本文主要是介绍linuxIO刷新机制fsync和fdatasync,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linux,unix在内核中设有 缓冲区高速缓冲或页面高速缓冲,大多数磁盘I/O都通过缓冲进行,采用延迟写技术。
sync:将所有修改过的快缓存区排入写队列,然后返回,并不等待实际写磁盘操作结束
fsync:只对有文件描述符制定的单一文件起作用,并且等待些磁盘操作结束,然后返回。
fdatasync:类似fsync,但它只影响文件的数据部分。fsync还会同步更新文件的属性。
fflush:标准I/O函数(如:fread,fwrite)会在内存建立缓冲,该函数刷新内存缓冲,将内容写入内核缓冲,要想将其写入磁盘,还需要调用fsync。(先调用fflush后调用fsync,否则不起作用)。
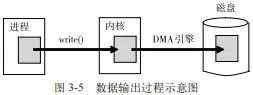
前面介绍函数write()时,我们认为该函数一旦返回,数据便已经写到了文件中。但是这种概念只是宏观上的。实际上,操作系统实现某些文件I/O时(如磁盘文件),为了保证I/O的效率,在内核通常会用到一片专门的区域(内存或独立的I/O地址空间)作为I/O数据缓冲区。应用程序可以将这片内核区域看成是I/O数据的一个快速中转站(图3-5)。当调用write()函数写出数据时,数据一旦写到该缓冲区,函数便立即返回。此时写出的数据可以用read()读回,也可以被其他进程读到,但是并不意味着它们已经被写到了外部永久存储介质上,即使调用close()关闭文件后也可能如此。内核I/O数据缓冲区中的数据只在适当的时候才由操作系统启动外设进行传输,真正的传输动作由独立于CPU的外设控制器或者外设本身(Linux称之为DMA引擎)来完成。因此,从数据被实际写到磁盘的角度来看,用write()写出的文件数据与外部存储设备并不是完全同步的。在现代计算机系统中,这种不同步的时间间隔非常短,一般只有几秒或十几秒,具体取决于写出的数据量和I/O数据缓冲区的状态。尽管不同步的时间间隔很短,但是如果在此期间发生掉电或者系统崩溃,则会导致所写数据来不及写至磁盘而丢失的情况。
由于现代计算机通常都十分稳定可靠,出现掉电或系统崩溃的情况极少,因此多数应用在写文件时可以忽略这种瞬间不同步情况。但是,有些应用存在着这样的一些同步点,在这些点上所写的数据非常关键,或者必须及时保证文件的一致性。为了防备万一,这些应用需要确保所有写出的数据都已经传送到了外部永久存储介质上。为此,UNIX提供了两种手段来实现这一目的。其中一种方法是对文件设置O_SYNC标志,这样可以保证每次写数据都直接写到磁盘。如果设置了这个标志,write()调用将直到数据已安全地写到磁盘后(而不仅仅是系统的I/O缓冲区)才返回。但是这样每次写数据都保持同步的效率比较低。
另一种方法是只在需要时调用函数fsync()或者fdatasync()。
#include <unistd.h>
int fsync(int fildes);
int fdatasync(int fildes)
fsync()强制与描述字fildes相连文件的所有修改过的数据(包括核内I/O缓冲区中的数据)传送到外部永久介质,即刷新fildes给出的文件的所有信息。调用 fsync()的进程将阻塞直到设备报告传送已经完成。这里“所有修改过的数据”包括用户写出的数据以及文件本身的特征数据(4.1.1节和表4-1),如文件的访问时间、修改时间、文件的属主等。
fdatasync()的功能与fsync()类似,只是它只强制传送用户已写出的数据至物理存储设备,不包括文件本身的特征数据。这样可以适当减少文件刷新时的数据传送量。不过有的系统并不支持fdatasync(),在这种系统上,fdatasync()等价于fsync()。
一个程序在写出数据之后,如果继续进行后续处理之前要求确保所写数据已写到磁盘,则应当调用fsync()。例如,数据库应用通常会在调用write()保存关键交易数据的同时也调用fsync()。
我们在曾讨论了标准I/O流缓冲区的问题以及函数fflush()。那么,这两个缓冲区有何不同?回答是,内核I/O缓冲区是由操作系统管理的空间,而流缓冲区是由标准I/O库管理的用户空间。fflush()只刷新位于用户空间中的流缓冲区。fflush()返回后,只保证数据已不在流缓冲区中,并不保证它们一定被写到了磁盘。此时,从流缓冲区刷新的数据可能已被写至磁盘,也可能还待在内核I/O缓冲区中。要确保流I/O写出的数据已写至磁盘,那么在调用fflush()后还应当调用fsync()。

这篇关于linuxIO刷新机制fsync和fdatasync的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



