本文主要是介绍一起talk C栗子吧(第一百二十九回:C语言实例--C程序内存布局一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
各位看官们,大家好,上一回中咱们说的是查看当前进程信息的例子,这一回咱们说的例子是:C程序内存布局。闲话休提,言归正转。让我们一起talk C栗子吧!
看官们,我们编写的每一个C程序都会被加载到内存中运行,那么C程序在内存中是如何存放的呢?我们今天一起来看看C程序在内存中的布局。
C程序在内存中主要有四个分区,它们分别是代码区,数据区,堆区和栈区。这些区域从低地址向高地址依次排列。为了大家更加直观地了解内存布局,我画了一张图供大家参考:
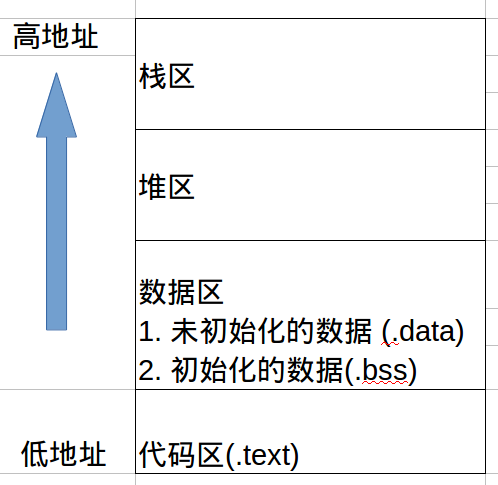
我们接下来依次介绍一下这些区域的作用和内容。
- 代码区:
代码区也叫正文区或者文本区。另外,在英文资料中经常使用 text section来表示该区域,因此有些中文资料叫文本段或者代码段。其英文名是.text。总之,不管是中文还是英文,只是名称和叫法不同而已。代码区里存放着程序的代码,当然了,这里的代码不是我们用C语言写的代码,而是能被CPU执行的指令,也就是我们写的C程序经过编译后形成的CPU指令。
- 数据区:
数据区也叫数据段,在英文资料中经常使用data section来表示该区域。依据区域中数据是否被初始化,它又可以分为两个部分,一部分存放未初始化的数据,该区域的英文名称是.bss;另外一部分存放初始化的数据,该区域的英文名称是.data。
- 堆区:
堆区是大小可变的区域,程序中动态分配的内存位于该区域内。比如我们在程序中使用malloc分配的内存区域就位于该区域中。
- 栈区:
栈区也是大小可变的区域,该区域中存放着程序中与函数调用相关的信息。因为对该区域的操作使用了栈“先进后出”的原理,所以取名叫栈区。
看官们,是不是觉得有些抽象呢,其实这些内容属于理论,理论嘛总是抽象的。不过,接下来咱们通过实际的例子来让大家亲身体验一下。我们使用最经典的“hello world程序”来给大家做示范。
#include <stdio.h>int main()
{printf("hello world \n");return 0;
}我们把该hello world程序保存到文件中,编译该文件并且生成可以执行文件s。然后通过readelf工具来查看可执行文件中的各个区域(section)。详细的结果如下:
readelf -S s //查看可执行文件中的各个区域
There are 30 section headers, starting at offset 0x1178:Section Headers:[Nr] Name Type Addr Off Size ES Flg Lk Inf Al[ 0] NULL 00000000 000000 000000 00 0 0 0[ 1] .interp PROGBITS 08048154 000154 000013 00 A 0 0 1[ 2] .note.ABI-tag NOTE 08048168 000168 000020 00 A 0 0 4[ 3] .note.gnu.build-i NOTE 08048188 000188 000024 00 A 0 0 4[ 4] .gnu.hash GNU_HASH 080481ac 0001ac 000020 04 A 5 0 4[ 5] .dynsym DYNSYM 080481cc 0001cc 000050 10 A 6 1 4[ 6] .dynstr STRTAB 0804821c 00021c 00004a 00 A 0 0 1[ 7] .gnu.version VERSYM 08048266 000266 00000a 02 A 5 0 2[ 8] .gnu.version_r VERNEED 08048270 000270 000020 00 A 6 1 4[ 9] .rel.dyn REL 08048290 000290 000008 08 A 5 0 4[10] .rel.plt REL 08048298 000298 000018 08 A 5 12 4[11] .init PROGBITS 080482b0 0002b0 000023 00 AX 0 0 4[12] .plt PROGBITS 080482e0 0002e0 000040 04 AX 0 0 16[13] .text PROGBITS 08048320 000320 000192 00 AX 0 0 16[14] .fini PROGBITS 080484b4 0004b4 000014 00 AX 0 0 4[15] .rodata PROGBITS 080484c8 0004c8 000014 00 A 0 0 4[16] .eh_frame_hdr PROGBITS 080484dc 0004dc 00002c 00 A 0 0 4[17] .eh_frame PROGBITS 08048508 000508 0000b0 00 A 0 0 4[18] .init_array INIT_ARRAY 08049f08 000f08 000004 00 WA 0 0 4[19] .fini_array FINI_ARRAY 08049f0c 000f0c 000004 00 WA 0 0 4[20] .jcr PROGBITS 08049f10 000f10 000004 00 WA 0 0 4[21] .dynamic DYNAMIC 08049f14 000f14 0000e8 08 WA 6 0 4[22] .got PROGBITS 08049ffc 000ffc 000004 04 WA 0 0 4[23] .got.plt PROGBITS 0804a000 001000 000018 04 WA 0 0 4[24] .data PROGBITS 0804a018 001018 000008 00 WA 0 0 4[25] .bss NOBITS 0804a020 001020 000004 00 WA 0 0 1[26] .comment PROGBITS 00000000 001020 00004f 01 MS 0 0 1[27] .shstrtab STRTAB 00000000 00106f 000106 00 0 0 1[28] .symtab SYMTAB 00000000 001628 000430 10 29 45 4[29] .strtab STRTAB 00000000 001a58 00024c 00 0 0 1
Key to Flags:W (write), A (alloc), X (execute), M (merge), S (strings)I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)O (extra OS processing required) o (OS specific), p (processor specific)从上面的结果中我们可以看到,可执行文件中一共有30个区域,我们只看最重要的区域,其它的区域暂时忽略掉。代码区(.text)位于第14号区域中,数据区中的初始化区域(.data)位于第25号区域中,数据区中的未初始化区域(.bss)位于第26号区域中,由此可见它们还是邻居呢。
这时有看官提问了,怎么没有看到堆区和栈区呢?这位看官问的好,堆区和栈区需要在程序运行才能体现出来,这个程序只是静态的,还没有运行,所以不能通过工具查看到堆区和栈区。
看官们,最后我再补充一下,我们在这里说的内存布局是指内存的逻辑空间,或者说内存的虚拟地址空间,而不是内存的物理空间或者说内存的物理地址空间。在Linux系统中我们只能操作内存的逻辑空间,我们通常说的内存地址是内存的虚拟地址,内存的物理地址由Linux内核来管理,我们是不能直接访问该物理地址的,这样做一方面可以减少应用程序开发人员的负担,另一方面可以更加有效地管理内存空间。
各位看官,关于C程序内存布局的例子咱们就说到这里。欲知后面还有什么例子,且听下回分解 。
这篇关于一起talk C栗子吧(第一百二十九回:C语言实例--C程序内存布局一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






