本文主要是介绍openEuler学习——部署MGR集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍如何利用GreatSQL 8.0.25构建一个三节点的MGR集群。
1.安装准备
| IP | 端口 | 角色 |
| 192.168.20.110 | 3306 | mgr1 |
| 192.168.20.111 | 3306 | mgr2 |
| 192.168.20.112 | 3306 | mgr3 |
配置hosts解析
[root@MGR1 ~]# cat >> /etc/hosts << EOF
> 192.168.20.110 MGR1
> 192.168.20.111 MGR2
> 192.168.20.112 MGR3
> EOF
安装MySQL8
[root@MGR1 ~]# yum install mysql-server -y
[root@MGR2 ~]# yum install mysql-server -y
[root@MGR3 ~]# yum install mysql-server -y
2.启动MySQL服务
首先修改 /etc/my.cnf.d/mysql-server.cnf 配置文件,增加:
#/etc/my.cnf*.d/mysql-server.cnf
[mysqld]
...
#开启GTID,必须开启
gtid_mode = ON
#强制GTID的一致性
enforce_gtid_consistency = ON
#binlog格式,MGR要求必须是ROW,不过就算不是MGR,也最好用
binlog_format = row
#server-id必须是唯一的
server-id = 1
#MGR使用乐观锁,所以官网建议隔离级别是RC,减少锁粒度
transaction_isolation = READ-COMMITTED
#因为集群会在故障恢复时互相检查binlog的数据,
#所以需要记录下集群内其他服务器发过来已经执行过的binlog,按GTID来区分是否执行过.
log-slave-updates = 1
#binlog校验规则,5.6之后的高版本是CRC32,低版本都是NONE,但是MGR要求使用NONE
binlog_checksum = NONE
#基于安全的考虑,MGR集群要求复制模式要改成slave记录记录到表中,不然就报错
master_info_repository = TABLE
#同上配套
relay_log_info_repository = TABLE
#组复制设置#记录事务的算法,官网建议设置该参数使用 XXHASH64 算法
transaction_write_set_extraction = XXHASH64
#相当于此GROUP的名字,是UUID值,不能和集群内其他GTID值的UUID混用,可用uuidgen来生成一个新的,
#主要是用来区分整个内网里边的各个不同的GROUP,而且也是这个group内的GTID值的UUID
loose-group_replication_group_name = '5dbabbe6-8050-49a0-9131-1de449167446'
#IP地址白名单,默认只添加127.0.0.1,不会允许来自外部主机的连接,按需安全设置
loose-group_replication_ip_whitelist = '127.0.0.1/8,192.168.6.0/24'
#是否随服务器启动而自动启动组复制,不建议直接启动,怕故障恢复时有扰乱数据准确性的特殊情况
loose-group_replication_start_on_boot = OFF
#本地MGR的IP地址和端口,host:port,是MGR的端口,不是数据库的端口
loose-group_replication_local_address = '192.168.6.151:33081'
#需要接受本MGR实例控制的服务器IP地址和端口,是MGR的端口,不是数据库的端口
loose-group_replication_group_seeds = '192.168.6.151:33081,192.168.6.152:33081,192.168.6.153:33081'
#开启引导模式,添加组成员,用于第一次搭建MGR或重建MGR的时候使用,只需要在集群内的其中一台开启,
loose-group_replication_bootstrap_group = OFF
#是否启动单主模式,如果启动,则本实例是主库,提供读写,其他实例仅提供读,如果为off就是多主模式了
loose-group_replication_single_primary_mode = ON
#多主模式下,强制检查每一个实例是否允许该操作,如果不是多主,可以关闭
loose-group_replication_enforce_update_everywhere_checks = on #单主模式不需要启动服务
systemctl restart mysqld3.安装插件
利用这份配置文件,重启MySQL Server,之后就应该能看到已经成功加载 group_replicaiton 插件了:
[root@MGR1 ~]# mysql -e "show plugins;" | grep "group_replication"
如果输入没有输出结果,也可以手动添加
[root@MGR1 ~]# mysql -e "install plugin group_replication soname 'group_replication.so'"
[root@MGR1 ~]# mysql -e "show plugins;" | grep "group_replication"
group_replication ACTIVE GROUP REPLICATION group_replication.so GPL
#这样就有了注意:每个模拟机都需要,也就是要配置三次
4.配置账号
接下来,创建MGR服务专用账户,并准备配置MGR服务通道:
注意:每个节点都要单独创建用户,因此这个操作没必要记录binlog并复制到其他节点
mysql> set session sql_log_bin=0;
Query OK, 0 rows affected (0.00 sec)mysql> create user repl@'%' identified with mysql_native_password by 'repl';
Query OK, 0 rows affected (0.00 sec)mysql> GRANT BACKUP_ADMIN, REPLICATION SLAVE ON *.* TO `repl`@`%`;
Query OK, 0 rows affected (0.00 sec)
#配置MGR服务通道
#通道名字 group_replication_recovery 是固定的,不能修改
mysql> set session sql_log_bin=1;
Query OK, 0 rows affected (0.00 sec)mysql> CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='repl' FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 5 warnings (0.03 sec)
5.启动MGR单主模式
在MGR1主节点输入:
SET GLOBAL group_replication_bootstrap_group = ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group = OFF;
SELECT * FROM performance_schema.replication_group_members;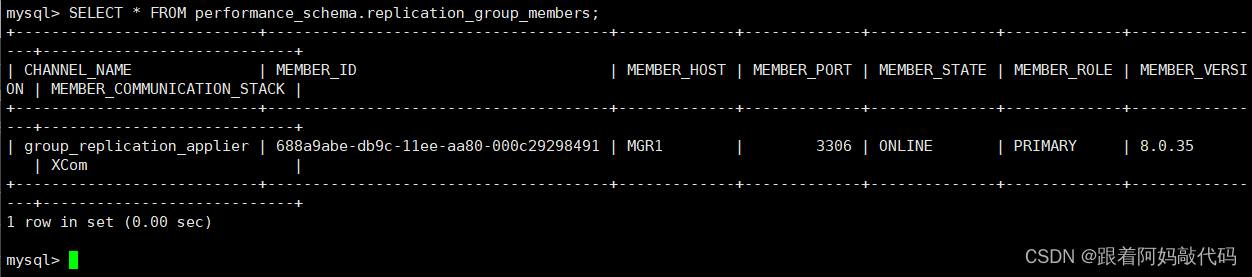
在mgr2\mgr3节点,进入mysql服务端:
START GROUP_REPLICATION;
SELECT * FROM performance_schema.replication_group_members;再次查看MGR主节点状态:
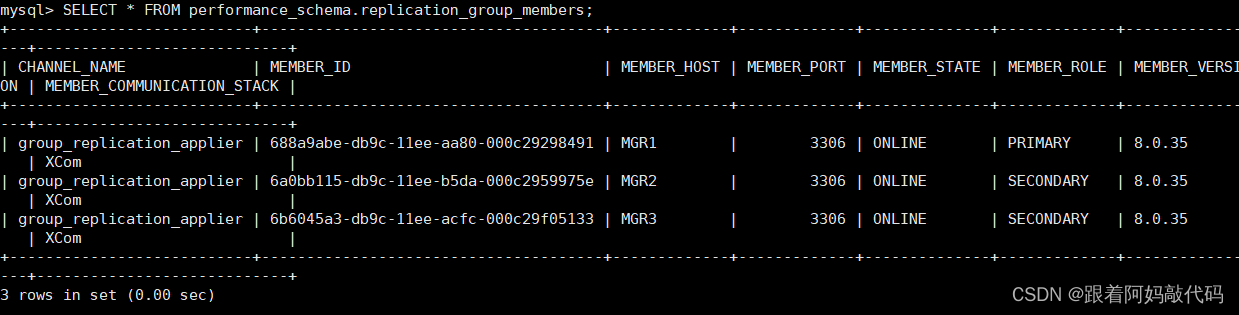
看到上面这个集群共有3个节点处于ONLINE状态,其中 192.168.20.110 是 PRIMARY 节点,其余两个都是 SECONDARY 节点,也就是说当前这个集群采用 单主 模式。如果采用多主模式,则所有节点的角色都是 PRIMARY。
6. 向MGR集群中写入数据
在MGR1中创建一个表生成一个随机数
mysql> use mgr;
Database changed
mysql> create table t1(c1 int unsigned not null primary key);
Query OK, 0 rows affected (0.01 sec)mysql> insert into t1 select rand()*10240;
Query OK, 1 row affected (0.03 sec)
Records: 1 Duplicates: 0 Warnings: 0mysql> select * from t1;
+------+
| c1 |
+------+
| 3506 |
+------+
1 row in set (0.00 sec)
再连接到其中一个 SECONDARY 节点,查看刚刚在 PRIMARY 写入的数据是否可以看到:
MGR2:
mysql> select * from mgr.t1;
+------+
| c1 |
+------+
| 3506 |
+------+
1 row in set (0.00 sec)mysql> select @@hostname;
+------------+
| @@hostname |
+------------+
| MGR2 |
+------------+
1 row in set (0.00 sec)MGR3:
mysql> select * from mgr.t1;
+------+
| c1 |
+------+
| 3506 |
+------+
1 row in set (0.00 sec)mysql> select @@hostname;
+------------+
| @@hostname |
+------------+
| MGR3 |
+------------+
1 row in set (0.00 sec)
确认可以读取到该数据。
到这里,就完成了三节点MGR集群的安装部署。
5. MGR管理维护
介绍MGR集群的日常管理维护操作:包括主节点切换,单主&多主模式切换等。
现在有个三节点的MGR集群:

1. 切换主节点
当主节点需要进行维护时,或者执行滚动升级时,就可以对其进行切换,将主节点切换到其他节点。
在命令行模式下,可以使用 group_replication_set_as_primary() 这个udf实现切换,例如:
注意:MEMBER_ID唯一,注意替换需要切换的主节点
mysql> select group_replication_set_as_primary('6a0bb115-db9c-11ee-b5da-000c2959975e');
+--------------------------------------------------------------------------+
| group_replication_set_as_primary('6a0bb115-db9c-11ee-b5da-000c2959975e') |
+--------------------------------------------------------------------------+
| Primary server switched to: 6a0bb115-db9c-11ee-b5da-000c2959975e |
+--------------------------------------------------------------------------+
1 row in set (0.01 sec)
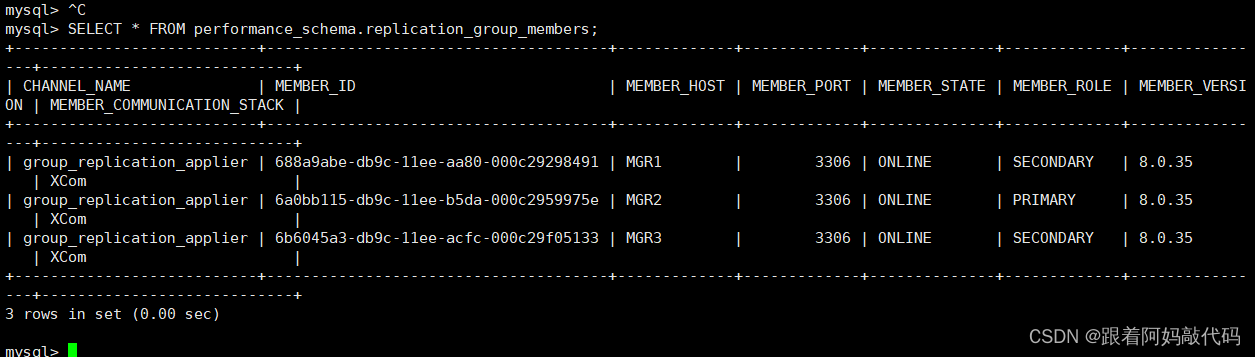
顺便提一下,在MySQL 5.7版本中,只能通过重启以实现主节点的自动切换,不能手动切换。从这个角度来说,如果想要使用MGR,最好是选择MySQL 8.0版本,而不要使用5.7版本。
2. 切换单主/多主模式
在命令行模式下,可以调用 group_replication_switch_to_single_primary_mode() 和 group_replication_switch_to_multi_primary_mode() 来切换单主/多主模式。
mysql> select group_replication_switch_to_multi_primary_mode();
+--------------------------------------------------+
| group_replication_switch_to_multi_primary_mode() |
+--------------------------------------------------+
| Mode switched to multi-primary successfully. |
+--------------------------------------------------+
1 row in set (0.01 sec)

切换成单主模式时可以指定某个节点的 server_uuid,如果不指定则会根据规则自动选择一个新的主节点
mysql> select group_replication_switch_to_single_primary_mode('6b6045a3-db9c-11ee-acfc-000c29f05133');
+-----------------------------------------------------------------------------------------+
| group_replication_switch_to_single_primary_mode('6b6045a3-db9c-11ee-acfc-000c29f05133') |
+-----------------------------------------------------------------------------------------+
| Mode switched to single-primary successfully. |
+-----------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
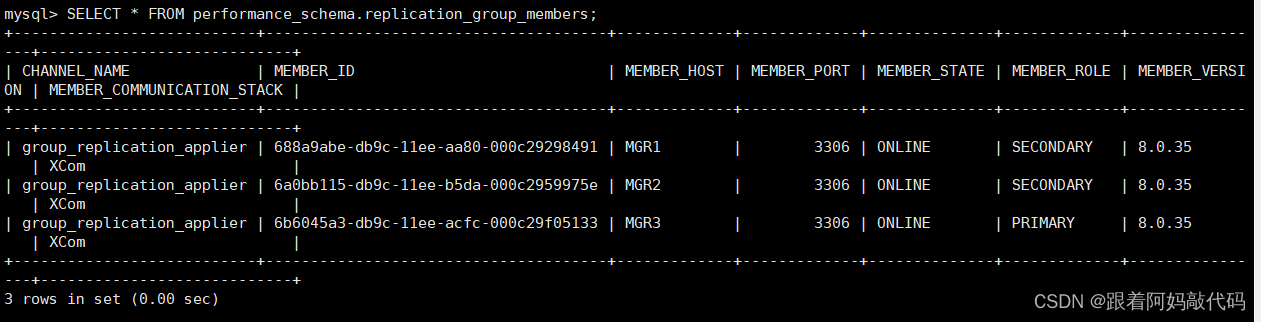
注意,在已经是单主模式时,无论
group_replication_switch_to_single_primary_mode()还是switchToSinglePrimaryMode()函数中指定另一个节点时是不会发生切换的,但也不会报错,只有提示。
3. 添加新节点
首先,要先完成MySQL Server初始化,创建好MGR专用账户、设置好MGR服务通道等前置工作。
接下来,直接执行命令 start group_replication 启动MGR服务即可,新增的节点会进入分布式恢复这个步骤,它会从已有节点中自动选择一个作为捐献者(donor),并自行决定是直接读取binlog进行恢复,还是利用Clone进行全量恢复。
如果是已经在线运行一段时间的MGR集群,有一定存量数据,这时候新节点加入可能会比较慢,建议手动利用Clone进行一次全量复制。还记得前面创建MGR专用账户时,给加上了 BACKUP_ADMIN 授权吗,这时候就排上用场了,Clone需要用到这个权限。
| IP | 端口 | 角色 |
| 192.168.20.112 | 3306 | MGR4 |
接下来我们演示如何向MGR集群中添加一个新节点。
首先,要先完成MySQL Server初始化,创建好MGR专用账户、设置好MGR服务通道等前置工作。
接下来,直接执行命令 start group_replication 启动MGR服务即可,新增的节点会进入分布式恢复这个步骤,它会从已有节点中自动选择一个作为捐献者(donor),并自行决定是直接读取binlog进行恢复,还是利用Clone进行全量恢复。

4. 删除节点
在命令行模式下,一个节点想退出MGR集群,直接执行 stop group_replication 即可,如果这个节点只是临时退出集群,后面还想加回集群,则执行 start group_replication 即可自动再加入。而如果是想彻底退出集群,则停止MGR服务后,执行 reset master; reset slave all; 重置所有复制(包含MGR)相关的信息就可以了。
5. 重启MGR集群
正常情况下,MGR集群中的Primary节点退出时,剩下的节点会自动选出新的Primary节点。当最后一个节点也退出时,相当于整个MGR集群都关闭了。这时候任何一个节点启动MGR服务后,都不会自动成为Primary节点,需要在启动MGR服务前,先设置 group_replication_bootstrap_group=ON,使其成为引导节点,再启动MGR服务,它才会成为Primary节点,后续启动的其他节点也才能正常加入集群。
这篇关于openEuler学习——部署MGR集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







