本文主要是介绍第15章——西瓜书规则学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.序贯覆盖
序贯覆盖是一种在规则学习中常用的策略,它通过逐步构建规则集来覆盖训练数据中的样本。该策略采用迭代的方式,每次从训练数据中选择一部分未被覆盖的样本,学习一条能够覆盖这些样本的规则,然后将这条规则加入到规则集中。接下来,从训练数据中去除已被覆盖的样本,重复上述过程,直到所有样本都被覆盖或达到其他停止条件。
在序贯覆盖中,可以采用自底向上或自顶向下的方法来构建规则。
(1)自顶向下
自顶向下的方法则是从较为一般的规则开始,然后逐渐添加更具体的条件来缩小规则的覆盖范围。在序贯覆盖中,自顶向下意味着初始规则是非常宽泛的,能够覆盖大量的样本。然后,算法会逐步添加条件或约束,以缩小规则的适用范围并提高规则的准确性。
(2)自底向上
自底向上的方法从具体的、特殊的规则开始,然后逐步合并或泛化这些规则,以扩大它们的覆盖范围。在序贯覆盖的上下文中,自底向上意味着初始规则是基于训练数据中的具体样本或条件构建的。这些规则可能非常具体,仅适用于少数样本。然后,算法会尝试合并这些规则,通过去除冗余条件或引入更一般的条件来扩大规则的适用范围。
第一种策略是覆盖范围从大往小搜索规则,第二种策略则相反;前者通常更容易产生泛化性能较好的规则,而后者则更适合于训练样本较少的情形,此外,前者对噪声的鲁棒性比后者要强得多.因此,在命题规则学习中通常使用第一种策略,而第二种策略在一阶规则学习这类假设空间非常复杂的任务上使用较多。
然而,序贯覆盖方法可能会受到贪心搜索的影响,即每次只选择当前最优的规则进行覆盖,而忽略了其他可能更优的规则组合。为了解决这个问题,可以采用集束搜索(beam search)的策略进行改进。集束搜索通过维护一个候选列表(集束),在每一步扩展最有希望的节点,从而考虑了更多的搜索空间,避免了陷入局部最优解。
2.剪枝优化
(1)预剪枝
预剪枝的核心思想是在决策树或规则生成过程中,对每个节点或规则在划分前进行估计。如果当前节点或规则的划分不能显著提升模型的泛化性能,则停止划分并将当前节点标记为叶节点,或将当前规则视为已完成。这有助于减少模型的复杂性,避免对训练数据的噪声或特定特征的过度拟合。
在CN2算法中,预剪枝可以通过似然率统计量(Likelihood Ratio Statistics,LRS)等统计显著性检验方法来实现。这种方法涉及比较当前规则或节点划分前后的模型性能。具体来说,它比较了包含当前划分和不包含当前划分的模型在训练数据上的似然性。如果LRS超过这个阈值,则认为当前规则或划分对模型有显著贡献,应保留。否则,应进行剪枝。
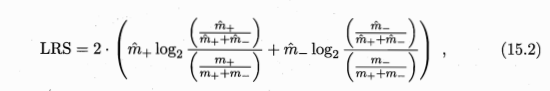
(2)后剪枝
REP:
在每一轮穷举所有可能的剪枝操作,然后用验证集对剪枝产生的所有候选规则集进行评估,保留最好的那个规则集进行下一轮剪枝,如此继续,直到无法通过剪枝提高验证集上的性能为止.
REP剪枝通常很有效[Brunk and Pazzani,1991],但其复杂度是,m为训练样例数目.
IREP
IREP将复杂度降到.
IREP算法采用了增量式的方法,这意味着它不是一次性生成整个规则集,而是逐步构建规则集,每次只添加一条规则。在生成每条规则之前,IREP都会将当前的样例集划分为训练集和验证集。然后,它会在训练集上生成一条规则,并立即在验证集上对其进行剪枝。这种即时剪枝的方式可以确保每条规则都是经过优化的,且不会引入不必要的复杂性。
例如,我们正在构建一个垃圾邮件分类器,将电子邮件分为“垃圾邮件”或“非垃圾邮件”。我们的数据集包括某些关键词的存在、电子邮件长度和发送时间等特征。
-
初始数据集:我们从1000封电子邮件开始,500封标为垃圾邮件,500封标为非垃圾邮件。
-
第一次迭代:
- 数据划分:我们将数据集划分,使用800封电子邮件进行训练,200封进行验证。
- 生成规则:在训练集上,IREP生成了一条规则:“如果电子邮件中包含'free'和'money',则分类为垃圾邮件。”
- 剪枝规则:在验证集上的测试显示,包括'money'并没有显著提高准确性但降低了泛化能力。因此,我们将条件剪枝为“如果电子邮件中包含'free',则分类为垃圾邮件。”
- 添加规则:被剪枝的规则被添加到我们的模型中。
-
后续迭代:
- 过程重复,每次使用减少的数据集(排除已经被之前规则分类的电子邮件),专注于捕捉垃圾邮件的不同特征。
- 假设下一条生成的规则涉及电子邮件长度,剪枝后,它如果电子邮件异常短并且在凌晨2点到5点之间发送,则将电子邮件分类为垃圾邮件。
-
最终结果:我们最终得到了一组简单的、经过剪枝的规则,这些规则共同很好地覆盖了垃圾邮件的特征,同时保持了对新电子邮件的泛化能力。
通过IREP的改进:
IREP的增量和剪枝方法确保添加到模型中的每条规则都是必要和有效的。通过使用单独的验证集验证和剪枝规则,它避免了对训练数据的过拟合,这是复杂模型中的常见问题。这种有条不紊地生成和验证规则的方法导致了一个更健壮、更具泛化能力的垃圾邮件分类器。
RIPPER
它结合了IREP(Incremental REP)的增量式学习策略与更高级的后处理优化手段。以下是RIPPER相对于其前身算法(如REP和IREP)的主要改进:
1. 优化的剪枝策略
RIPPER不仅采用了IREP的即时剪枝策略,还在剪枝过程中引入了更精细的评估机制。它不仅仅基于验证集上的错误率来剪枝规则,还可能考虑其他性能指标:![]()
2. 规则集后处理
除了对单条规则进行剪枝外,RIPPER还对整个规则集进行后处理优化。这包括合并相似的规则、删除冗余规则以及根据某种准则(如规则的覆盖度或准确性)对规则进行排序。这些步骤有助于进一步简化规则集,提高其可读性和可解释性。
3.更复杂的停止条件
IREP通常基于错误率的减少来决定何时停止迭代。然而,这种方法可能会导致生成的规则集过于庞大,包含许多冗余或不必要的规则。相比之下,RIPPER采用了更复杂的停止条件。除了考虑错误率的减少外,RIPPER还可以考虑其他因素,如规则集的简洁性、规则的覆盖度或泛化能力等。例如,如果添加新规则不再显著提高性能,或者规则集变得过于复杂,RIPPER可能会提前停止迭代。这种更灵活的停止条件使得RIPPER能够在迭代过程中更有效地平衡规则集的准确性和简洁性。
4. 对已有规则集的有效利用
在IREP中,每次迭代都是基于当前的样本集来生成新的规则,而已有的规则集在后续迭代中的利用有限。然而,在RIPPER中,已有的规则集被更有效地利用起来。在每次迭代中,RIPPER会基于当前的规则集和剩余的样本集来生成新的规则,并利用已有的规则集对新规则进行评估和优化。这种对已有规则集的有效利用使得RIPPER能够在迭代过程中逐步积累知识,并生成更准确、更稳定的规则集。
3.一阶规则学习
一阶归纳学习器(FOIL)是一种规则学习算法,它从一组示例中生成一阶逻辑规则。一阶逻辑允许表示实体之间的复杂关系,使得FOIL适用于涉及关系数据的任务,如关系数据库。
4.归纳逻辑程序设计(ILP)
归纳逻辑程序设计(ILP)是机器学习的一个子领域,专注于从示例和背景知识中学习逻辑程序。它结合了人工智能(AI)和逻辑程序设计的技术,旨在构建一个逻辑程序,该程序在给定背景知识的约束下解释所提供的示例。
这篇关于第15章——西瓜书规则学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!