本文主要是介绍Elastic search点点滴滴,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在打造集中化日志那篇中,稍微提了下Elastic search。
Elk打造集中化日志
Elastic search是Elk的核心,写的时候重点也放在它上面,不过还是觉得深度挖掘得不是太够,所以决定再另写一篇重点介绍下Elastic search。
ES集群
正如Elastic的本义一样,ES就是为扩展而生,天生就是支持分布式。这意味着我们可以对ES进行横向扩展,且不需要付出沉重的代价。添加或者删除节点,ES都能很好的处理。
首先介绍几个概念:
cluster
代表集群。集群有多个节点,其中有一个为主节点,所有有master资格的节点都有可能被选举成为leader。主从节点是相对集群内部来而言,ES集群是去中心化的,对于集群外部,集群是没有中心节点的,从外部来看,ES集群就是个逻辑整体,与任何一个节点的通信和与整个es集群通信是等价的。leader主要是负责在集群内部维护集群的状态,对外则和所有其他节点是一样的。这就不会发生Hadoop那样namenode故障导致集群不可用的状况。
shards
代表索引分片。es将一个完整的索引分成多个分片,这样就可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改,默认是5个。可以通过index.number_of_shards 修改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用主要就是容错。默认是1个,可以通过index.number_of_replicas修改。
recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
gateway
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互。
先测试一下,我启动了三个ES实例分别在:
10.0.250.90 9200 9300
10.0.250.90 9201 9301
10.0.250.91 9200 9200
ES上有两个索引,一个是.es一个是logstash-*。打开head节点看下集群的节点状态
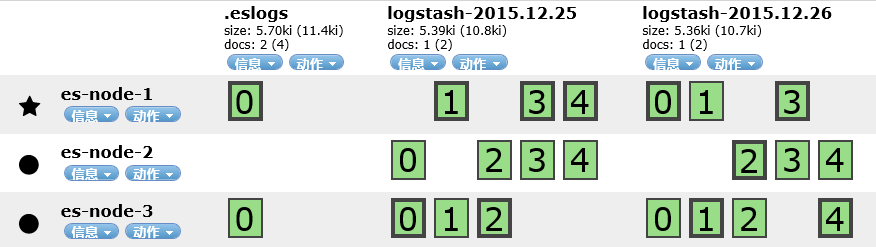
.es索引有一个分片,而logstash索引总共有10个分片,各自都是1个副本,总共就是22个分片均匀分布在不同的es节点上。节点1和2各有7个分片,而节点3有8个。
这时候如果我们继续做扩展,比如加一个节点。这时候就会进行reshard,

22个节点被均匀分布到4个节点上。如果节点被扩到22个,那就正好每个节点 1个分片。如果继续扩,那就意味着有节点不需要处理写请求,可以将多出来的专门用于处理读请求。
我们此时再将节点4的进程kill掉
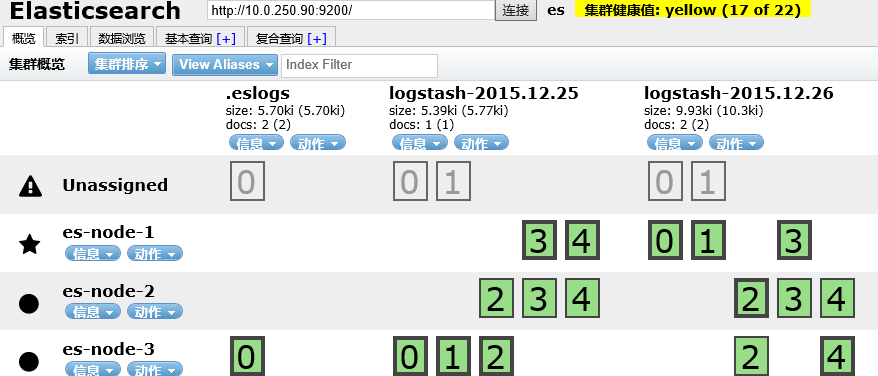
集群健康值变为了黄色,在黄色前应该有个红色的状态,当有主分片的节点故障时会显示红色,代表集群不能正常提供服务,此时进行reshard,leader会把相应副本分片提升为主分片,此时集群可以正常提供服务,就变成了黄色。
ES索引
索引是一个逻辑存储空间,分片才是实际的物理存储,每个分片都只有索引数据一部分 。节点会通过集群内部的Gossip协议交换集群状态,从而所有节点信息都是对等的。
以上图的索引分布为例,
1. 客户端访问es-node-1,要求获取.eslogs的相关文档。
2. es-node-1计算出该文档归属于分片0,于是将请求转发给es-node-3,由节点3继续处理。
3. 节点3处理完请求后将结果返回给节点1,再返回给客户端。
4. 节点1为请求节点,相应的节点3为处理节点
对于写请求,也是类似的,但是有点差别,请求节点将写请求根据路由规则转发后,处理节点对主分片做写操作,做完后该处理节点再转发请求给相应的备份分片节点,备份分片写操作完成后,处理节点会汇报成功给请求节点,由请求节点报告成功给客户端。
默认情况下,主分片需要通过仲裁(Quorum),确认大部分分片拷贝(分片拷贝可以使主要分片或者副本分片,两者均可)有效时,才会发起一个写操作。这样做的目的是为了防止将数据写入到网络中”错误的一侧(Wrong Side)”。仲裁的公式如下:
int( (primary + number_of_replicas) / 2 ) + 1number_of_replicas是指定在索引设置中的副本分片的数量,不是当前处于活动状态的副本分片数量。如果在索引中指定了有3个副本分片的话,那么quorum的值就是3
那么当只启动了两个节点时,那么就无法满足quorum,从而导致备份分片的写操作不会执行。
如果不能通过仲裁,ES会等待一段时间,默认是1分钟。
这篇关于Elastic search点点滴滴的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







