本文主要是介绍小文件问题及GlusterFS的瓶颈,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01海量小文件存储的挑战
为了解决海量小文件的存储问题,必须采用分布式存储,目前分布式存储主要采用两种架构:集中式元数据管理架构和去中心化架构。
(1)集中式元数据架构:
典型的集中式元数据架构的分布式存储有GFS,HDFS,MooseFs等。其采用的典型架构如下图1所示:
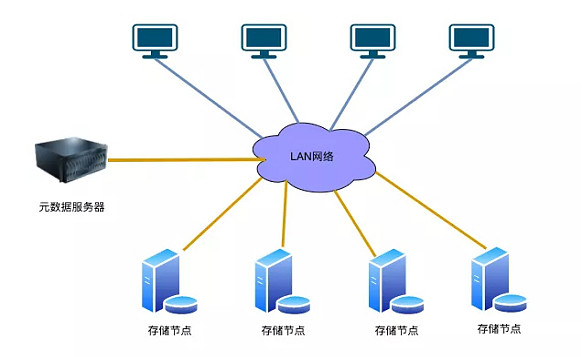
图1 集中式元数据架构
此架构主要包含3个部分:
1)客户端:主要用于提供访问分布式存储系统的接口;
2) 元数据服务器:主要用于存放分布式存储系统的命名空间和文件的一些元数据信息。
3)存储服务器: 主要负责存储文件的具体数据。
使用集中式的元数据管理的方式,其主要优点如下:
1) 元数据的操作性能高: 存储系统的命令空间和文件的元数据都存放在元数据服务器上,元数据操作如list directory和create file等元数据的操作性能会比较高;
2) 扩容时不需要数据迁移:元数据服务器上存放有所有文件的位置信息,在集群需要扩容增加新的节点时,这些位置信息不需要变动,因此集群在扩容时不需要进行数据迁移。
其主要缺点如下:
1) 元数据节点是瓶颈:客户端在访问文件数据之前通常都需要到元数据节点上查询文件的位置信息,因此元数据节点不可避免地成为了整个系统的性能瓶颈。
2) 文件的数量受限:为了提高性能,元数据节点中的数据一般都会保存到内存中,而元数据节点的内存不是无限增长的。
基于以上缺点,集中式的元数据管理方式非常不适合于海量小文件的存储。
(2) 去中心化架构:
为了解决集中式元数据架构的问题,去中心化架构的分布式存储产生,典型的去中心化分布式存储有GlusterFs,Ceph等。其采用的典型的架构如下图2所示:
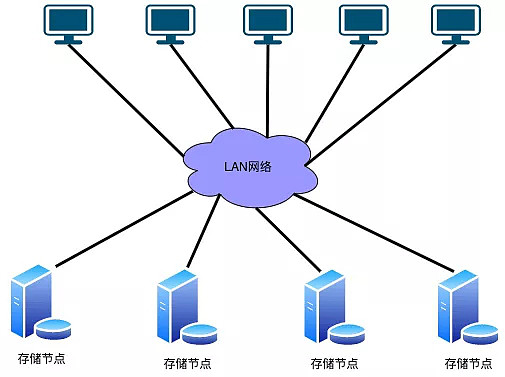
图2 去中心化元数据架构
此架构主要包含3个部分:
1) 客户端: 主要用于提供访问分布式存储系统的接口。
2) 存储服务器:主要负责存储文件的具体数据和元数据。
去中心化架构没有单独的元数据节点去保存文件的命名空间和元数据,元数据依然存储在存储节点上,文件的寻址一般采用DHT(一致性HASH)的方式计算。此架构一般会将多个存储节点进行逻辑分组,组内复制保证数据可靠性,因此会有可选的中心端服务器保存整个集群的存储节点以及分组信息。例如Ceph使用Ceph monitor保存整个集群的成员和状态信息(不保存文件信息),而GlusterFs选择将这些信息存放在所有的存储节点上。
使用去中心化的的方式,其主要优点如下:
1)无单点的性能瓶颈: 没有单独的元数据节点,客户端可以直接通过Hash的方式寻址文件,直接到存储节点上访问。
2) 文件的数量几乎不受限制: 没有单独的元数据节点,理论上文件的数量不受中心端节点容量的限制。
3) 读写性能更高: 读写请求不用到元数据节点上寻址而采用Hash计算的方式,理论上性能更高。
从以上优点可以得出去中心化的架构还是比较适合海量小文件的存储。
02系统设计
目前业界解决海量小文件存储主要有以下的解决几种优化方式:
1) 硬件优化: 海量小文件的读写请求,瓶颈一般在机械硬盘上。硬件优化主要是采用支持随机读写的SSD硬盘代替机械硬盘,可以显著提高海量小文件的读写性能。但是考虑到成本因素,在数据量很大的情况下SSD硬盘一般只会在系统做作为Cache存在。
2) 文件元数据管理优化:分布式存储系统中文件的元数据包含文件的位置信息,文件的size,创建时间等。在读写小文件之前,都需要先得到文件的元数据信息,例如需要得到文件的位置信息才能到对应的存储节点上读写文件数据,只有拿到文件的size才能知道需要读取数据的长度。为了减小访问元数据的开销,应该尽量减少元数据的数量,元数据的数量越少,cache命中率越高,性能越高。
3) 小文件合并成大文件: 通过将大量的小文件合并成一个大文件,可以显著减少文件的数量,也就减少了元数据的数量,元数据的查询会更快。对于大文件机械硬盘可以做到顺序读写,可以显著降低硬盘的负载GLuste
GlusterFS的性能问题
GlusterFS在海量小文件场景的优势和劣势
GlusterFS系统的metadata跟数据存放在一起,没有像业界的其它分布式文件系统一样采用集中式的metadata服务。这样的架构在海量小文件场景有优势,也有劣势。
- 无中心架构优势1)对于lookup操作,在server端会有最后落盘文件的元数据和分布的缓存,这样在open操作时候可以直接从缓存读取,不需要再操作一次磁盘。而对metadata与data分离的文件系统,lookup在metadata服务上进行,open或者读写时候,需要去读取一次disk查找文件的元数据。
2) metadata和数据结合紧密,理论上扩展更为线性。添加节点时,该节点的所有metadata都在新增的节点上。 - 无中心架构劣势
1)在进行类似ls这样的目录遍历相关操作时,由于Gluster没有集中式的metadata服务,需要遍历所有brick相应的目录取出相关的文件列表,导致ls或者find等遍历操作会变成非常慢,这个问题在gluster brick数量多或者文件数量多时候会比较严重。
2) Gluster在每一个brick节点都建立了隐藏目录.glusterfs,该目录是本机所有的一般文件的硬链接,和目录等文件的软连接。使得Gluster对于后端文件系统的inode数量翻倍。
1、元数据性能
GlusterFS使用弹性哈希算法代替传统分布式文件系统中的集中或分布式元数据服务,这个是GlusterFS最核心的思想,从而获得了接近线性的高扩展性,同时也提高了系统性能和可靠性。GlusterFS使用算法进行数据定位,集群中的任何服务器和客户端只需根据路径和文件名就可以对数据进行定位和读写访问,文件定位可独立并行化进行。
这种算法的特点是,给定确定的文件名,查找和定位会非常快。但是,如果事先不知道文件名,要列出文件目录(ls或ls -l),性能就会大幅下降。对于Distributed哈希卷,文件通过HASH算法分散到集群节点上,每个节点上的命名空间均不重叠,所有集群共同构成完整的命名空间,访问时使用HASH算法进行查找定位。列文件目录时,需要查询所有节点,并对文件目录信息及属性进行聚合。这时,哈希算法根本发挥不上作用,相对于有中心的元数据服务,查询效率要差很多。
从我接触的一些用户和实践来看,当集群规模变大以及文件数量达到百万级别时,ls文件目录和rm删除文件目录这两个典型元数据操作就会变得非常慢,创建和删除100万个空文件可能会花上15分钟。如何解决这个问题呢?我们建议合理组织文件目录,目录层次不要太深,单个目录下文件数量不要过多;增大服务器内存配置,并且增大GlusterFS目录缓存参数;网络配置方面,建议采用万兆或者InfiniBand。从研发角度看,可以考虑优化方法提升元数据性能。比如,可以构建全局统一的分布式元数据缓存系统;也可以将元数据与数据重新分离,每个节点上的元数据采用全内存或数据库设计,并采用SSD进行元数据持久化。
2、小文件问题
理论和实践上分析,GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。海量小文件LOSF问题是工业界和学术界公认的难题,GlusterFS作为通用的分布式文件系统,并没有对小文件作额外的优化措施,性能不好也是可以理解的。
对于LOSF而言,IOPS/OPS是关键性能衡量指标,造成性能和存储效率低下的主要原因包括元数据管理、数据布局和I/O管理、Cache管理、网络开销等方面。从理论分析以及LOSF优化实践来看,优化应该从元数据管理、缓存机制、合并小文件等方面展开,而且优化是一个系统工程,结合硬件、软件,从多个层面同时着手,优化效果会更显著。GlusterFS小文件优化可以考虑这些方法,这里不再赘述,关于小文件问题请参考“海量小文件问题综述”一文。
更多GlusterFS缺点分析_glusterfs 间接读不到-CSDN博客
由于Gluster在设计上并没有针对小文件的提供特别的优化,使用系统参数调优的效果终究有限,如果希望进一步提升小文件性能,还是需要从软件代码层面入手,对Gluster进行优化,可以考虑的优化方向包括:
- 合并小文件,小文件合并存储是目前优化LOSF问题最为成功的策略,已经被包括Facebook Haystack和淘宝TFS在内多个分布式存储系统采用。它通过多个逻辑文件共享同一个物理文件,将多个小文件合并存储到一个大文件中,实现高效的小文件存储。这种机制对于WORM(Write Once Read Many)模式的分布式存储系统非常适合,可以显著提升系统的读性能。
- 增加元数据服务,在服务端增加内存级的持久元数据,可以有效提高小文件读写IOPS、多级目录下的文件访问加速、海量目录项读取加速。可以显著增加系统ls等操作的性能。
- 针对小文件增加cache,可以显著增加系统的读性能。
- 针对Gluster通信进行优化,减少网络交互次数,可以提升系统OPS,减少延时
这篇关于小文件问题及GlusterFS的瓶颈的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






