本文主要是介绍智联招聘数据分析与可视化python,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目 录
1 需求分析... 2
1.1 需求背景... 2
1.2 数据分析需求... 2
1.3 可视化需求分析... 2
1.4 技术需求分析... 3
2 概要设计... 3
2.1 数据洞察... 3
2.2 数据预处理... 3
2.3 数据分析... 4
3 开发工具和编程语言... 5
3.1 开发工具... 5
3.2 编程语言... 5
4 详细设计及运行结果... 5
4.1 添加数据且分析... 5
4.2 平均工资可视化... 6
4.3 公司类型可视化分析... 8
4.4公司招聘领域可视化分析... 9
4.5 公司人数规模可视化分析... 9
4.6工作经验与所对应的职位数量分析... 11
4.7招聘数量与招聘地区的分析... 12
4.8招聘岗位数最多的城市Top10. 14
4.9招聘岗位对学历的要求... 15
5 调试分析... 17
6 总结... 18
7 参考文献... 18
1 需求分析
1.1 需求背景
现在,随着互联网网络的飞速发展,人们获取信息的最重要来源也由报纸、电视转变为了互联网。互联网的广泛应用使网络的数据量呈指数增长,让人们得到了更新、更完整的海量信息的同时,也使得人们在提取自己最想要的信息,过滤掉对自己无用的信息时变得不那么容易,对于应聘者也是如此。由于招聘网站的日益流行,也使得应聘网站成为了应聘者找工作的主要平台。在面对着大量的招聘信息时,就业者不能一目了然的获取自己想要的招聘信息,因此我们需要对海量的招聘数据进行处理,做出一种招聘信息的分析系统。我们可以借助计算机技术来进行自动获取筛选分析自己想要的职位信息。本文对于基于智联招聘网站的可视化的课题研究就显得尤为重要了。
1.2 数据分析需求
爬取的智联招聘网站招聘数据,也可以通过学历和职位来选择查看满足条件的招聘信息,可以选择学历要求、输入职位来搜索更加精准的职位。
1.3 可视化需求分析
薪资情况:通过选择学历来查看各种岗位对于不同学历的薪资可视化情况,以柱状图、饼图的形式来展示各种职位的薪资分布、所占比例,提供给用户在找工作是作为参考。
企业情况:通过选择职位可以来查看这个职位的主要招聘城市,还可以大概查看一下这个职位的公司规模情况,以及每个职位在各个主要城市所占的比例饼图。
福利情况:通过数据可视化速览公司福利,基于词云进行构造,可以清晰看出所有公司给出的最核心的福利待遇。
学历情况:可以查看各个职位对学历以及工作经验的要求,以条形图、矩形树的形式进行可视化展示。
1.4 技术需求分析
完全用Python来做同样的事。用到的库有Pandas、Matplotlib。np、pd、pl、分别是numpy、pandas、matplotlib.pyplot的常用缩写。Numpy(Numerical Python的简称)是Python科学计算的基础包。
2 概要设计
2.1 数据洞察
数据来源:已经爬虫好的智联招聘数据excel表格
数据规模:约有10万条数据,里边包括了公司的规模、位置、名称、工作地、学历、工作经验等一系列公司相关信息。
数据形式:以excel表格的形式展示出来,里边有各个公司的所对应的索引名称和需求信息需求岗位等。
整体项目设计是利用网络爬虫抓取招聘网站相关岗位的招聘信息,包括职位、公司名称、公司地点、薪资、工作经验要求、学历要求和公司福利等信息。将获取的数据进一步处理,包括对一些空值和异常数据进行清洗,以及对单位和格式不统一的数据规范化。再通过Python第三方库将处理好的数据可视化,最终利用前端技术将所有可视化图片合并成一个系统。所要呈现的功能目标包括以下几点:
Top1:清晰展示招聘相关岗位的企业集中在哪些地区或城市。
Top2:探寻主要城市在相关岗位上的薪资与其他地区存在多大的差异。
Top3:了解薪资与哪些因素潜在明显的关系。
Top4:调查相关岗位的招聘企业对应聘者有哪些方面的要求。
Top5:清楚的了解到相关岗位的招聘企业一些相关企业信息。
2.2 数据预处理
对数据进行简单的清洗和删除重复的内容,经过初步筛选,未发现重复数据,共有数据105152条数据。
2.3 数据分析
首先打开visual。在visual的界面里导入常用的包numpy、pandas、matplotlib.pyplot等。用pandas的read_excel()方法读取xlsxn文件,并转化为用data命名的DataFrame格式文件。
根据前面数据可视化的结果,总结出不同城市的工作以及对其经验的工作年限和学历进行分析。
相关性探究,利用 matplotlib库对不同类型的数据进行相关性探究,并绘制出招聘数据的直方图饼图将相关性可视化,便于后续针对性的分析数据。根据直方图与饼图结果,探究学历与工作经验的关系。
整体项目设计是利用网络爬虫抓取招聘网站相关岗位的招聘信息,包括职位、公司名称、公司地点、薪资、工作经验要求、学历要求和公司福利等信息。将获取的数据进一步处理,包括对一些空值和异常数据进行清洗,以及对单位和格式不统一的数据规范化。再通过Python第三方库将处理好的数据可视化,最终利用前端技术将所有可视化图片合并成一个系统。所要呈现的功能目标包括以下几点:
Top1:清晰展示招聘相关岗位的企业集中在哪些地区或城市。
Top2:探寻主要城市在相关岗位上的薪资与其他地区存在多大的差异。
Top3:了解薪资与哪些因素潜在明显的关系。
Top4:调查相关岗位的招聘企业对应聘者有哪些方面的要求。
Top5:清楚的了解到相关岗位的招聘企业一些相关企业信息。
打开Excel表,除了具体的公司和职位名称以外,我们还比较关心几个关键词:平均月薪、工作经验、工作城市、最低学历和岗位职责描述,这些标签可以两两组合产生各种数据。譬如我想知道各个城市的招聘数量分布情况,会不会大部分的工作机会都集中在北上广深?是不是北上广深的平均工资也高于其他城市?我想知道excel表格中这个10万多条招聘数据中对学历的要求和对工作经验的要求,以及它们分别占比多少?我还想知道平均月薪和工作经验的关系?最低学历和平均月薪的关系?---------好,让我们一个个来。
3 开发工具和编程语言
3.1 开发工具
Jupyter Notebook 是一个灵活、可交互和可扩展的工具,适用于数据分析、机器学习、可视化和教学等各种领域的工作。它提供了一个方便的平台,使用户能够以交互式和可视化的方式探索数据、开发代码,并以可共享的方式记录和展示工作成果。
visual是一个专业的Python集成开发环境(IDE),具有强大的代码编辑以及很方便和轻松的识别能力和包的导入。
3.2 编程语言
Python是最受欢迎的数据科学编程语言之一,具有丰富的数据处理、分析、可视化和机器学习库。由于其简单易学、语法简洁、跨平台等特点,Python成为了科学数据库项目的首选编程语言。
4 详细设计及运行结果
4.1 添加数据且分析
如下是读取智联招聘数据excel表格的代码

程序运行结果如图 4-1 所示。
图 1-1 导入数据运行结果
对导入的数据进行筛选查看是否有重复的数据,如有便删除重复数据,具体执行代码如下:

4.2 平均工资可视化
下面,将进行【providesalary】列的分列操作,新增三列【bottom】、【top】、【average】分别存放最低月薪、最高月薪和平均月薪。 其中try语句执行的是绝大多数情况:职位月薪格式如:8000-10000元/月,为此需要对【职位月薪】列用正则表达式逐个处理,并存放至三个新列中。 处理后bottom = 8000,top = 10000,average = 9000. 其中不同语句用于处理不同的情况,譬如【职位月薪】=‘面议’、‘found no element’等。对于字符形式的‘面议’、‘found no element’ 处理后保持原字符不变,即bottom = top = average = 职位月薪。
q1,q2,q3,q4用来统计各个语句执行次数.其中q1统计职位月薪形如‘6000-8000元/月’的次数;q2统计形如月收入‘10000元/月以下’;q3代表其他情况如‘found no element’,‘面议’的次数;q4统计失败的特殊情况。以下是核心代码展示:

程序运行结果如图 4-2 所示。
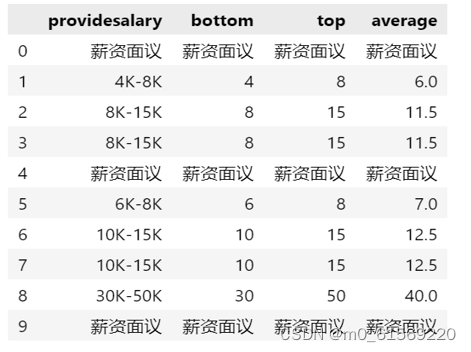
图 4-2 计算平均工资
4.3 公司类型可视化分析
将公司的类型以饼状图的形式更直观的展现出来,从图中可以看出总体公司的类型是以上市公司为主还是国企或者合资等类型,以饼状图展示结果来看,其中上市公司占比百分之七十,占很大一部分,故此可以根据此数据了解此专业的招聘数据的大部分公司类型,从而可以更好的结合自己的资源和能力进行更方便的投递简历。如下是代码展示:

运行结果如图4-3所示
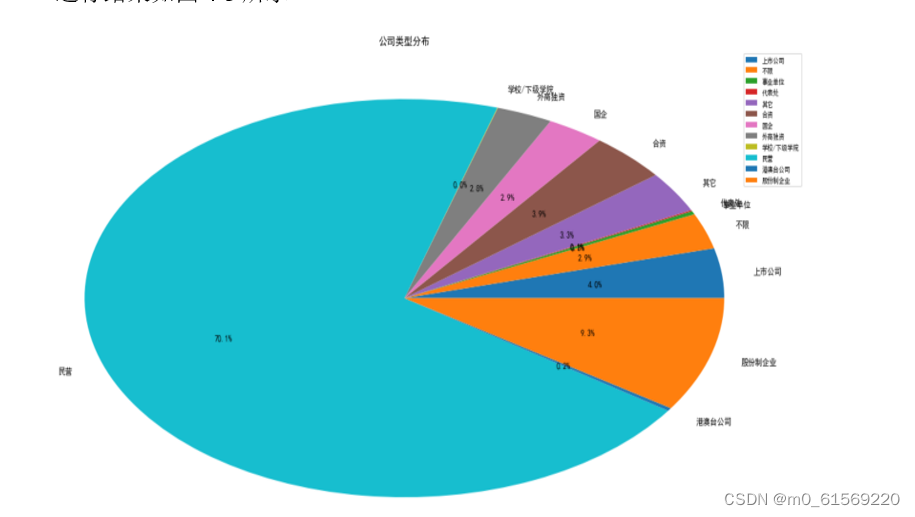
图4-3公司类型分布图
4.4公司招聘领域可视化分析
各领域公司的招聘数据,由运行结果和筛选可知,其中绝大多部分的招聘岗位和领域以销售为主,销售岗和技术岗占很大一部分,这也恰恰说明了经济的复苏离不开销售离不开交易,科技的强大背后依旧是技术岗位的支撑,技术岗位也具有很大优势。以下是代码展示:

图4-4是公司领域分析
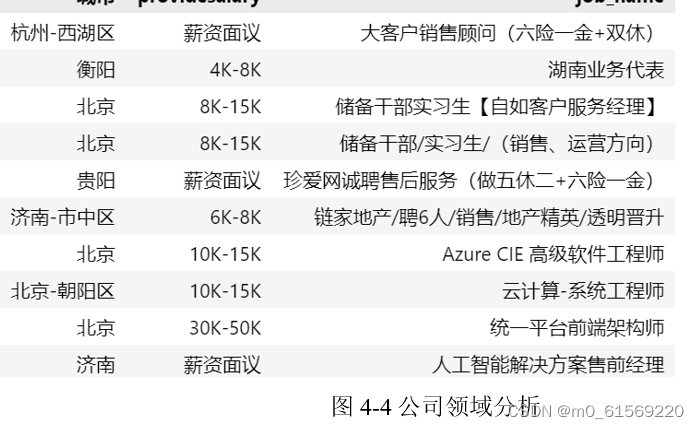
图4-4公司领域分析
4.5 公司人数规模可视化分析
公司人数规模的可视化分析是企业管理中不可或缺的一部分。通过数据可视化,我们可以更好地理解公司员工分布、规模变化以及发展趋势,为管理层提供决策支持,同时也为公司战略规划提供数据依据。在未来的工作中,我们将继续优化数据可视化方案,提高数据的洞察力和可操作性,帮助求职者可以更好地了解现在公司的规模行情。具体代码如下:

运行结果如图4-5所示

图4-5公司规模可视化分析
由图可知,其中大部分公司的人数规模是以20---500人之间,说明现在的公司大部分以20---500人为主,但也有万人公司存在,所以在求职中可以更好的了解公司的规模。
4.6工作经验与所对应的职位数量分析
工作经验与所对应的职位数量之间的关系是密切相关的。通常来说,随着工作经验的增加,求职者所能够胜任的职位数量也会逐渐增加。对于刚刚步入社会的年轻人来说,他们通常需要从基层岗位开始,通过积累一定的工作经验,逐渐提升自己的能力和职位以及有更深层次的认识,具体代码展示如下:

运行结果如图4-6所示
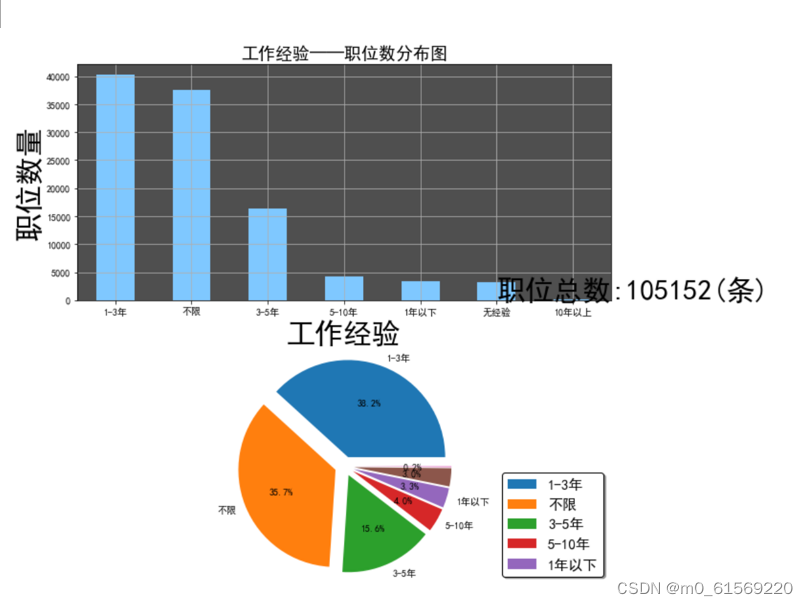
运行结果如图4-6所示
同时需要注意的是,并不是所有职位都需要相同的工作经验。有些职位可能更加注重求职者的技能和知识水平,而有些职位可能更加注重求职者的人际交往能力和领导能力。因此,在申请不同的职位时,需要根据自己的实际情况和职位要求来选择适合自己的职位。
总之,工作经验与所对应的职位数量之间存在密切的关系。随着工作经验的增加,求职者所能够胜任的职位数量也会逐渐增加。同时需要注意的是,不同的职位需要不同的工作经验和技能,需要根据自己的实际情况和职位要求来选择适合自己的职位。
4.7招聘数量与招聘地区的分析
招聘数量与招聘地区之间的关系可以从以下几个方面进行文字分析:
招聘数量与招聘地区之间存在明显的相关性。通常情况下,一个地区的招聘数量会受到当地经济发展水平、行业分布、就业市场状况等多种因素的影响。例如,在经济发展较快、行业集聚的城市,如北京、上海、深圳等一线城市,招聘数量相对较多;而在一些欠发达地区或农村地区,招聘数量则相对较少。
不同地区对于不同职位的招聘数量也存在差异。在一些发达城市中,由于产业聚集和经济发达,往往有更多的职位可供选择。例如,在IT行业较为集中的北京、上海等城市,相关职位的招聘数量就相对较多。而在一些新兴城市或发展中地区,由于人才相对较少,雇主可能更注重求职者的潜力和能力,因此一些新兴产业或高技能职位的招聘数量相对较多。
招聘数量的变化也会受到不同地区政策的影响。对于求职者来说,选择不同地区的招聘职位也需要根据当地的就业市场情况、经济发展水平和文化特点来评估自己的竞争力,并选择适合自己的职位。在一些发达城市中,由于竞争激烈,雇主往往更注重求职者的工作经验和个人能力;而在一些新兴城市或发展中地区,由于人才相对较少,雇主可能更注重求职者的潜力和能力。具体代码如下:

运行结果如图4-7所示
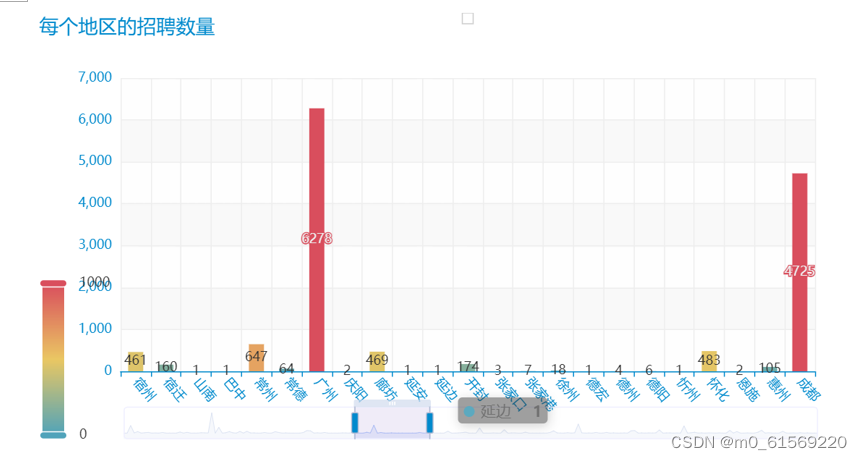
图4-7地区与招聘数量
为了更清晰直观的观察数据,此图可进行拖拽:如图4-7.1
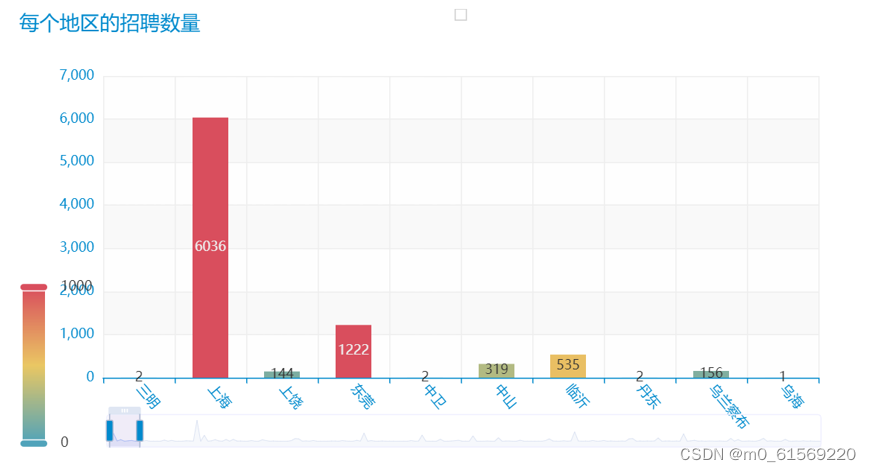
图4-7.1
由图中数据可知,其中绝大部分岗位分布在北上广城市,这恰恰印证了我们数据的可靠性和代码的完整性。
总之,招聘数量与招聘地区之间存在密切的关系。一个地区的招聘数量会受到当地经济发展水平、行业分布、就业市场状况等多种因素的影响。对于求职者来说,选择不同地区的招聘职位需要根据当地的实际情况来评估自己的竞争力,并选择适合自己的职位。
4.8招聘岗位数最多的城市Top10
随着中国经济的快速发展,越来越多的人涌入城市寻找就业机会。各个城市为了吸引人才,都在努力提升自身的人才环境和就业机会。本次报告将针对招聘岗位数最多的10个城市进行分析,具体主要代码如下:

运行结果如图4-8所示
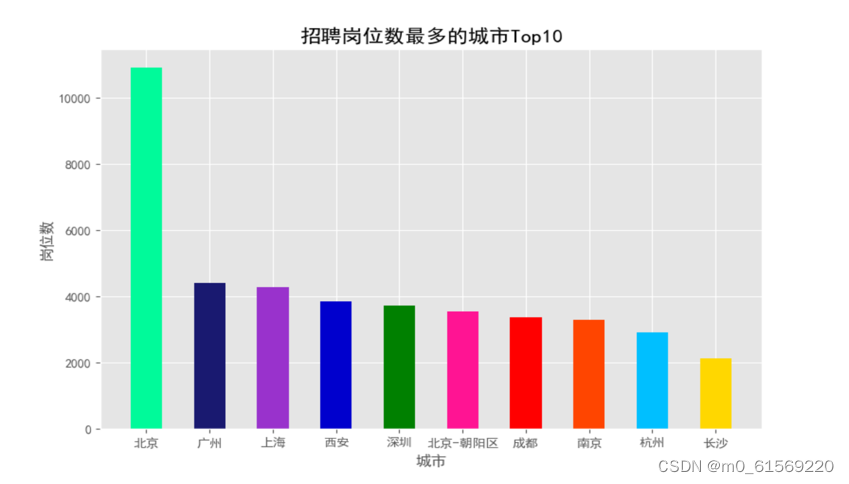
图4-8招聘岗位数量最多的城市
北、上、深、杭、广占据了不小的比重!这5个城市占据了全国68%的职位数量!令人意外的是北京的工作机会领先第二名广州不少,果然是帝都!西安表现亮眼,超越了深圳,这个和古都西安历史名城的贡献应该有很大关系!北上广深航+成都、南京、杭州,这10个城市占据了中国80%的工作机会!
4.9招聘岗位对学历的要求
随着教育的普及和人才市场的竞争加剧,招聘岗位对学历的要求也越来越高。本报告将对招聘岗位对学历的要求进行文字分析。
本科及以上:大多数招聘岗位对学历的要求为本科及以上。这一要求反映了当前社会对高等教育普遍重视,以及人才市场竞争的激烈程度。一些高薪职位或高端职位,如金融分析师、高级工程师等,更是将学历要求提高到硕士或博士。
大专及以上:部分招聘岗位对学历的要求为大专及以上。这些职位通常属于一些初级职位或技能型职位,如销售代表、技工等。这些职位更注重实际能力和工作经验。
高中及以上:一些基础性职位或服务性职位,如餐饮服务员、客服等,对学历的要求为高中及以上。这些职位更注重团队合作和服务意识。
本科优先:部分招聘岗位虽然对学历没有硬性要求,但明确表示本科优先。这说明在同等条件下,拥有本科学历的求职者更容易获得这些职位。
硕士优先:一些高端职位或高薪职位,如高级管理职位、研究员等,更倾向于招聘拥有硕士学历的求职者。这反映了硕士学历在某些领域的重要性。
具体展示代码如下:

运行结果如下图4-9所示
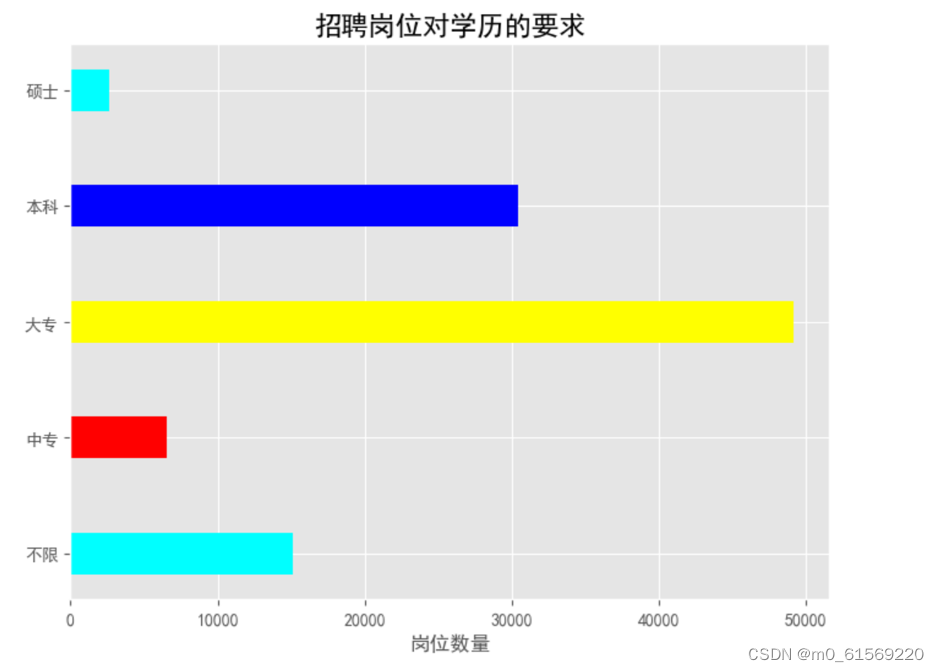
图4-9招聘岗位对学历的要求
从以上分析可以看出,招聘岗位对学历的要求因职位类型、职位等级和行业特点而异。一般来说,高端职位和高薪职位更注重高学历和专业知识,而初级职位和服务性职位更注重实际能力和工作经验。
5 调试分析
(1)ModuleNotFoundError:No module named 'pyecharts'
原因:当前python版本里面没有pyecharts模块
解决方法:是直接打开cmd,输入以下命令行:
Pip install pyecharts
(2)画图时不显示中文
原因:未添加显示中文的代码
解决方法:添加以下代码

6 总结
其实展开了还可以分析的东西有不少,譬如Pandas、Matplotlib的用法,譬如更多维度的分析和两两组合! 好了,整体的先暂时分析到这,总结一下呢就是:Python+工作经验+学历+大城市 = 高薪!但是,工作经验、学历和城市其实并没那么重要, 关键要看自己的Python用的6不6,关键在于你知道自己想做什么,知道自己能做什么,知道自己做出了什么!哈哈,当你知道越来越接近这些问题的答案呢,那么我相信,薪水对你来说已经不那么重要了!(当然,高薪是必须有的!) 人生苦短,我用Python!
7 参考文献
[1]段红秀, 刘梅,and 陈震啸."基于大数据技术的招聘服务平台设计与实现." 互联网周刊 .19(2022):13-15.
[2]王金威."基于大数据分析的高校云招聘信息个性化推送研究." 安徽电子信息职业技术学院学报 21.04(2022):25-31.
[3]吴莉萍, 刘科,and 谢鹏."互联网招聘大数据分析对于高职院校学生就业的推进作用." 内江科技 43.07(2022):55-56+37.
[4]张振寰."基于大数据面向就业岗位招聘的数据分析." 科技资讯 20.12(2022):228-231. doi:10.16661/j.cnki.1672-3791.2203-5042-4550.
[5]殷乐."大数据在企业人力资源招聘管理中的应用研究——以JJ公司为例." 中国管理信息化 25.12(2022):167-169.
[6]宋东翔, 王怡然,and 马伽洛伦."基于ECharts的高校教师招聘大数据可视化平台构建与应用." 软件 43.05(2022):42-45.
若有疑问可以q1614795749接受建议和整改
这篇关于智联招聘数据分析与可视化python的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







