本文主要是介绍新库上线 | 你想要的新三板企业知识产权数据,在这里→,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多内容点击查看:新库上线 | 你想要的新三板企业知识产权数据,在这里→
一、前言
新三板诞生至今就被定位于为中小企业和民营经济提供金融服务的重要平台。对于中小企业来说,如何在激烈的市场经济中寻求自身的立足点至关重要。知识产权作为企业创新成果的重要体现,也是目前学界用于衡量企业创新潜力的重要指标。
基于此,我们创建了新三板企业知识产权数据库,系统全面的整理了有关新三板企业的专利和软著信息,以供学者们研究使用。其中,专利信息库中包含了新三板企业所有专利的基本信息以及按照企业年度归并后的企业层级的年度数据;软著信息同样也包含了软件著作权的基本信息和按照企业年度归并后的企业层级的年度数据。
二、数据库简介
(🔍点击查看大图)
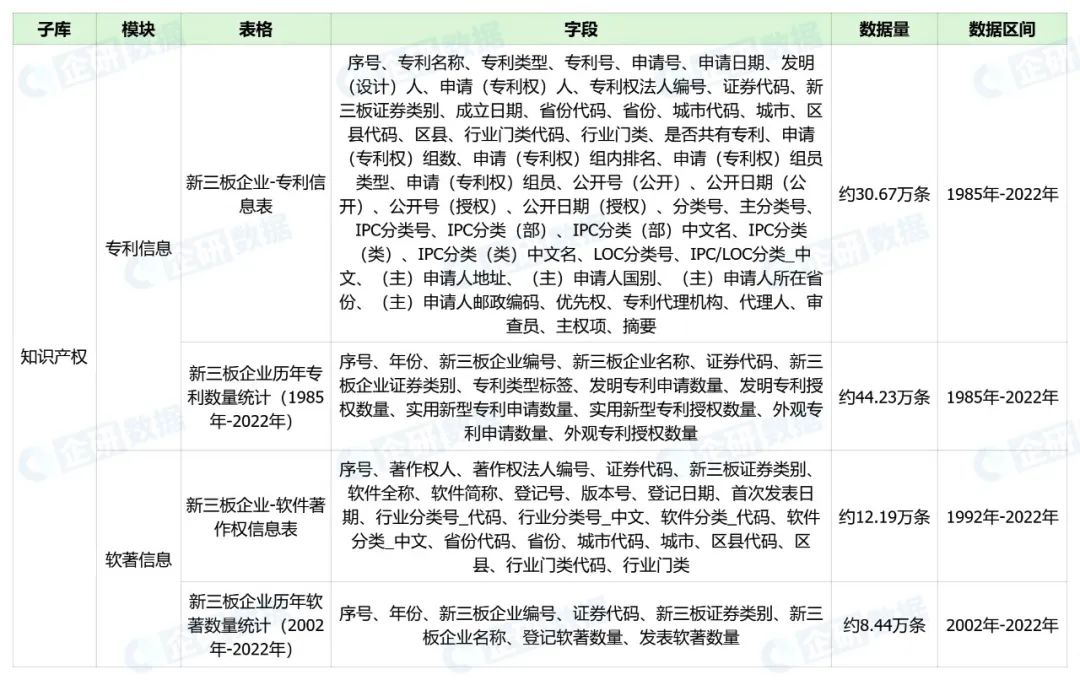
三、样例数据
因篇幅有限,推文只展示部分字段。完整数据请登录企研·社科大数据平台(https://r.qiyandata.com)或企研·数据超市(https://m.qiyandata.com)进行查询!
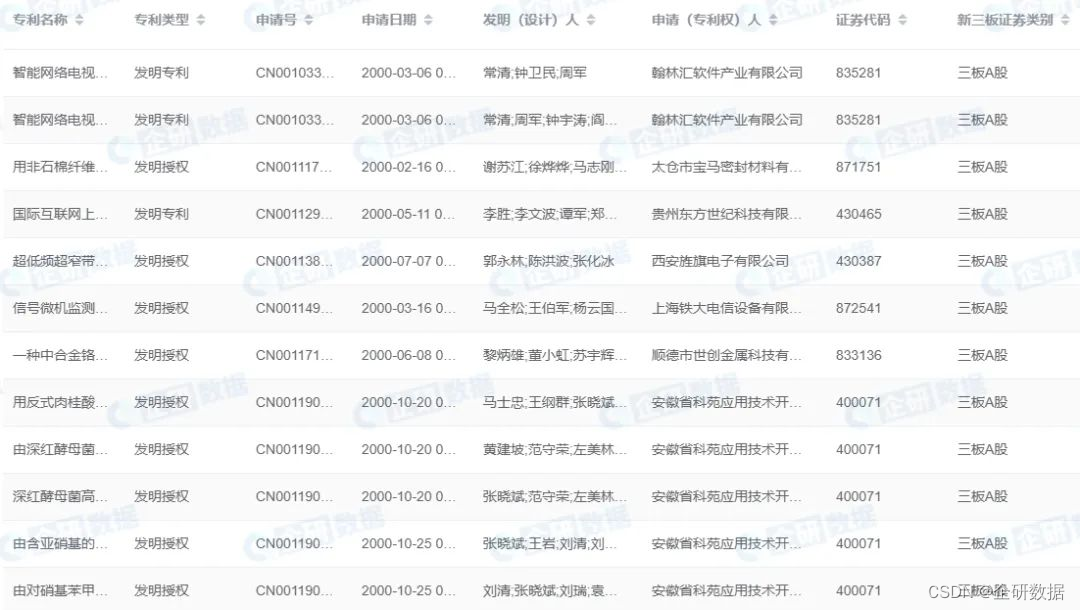 图一 新三板企业-专利信息表(部分)
图一 新三板企业-专利信息表(部分)

图二 新三板企业-软件著作权信息表 (部分)
四、数据应用
(一)《中国工业经济》:金融科技与企业创新——新三板上市公司的证据
金融科技与企业创新——新三板上市公司的证据
李春涛(中南财经政法大学金融学院)
闫续文(中南财经政法大学金融学院)
宋敏(武汉大学经济与管理学院)
杨威(武汉大学经济与管理学院)
摘要:金融科技催生出新的金融服务模式,这能否解决实体经济的融资难题从而促进企业创新呢?通过“金融科技”关键词百度新闻高级检索,本文创新性地构建了地区金融科技发展水平指标,并利用2011—2016年新三板上市公司数据,考察了金融科技发展对企业创新的影响及其机制。实证结果表明,金融科技发展显著促进了企业创新。就经济意义而言,城市的金融科技发展水平每提高1%,当地企业专利申请数量平均会增加约0.17项。作为一个宏观变量,地区金融科技发展水平受单个企业创新行为的影响较小,但是依然会存在测量误差和遗漏变量等内生性问题。本文运用接壤城市金融科技发展水平的均值作为工具变量,得到了一致的估计结果。本文的结果在替换企业创新指标、使用不同回归模型等一系列稳健性检验后仍然成立。机制分析表明,金融科技通过两个渠道促进企业创新,一是缓解企业的融资约束,二是提高税收返还的创新效应。异质性分析表明,金融科技促进企业创新的作用在东部地区和高科技行业表现得更为明显。在中国经济高质量发展背景下,持续推进金融科技发展、重塑金融行业生态格局,才能为实体经济提供源源不断的创新活力,从而推动创新型国家建设。
关键词:金融科技发展;企业创新;融资约束
文中所用新三板企业专利数据:

图源:原文
(二)《中国软科学》:转板能促进中小企业创新吗?——来自新三板转板企业的新证据
转板能促进中小企业创新吗?——来自新三板转板企业的新证据
薛海燕(山西财经大学会计学院)
张信东(山西大学经济与管理学院)
贺亚楠(山西财经大学会计学院)
摘要:运用多期双重差分和动态分析模型,考察新三板企业转板行为对其创新的影响及作用机制。结果表明,转板能显著促进企业创新投资和创新产出,且在转板后两年内促进效果明显。机制研究发现,转板通过增强外部监督和吸引创新人才促进了企业创新。异质性分析表明:转板对竞争能力较强企业的创新投资和创新产出促进效果明显;对于两权合一和创新能力较强的企业,转板有利于促进其创新投资,而对于非两权合一和创新能力较弱的企业,转板对其创新产出的促进效果更显著。进一步研究发现,转板并不能缓解企业融资约束,也不会加剧管理者短视,已有IPO影响企业创新的作用机制并不适用于转板情境。研究结论有助于科学评估新三板对中小企业创新的市场培育功能,为市场监管者通过转板制度安排促进中小企业创新提供实践证据。
关键词:转板;中小企业;创新;多期双重差分;动态分析
文中所用新三板企业专利数据:
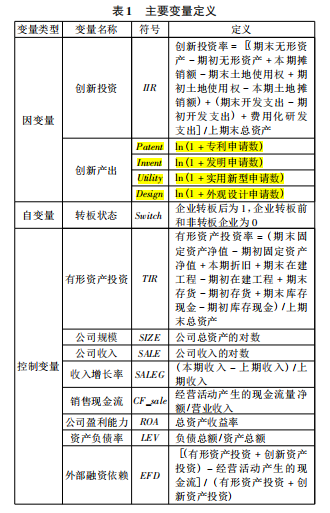
图源:原文
五、数据下载指南
本数据已在企研·社科大数据平台(https://r.qiyandata.com)及企研·数据超市(https://m.qiyandata.com)上线!
(一)机构用户直接下载
企研·社科大数据平台现为国内各大高校开通3-6月不等的试用期,可通过校内IP访问,查询下载数据。欢迎各位读者朋友向学校/机构图书馆推荐企研·社科大数据平台(https://r.qiyandata.com)!
>>>点此查看已开通试用高校名单
具体介绍参考文章:数据资源全攻略!你需要的科研数据都在这里,赶紧收藏!(附获取方式)
关于如何推荐请查看:企研·社科大数据平台 | 保姆级试用/采购推荐教程请收好!
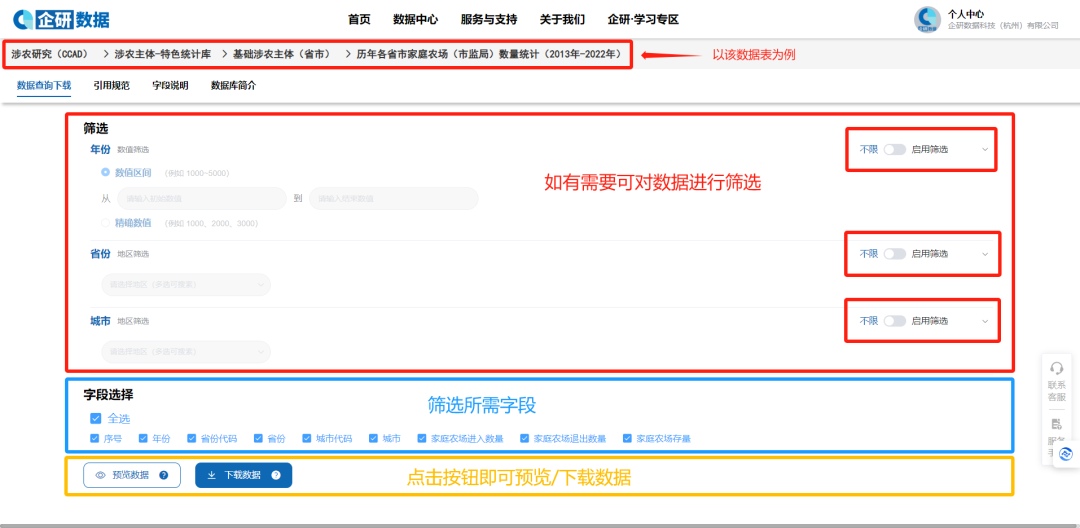
下载流程:
进入企研·社科大数据平台网站(https://r.qiyandata.com);
点击网站右上角,选择“机构用户(IP)登录”;
在导航栏选择需要的专题数据库→数据表→筛选字段等信息→预览数据或下载。
图片来源:企研·社科大数据平台 r.qiyandata.com
(二)个人用户采购下载
如果您所在的高校/机构没有开通大数据平台试用,可以直接在企研·数据超市(https://m.qiyandata.com)上采购您所需的数据!
采购路径:
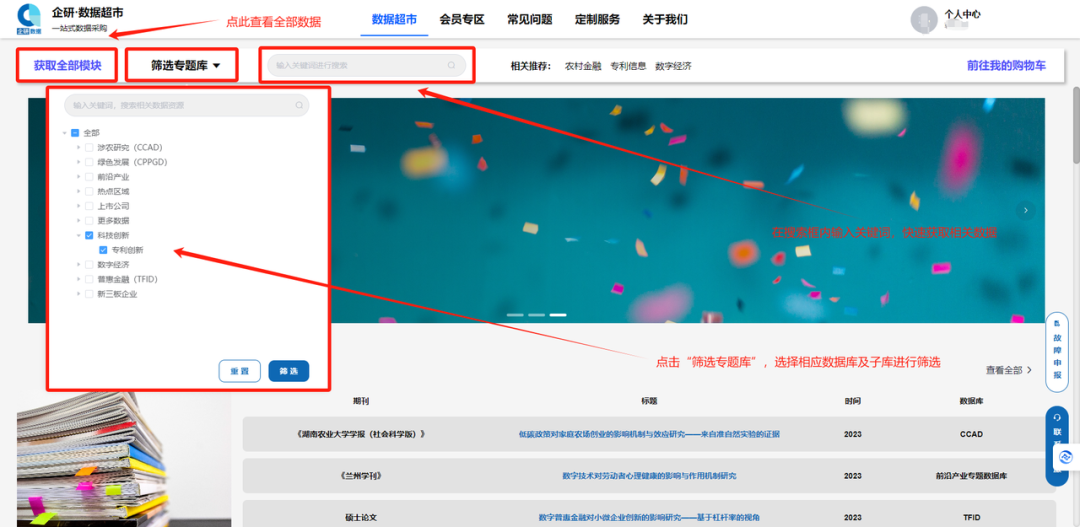
进入企研·数据超市网站(https://m.qiyandata.com);
点击“个人用户登录”;
登录成功后,页面将自动跳转至“数据超市”页面;
点击“获取全部模块”可查看全部可采购数据;点击“筛选专题库”,可对数据进行筛选;在搜索框内输入关键词,可快速获取相关数据。
图片来源:企研·数据超市 m.qiyandata.com
六、引用规范
本数据由企研数据提供。使用企研·社科大数据平台研究发表的社科论文或研究报告,需在中文成果中标明“ 本论文(报告)使用数据全部(部分)来自企研·社科大数据平台(CBDPS)”,英文成果中标注数据来源为“Qiyan China Big Data Platform for Social-Science(CBDPS)”。
注:如需咨询数据,请查看原文新库上线 | 你想要的新三板企业知识产权数据,在这里→,以获取客服联系方式。
这篇关于新库上线 | 你想要的新三板企业知识产权数据,在这里→的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







