本文主要是介绍机器学习-pytorch1(持续更新),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一节我们学习了机器学习的线性模型和非线性模型的机器学习基础知识,这一节主要将公式变为代码。
代码编写网站:https://colab.research.google.com/drive
学习课程链接:ML 2022 Spring
1、Load Data(读取数据)
这需要用到pytorch里面的两个函数Dataset和Dataloader
torch.utils.data.Dataset
torch.utils.data.DataLoaderDataset:是用来存储数据样本和期望值
dataset = MyDataset(file)Dataloader:批量对数据进行分组,启用多处理
dataloader = DataLoader(dataset, batch_size, shuffle=True)// 其中对于shuffle的取值,True表示训练,false表示测试
关于Dataset和Dataloader的关系如下:

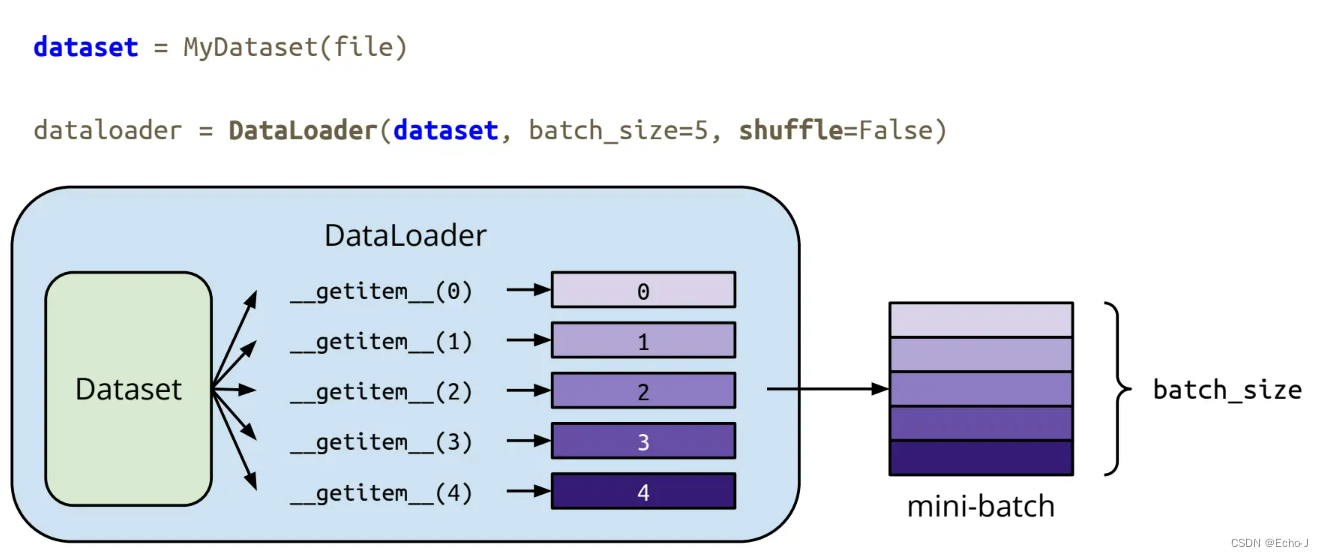
我们读取完数据,是不是想知道我们的数据长什么样子呢?(我们称数据为Tensors)
首先,它可能是一个一维数据,比如一个音频、一个温度
其次,还可能是一个二维数据,比如一张二值图像
最后,还可能是一个三维数据,比如一个彩色的图像
又有问题了,我们怎么通过编程得到我们图像的大小?
可以使用pytorch里面的shape()函数
我们怎么通过编程创造我们的数据呢?
eg:
x = torch.tensor([[1,-1],[-1,1]])
x = torch.from_numpy(np.array([[1,-1],[-1,1]]))
全0或全1数据
x = torch.zeros([2,2]) # 2*2的全0数据
x = torch.ones([1,2,5]) # 1*2*5的全1数据其次,还支持矩阵的运算
Addition:z = x + y
Subtraction:z = x - y
Power:y = x.pow(2)
Summation:y = x.sum()
Mean:y = x.mean()
维度转换:x = x.transpose(dim0,dim1)
消除维度:x = x.squeeze(dim)
增加维度:x = x.unsqueeze(dim)
组合:w = torch.cat([x,y,z],dim=1)拥有不同的数据类型:

使用.to()可以切换到不同的设备:
CPU: x = x.to('cpu')
GPU: x = x.to('cuda')这里就又涉及到如何检查你的GPU了?可以使用以下语句检查你的计算机是否有GPU:
torch.cuda.is_available()如何计算梯度?
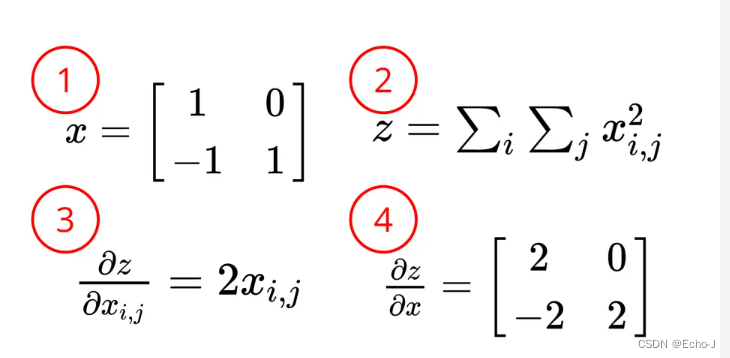
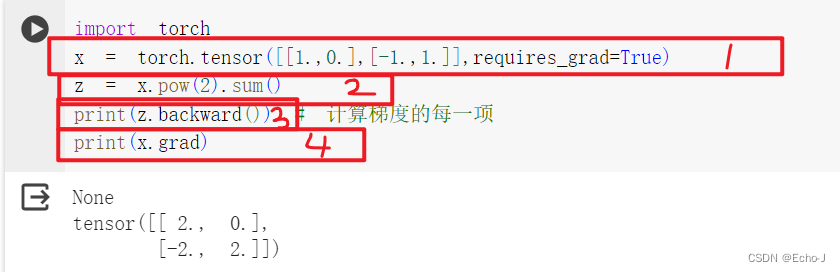
// 注意矩阵一定要使用小数点
2、Define Neural Network(训练和测试神经网络)
torch.nn.Module线性:
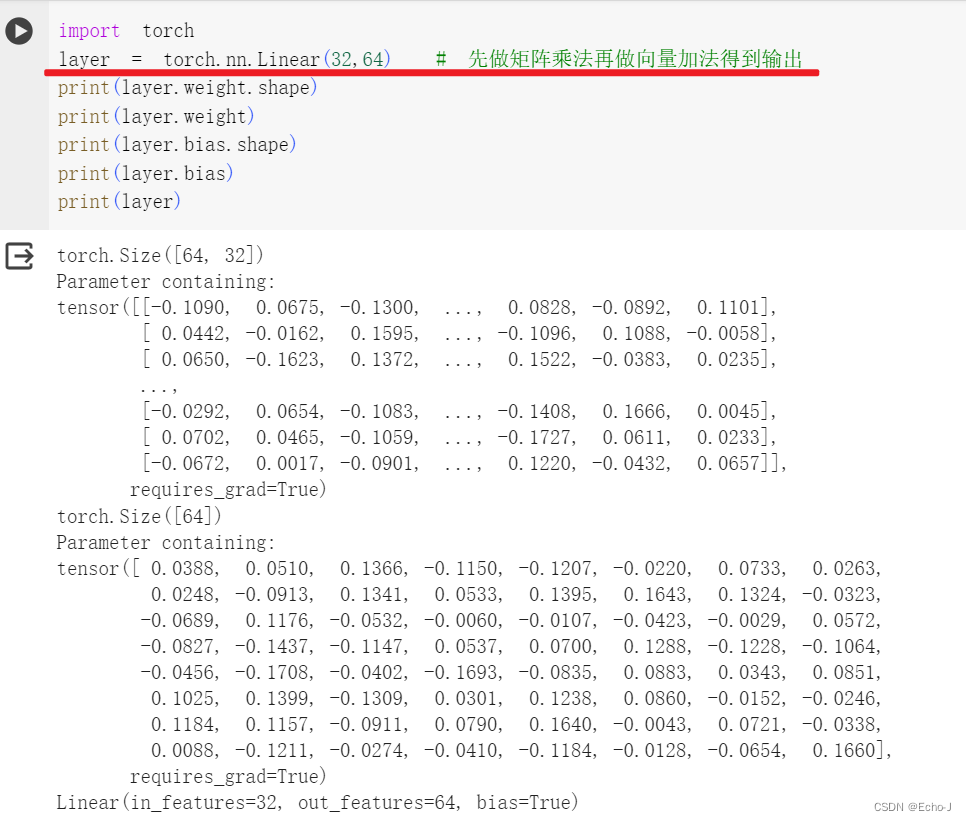
非线性:
Sigmoid Activation:nn.Sigmoid()
ReLU Activation:nn.ReLU()
下面我根据所学的知识构建我自己的神经网络:
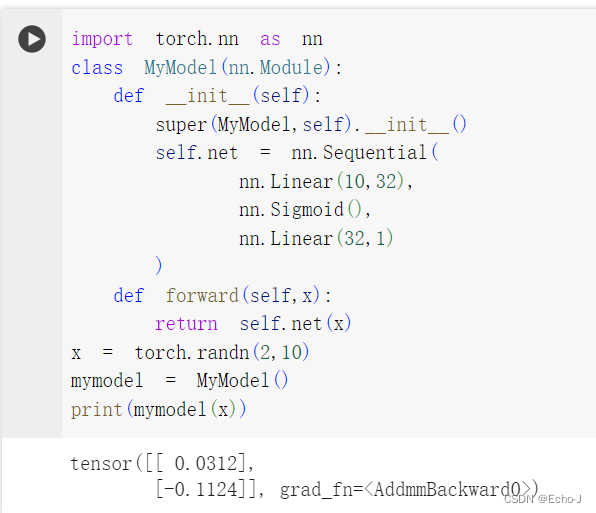
3、Loss Function(损失函数)
x = torch.nn.MSELoss # 对于回归任务
x = torch.nn.CrossEntropyLoss etc. # 对于分类任务
loss = x(model_output,expected_value)4、Optimization Algorithm(优化)
torch.optim这是基于梯度的优化算法,不断调整参数,减少误差
比如:随机梯度下降(SGD)
torch.optim.SGD(model.parameters(), lr, momentum = 0)* 调用optimizer.zero_grad()重置模型参数的梯度。
*调用loss.backward()反向传播预测loss的梯度。
*调用optimizer.step()调整模型参数。
5、Entire Procedure(整个程序)
import torch.utils.data as data
dataset = data.Dataset(file) # 读取数据
tr_set = DataLoader(dataset,batch_size,shuffle=True) # 对数据集进行分组
model = MyModel().to(device) # 建立我的模型并且选择我的设备(cpu or gpu)
criterion = nn.MSELoss() # 建立损失函数
optimizer = torch.optim.SGD(model.parameters(),0.1) # 建立优化
# 训练
for epoch in range(n_epochs): # 迭代数据model.train() # 训练模型for x, y in tr_set: # 迭代数据集optimizer.zero_grad() # 设置梯度为0x, y = x.to(device),y.to(device) # 将数据移动到设备pred = model(x) # 计算输出loss = criterion(pred,y) # 计算损失函数loss.backward() # 计算反向梯度optimizer.model() # 优化模型
# 验证
model.eval() # 将模型设置为评估模式
total_loss = 0
for x,y in dv_set: # 对数据集进行迭代x,y = x.to(device),y.to(device) # 将数据移动到涉笔with torch.no_grad(): # 不可迭代的计算pred = model(x) # 计算输出loss = criterion(pred,y) # 计算损失函数total_loss += loss.cpu().item()*len(x) # 累加损失误差avg_loss = total_loss / len(dv_set.dataset) # 计算平均损失
# 测试
model.eval() # 将模型设置为评估模式
preds = []
for x in dv_set: # 对数据集进行迭代x = x.to(device) # 将数据移动到涉笔with torch.no_grad(): # 不可迭代的计算pred = model(x) # 计算输出preds.append(pred.cpu()) # 收集预测// model.eval() :更改模型的行为
// with torch.no_grad() :防止对验证/测试数据进行意外训练
当我们训练完模型,也完成了测试,为了不使模型丢失,我们需要保存模型,pytorch也为我们提供了保存模型的方法。
保存模型:torch.save(model.state_dict(),path)
下次我们使用已经训练完成的模型,或者想继续训练,我们需要读取模型。
读取模型:ckpt = torch.load(path) model.load_state_dict(ckpt)
// 这只是我根据所听的课自己写的笔记,如果有什么错误欢迎指正!!!
这篇关于机器学习-pytorch1(持续更新)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









