本文主要是介绍【更新】数字金融与企业ESG表现:效应、机制与“漂绿”检验数据集(2011-2022年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参照温亚东(2024)的做法,本团队对来自统计与决策《数字金融与企业ESG表现:效应、机制与"漂绿"检验》一文中的基准回归部分进行复刻

一、数据介绍
数据名称:数字金融与企业ESG表现
参考期刊:《统计与决策》
数据年份:2011-2022年
数据范围:A股上市公司
有效样本:33485条
数据来源:上市公司年报、华证ESG、北大数字普惠金融
数据整理:自主整理,内含原始数据、dofile和基准回归
二、数据指标
| 企业ESG表现 | 华证指数ESG评级的季度评级数据取平均值 |
| 数字金融 | 数字普惠金融省级总指数除以100 |
| 数字金融广度 | 数字普惠金融广度分指数除以100 |
| 数字金融深度 | 数字普惠金融深度分指数除以100 |
| 数字化程度 | 数字普惠金融数字化程度分指数除以100 |
| 企业规模 | 总资产的自然对数 |
| 资产负债率 | 总负债与总资产之比 |
| 经营现金流 | 经营活动现金流量净额与总资产之比 |
| 资产报酬率 | 税后净利润与期末总资产之比 |
| 企业年龄 | 观测年份与成立年份之差加1的自然对数 |
| 股权性质 | 国有企业取值为1,否则为0 |
| 股权集中度 | 第一大股东持股比例 |
| 两职合一 | 董事长与总经理为同一人取值为1,否则为0 |
| 董事会规模 | 董事会人数的自然对数 |
三、参考文献
温亚东,陈艳.数字金融与企业ESG表现:效应、机制与“漂绿”检验[J].统计与决策,2024,40(01):142-147.
中间机制
➤数字金融通过提高环境合规性提升企业ESG表现
➤数字金融通过缓解融资约束提升企业ESG表现
➤数字金融通过减少委托代理提升企业ESG表现
四、数据概览
基本数据
处理代码

描述性统计

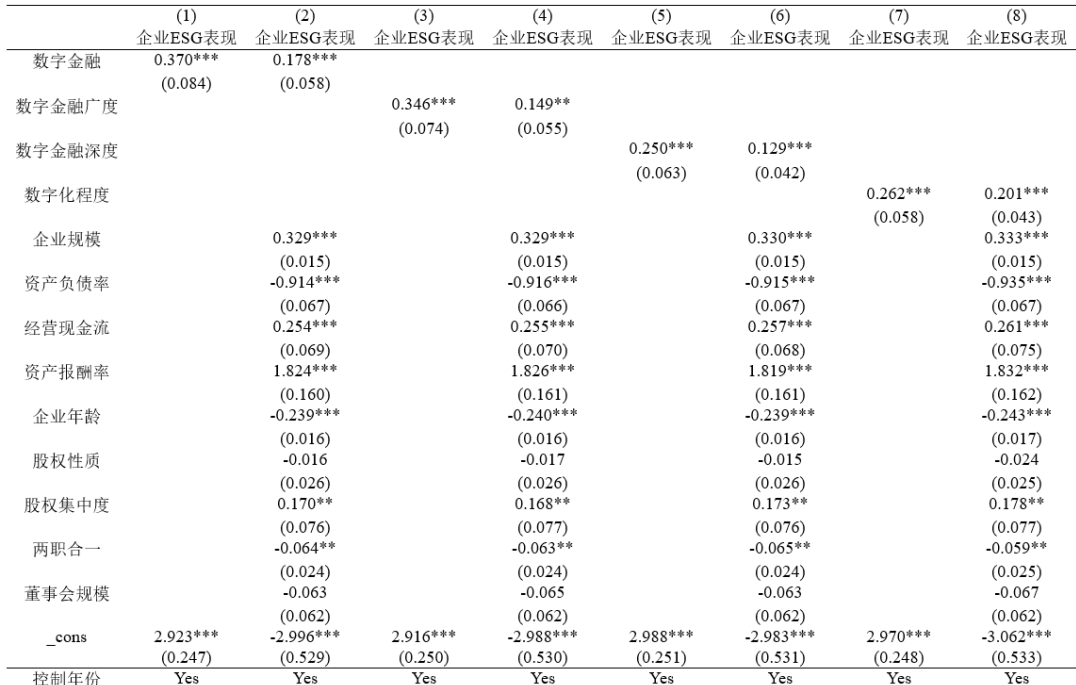
基准回归
五、下载链接
参考文献:https://download.csdn.net/download/T0620514/88944234
基础数据:https://download.csdn.net/download/T0620514/88944276
处理代码:https://download.csdn.net/download/T0620514/88944275
这篇关于【更新】数字金融与企业ESG表现:效应、机制与“漂绿”检验数据集(2011-2022年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






