本文主要是介绍大数据-玩转数据-阿里Dataphin全接触,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:本文重因个人偏好,重点偏向于数仓规划、数据引入、编码研发
一、什么是Dataphin
Dataphin是阿里巴巴集团OneData数据治理方法论内部实践的云化输出,一站式提供数据采、建、管、用全生命周期的大数据能力,以助力企业显著提升数据治理水平,构建质量可靠、消费便捷、生产安全经济的企业级数据中台。Dataphin提供多种计算平台支持及可拓展的开放能力,以适应不同行业客户的平台技术架构和特定诉求。
二、Dataphin框架
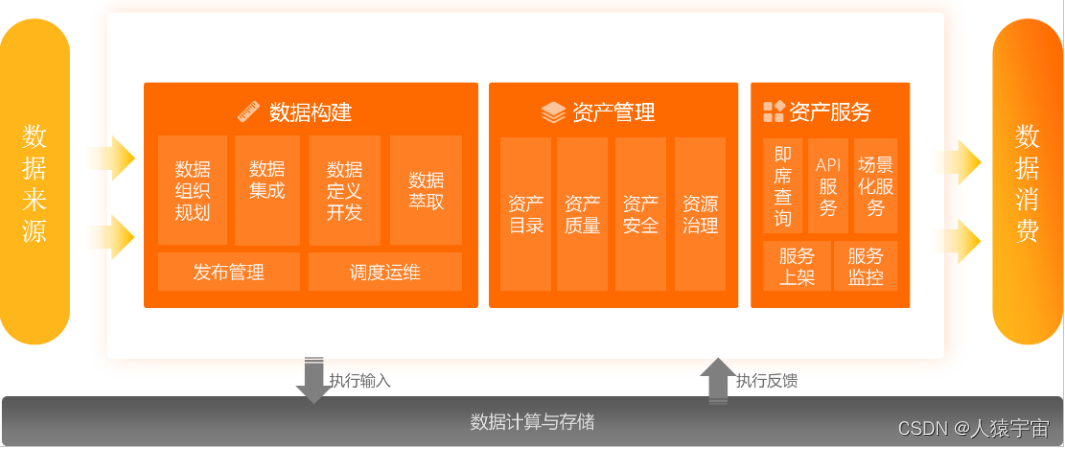
三、平台管理
Dataphin的基础功能,包含账号管理、计算设置和智能引擎。超级管理员需要通过管理中心来进行成员管理和计算设置,同时您也可以通过智能引擎来配置计算和存储规则,以提高数据构建的效率。
平台管理根据说明书进行即可,在实施之前要进行整体规格。
四、数仓规划
基于Dataphin建设数据中台的第一步,同时也是数据体系的顶层设计中至关重要的一步。在您开始数据开发前,需要完成数据仓库的规划,包括定义业务板块、数据域、项目、数据源、计算源和统计周期。
数仓规划包括逻辑空间与物理空间的全局架构,以实现业务划分、资源管控、项目管理等目的:
- 逻辑空间:基于业务特征划分命名空间及其核心对象,包括业务板块、数据域和公共定义模块。
- 物理空间:基于开发协作管理需求划分物理项目,包括项目管理、数据源管理等模块。
基础研发版和智能研发版支持的功能不同:
- 基础研发版:规划包括项目和源两大模块。模块之间存在依赖关系,项目的计算存储资源配置基于计算源,项目空间内所用到的数据基于数据源。
- 智能研发版:规划包括业务、项目和源。模块之间存在依赖关系,项目的计算存储资源配置基于计算源,项目空间内所用到的数据基于数据源,项目可以归属于业务板块。
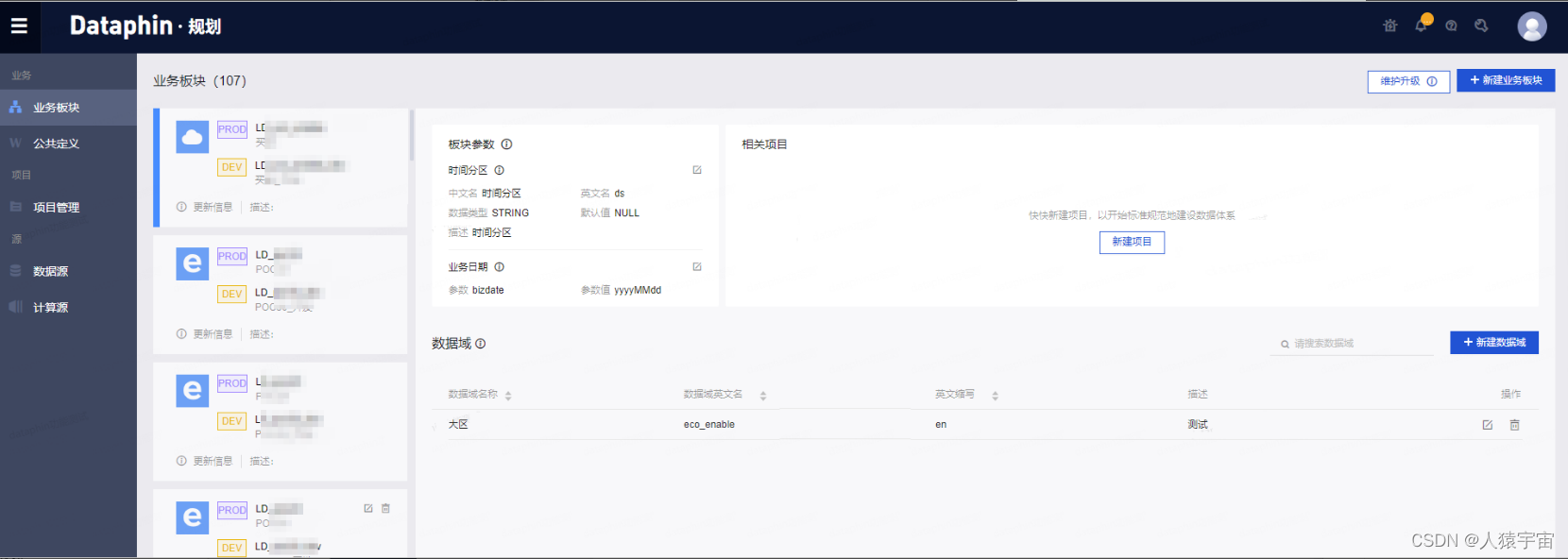
1、业务板块

2、数据域
数据域用于存放同一业务板块内不同意义的指标,如商品域、交易域、会员域等。
特指电信行业大数据领域的三大数据域。
- B域(业务域)=business support
system的数据域,B域有用户数据和业务数据,比如用户的消费习惯、终端信息、ARPU的分组、业务内容,业务受众人群等。业务支持系统(BSS)主要实现了对电信业务、电信资费、电信营销的管理,以及对客户的管理和服务的过程,它所包含的主要系统包括:计费系统、客服系统、帐务系统、结算系统以及经营分析系统等。 - O域(运营域)=operation support
system的数据域,O域有网络数据,比如信令、告警、故障、网络资源等。运营支撑系统(OSS)主要是面向资源(网络、设备、计算系统)的后台支撑系统,包括专业网络管理系统、综合网络管理系统、资源管理系统、业务开通系统、服务保障系统等,为网络可靠、安全和稳定运行提供支撑手段。 - M域(管理域)=management support
system的数据域。M域有位置信息,比如人群流动轨迹、地图信息等。管理支持系统(MSS),包括为支撑企业所需的所有非核心业务流程,内容涵盖制订公司战略和发展方向、企业风险管理、审计管理、公众宣传与形象管理、财务与资产管理、人力资源管理、知识与研发管理、股东与外部关系管理、采购管理、企业绩效评估、政府政策与法律等。
3、编辑板块参数
板块参数用于定义业务板块内的时间分区和业务日期。

4、管理统计周期
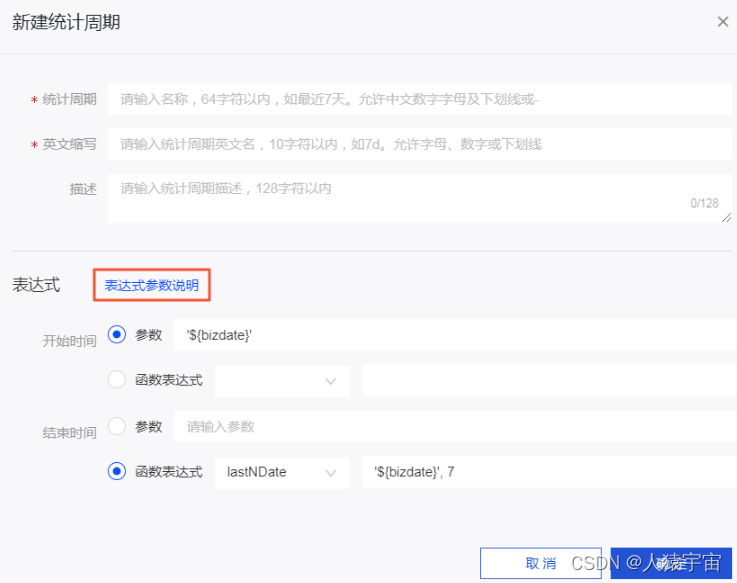
公共定义仅支持定义统计周期。统计周期即统计数据的时间范围,例如最近7天、最近30天等。
4、计算源
- 新建MaxCompute计算源
- 新建AnalyticDB For PostgreSQL计算源
- 新建Flink计算源
- 创建加速计算源
- 管理计算源
比如新建MaxCompute计算源
MaxCompute计算源用于绑定Dataphin项目空间和MaxCompute项目,为Dataphin项目提供处理离线计算任务的计算源。如果Dataphin系统的计算引擎设置为MaxCompute,则只有项目空间添加MaxCompute计算源,才支持规范建模、即席查询、MAXC任务、通用脚本等功能。
前提条件已设置Dataphin计算引擎为MaxCompute,
系统支持超级管理员和项目管理员角色的账号新建计算源
5、项目空间
- 创建Prod和Dev项目
- 创建Basic项目
- 管理项目成员及权限设置
比如:项目是Dataphin的基本组织单元,是进行多用户隔离和访问控制的主要边界。您开通Dataphin服务后,需要通过项目使用Dataphin。为了保障数据生产的稳定性及对数据研发流程的强管控,您可以创建Dev-Prod模式的项目。
6、数据源
- Dataphin支持的数据源
- Dataphin出网IP地址
- 网络连通解决方案
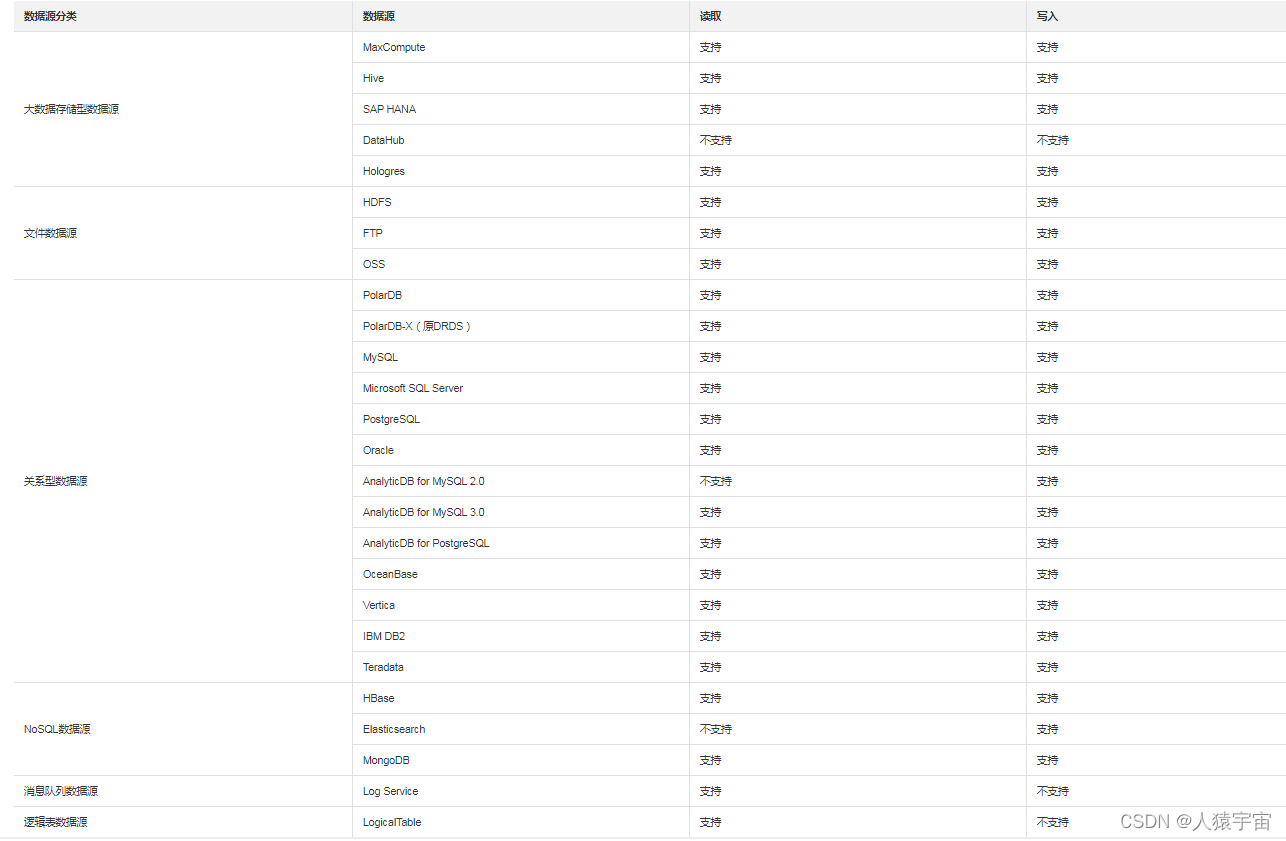
- 大数据存储数据源
- 文件数据源
- 消息队列数据源
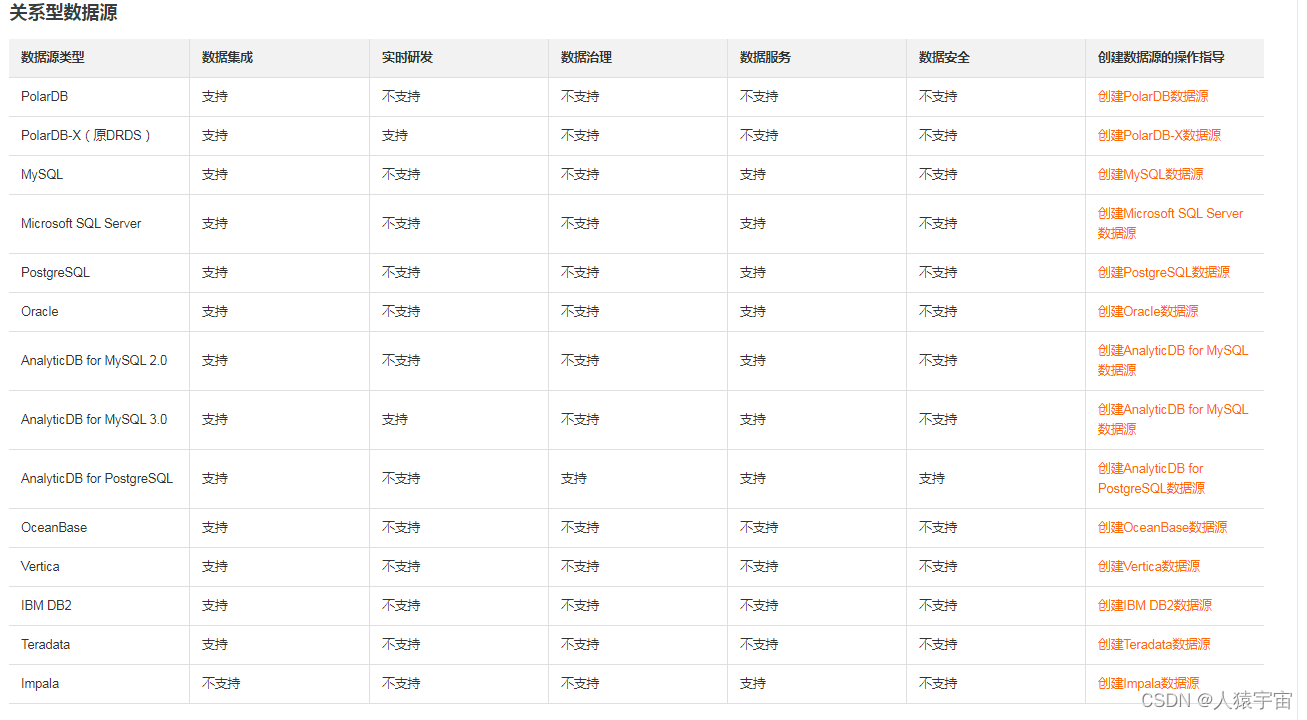
- 关系型数据源
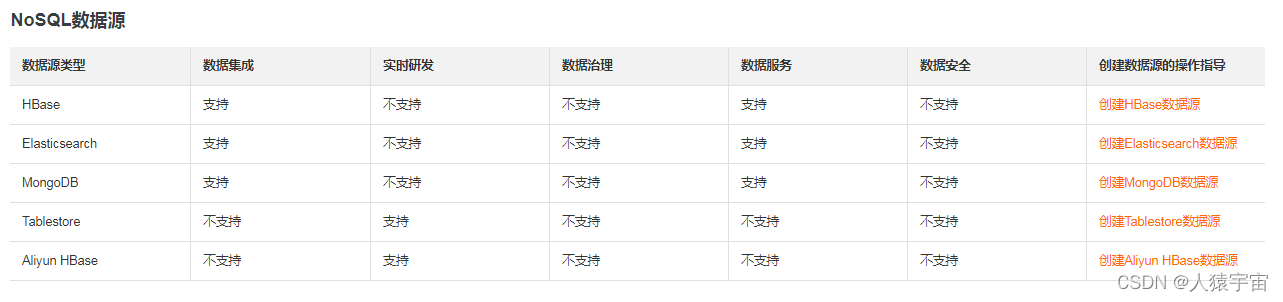
- NoSQL数据源
比如Dataphin支持的数据源:
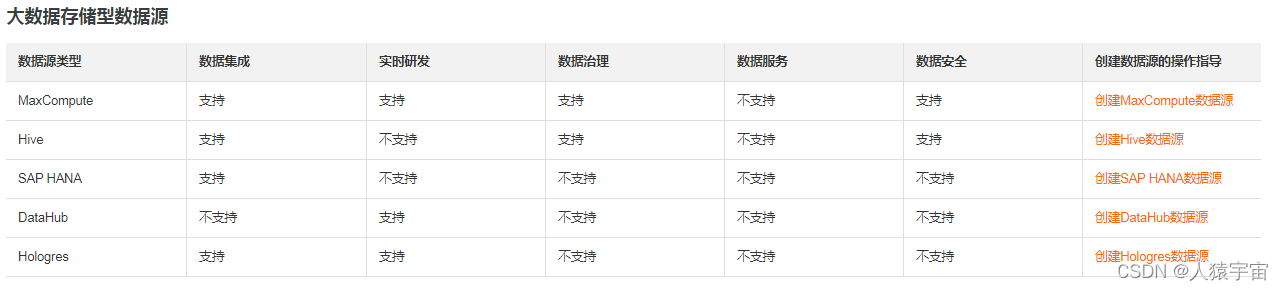
在使用Dataphin前,您需要选择符合业务场景需求的数据库或数据仓库作为数据源,用于读取原始数据和写入数据建设过程中的数据。Dataphin集成了丰富的数据引擎,支持对接如MaxCompute、Hive等数据仓库,也支持对接企业传统数据库,如MySQL、Oracle等。
Dataphin支持对接的数据源包括大数据存储型数据源、文件数据源、消息队列数据源、关系型数据源和NoSQL数据源,各模块支持对接的数据源类型说明如下。如果您需要在Dataphin中连接某数据源,则需要先在数仓规划中的数据源模块创建该数据源。


五、数据引入
基于全局设计定义的项目空间与物理数据源,将各业务系统、各类型的数据抽取加载至目标数据库。这个过程可以实现各类业务数据的同步与集成,助您完成基础数据中心建设,为后续进一步加工数据奠定基础。
1、数据集成
1.1 支持的数据源
数据集成支持两种数据迁移方式,包括表、文件迁移和整库迁移。
- 表、文件迁移 适用于数据上云、云上数据迁移到本地业务系统等场景。例如,将本地数据库MySQL的数据迁移至阿里云数据库RDS中。
- 整库迁移 适用于将本地数据中心或在ECS上自建的数据库,同步数据至离线数仓(Hive)、大数据计算服务等场景。例如,将ECS上自建的MySQL数据库的数据迁移至MaxCompute中。

1.2 管理管道脚本文件夹
新建、移动、删除及重命名用于存放管道脚本文件的文件夹。
1.3上传管道脚本
Dataphin支持将已下载的管道脚本上传至系统。进行二次开发。
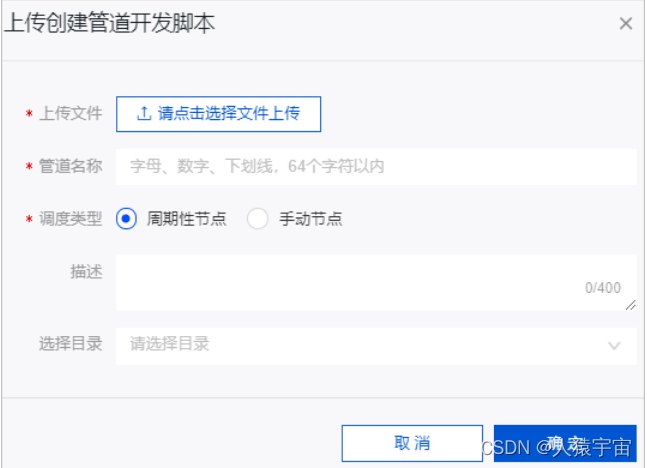
1.4 离线单条管道
- 配置离线单条管道
- 编辑离线单条管道
- 重命名离线单条管道
- 移动离线单条管道
- 查看历史信息
- 下线和删除离线单条管道
1.5 离线整库迁移
- 配置离线整库迁移
- 操作离线单条管道
- 重命名离线整库迁移
- 删除离线整库迁移
1.6 自定义组件
- 新建自定义组件
- 应用自定义组件
1.7 组件说明
- 组件库-输入组件
- 组件库-转换组件
- 组件库-流程组件
- 组件库-输出组件
2、数据同步
- 新建同步任务文件夹
- 新建同步目标表
- 新建同步任务
- 配置同步任务
- 调度配置
- 执行同步任务
- 验证同步任务
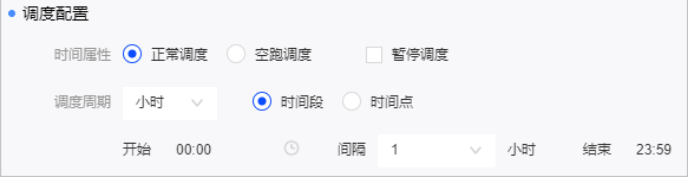
比如调度配置:
调度配置是配置节点在调度过程中的调度规则及依赖关系。
系统仅支持周期性节点的同步任务进行调度配置。
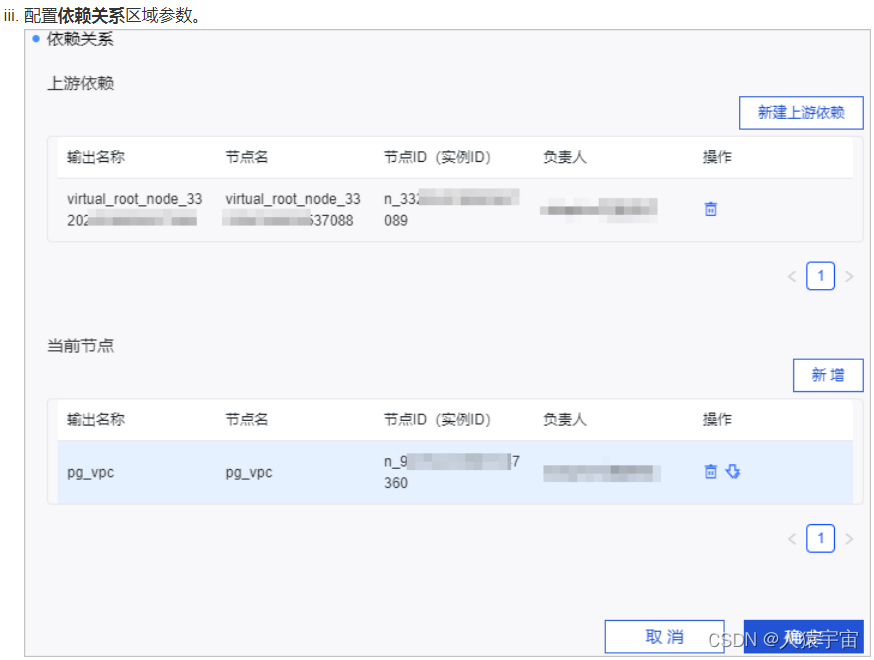
依赖关系是两个或多个节点之间的语义连接关系,同时上游节点的状态将影响其他下游节点的运行状态。
配置了依赖关系的节点调度规则为:首先,上游节点运行完成后,才能调度下游节点。其次,根据节点设定的调度时间判断是否执行调度。
当您在设定的调度时间之前提交的调度配置,会在设定的调度时间之后生效。而在设定的调度时间之后配置的依赖关系,只能间隔一天再生成实例。
调度配置的权限限制

比如验证同步任务:
执行以下SQL语句,查询同步任务执行的结果。
select * from 目标表名称 where ds=‘任务调度日期’
六、规范定义
规范定义 以维度建模作为理论基础,构建总线矩阵,划分并定义数据域、业务过程、维度、原子指标、业务限定、时间周期和派生指标,以保障数据标准化、规范化的产出。
七、建模研发
基于规范定义的数据元素,进行设计与构建可视化的数据模型。数据模型提交发布后,Dataphin自动化地生成代码与调度任务,大大提升了数据研发效率。
八、编码研发
基于通用的代码编辑页面,灵活地进行个性化的数据编码研发,完成任务发布。
Dataphin不同版本,支持构建不同类型的计算任务。
| 版本 | 计算任务类型 |
|---|---|
| 智能研发版 | SQL、Spark、MapReduce、Shell、Python、Virtual、Flink_SQL、Flink_Template_SQL和Flink_DataStream |
| 基础研发版 | ADB for PostgreSQL、Shell、Python、Virtual、Flink_SQL、Flink_Template_SQL和Flink_DataStream |
Flink_SQL和Flink_Template_SQL类型的任务,既支持处理实时数据又支持处理离线数据。
1、规范建模
1.1 规范定义-维度
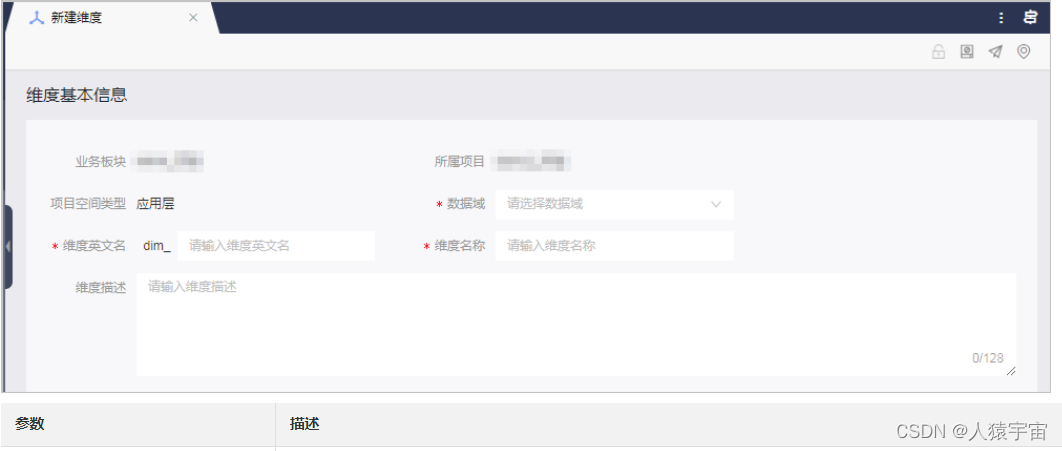
新建维度
维度是人们观察事物的角度,是确定事物的多方位、多角度、多层次的条件和概念。维度即进行数据统计的对象。通常情况下,维度是实际存在、不因事件发生而存在的实体,例如时间维度、地区维度、产品维度等。创建维度,即从顶层规范业务中实体(或称主数据)的存在性及唯一性。
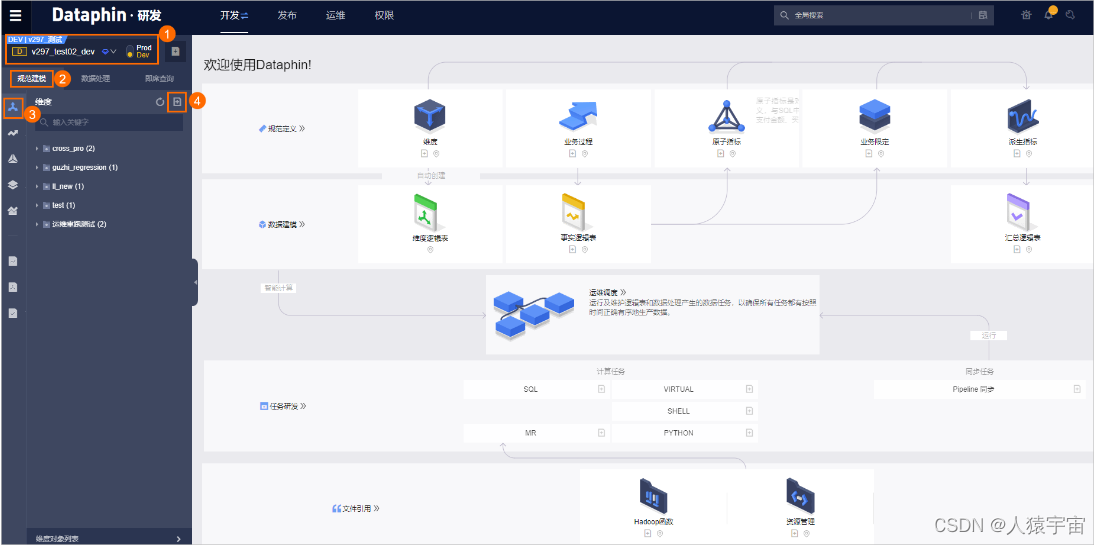
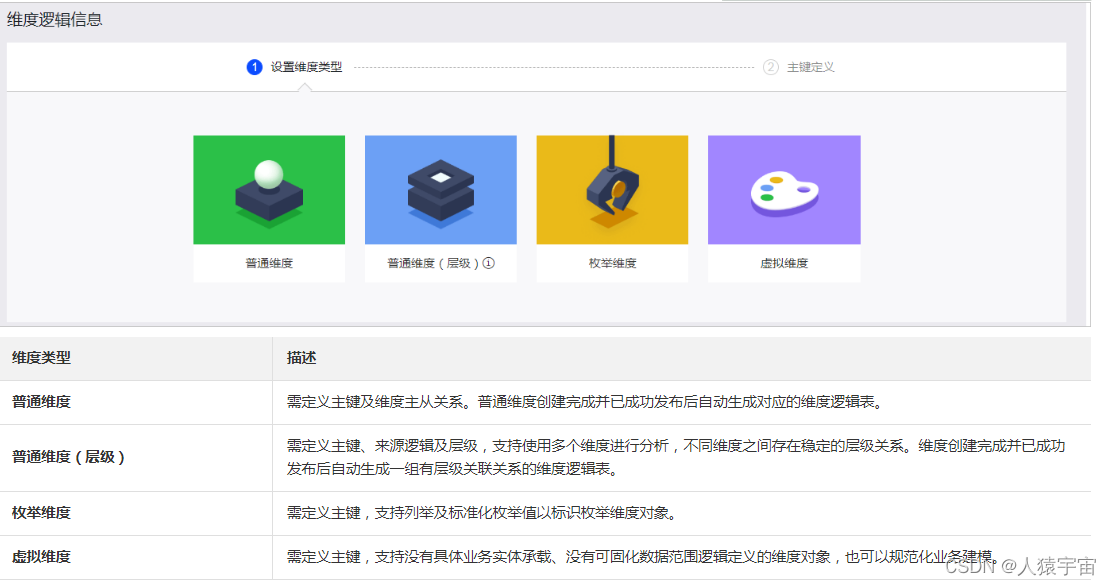
创建了维度后,可以对维度进行其它相应操作,查看维度逻辑表、编辑维度、继承维度、下线和删除维度
1.2 规范定义-业务过程
新建业务过程
业务过程是业务活动中不可拆分的事件,例如下单、支付和退款。创建业务过程,即从顶层视角,规范业务活动中事件的内容类型及唯一性。

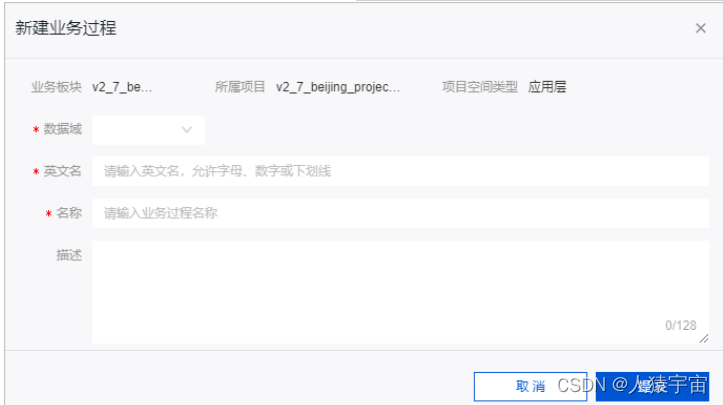
新建完业务过程,可以对业务过程进行编辑业务过程、克隆业务过程、创建逻辑表、查看相关事实逻辑表、删除业务过程等操作。
1.3 逻辑表-维度逻辑表
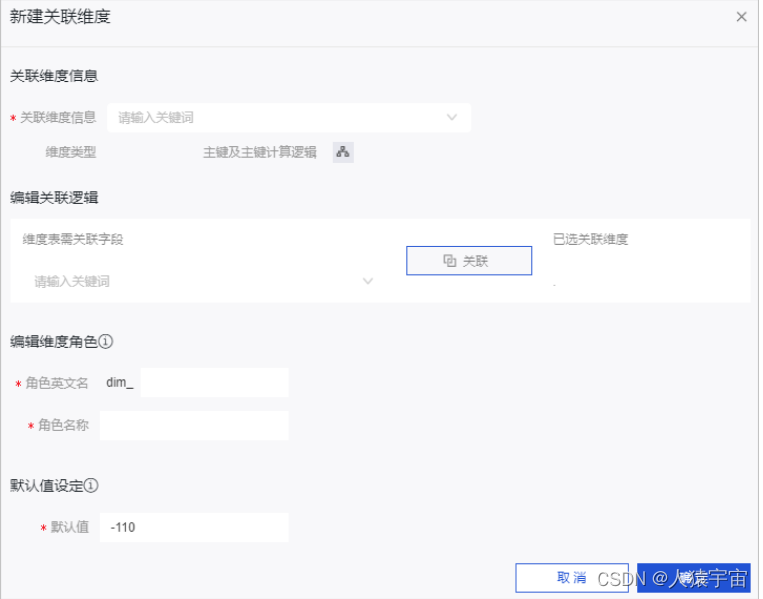
添加关联维度、属性和子维度
维度提交成功后,系统会自动创建与维度一一对应的维度逻辑表。同时,系统支持对维度逻辑表添加属性、关联维度和子维度。
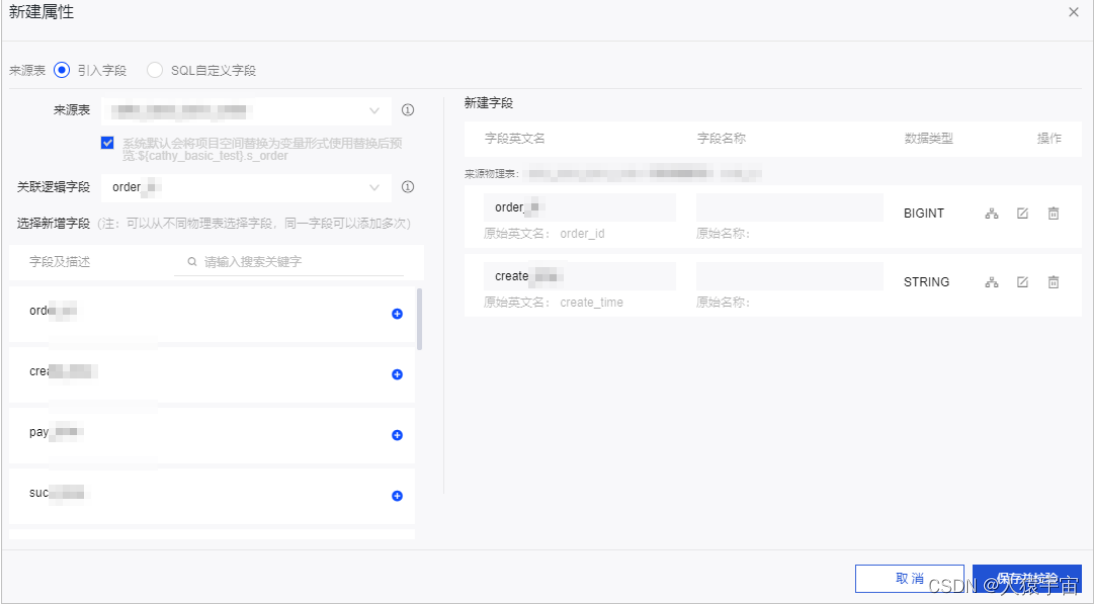
编辑字段的计算逻辑
order_id string
select order_id
from onedata.s_order a
join s_item b
on a.item_id=b.item_id
where ds='${bizdate}'
下面还可以进行以下操作:
编辑模型关系、定义公用计算逻辑、编辑字段、物理化配置、调度配置、参数配置、查看历史信息、下线和删除维度逻辑表
1.4 逻辑表-事实逻辑表
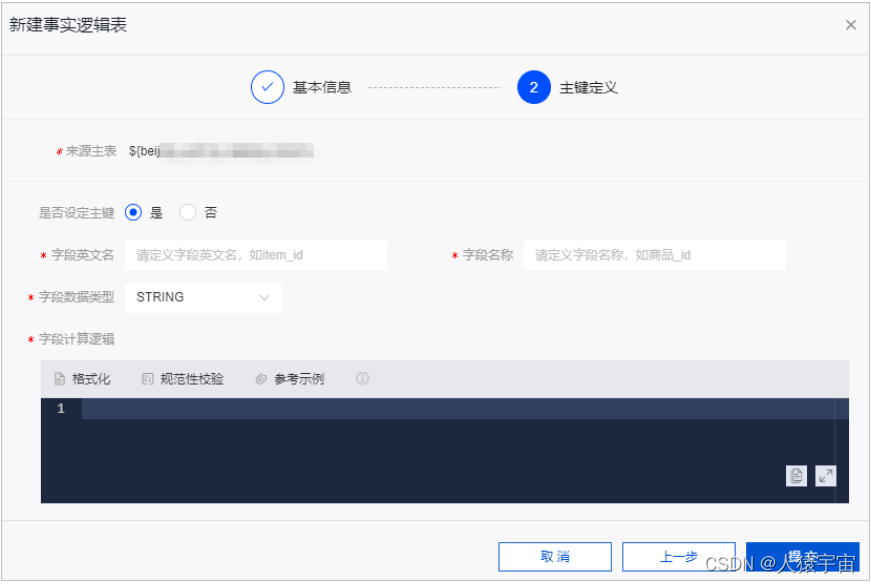
新建事实逻辑表
事实逻辑表用于描述业务过程的详细信息

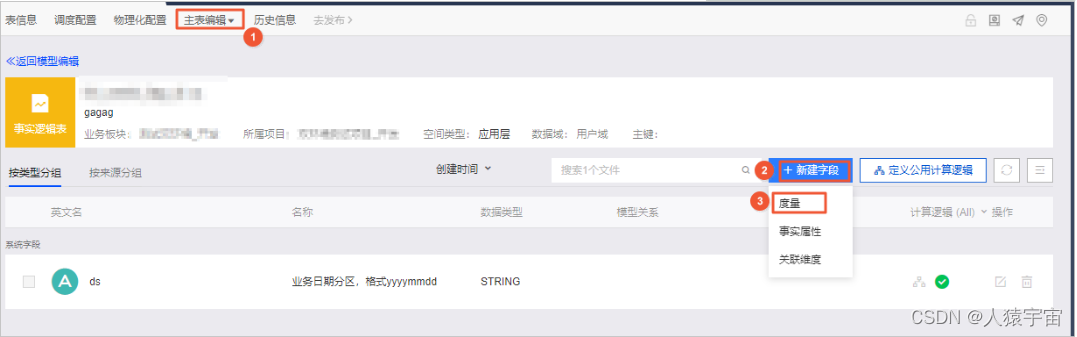

建立完事实表,还可以进行以下配置:
物理化配置、修改事实逻辑表、调度配置、查看历史信息、下线和删除事实逻辑表
1.5 规范定义-原子指标
新建原子指标
原子指标是对指标统计口径、具体算法的抽象。Dataphin创新性地提出了设计即开发的理念,指标定义同时也明确了设计统计口径(即计算逻辑),提升了研发效率,并保证了统计
这篇关于大数据-玩转数据-阿里Dataphin全接触的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





