本文主要是介绍Mysql按照月份分组统计数据,当月无数据则填充0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 起因
- 实现
- 结论
起因
最近有个需求需要在sql中实现获取近半年的统计数据,本来以为挺简单的,不过这个项目数据基本没有,在此情况下还要实现获取近半年的数据就没办法简单group by了
实现
#如果每个月都有数据的话是比较简单的
SELECT DATE_FORMAT(date, '%Y-%m') AS month, COUNT(*) AS number_of_invoices
FROM in_storeage_form
WHERE date BETWEEN DATE_SUB(CURDATE(), INTERVAL 6 MONTH) AND CURDATE()
GROUP BY month
不过这种方式可能会存在漏掉月份的情况

#如果要在补齐月份使用这种
SELECT DATE_FORMAT(date, '%Y-%m') AS month, COUNT(*) AS number_of_invoices
FROM in_storeage_form
WHERE date BETWEEN DATE_SUB(CURDATE(), INTERVAL 6 MONTH) AND CURDATE()
GROUP BY monthUNION ALLSELECT m.date as month,0 AS number_of_invoices
FROM ( SELECT DATE_FORMAT(CURDATE(), '%Y-%m') AS dateUNION ALLSELECT DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 1 MONTH), '%Y-%m') dateUNION ALLSELECT DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 2 MONTH), '%Y-%m') dateUNION ALLSELECT DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 3 MONTH), '%Y-%m') dateUNION ALLSELECT DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 4 MONTH), '%Y-%m') dateUNION ALLSELECT DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 5 MONTH), '%Y-%m') date ) m
where not exists(SELECT DATE_FORMAT(f.date, '%Y-%m') AS dateFROM in_storeage_form fWHERE date BETWEEN DATE_SUB(CURDATE(), INTERVAL 6 MONTH) AND CURDATE()and DATE_FORMAT(f.date, '%Y-%m') = m.dateGROUP BY date)
order by month desc
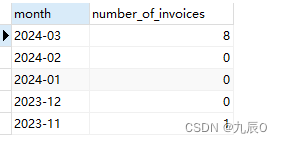
结论
先通过普通的计算有数据的月份,在获取近6个月到底是哪几个月,通过这几个月去跟有数据的几个月做一个筛选,获取到没数据的那几个月,再去将没数据的那几个月设为0就OK了
这篇关于Mysql按照月份分组统计数据,当月无数据则填充0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





