本文主要是介绍Python机器学习实践(二)K近邻分类(简单鸾尾花分类),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python机器学习 学习笔记与实践
环境:win10 + Anaconda3.8
例子二 源自《Python机器学习基础教程》—Andreas C.Muller
任务:鸾尾花的分类。鸾尾花有3个品种:setosa、versicolor、virginica。每种鸾尾花都有4个属性:花瓣的长度和宽度以及花萼的长度和宽度。现在要建立模型根据鸾尾花的4个属性来判断鸾尾花的种类,即分类问题。
1、获取数据
该数据集在scikit-learn的datasets模块中,我们用load_iris函数调用。
#获取鸾尾花数据集并观察键值
from sklearn.datasets import load_iris
iris_dataset=load_iris()
print(iris_dataset.keys())
iris_dataset数据类型是bunch,类似于字典,包含有键和值。运行结果如下:
dict_keys([‘data’, ‘target’, ‘frame’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’])
(1)'data’是花的四个属性值,‘target’是一个一维数组,data中的每一朵花对应target中的一个数据。target中用0,1,2分别表示三种类型的花。
(2)‘target_names‘’中保存了三种花的名字,‘feature_names’则保存了花的4个属性的名字。
可以自行用print分别打印各个参数,了解数据。
2、处理,显示数据
#将数据集分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
#观察数据,看看数据大致规律
import pandas as pd
import matplotlib.pyplot as plt
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)
grr=pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='.', hist_kwds={'bins':50},s=60,alpha=.8)
plt.show()
结果如下:
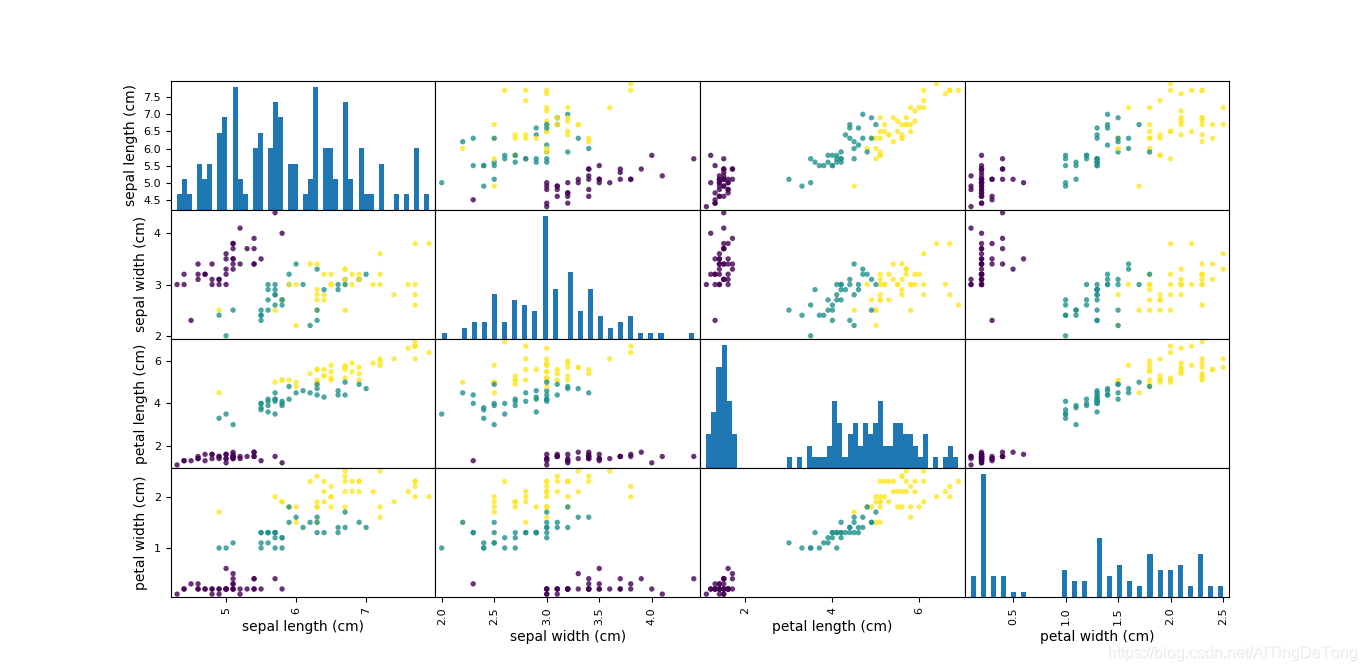
其中,反对角线上的图为该属性的直方图。
(1)用 train_test_split 函数将数据集分为两部分,一部分用来训练模型,另一部分用来作为测试集。默认情况下是训练集75%,测试集25%。由于有时候数据集在存储的时候是按一定顺序存储的,故在分片之前,该函数将产生伪随机序列打乱样本数据,而后进行分层。
“random_state”参数是初始化了伪随机序列的种子,从而使每一次运行结果一致。
(2)由于每个样本数据X都有4个属性,故在观察数据时绘制散点图矩阵。要注意如果不加plt.show()则图可能无法显示。
3、K近邻分类并评估
K近邻分类的思想比较简单,就是先保存训练集的结果,然后对于一个新样本过来,该算法在训练集里寻找和新样本“距离最近”的一个样本,并将它的标签进行输出。如果是K近邻,则是寻找“距离最近”的K个样本,然后输出这个样本中最多的类别标签。
例如K=1时有两个属性的样本散点图如下:

其中三角和圆分别训练集中表示不同的种类,五角星表示测试数据,模型找到与其最近的一个样本,并将该样本的标签给测试数据,图中用颜色表示。
同理,K=3时如下:
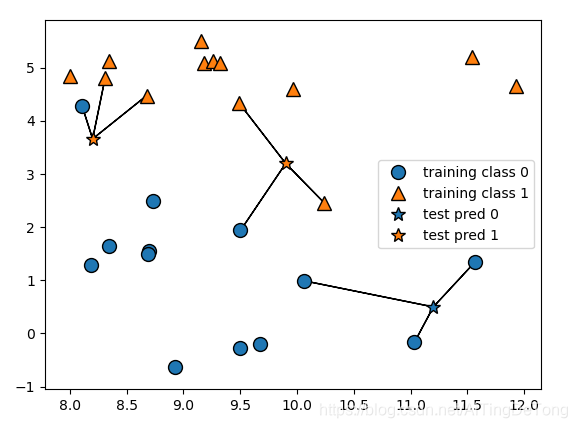
该部分代码如下:
#用K近邻算法分类
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
#用测试集数据评估模型
import numpy as np
y_predict=knn.predict(X_test)
print('Test score is {:.2f}'.format(np.mean(y_predict==y_test)))
#自己输入一个样本数据,看看模型输出结果
X_me=np.array([[5,2.9,1,0.2]])
Pred=knn.predict(X_me)
print('Prediction is : {} '.format(Pred))
print('The type of X_me is : {}'.format(iris_dataset['target_names'][Pred]))
运行结果如下:
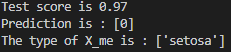
(1)本例在建立KNN模型时将n_neighbors设为1,即寻找“长得最像”的一个样本。
(2)Test score反映了该模型对于测试集的输出效果,即有97%的测试样本预测成功,也可以说对于接下来的新样本,我们有97%的把握认为它是正确的。
(3)在自己创建一个样本的时候,要将数据转为二维矩阵的一行,因为scikit-learn只能接受二维矩阵。
(4)尝试将K近邻改为2和5之后,发现Test score 和预测结果均没有变化。
4、完整代码
#获取鸾尾花数据集并观察键值
from sklearn.datasets import load_iris
iris_dataset=load_iris()
print(iris_dataset.keys())
#将数据集分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
#观察数据,看看数据大致规律
import pandas as pd
import matplotlib.pyplot as plt
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)
grr=pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='.', hist_kwds={'bins':50},s=60,alpha=.8)
plt.show()
#用K近邻算法分类
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
#用测试集数据评估模型
import numpy as np
y_predict=knn.predict(X_test)
print('Test score is {:.2f}'.format(np.mean(y_predict==y_test)))
#自己输入一个样本数据,看看模型输出结果
X_me=np.array([[5,2.9,1,0.2]])
Pred=knn.predict(X_me)
print('Prediction is : {} '.format(Pred))
print('The type of X_me is : {}'.format(iris_dataset['target_names'][Pred]))
这篇关于Python机器学习实践(二)K近邻分类(简单鸾尾花分类)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






