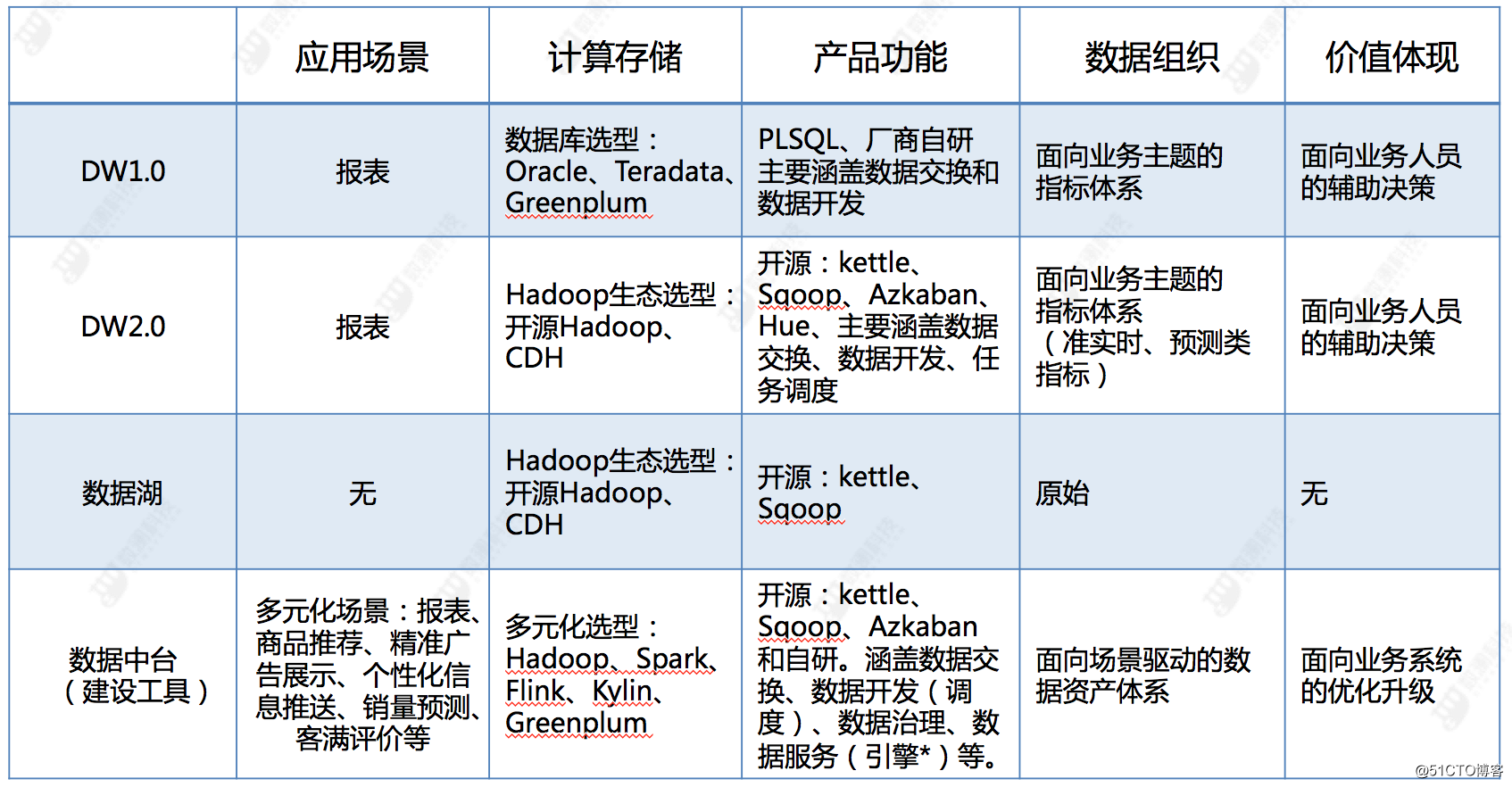
2)已经构建数仓了,数据中台的项目是否会冲突?
中台项目偏重的数据在多场景下的「用」,完全可以基于数仓(指标体系)再次「升级」,所以并不冲突。
企业C
主要通过线下售卖服装盈利,同时运营两个品牌:MINI 1 和 MINI 2。两个品牌的 CRM 分别由不同供应商提供,为了更好的为会员提供服务,故需要打通两个 CRM 中的用户数据。
大数据场景:无,属于业务中台范畴,主要构建统一的用户中心来为 CRM 提供数据。
企业D
多业态集团公司。旗下有图书零售板块,有金融保险业务同时还有多个大型 Shoppingmall。各个业务板块都有自己的数仓和报表,现面向集团需要构建统一的数据管理平台或数据资产管理平台。
大数据场景:这属于典型的数据中台类型项目。
通过以上内容,相信大家对自己的企业是否需要建设数据中台有了初步的认识。当然,在实际判断中还需要更加谨慎,不要被厂商用一些概念所混淆。
看完不过瘾?一个小剧透
另外,一定要持续关注我们后续文章呀 !精彩不容错过!
关于数澜
数澜科技成立于2016年6月,秉承“让企业的数据用起来”的使命,致力于成为客户信赖的数据应用基础设施供应商。2019年初,跻身“杭州准独角兽企业”榜。
自成立之日起,数澜团队即坚持以“数据中台”作为核心战略构建和培养团队。目前已有成员200+,建成以数据科学家、数据产品专家、数据咨询专家及数据可视化专家为核心的数据科技研发团队,核心成员来自阿里、华为、金蝶及运营商等大型B端企业,拥有大数据业务和技术多年实战经验,是国内最早一批大数据服务创新实践者。
目前,数澜已为万科、方太、兴业银行、百果园、中信云网、时尚集团、温州检察院、喜茶、视源科技等多家行业头部企业和政府客户,提供了数据中台建设和数据资产开发服务,并基于数栖帮助企业持续挖掘数据资产,赋能业务创新。
转载于:https://blog.51cto.com/13936314/2343672
这篇关于数澜数据中台系列(一):你的企业真的需要「数据中台」吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








