本文主要是介绍Camunda7历史记录级别配置和历史数据清理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
camunda工作流引擎中有好多以ACT_HI_*开始的数据库表,HI代表历史。这些表包含历史数据,如过去的流程实例、变量、任务等。camunda详细数据库表结构介绍见:https://blog.csdn.net/wxz258/article/details/136442339。
camunda流程引擎内部有历史记录事件流的机制,在流程执行过程中,会产生大量的历史数据,这些历史数据可以通过历史记录级别参数来设置,也可以通过API接口查询这些历史实例数据,或者通过历史实例任务数据进行统计分析,找到业务流程执行瓶颈,或者为业务KPI考核提供依据。但大量的历史记录数据存储会对流程引擎的执行性能产生影响,这就需要通过设置历史记录的清理策略,根据不同的业务需要定时删除历史数据。本文重点介绍如何设置camunda的历史记录级别、如何查询历史实例数据、如何进行统计分析、如何删除清理历史记录数据。
1、流程历史记录产生原理
camunda的历史事件流提供有关已执行流程实例的历史信息,执行原理图如下:
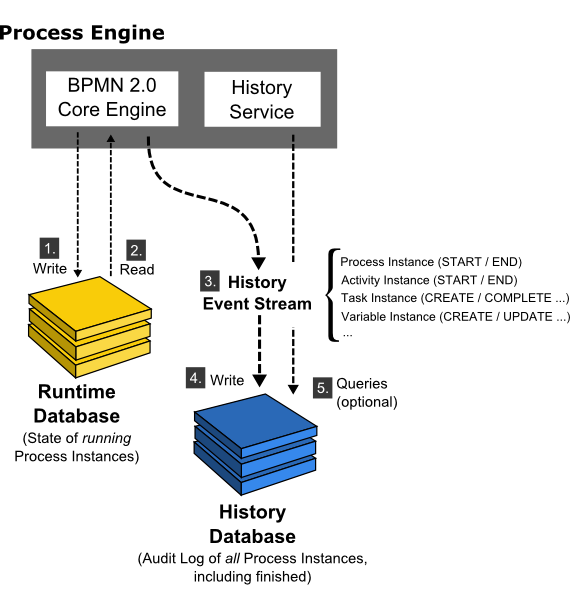
流程引擎维护数据库内正在运行的流程实例的状态。这包括在流程实例达到等待状态时将 (1.) 流程实例的状态写入数据库,并在流程执行继续时读取 (2.)流程执行继续时的状态。我们将此数据库称为运行时数据库。除了维护运行时状态外,流程引擎还创建审计日志,提供有关已执行流程实例的审计信息。我们将此事件流称为历史事件流 (3.)。构成此事件流的单个事件称为历史事件,包含有关已执行流程实例、活动实例、更改的流程变量等的数据。在默认配置中,流程引擎将简单地将 (4.) 此事件流写入历史记录数据库。HistoryService API 允许查询此数据库 (5.)。历史记录数据库和历史记录服务是可选组件;如果历史记录事件流未记录到历史记录数据库,或者用户选择将事件记录到其他数据库,则流程引擎仍能够工作,并且仍能够填充历史记录事件流。这是可能的,因为 BPMN 2.0 核心引擎组件不会从历史数据库中读取状态。也可以使用流程引擎配置中的historyLevel设置来配置记录的数据量。
由于流程引擎不依赖于历史数据库的存在来生成历史事件流,因此可以提供不同的后端来存储历史事件流。默认后端DbHistoryEventHandler是将事件流记录到历史数据库的后端。可以交换后端,为历史事件日志提供自定义存储机制。
2、流程历史记录级别介绍
历史记录级别控制流程引擎通过历史记录事件流提供的数据量,该参数的设置会影响流程引擎性能,尤其是历史数据比较多的情况下,项目上要根据具体需求设置合适的历史记录级别。
- NONE:不会触发任何历史记录事件。
- ACTIVITY:触发以下事件:
- 流程实例 START、UPDATE、END、MIGRATE:在启动、更新、结束和迁移流程实例时触发
- 案例实例 CREATE、UPDATE、CLOSE:在创建、更新和关闭案例实例时触发
- 活动实例START, UPDATE, END, MIGRATE:在启动、更新、结束和迁移活动实例时触发
- 案例活动实例 CREATE, UPDATE, END:在创建、更新和结束案例活动实例时触发
- 任务实例 CREATE、UPDATE、COMPLETE、DELETE、MIGRATE:在创建、更新(即重新分配、委派等)、完成、删除和迁移任务实例时触发。
- AUDIT:除了历史记录ACTIVITY级别提供的事件外,还会触发以下事件:
- 变量实例 CREATE、UPDATE、DELETE、MIGRATE:在创建、更新、删除和迁移流程变量时触发。缺省历史记录后端 (DbHistoryEventHandler) 将变量实例事件写入历史变量实例数据库表。此表中的行会随着变量实例的更新而更新,这意味着只有流程变量的最后一个值可用。
- FULL:除了历史记录AUDIT级别提供的事件外,还会触发以下事件:
- 表单属性 UPDATE:在创建和/或更新表单属性时触发。
- 默认历史记录后端 (DbHistoryEventHandler) 将历史变量更新写入数据库。这样就可以使用历史记录服务检查过程变量的中间值。
- 用户操作日志 UPDATE:当用户执行声明用户任务、委派用户任务等操作时触发。
- 事件创建、删除、解决、迁移:在创建、删除、解决和迁移事件时触发
- 历史作业日志 CREATE、FAILED、SUCCESSFUL、DELETED:在创建作业、作业执行失败或成功或作业被删除时触发
- 决策实例评估:当 DMN 引擎评估决策时触发。
- 批处理 START、END:在批次开始和结束时触发
- 身份链接 ADD、DELETE:在添加、删除身份链接或设置或更改用户任务的受让人以及设置或更改用户任务的所有者时触发。
- 历史外部任务日志 CREATED, DELETED, FAILED, SUCCESSFUL:在创建、删除外部任务或报告外部任务执行失败或成功时触发。
- AUTO:如果您计划在同一数据库上运行多个引擎,则auto级别很有用。在这种情况下,所有引擎都必须使用相同的历史级别。无需手动使配置保持同步,而是使用auto级别,引擎会自动确定数据库中已配置的级别。如果未找到,则使用默认值audit。请记住:如果您计划使用自定义历史记录级别,则必须为每个配置注册自定义级别,否则会引发异常。
如果需要自定义记录的历史事件量,可以提供自定义实现 HistoryEventProducer,并将其连接到流程引擎配置中。
3、如何设置历史记录级别
3.1、通过Java接口设置
历史记录级别可以作为流程引擎配置中的属性提供。根据流程引擎的配置方式,可以使用 Java 代码设置该属性:
ProcessEngine processEngine = ProcessEngineConfiguration.createProcessEngineConfigurationFromResourceDefault().setHistory(ProcessEngineConfiguration.HISTORY_FULL).buildProcessEngine();3.2、通过配置文件设置
也可以使用 Spring XML 或部署描述符(bpm-platform.xml、processes.xml)来设置它。
<property name="history">audit</property>
请注意,使用默认历史后端时,历史级别存储在数据库中,以后无法更改。
如果使用Camunda Platform Cockpit Web 应用程序,历史记录级别设置为FULL时效果最佳,“较低”历史记录级别将禁用某些与历史记录相关的功能。
3.3、自定义历史记录级别
要提供自定义历史记录级别,请使用接口org.camunda.bpm.engine.impl.history。必须实现HistoryLevel。然后,必须通过配置或流程引擎插件将自定义历史级别的实现添加到流程引擎配置中。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="processEngineConfiguration" class="org.camunda.bpm.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration" ><property name="customHistoryLevels"><list><bean class="org.camunda.bpm.example.CustomHistoryLevel" /></list></property></bean>
</beans>自定义历史记录级别必须为新历史记录级别提供唯一的 ID 和名称。
public int getId() {return 42;
}
public String getName() {return "custom-history";
}如果启用了历史记录级别,则该方法
boolean isHistoryEventProduced(HistoryEventType eventType, Object entity)
为每个历史事件调用,以确定是否应将该事件保存到历史中。引擎中使用的事件类型可以在org.camunda.bpm.engine.impl.history.event中找到。HistoryEventTypes(请参阅Javadocs)。
第二个参数是触发事件的实体,例如流程实例、活动实例或变量实例。如果实体为null,则引擎测试历史级别是否通常处理此类历史事件。如果该方法返回false,则引擎将不会再次生成任何此类历史事件。这意味着,如果您的历史级别只想为某个事件的某些实例生成历史事件,那么如果实体为null,它仍然必须返回true。
请看一下这个完整的例子https://github.com/camunda/camunda-bpm-examples/tree/master/process-engine-plugin/custom-history-level,以获得更好的理解。
4、如何查询历史记录数据
默认历史记录数据库将历史记录事件写入相应的数据库表。然后,可以使用HistoryService或REST API查询数据库表。
4.1、历史实体
有以下 History 实体,与运行时数据相反,在流程和案例实例完成后,这些实体也将保留在数据库中:
- HistoricProcessInstances包含有关当前和过去流程实例的信息。
- HistoricVariableInstances包含有关流程实例中保存的变量的最新状态的信息。
- HistoricCaseInstances包含有关当前和过去案例实例的信息。
- HistoricActivityInstances包含有关活动的单次执行的信息。
- HistoricCaseActivityInstances包含有关案例活动的单个执行的信息。
- HistoricTaskInstances包含有关当前和过去(已完成和已删除)任务实例的信息。
- HistoricDetails包含与历史流程实例、活动实例或任务实例相关的各种信息。
- HistoricIncidents包含有关当前和过去(即已删除或已解决)事件的信息。
- UserOperationLogEntry包含有关用户执行的操作的信息的日志条目。这用于记录操作,例如创建新任务、完成任务等。
- HistoricJobLog包含有关作业执行的信息。该日志提供有关作业生命周期的详细信息。
- HistoricDecisionInstance包含有关决策的单个评估的信息,包括输入值和输出值。
- HistoricBatch包含有关当前批次和过去批次的信息。
- HistoricIdentityLinkLog包含有关当前和过去(添加、删除、设置或更改任务分配对象以及设置或更改所有者)身份链接的信息。
- HistoricExternalTaskLog包含有关外部日志的信息。该日志提供有关外部任务生命周期的详细信息。
HistoricProcessInstances 的状态。对于每个流程实例,流程引擎将在历史记录数据库中创建单个记录,并将在流程执行期间不断更新此记录。每个 HistoricProcessInstance 记录都可以分配以下状态之一:
- ACTIVE - 正在运行的流程实例
- SUSPENDED - 挂起的流程实例
- COMPLETED - 通过正常结束事件完成
- EXTERNALLY_TERMINATED - 在外部终止,例如通过 REST API
- INTERNALLY_TERMINATED - 在内部终止,例如通过终止边界事件
4.2、查询历史记录
HistoryService公开了方法createHistoricProcessInstanceQuery()、createHistoricalVariableInstanceQuery(),createHistoryDecisionInstanceQuery()、createHistoryBatchQuery(),createHistoryExternalTaskLogQuery等方法可用于查询历史。
下面是一些示例,它们显示了如何查询 API 对历史记录。
获取所有已完成流程中完成且完成时间最长(持续时间最长)的十个历史流程实例,定义为“XXX”。
historyService.createHistoricProcessInstanceQuery().finished().processDefinitionId("XXX").orderByProcessInstanceDuration().desc().listPage(0, 10);获取所有已关闭案例中已关闭且关闭时间最长(持续时间最长)的十个案例实例,定义为“XXX”。
historyService.createHistoricCaseInstanceQuery().closed().caseDefinitionId("XXX").orderByCaseInstanceDuration().desc().listPage(0, 10);获取所有任务中已完成且完成时间最长(持续时间最长)的 10 个历史任务实例 。
historyService.createHistoricTaskInstanceQuery().finished().orderByHistoricTaskInstanceDuration().desc().listPage(0, 10);.list();查询失败的历史外部任务日志:
historyService.createHistoricExternalTaskLogQuery().failureLog().list();4.3、检索历史报告
您可以使用报告部分来检索自定义统计信息和报告。目前支持以下类型的报告:
- 实例持续时间报告
- 任务报告
- 已完成实例报告
4.3.1、实例持续时间报告
检索有关已完成流程实例的持续时间的报告,该报告按指定的周期分组。这些报告包括在指定时间段内启动的所有已完成流程实例的最大、最小和平均持续时间。以下代码段检索自引擎启动以来每个月的报告:
historyService.createHistoricProcessInstanceReport().duration(PeriodUnit.MONTH);到目前为止,支持的期间是org.camunda.bpm.engine.query中的MONTH和QUARTER。周期单位。
要缩小报告查询的范围,可以使用HistoricProcessInstanceReport中的以下方法:
- startedBefore:只考虑在给定日期之前启动的历史流程实例。
- startedAfter:只考虑在给定日期之后启动的历史流程实例。
- processDefinitionIdIn:只考虑给定流程定义ID的历史流程实例。
- processDefinitionKeyIn:只考虑给定流程定义键的历史流程实例。
例如,可以查询之前启动的所有历史流程实例,并获取它们的持续时间:
Calendar calendar = Calendar.getInstance();
historyService.createHistoricProcessInstanceReport().startedBefore(calendar.getTime()).duration(PeriodUnit.MONTH);4.3.2、任务报告
检索已完成任务的报告。对于任务报告,有两种可能的报告类型:计数和持续时间。
如果在报表查询的末尾使用countByProcessDefinitionKey或countByTaskName方法,则报表将包含已完成任务计数的列表,其中一个条目包含任务名称、任务的定义关键字、流程定义id、流程定义关键字、程序定义名称以及指定关键字在给定时间段内完成的任务数。方法countByProcessDefinitionKey和countByTaskName然后根据条件“definition key”或“task name”对计数报告进行分组。要检索按任务名称分组的任务计数报告,可以执行以下查询:
historyService.createHistoricTaskInstanceReport().countByTaskName();如果报告类型设置为持续时间,则报告包含给定时间段内所有已完成任务实例的最小、最大和平均持续时间值。
historyService.createHistoricTaskInstanceReport().duration(PeriodUnit.MONTH);支持的时间段时间和查询的限制类似于实例持续时间报告。
4.3.3、完成的实例报告
检索已完成流程、决策或案例实例的报告。该报告可帮助用户调整定义的历史生存时间。他们可以看到历史数据的摘要,这些数据可以在历史清理后进行清理。输出字段是定义id、键、名称、版本、已完成实例的计数和“可清理”实例的计数。
historyService.createHistoricFinishedProcessInstanceReport().list();
historyService.createHistoricFinishedDecisionInstanceReport().list();
historyService.createHistoricFinishedCaseInstanceReport().list();注意:以上的方法直接查询camunda流程实例运行的历史数据库,可能会对正在执行的流程实例执行效率造成影响,在实际的项目中,不建议这样直接查询流程执行库,可以把历史实例数据同步到备份库进行统计查询,如云程低代码平台中的流程分析功能,就采用了流程实例数据定时和手动同步方式,这样统计分析流程历史数据,不会到正在运行的实例造成影响。
访问地址:http://www.yunchengxc.com
5、如何清理删除历史记录
当大量使用时,流程引擎可以产生大量的历史数据。历史记录清理是一项功能,可根据可配置的生存时间设置删除此数据。但对于我们国内使用最多的OA审批流程,会涉及到流程审批意见、流程流转记录等是需要长时间保留的,不能直接删除,可以通过归档方式实现对历史记录表的清理。
清理流程历史记录将删除如下数据:
- 历史流程实例以及所有相关的历史数据(例如,历史变量实例、历史任务实例、历史实例权限、与其相关的所有注释和附件等)
- 历史决策实例以及所有相关的历史数据(即历史决策输入和输出实例)
- 历史案例实例以及所有相关的历史数据(例如,历史变量实例、历史任务实例等)
- 历史批次以及所有相关的历史数据(历史事件和作业日志)
历史记录清理可以手动触发,也可以定期安排。只有流程管理员有权手动执行历史记录清理。
通过示例理解历史记录如何清理。假设我们有一个计费流程,出于法律合规原因,我们必须将历史记录保留十年。然后我们有一个假期申请流程,其中历史数据仅在短时间内相关。为了减少我们必须存储的数据量,我们希望快速删除与假期相关的数据。
通过历史记录清理,我们可以为计费流程分配十年的生存历史时间,为假日流程分配七天的生存历史时间。然后,历史记录清理可确保在生存时间到期时删除历史记录数据。这样,我们就可以根据历史数据对我们业务的重要性有选择地保留历史数据。同时,我们只在数据库中保留必要的内容。
注意:删除数据的确切时间取决于几个配置设置,例如所选的历史记录清理策略。以下介绍了基本概念和设置。
5.1、基本概念
5.1.1、可清理实例
Camunda 历史的以下元素是可清除的:
- 流程实例
- 决策实例
- 案例实例
- 批处理
请注意,清理一个这样的实例总是会删除所有依赖的历史数据。例如,清理流程实例会删除历史流程实例以及所有历史活动实例、历史任务实例等。
5.1.2、历史生存时间 (TTL)
历史生存时间 (TTL) 定义历史数据在清理之前应在数据库中保留多长时间。
- 流程、案例和决策实例:TTL 可以在相应定义的 XML 文件中定义。此外,还可以在通过 Java 和 REST API 部署后更改此值。
- 批处理:TTL 可以在流程引擎配置中定义。
有关如何设置 TTL,请参阅 TTL 配置部分:https://docs.camunda.org/manual/latest/user-guide/process-engine/history/#history-time-to-live。
5.1.3、实例结束时间
结束时间是实例不再处于活动状态的时间。
- 流程实例:实例完成的时间。
- 决策实例:评估决策的时间。
- 案例实例:实例完成的时间。
- 批处理:批处理完成的时间。
结束时间保留在相应的实例表ACT_HI_PROCINST、ACT_HI_CASEINST、ACT_HI_DECINST和ACT_HI_BATCH中。
5.1.4、实例移除时间
删删除时间是指删除实例的时间。其计算方式为移除时间=基准时间+TTL。基准时间是可配置的,可以是实例的开始时间或结束时间。
- 流程实例:基准时间是流程实例开始的时间或完成的时间。这是可配置的。
- 决策实例:基准时间是评估决策的时间。
- 案例实例:不为案例实例实现删除时间概念。
- 批处理:基准时间是创建批次或批次完成的时间。这是可配置的。
删除时间保留在所有历史记录表中。因此,在流程实例的情况下,删除时间存在于ACT_HI_PROCINST以及ACT_HI_ACTINST、ACT_HI_TASKINST等中的相应辅助条目中。
请参阅删除时间策略配置部分https://docs.camunda.org/manual/latest/user-guide/process-engine/history/#removal-time-strategy,了解如何配置删除时间是基于实例的开始时间还是结束时间。
5.2、清理策略
要使用历史记录清理,您必须决定使用两种可用的历史记录清理策略之一:基于删除时间(Removal-Time-based)或基于结束时间(End-Time-based)的策略。基于删除时间的策略是默认策略,建议在大多数情况下使用。以下详细介绍了这些策略及其差异。有关如何配置每个策略的信息,请参阅清理策略配置部分。
5.2.1、基于时间的移除策略
基于删除时间的清理策略将删除删除时间已过期的数据。
优势:
- 由于每个历史表都有一个删除时间属性,因此可以使用简单的DELETE FROM <TABLE> WHERE REMOVAL_TIME_ < <now> SQL语句来完成历史清理。这比基于结束时间的清理效率高得多。
- 由于层次结构中所有实例的删除时间都是一致的,因此一旦删除时间到期,层次结构总是会被完全清除。不可能在不同的时间删除实例。
局限性:
- 只能删除设置了删除时间的数据。对于使用 Camunda 版本 < 7.10.0 创建的数据,情况尤其如此。
- 更改定义的 TTL 仅适用于将来创建的历史数据。它不会动态更新已写入历史数据的删除时间。但是,可以通过批量操作设置删除时间。
- 案例实例的历史数据不会被清理。
5.2.2、基于结束时间的策略
基于结束时间的清理策略会删除结束时间加上 TTL 已过期的数据。与删除时间策略相比,每当执行历史记录清理时,都会计算此值。
优势:
- 更改定义的 TTL 也会影响已写入的历史数据。
- 可以从任何 Camunda 版本中删除数据。
局限性:
- 结束时间仅存储在实例表(ACT_HI_PROCINST、ACT_HI_CASEINST、ACT_HI_DECINST和ACT_HI_BATCH)中。要从所有历史表中删除数据,首先通过SELECT语句获取可清理实例。在此基础上,为每个历史表生成DELETE语句。这些语句可能涉及联接。这比基于删除时间的历史记录清理效率低。
- 实例层次结构不是以原子方式清理的。由于各个实例具有不同的结束时间,因此将在不同的时间对它们进行清理。因此,层次结构可能显示为部分删除。
- 未清理历史实例权限。
- 历史清理作业不会从历史作业日志中删除。
5.3、历史记录清理配置
5.3.1、TTL的设置
只有当流程实例的相应定义具有有效的生存时间(TTL)时,才会对其进行清理。使用流程定义的“historyTimeToLive”扩展属性来定义其所有实例的TTL:
<process id="oneTaskProcess" name="The One Task Process" isExecutable="true" camunda:historyTimeToLive="5">
...
</process>TTL 也可以用日期格式定义。该函数仅接受用于定义天数的表示法。
<process id="oneTaskProcess" name="The One Task Process" isExecutable="true" camunda:historyTimeToLive="P5D">
...
</process>部署后,TTL 可以通过 Java API 进行更新:
processEngine.getRepositoryService().updateProcessDefinitionHistoryTimeToLive(processDefinitionId, 5);将该值设置为清除 TTL。同样可以通过 REST API 完成。
对于决策和案例定义,可以用类似的方式定义 TTL。
如果要为所有流程、决策和案例定义提供引擎范围的默认 TTL,请使用流程引擎配置的“historyTimeToLive”属性。每当部署不带 TTL 的新定义时,此值将作为默认值应用。请注意,因此它不会更改已部署定义的 TTL。在这种情况下,使用上面给出的 API 方法更改 TTL。
5.3.2、Task任务指标
流程引擎向数据库报告运行时指标,这些指标可以帮助得出有关Camunda BPM平台的使用、负载和性能的结论。每次分配用户任务时,相关任务工作者都会作为假名固定长度值与时间戳一起存储在ACT_RU_TASK_METER_LOG表中。如果需要,需要显式配置此数据的清理。
taskMetricsTimeToLive属性可用于为用户任务分配产生的任务度量条目定义TTL。该属性接受ISO-8601日期格式的值。请注意,只允许使用定义天数的符号。
<property name="taskMetricsTimeToLive">P540D</property>如果您是企业客户,您的许可协议可能要求您每年报告一些指标。请将任务指标存储ACT_RU_TASK_METER_LOG至少 18 个月,直到它们被报告。
5.3.3、设置清理作业定时器
历史记录清理通过作业定时器实现,并由作业执行程序执行。清理窗口要确定运行历史记录清理的时间范围。建议在系统负载很小时(例如在夜间或周末)使用作业执行程序的资源。默认值:未定义清理窗口。这意味着不会自动执行历史记录清理。
对于定期自动历史记录清理,必须配置批处理窗口 - 一天中运行清理的时间段。
使用以下引擎配置属性为一周中的每一天定义批处理窗口:
<property name="historyCleanupBatchWindowStartTime">20:00</property>
<property name="historyCleanupBatchWindowEndTime">06:00</property>清理也可以单独安排一周中的每一天(例如,仅在周末运行清理):
<!-- default for all weekdays -->
<property name="historyCleanupBatchWindowStartTime">20:00</property>
<property name="historyCleanupBatchWindowEndTime">06:00</property><!-- overriding batch window for saturday and sunday -->
<property name="saturdayHistoryCleanupBatchWindowStartTime">06:00</property>
<property name="saturdayHistoryCleanupBatchWindowEndTime">06:00</property>
<property name="sundayHistoryCleanupBatchWindowStartTime">06:00</property>
<property name="sundayHistoryCleanupBatchWindowEndTime">06:00</property>默认情况下,未配置任何清理窗口。在这种情况下,不会自动执行历史记录清理。
5.3.4、设置清理策略
可以按如下方式选择基于删除时间或基于结束时间的清理:
<property name="historyCleanupStrategy">removalTimeBased</property>有效值为removalTimeBased和endTimeBased。removalTimeBased是默认值。
这篇关于Camunda7历史记录级别配置和历史数据清理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





