本文主要是介绍【数字人】12、DINet | 使用形变+修复模块实现高清 talking head 生成(AAAI2023),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、背景
- 二、方法
- 2.1 deformation part
- 2.2 inpainting part
- 2.3 Loss 函数
- 三、效果
- 3.1 数据集
- 3.2 实现细节
- 3.3 可视化效果
论文:DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
代码:https://github.com/MRzzm/DINet
出处:AAAI2023
贡献:
- 提出了能产生高分辨率视频的方法,能够同时产生准确的嘴型且保留纹理细节
- 本文方法是【形变模块】+【修复模块】组成的,在参考帧的基础上对嘴型进行形变从而产生新的口型结果,而非直接生成
一、背景

本文针对 few-shot learning,提出了一种 Deformation Inpainting Network (DINet)
DINet 和之前的方法最大的不同在于:
- 之前的方法主要依赖于多个上采样层来直接从隐空间来生成最终的像素结果
- DINet 在 referece image 的特征图上使用了 spatial deformation,能够保留更多的高频纹理细节
DINet 的组成:
- 一个 deformation 模块:嘴部形变模块,为了避免生成的结果产生模糊,本文是会对嘴部区域附近的特征图进行空间形变,用于产生音频同步的嘴型
- 首先会自适应的选取 5 个参考帧(面部图片)
- 然后使用 spatial deformation 来为这些参考帧的人脸的特征图进行形变,生成形变后的特征图,目标是为了让【嘴部】和输入的【音频+头部姿态】保持对齐
- 一个 inpainting 模块:也就是一个解码器,能够将形变后的嘴部特征和上半脸+头部姿态合并起来,输出自然的生成结果
- 通过卷积层融合源人脸特征和变形结果,修复嘴部区域像素
二、方法
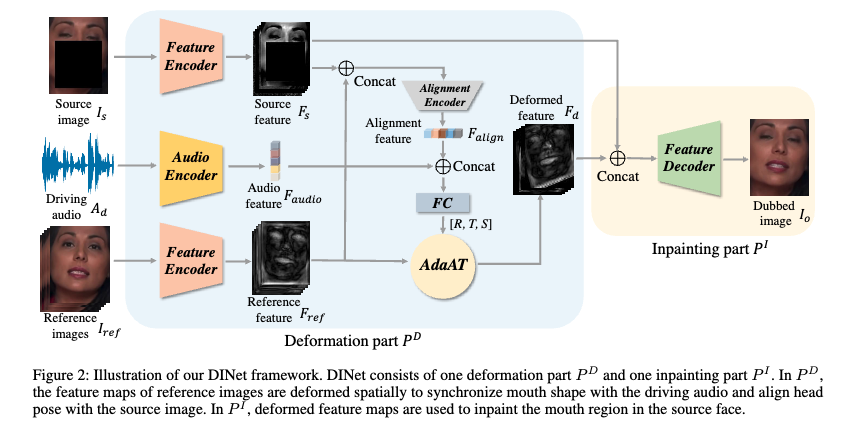
本文提出的 DINet 的结构如图 2 所示,主要由变形模块( P D P^D PD)和修复模块 ( P I P^I PI)组成,前者是在空间上对参考帧的特征图进行形变,后者是利用变形后的结果来修复源人脸中的嘴部区域
2.1 deformation part
如图 2 的上半部分就是变形模块( P D P^D PD):
- 给定源图片 source image I s ∈ R 3 × H × W I_s \in R{3 \times H \times W} Is∈R3×H×W
- 给定驱动声音 A d ∈ R T × 29 A_d \in R^{T \times 29} Ad∈RT×29
- 给定 5 张参考图片 reference image I r e f ∈ R 15 × H × W I_{ref} \in R{15 \times H \times W} Iref∈R15×H×W
变形模块的主要目标是生成形变特征 F d ∈ R 256 × H / 4 × W / 4 F_d \in R{256 \times H/4 \times W/4} Fd∈R256×H/4×W/4,并且这个特征是要和驱动音频 A d A_d Ad 同步的嘴型,并和 source 图片 I s I_s Is 对齐头部姿态
- 首先,将音频特征输入 audio encoder 得到 audio feature F a u d i o F_{audio} Faudio
- 然后,将 source image I s I_s Is 和 reference image I r e f I_{ref} Iref 输入两个不同的 encoder 网络来分别生成对应的特征 F s ∈ R 256 × H / 4 × W / 4 F_s \in R^{256 \times H/4 \times W/4} Fs∈R256×H/4×W/4 和 F r e f ∈ R 256 × H / 4 × W / 4 F_{ref} \in R^{256 \times H/4 \times W/4} Fref∈R256×H/4×W/4
- 接着,将 F s ∈ R 256 × H / 4 × W / 4 F_s \in R^{256 \times H/4 \times W/4} Fs∈R256×H/4×W/4 和 F r e f ∈ R 256 × H / 4 × W / 4 F_{ref} \in R^{256 \times H/4 \times W/4} Fref∈R256×H/4×W/4 进行 concat 后输入一个 alignment encoder 来得到对齐后的特征 F a l i g n ∈ R 128 F_{align} \in R^{128} Falign∈R128, F a l i g n ∈ R 128 F_{align} \in R^{128} Falign∈R128 的作用是对 I s I_s Is 和 I r e f I_{ref} Iref 的 head pose 进行对齐
- 最后,使用 F a u d i o F_{audio} Faudio 和 F a l i g n F_{align} Falign 被用于将 F r e f F_{ref} Fref 形变为 F d F_d Fd
如何进行形变呢:
- 本文使用了 AdaAT 的方法来进行形变(没有使用密集flow的方法),主要的原因是相比于 flow,AdaAT 能够通过对特征通道进行特定变形来变形特征图
- AdaAT 会在不同的特征通道上计算不同的仿射系数
- 在此处 P D P^D PD 使用全连接层来计算旋转、平移、缩放系数,然后使用这些仿射系数对 F r e f F_{ref} Fref 进行仿射变换

2.2 inpainting part
图 2 的黄色矩形就是 inpainting part P I P^I PI 的结构,这个模块的目标就是使用 source image 的特征图 F s F_s Fs 和形变后的 ref 特征图 F d F_d Fd 来合成最终的说话图片 I o ∈ 3 × H × W I_o \in 3 \times H \times W Io∈3×H×W。
- 首先,将 F d F_d Fd 和 F s F_s Fs 进行 concat
- 然后,使用一个 decoder(卷积层)来修复 source image 被 mask 掉的嘴部区域,并且生成 I o I_o Io
2.3 Loss 函数
作者在训练过程中使用了 3 个 loss 函数
- perception loss
- GAN loss
- lip-sync loss
1、perception loss
作者使用两个尺度上的图片来计算感知损失,作者将生成的图像和原始的图像送入 VGG-19 得到特征后计算一次 loss,下采样 2 倍后送入 VGG-19 得到特征后再计算一次 loss,两个 loss 求均值:

2、GAN loss
作者使用 LS-GAN loss

3、Lip-sync loss
作者使用这个 loss 是为了提升生成的嘴型同步性,作者使用 audio spectrogram with deepspeech 特征重新训练了 syncnet
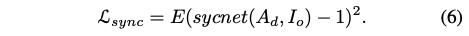
4、整体 loss

三、效果
3.1 数据集
作者使用 HDTF 和 MEAD 数据集
- HDTF:约 430 个视频,分辨率为 720P 或 1080P,随机选择 20 个视频作为测试
- MEAD:收集了约 1920 个正常表情的前视方向的视频作为训练数据,选择了 240 个视频(6个人)作为测试
3.2 实现细节
数据处理:
- 视频首先会 resample 到 25fps
- 使用 openface 提取到 68 个人脸关键点,然后 crop 出面部区域,将所有 crop 的面部区域 resize 到 416x320,其中嘴部区域会占 256x256
- 使用 deepspeech 提取语音特征
训练阶段:
- DINet 输入一个 source frame,分辨率为 3x416x320,再输入一个 driving audio,维度为 5x29,还有 5 帧 reference image,分辨率为 15416x320
- syncnet 输入 5 帧 mouth image(256x256) 和对应的 deepspeech 特征
- 优化器:Adam,学习率 0.0001
- batch: DINet 是 3,syncnet 是 20
3.3 可视化效果


这篇关于【数字人】12、DINet | 使用形变+修复模块实现高清 talking head 生成(AAAI2023)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






