本文主要是介绍【Python】科研代码学习:三 PreTrainedModel, PretrainedConfig, PreTrainedTokenizer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【Python】科研代码学习:三 PreTrainedModel, PretrainedConfig, PreTrainedTokenizer
- 前言
- Models : PreTrainedModel
- PreTrainedModel 中重要的方法
- tensorflow & pytorch 简单对比
- Configuration : PretrainedConfig
- PretrainedConfig 中重要的方法
- Tokenizer : PreTrainedTokenizer
- PreTrainedTokenizer 中重要的方法
前言
- HF 官网API
本文主要从官网API与源代码中学习调用HF的关键模组
Models : PreTrainedModel
- HF 提供的基础模型类有
PreTrainedModel, TFPreTrainedModel, and FlaxPreTrainedModel - 这三者有什么区别呢
PreTrainedModel指的是用torch的框架
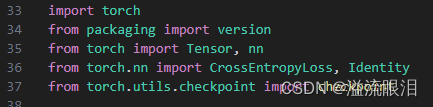
TFPreTrainedModel指的是用tensorflow框架
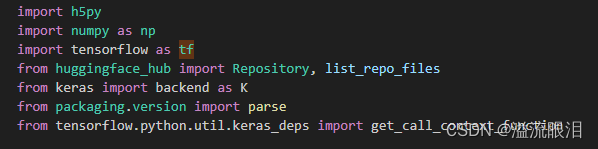
FlaxPreTrainedModel指的是用flax框架,是用jax做的
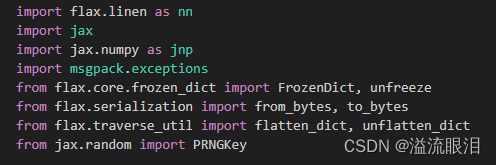
(哈哈,搜了好久都没搜到,去看源码导包瞬间明白了,也可能是我比较笨) - Transformers的大部分模型都会继承PretrainedModel基类。PretrainedModel主要负责管理模型的配置,模型的参数加载、下载和保存。
- PretrainedModel继承自
nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin, PeftAdapterMixin
在初始化时需要提供给它一个config: PretrainedConfig - 所以,我们可以视为它是所有模型的基类
可以看到很多其他代码在判断模型类型时,一般写model: Union[PreTrainedModel, nn.Module]
PreTrainedModel 中重要的方法
- push_to_hub:将模型传到HF hub
from transformers import AutoModelmodel = AutoModel.from_pretrained("google-bert/bert-base-cased")# Push the model to your namespace with the name "my-finetuned-bert".
model.push_to_hub("my-finetuned-bert")# Push the model to an organization with the name "my-finetuned-bert".
model.push_to_hub("huggingface/my-finetuned-bert")
- from_pretrained:根据config实例化预训练pytorch模型(Instantiate a pretrained pytorch model from a pre-trained model configuration.)
默认使用评估模式.eval()
可以打开训练模式.train()
看下面的例子,可以从官方加载,也可以从本地模型参数加载。如果本地参数是tf的,转pytorch需要设置from_tf=True,并且会慢些;本地参数是flax的话类似同理。
from transformers import BertConfig, BertModel# Download model and configuration from huggingface.co and cache.
model = BertModel.from_pretrained("google-bert/bert-base-uncased")
# Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
model = BertModel.from_pretrained("./test/saved_model/")
# Update configuration during loading.
model = BertModel.from_pretrained("google-bert/bert-base-uncased", output_attentions=True)
assert model.config.output_attentions == True
# Loading from a TF checkpoint file instead of a PyTorch model (slower, for example purposes, not runnable).
config = BertConfig.from_json_file("./tf_model/my_tf_model_config.json")
model = BertModel.from_pretrained("./tf_model/my_tf_checkpoint.ckpt.index", from_tf=True, config=config)
# Loading from a Flax checkpoint file instead of a PyTorch model (slower)
model = BertModel.from_pretrained("google-bert/bert-base-uncased", from_flax=True)
可以给 torch_dtype 设置数据类型。若不给,则默认为 torch.float16。也可以给 torch_dtype="auto"
- get_input_embeddings:获得输入的词嵌入
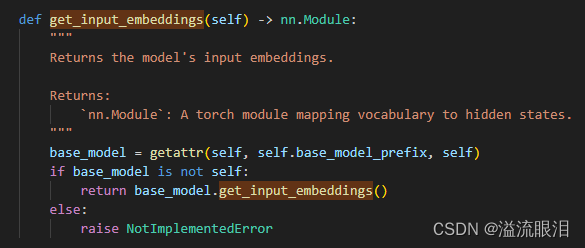
对应还有 get_output_embeddings - init_weights:设置参数初始化
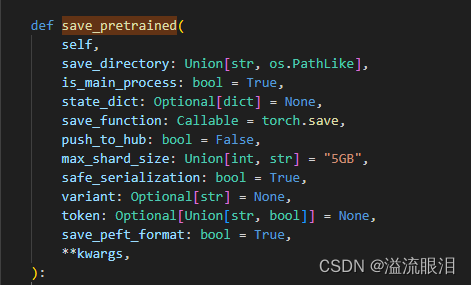
如果需要自己调整参数初始化的,在_init_weights,_initialize_weights中设置 - save_pretrained:把模型和配置参数保存在文件夹中
保存完后,便可以通过 from_pretrained 再次加载模型了
tensorflow & pytorch 简单对比
- 知乎:Tensorflow 到底比 Pytorch 好在哪里?
下面截取了比较重要的图
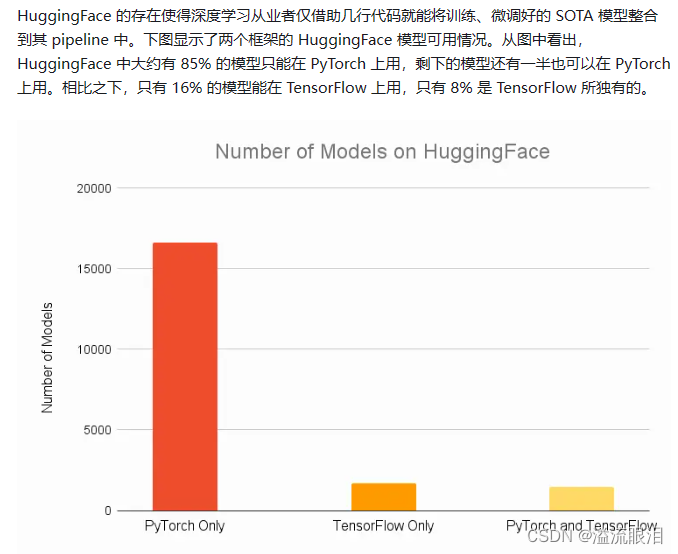
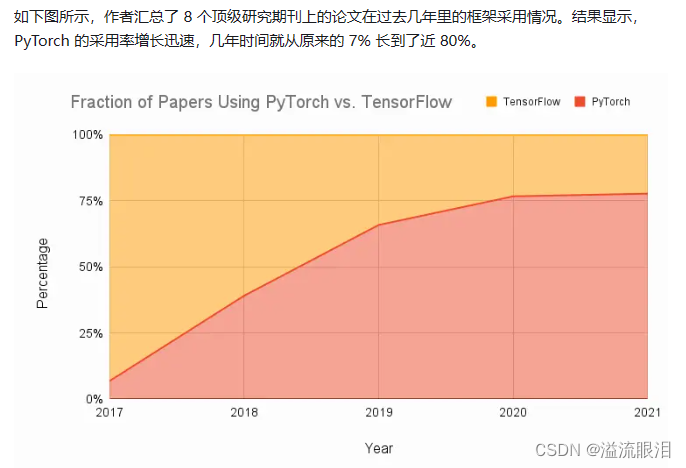
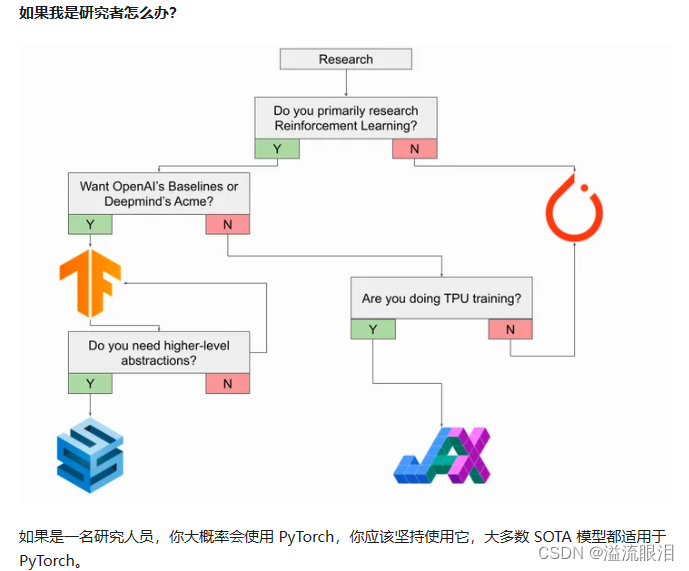
- 里面还提到了一个内容叫做
Keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化
Configuration : PretrainedConfig
- 刚才看了,对于
PretrainedModel初始化提供的参数是PretrainedConfig类型的参数。
它主要为不同的任务,提供了不同的重要参数
HF官网:PretrainedConfig - 列一下对于NLP中比较重要的参数吧,所有的就看官方文档吧
返回信息
output_hidden_states (bool, optional, defaults to False) — Whether or not the model should return all hidden-states.
output_attentions (bool, optional, defaults to False) — Whether or not the model should returns all attentions.
return_dict (bool, optional, defaults to True) — Whether or not the model should return a ModelOutput instead of a plain tuple.
output_scores (bool, optional, defaults to False) — Whether the model should return the logits when used for generation.
return_dict_in_generate (bool, optional, defaults to False) — Whether the model should return a ModelOutput instead of a torch.LongTensor.序列生成
max_length (int, optional, defaults to 20) — Maximum length that will be used by default in the generate method of the model.
min_length (int, optional, defaults to 0) — Minimum length that will be used by default in the generate method of the model.
do_sample (bool, optional, defaults to False) — Flag that will be used by default in the generate method of the model. Whether or not to use sampling ; use greedy decoding otherwise.
num_beams (int, optional, defaults to 1) — Number of beams for beam search that will be used by default in the generate method of the model. 1 means no beam search.
diversity_penalty (float, optional, defaults to 0.0) — Value to control diversity for group beam search. that will be used by default in the generate method of the model. 0 means no diversity penalty. The higher the penalty, the more diverse are the outputs.
temperature (float, optional, defaults to 1.0) — The value used to module the next token probabilities that will be used by default in the generate method of the model. Must be strictly positive.
top_k (int, optional, defaults to 50) — Number of highest probability vocabulary tokens to keep for top-k-filtering that will be used by default in the generate method of the model.
top_p (float, optional, defaults to 1) — Value that will be used by default in the generate method of the model for top_p. If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.
epetition_penalty (float, optional, defaults to 1) — Parameter for repetition penalty that will be used by default in the generate method of the model. 1.0 means no penalty.
length_penalty (float, optional, defaults to 1) — Exponential penalty to the length that is used with beam-based generation. It is applied as an exponent to the sequence length, which in turn is used to divide the score of the sequence. Since the score is the log likelihood of the sequence (i.e. negative), length_penalty > 0.0 promotes longer sequences, while length_penalty < 0.0 encourages shorter sequences.
bad_words_ids (List[int], optional) — List of token ids that are not allowed to be generated that will be used by default in the generate method of the model. In order to get the tokens of the words that should not appear in the generated text, use tokenizer.encode(bad_word, add_prefix_space=True).tokenizer相关
bos_token_id (int, optional) — The id of the beginning-of-stream token.
pad_token_id (int, optional) — The id of the padding token.
eos_token_id (int, optional) — The id of the end-of-stream token.PyTorch相关
torch_dtype (str, optional) — The dtype of the weights. This attribute can be used to initialize the model to a non-default dtype (which is normally float32) and thus allow for optimal storage allocation. For example, if the saved model is float16, ideally we want to load it back using the minimal amount of memory needed to load float16 weights. Since the config object is stored in plain text, this attribute contains just the floating type string without the torch. prefix. For example, for torch.float16 `torch_dtype is the "float16" string.常见参数
vocab_size (int) — The number of tokens in the vocabulary, which is also the first dimension of the embeddings matrix (this attribute may be missing for models that don’t have a text modality like ViT).
hidden_size (int) — The hidden size of the model.
num_attention_heads (int) — The number of attention heads used in the multi-head attention layers of the model.
num_hidden_layers (int) — The number of blocks in the model.
PretrainedConfig 中重要的方法
- push_to_hub:依然是上传到 HF hub
- from_dict:把一个 dict 类型转到 PretrainedConfig 类型
- from_json_file:把一个 json 文件转到 PretrainedConfig 类型,传入的是文件路径
- to_dict:转成 dict 类型
- to_json_file:保存到 json 文件
- to_json_string:转成 json 字符串
- from_pretrained:从预训练模型配置文件中直接获取配置
可以是HF模型,也可以是本地模型,见下方例子
# We can't instantiate directly the base class *PretrainedConfig* so let's show the examples on a
# derived class: BertConfig
config = BertConfig.from_pretrained("google-bert/bert-base-uncased"
) # Download configuration from huggingface.co and cache.
config = BertConfig.from_pretrained("./test/saved_model/"
) # E.g. config (or model) was saved using *save_pretrained('./test/saved_model/')*
config = BertConfig.from_pretrained("./test/saved_model/my_configuration.json")
config = BertConfig.from_pretrained("google-bert/bert-base-uncased", output_attentions=True, foo=False)
assert config.output_attentions == True
config, unused_kwargs = BertConfig.from_pretrained("google-bert/bert-base-uncased", output_attentions=True, foo=False, return_unused_kwargs=True
)
assert config.output_attentions == True
assert unused_kwargs == {"foo": False}
- save_pretrained:把配置文件保存到文件夹中,方便下次 from_pretrained 直接读取
Tokenizer : PreTrainedTokenizer
- HF官网:PreTrainedTokenizer
Tokenizer 是用来把输入的字符串,转成 id 数组用的
先来看一下其中相关的类的继承关系
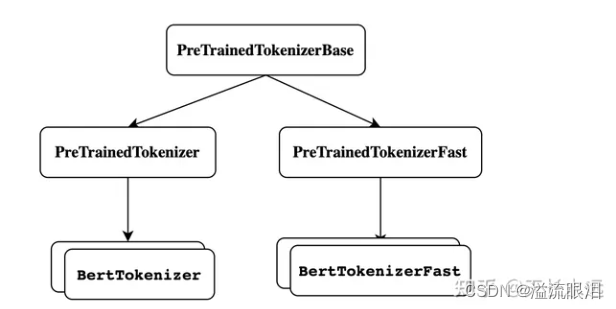
- PreTrainedTokenizer 的初始化方法是直接给了 **kwargs
调几个重要的列在下面,可以看到大部分都是设置一些token的含义。
bos_token (str or tokenizers.AddedToken, optional) — A special token representing the beginning of a sentence. Will be associated to self.bos_token and self.bos_token_id.
eos_token (str or tokenizers.AddedToken, optional) — A special token representing the end of a sentence. Will be associated to self.eos_token and self.eos_token_id.
unk_token (str or tokenizers.AddedToken, optional) — A special token representing an out-of-vocabulary token. Will be associated to self.unk_token and self.unk_token_id.
sep_token (str or tokenizers.AddedToken, optional) — A special token separating two different sentences in the same input (used by BERT for instance). Will be associated to self.sep_token and self.sep_token_id.
pad_token (str or tokenizers.AddedToken, optional) — A special token used to make arrays of tokens the same size for batching purpose. Will then be ignored by attention mechanisms or loss computation. Will be associated to self.pad_token and self.pad_token_id.
cls_token (str or tokenizers.AddedToken, optional) — A special token representing the class of the input (used by BERT for instance). Will be associated to self.cls_token and self.cls_token_id.
mask_token (str or tokenizers.AddedToken, optional) — A special token representing a masked token (used by masked-language modeling pretraining objectives, like BERT). Will be associated to self.mask_token and self.mask_token_id.
PreTrainedTokenizer 中重要的方法
- add_tokens:添加一些新的token
它强调了,添加新token需要确保 token 嵌入矩阵与tokenizer是匹配的,即多调用一下resize_token_embeddings方法
# Let's see how to increase the vocabulary of Bert model and tokenizer
tokenizer = BertTokenizerFast.from_pretrained("google-bert/bert-base-uncased")
model = BertModel.from_pretrained("google-bert/bert-base-uncased")num_added_toks = tokenizer.add_tokens(["new_tok1", "my_new-tok2"])
print("We have added", num_added_toks, "tokens")
# Notice: resize_token_embeddings expect to receive the full size of the new vocabulary, i.e., the length of the tokenizer.
model.resize_token_embeddings(len(tokenizer))
- add_special_tokens:添加特殊tokens,比如之前的 eos,pad 等,与之前普通的tokens是不大一样的,但要确保该token不在词汇表里
# Let's see how to add a new classification token to GPT-2
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
model = GPT2Model.from_pretrained("openai-community/gpt2")special_tokens_dict = {"cls_token": "<CLS>"}num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
print("We have added", num_added_toks, "tokens")
# Notice: resize_token_embeddings expect to receive the full size of the new vocabulary, i.e., the length of the tokenizer.
model.resize_token_embeddings(len(tokenizer))assert tokenizer.cls_token == "<CLS>"
- encode, decode:字符串转id数组,id数组转字符串,即词嵌入
encode 和 self.convert_tokens_to_ids(self.tokenize(text)) 等价
decode 和 self.convert_tokens_to_string(self.convert_ids_to_tokens(token_ids)) 等价 - tokenize:把字符串转成token序列,即分词 str → list[str]
这篇关于【Python】科研代码学习:三 PreTrainedModel, PretrainedConfig, PreTrainedTokenizer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




