本文主要是介绍3. 在Go语言项目中使用Zap日志库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、介绍
- 二、 默认的Go Logger
- 1. 实现Go Logger
- 2. 设置Logger
- 3. 使用Logger
- 4. Logger的运行
- 5. Go Logger的优势和劣势
- 三、Uber-go Zap
- 1. 为什么选择Uber-go zap
- 2. 安装
- 3. 配置Zap Logger
- 4. 定制logger
- 4.1 将日志写入文件而不是终端
- 4.2 将JSON Encoder更改为普通的Log Encoder
- 4.3 更改时间编码并添加调用者详细信息
- 4.4 AddCallerSkip
- 4.5 将日志输出到多个位置
- 四、使用Lumberjack进行日志切割归档
- 1. 安装
- 2. zap logger中加入Lumberjack
- 五、测试所有功能
代码地址: https://gitee.com/lymgoforIT/golang-trick/tree/master/44-zap
本文将先介绍
Go语言原生的日志库的使用,然后详细介绍非常流行的Uber开源的zap日志库,同时会介绍如何搭配·Lumberjack·实现日志的切割和归档。
一、介绍
在许多Go语言项目中,一个好的日志记录器一般期望能够提供下面这些功能:
- 能够将事件记录到文件中,而不是应用程序控制台。
- 日志切割:能够根据文件大小、时间或间隔等来切割日志文件。
- 支持不同的日志级别。例如
INFO,DEBUG,ERROR等。 - 能够打印基本信息,如调用文件/函数名和行号,日志时间等。
二、 默认的Go Logger
在介绍Uber-go的zap包之前,让我们先看看Go语言提供的基本日志功能。Go语言提供的默认日志包是https://golang.org/pkg/log/。
1. 实现Go Logger
实现一个Go语言中的日志记录器非常简单——创建一个新的日志文件,然后设置它为日志的输出位置即可。
2. 设置Logger
我们可以像下面的代码一样设置日志记录器
func SetupLogger() {logFileLocation, _ := os.OpenFile("/Users/lym/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)log.SetOutput(logFileLocation)
}
3. 使用Logger
让我们来写一些虚拟的代码,使用这个日志记录器。
在当前的示例中,我们将建立一个到URL的HTTP连接,并将状态代码/错误记录到日志文件中。
func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {log.Printf("Error fetching url %s : %s", url, err.Error())} else {log.Printf("Status Code for %s : %s", url, resp.Status)resp.Body.Close()}
}
4. Logger的运行
现在让我们执行上面的代码并查看日志记录器的运行情况。
func main() {SetupLogger()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}
当我们执行上面的代码,我们能看到一个test.log文件被创建,下面的内容会被添加到这个日志文件中。(因为www.baidu.com谷歌没有带http://开头,所以访问失败,但是http://www.baidu.com访问成功)
2024/03/06 15:14:13 Error fetching url www.google.com : Get www.baidu.com: unsupported protocol scheme ""
2024/03/06 15:14:14 Status Code for http://www.baidu.com : 200 OK
5. Go Logger的优势和劣势
优势
它最大的优点是使用非常简单。我们可以设置任何io.Writer作为日志记录输出并向其发送要写入的日志。
劣势
- 仅限基本的日志级别
- 只有一个
Print选项。不支持INFO/DEBUG等多个级别。 - 对于错误日志,它有
Fatal和PanicFatal日志通过调用os.Exit(1)来结束程序Panic日志在写入日志消息之后抛出一个panic- 但是它缺少一个
ERROR日志级别,这个级别可以在不抛出panic或退出程序的情况下记录错误
- 缺乏日志格式化的能力——例如记录调用者的函数名和行号,格式化日期和时间格式。等等。
- 不提供日志切割的能力。
三、Uber-go Zap
Zap是非常快的、结构化的,分日志级别的Go日志库。
1. 为什么选择Uber-go zap
- 它同时提供了结构化日志记录和
printf风格的日志记录 - 它非常的快
- 根据
Uber-go Zap的文档,它的性能比类似的结构化日志包更好——也比标准库更快。 以下是Zap发布的基准测试信息
记录一条消息和10个字段:
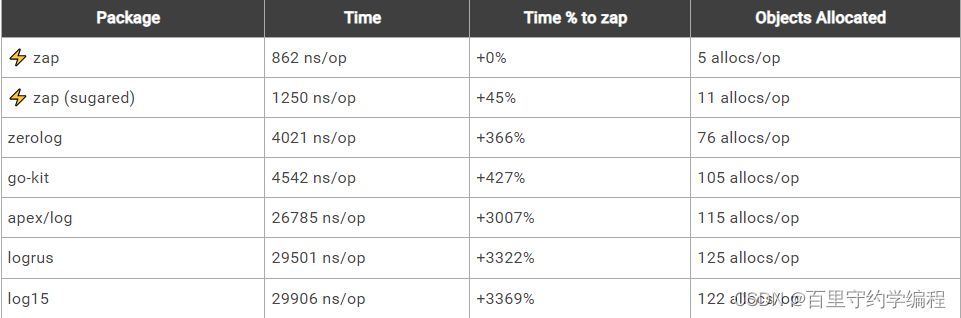
记录一个静态字符串,没有任何上下文或printf风格的模板:
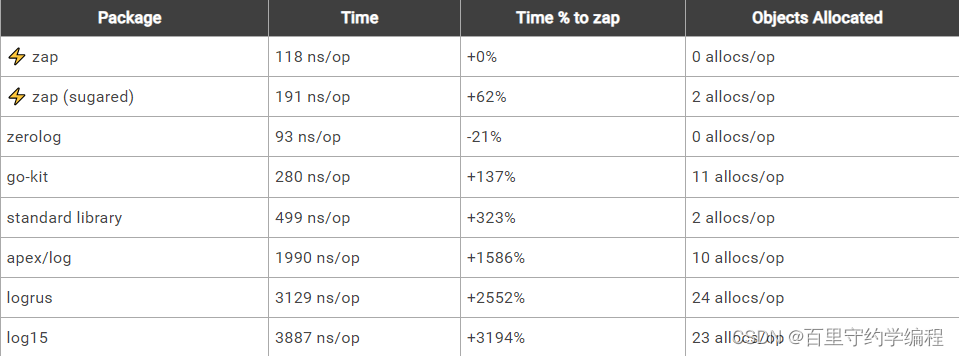
2. 安装
运行下面的命令安装zap
go get -u go.uber.org/zap
3. 配置Zap Logger
Zap提供了两种类型的日志记录器—Sugared Logger和Logger。
在性能很好但不是很关键的上下文中,使用SugaredLogger。它比其他结构化日志记录包快4-10倍,并且支持结构化和printf风格的日志记录。
在每一微秒和每一次内存分配都很重要的上下文中,使用Logger。它甚至比SugaredLogger更快,内存分配次数也更少,但它只支持强类型的结构化日志记录。
Logger
-
通过调用
zap.NewProduction()/zap.NewDevelopment()或者zap.Example()创建一个Logger。 -
上面的每一个函数都将创建一个
logger。唯一的区别在于它将记录的信息不同。例如production logger默认记录调用函数信息、日期和时间等。 -
通过
Logger调用Info/Error等。 -
默认情况下日志都会打印到应用程序的
console界面。
package mainimport ("net/http""go.uber.org/zap"
)// 定义全局日志对象,方便后续直接使用
var logger *zap.Loggerfunc main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}// InitLogger 初始化logger对象
func InitLogger() {logger, _ = zap.NewProduction()
}func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {logger.Error("Error fetching url..",zap.String("url", url),zap.Error(err)) // key为error} else {logger.Info("Success..",zap.String("statusCode", resp.Status),zap.String("url", url))resp.Body.Close()}
}
在上面的代码中,我们首先创建了一个Logger,然后使用Info/ Error等Logger方法记录消息。
日志记录器方法的语法是这样的:
func (log *Logger) MethodXXX(msg string, fields ...Field)
其中MethodXXX是一个可变参数函数,可以是Info / Error/ Debug / Panic等。每个方法都接受一个消息字符串和任意数量的zapcore.Field参数。
每个zapcore.Field其实就是一组键值对参数。
我们执行上面的代码会得到如下输出结果:
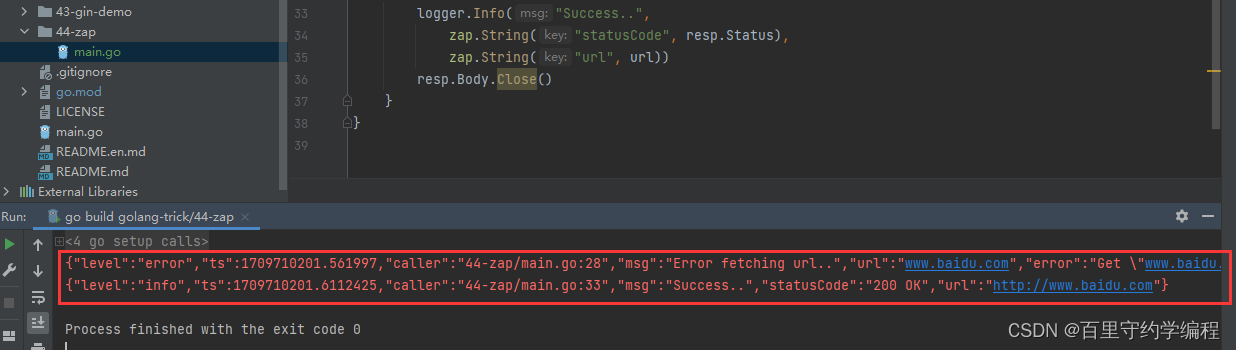
{"level":"error","ts":1709710201.561997,"caller":"44-zap/main.go:28","msg":"Error fetching url..","url":"www.baidu.com","error":"Get \"www.baidu.com\": unsupported protocol scheme \"\"","stacktrace":"main.simpleHttpGet\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:28\nmain.main\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:16\nruntime.main\n\tC:/Program Files/Go/src/runtime/proc.go:267"}
{"level":"info","ts":1709710201.6112425,"caller":"44-zap/main.go:33","msg":"Success..","statusCode":"200 OK","url":"http://www.baidu.com"}
Sugared Logger
现在让我们使用Sugared Logger来实现相同的功能。
大部分的实现基本都相同。惟一的区别是,我们通过调用主logger的. Sugar()方法来获取一个SugaredLogger。然后使用SugaredLogger以printf格式记录语句
下面是修改过后使用SugaredLogger代替Logger的代码:
var sugarLogger *zap.SugaredLoggerfunc main() {InitLogger()defer sugarLogger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}func InitLogger() {logger, _ := zap.NewProduction()sugarLogger = logger.Sugar()
}func simpleHttpGet(url string) {sugarLogger.Debugf("Trying to hit GET request for %s", url)resp, err := http.Get(url)if err != nil {sugarLogger.Errorf("Error fetching URL %s : Error = %s", url, err)} else {sugarLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)resp.Body.Close()}
}
当你执行上面的代码会得到如下输出:
{"level":"error","ts":1709710774.730964,"caller":"44-zap/main.go:58","msg":"Error fetching URL www.baidu.com : Error = Get \"www.baidu.com\": unsupported protocol scheme \"\"","stacktrace":"main.simpleHttpGet\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:58\nmain.main\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:45\nruntime.main\n\tC:/Program Files/Go/src/runtime/proc.go:267"}
{"level":"info","ts":1709710774.7849257,"caller":"44-zap/main.go:60","msg":"Success! statusCode = 200 OK for URL http://www.baidu.com"}
你应该注意到的了,到目前为止这两个logger都打印输出JSON结构格式。
在本博客的后面部分,我们将更详细地讨论SugaredLogger,并了解如何进一步配置它。
4. 定制logger
4.1 将日志写入文件而不是终端
我们要做的第一个更改是把日志写入文件,而不是打印到应用程序控制台。
我们将使用zap.New(…)方法来手动传递所有配置,而不是使用像zap.NewProduction()这样的预置方法来创建logger。
func New(core zapcore.Core, options ...Option) *Logger
zapcore.Core需要三个配置——Encoder,WriteSyncer,LogLevel。
1.Encoder:编码器(如何写入日志)。我们将使用开箱即用的NewJSONEncoder(),并使用预先设置的ProductionEncoderConfig()。
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
2.WriterSyncer :指定日志将写到哪里去。我们使用zapcore.AddSync()函数并且将打开的文件句柄传进去。
file, _ := os.Create("./test.log")
writeSyncer := zapcore.AddSync(file)
3.Log Level:哪种级别的日志将被写入。
我们将修改上述部分中的Logger代码,并重写InitLogger()方法。其余方法main() /SimpleHttpGet()保持不变。
package mainimport ("net/http""os""go.uber.org/zap""go.uber.org/zap/zapcore"
)// 定义全局日志对象,方便后续直接使用
var logger *zap.Logger
var sugarLogger *zap.SugaredLoggerfunc main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {logger.Error("Error fetching url..",zap.String("url", url),zap.Error(err)) // key为error} else {logger.Info("Success..",zap.String("statusCode", resp.Status),zap.String("url", url))resp.Body.Close()}
}// InitLogger 初始化logger对象
func InitLogger() {writeSyncer := getLogWriter()encoder := getEncoder()core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)logger = zap.New(core)sugarLogger = logger.Sugar()
}func getLogWriter() zapcore.WriteSyncer {file, _ := os.OpenFile("44-zap/test.log",os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)return zapcore.AddSync(file)
}func getEncoder() zapcore.Encoder {return zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
}
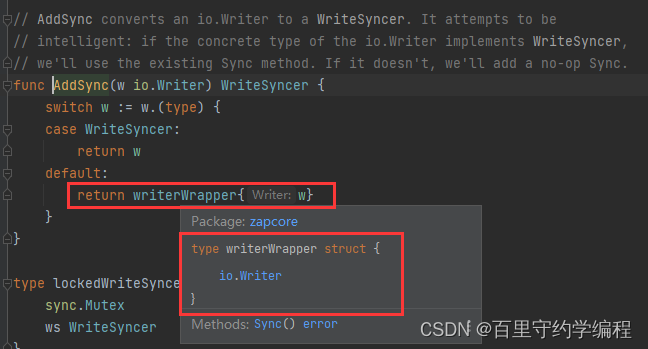
注:上面代码getLogWriter函数中的zapcore.AddSync方法源码如下,实际就是想把一个io.Writer对象包装为zapcore.NewCore中需要的zapcore.WriteSyncer类型
当使用这些修改过的logger配置调用上述部分的main()函数时,以下输出将打印在文件test.log中。
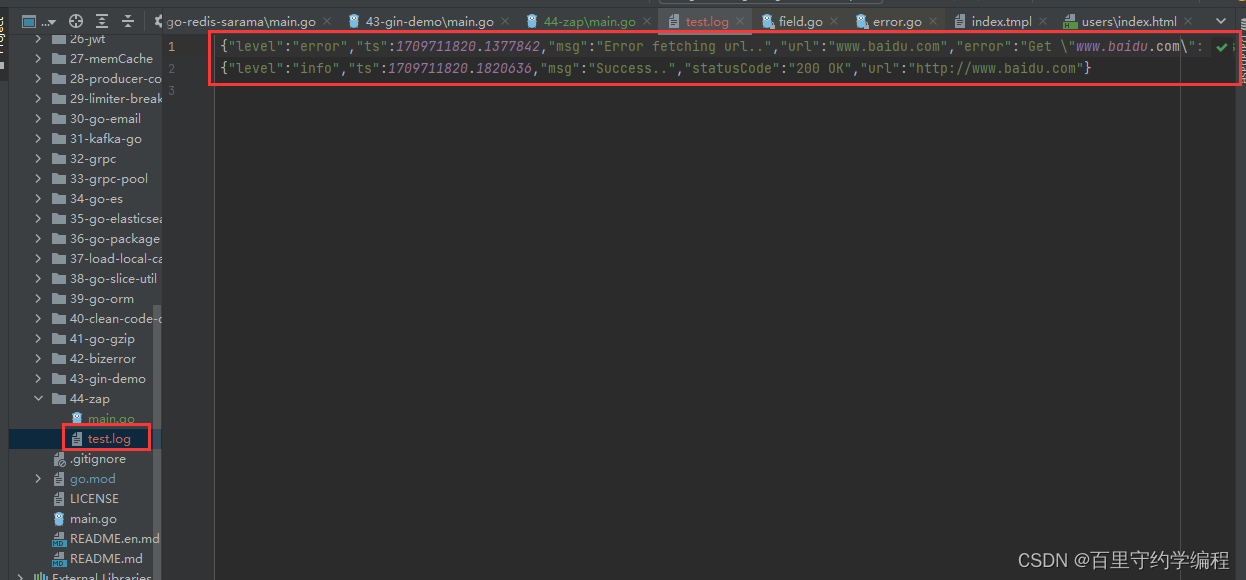
{"level":"error","ts":1709711820.1377842,"msg":"Error fetching url..","url":"www.baidu.com","error":"Get \"www.baidu.com\": unsupported protocol scheme \"\""}
{"level":"info","ts":1709711820.1820636,"msg":"Success..","statusCode":"200 OK","url":"http://www.baidu.com"}
4.2 将JSON Encoder更改为普通的Log Encoder
现在,我们希望将编码器从JSON Encoder更改为普通Encoder。为此,我们需要将NewJSONEncoder()更改为NewConsoleEncoder()。表示打印的格式和控制台打印的一样,而非json格式了,但是内容还是打印到test.log文件中的,并不是说打印到控制台哦。
return zapcore.NewConsoleEncoder(zap.NewProductionEncoderConfig())
当使用这些修改过的logger配置调用上述部分的main()函数时,以下输出将打印在文件test.log中。
因为我们设置zapcore.WriteSyncer时,文件句柄指定的是追加方式,所以是在test.log文件后面追加了两行

4.3 更改时间编码并添加调用者详细信息
鉴于我们对配置所做的更改,有下面两个问题:
- 时间是以非人类可读的方式展示,例如
1.7097121171450913e+09 - 调用方函数的详细信息没有显示在日志中
我们要做的第一件事是覆盖默认的ProductionConfig(),并进行以下更改:
-
修改时间编码器
-
在日志文件中使用大写字母记录日志级别
func getEncoder() zapcore.Encoder {encoderConfig := zap.NewProductionEncoderConfig()encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoderencoderConfig.EncodeLevel = zapcore.CapitalLevelEncoderreturn zapcore.NewConsoleEncoder(encoderConfig)
}
接下来,我们将修改zap logger代码,添加将调用函数信息记录到日志中的功能。为此,我们将在zap.New(..)函数中添加一个Option。logger = zap.New(core, zap.AddCaller())
// InitLogger 初始化logger对象
func InitLogger() {writeSyncer := getLogWriter()encoder := getEncoder()core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)logger = zap.New(core, zap.AddCaller())sugarLogger = logger.Sugar()
}
当使用这些修改过的logger配置调用上述部分的main()函数时,以下输出将打印在文件test.log中。

4.4 AddCallerSkip
当我们不是直接使用初始化好的logger实例记录日志,而是将其包装成一个函数时,此时日志的函数调用链会增加,想要获得准确的调用信息就需要通过AddCallerSkip函数来跳过。可参考本人另两篇博客中记录堆栈信息的方式:
95. Go中runtime.Caller的使用
96.Go设计优雅的错误处理(带堆栈信息)
logger = zap.New(core, zap.AddCaller(), zap.AddCallerSkip(1))
4.5 将日志输出到多个位置
我们可以将日志同时输出到文件和终端。
func getLogWriter() zapcore.WriteSyncer {file, _ := os.OpenFile("44-zap/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)// 利用io.MultiWriter支持文件和终端两个输出目标ws := io.MultiWriter(file, os.Stdout)return zapcore.AddSync(ws)
}
将err日志单独输出到文件
有时候我们除了将全量日志输出到xx.log文件中之外,还希望将ERROR级别的日志单独输出到一个名为xx.err.log的日志文件中。我们可以通过以下方式实现。
func InitLogger() {encoder := getEncoder()// test.log记录全量日志logF, _ := os.OpenFile("44-zap/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)c1 := zapcore.NewCore(encoder, zapcore.AddSync(logF), zapcore.DebugLevel)// test.err.log记录ERROR级别的日志errF, _ := os.OpenFile("44-zap/test.err.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)c2 := zapcore.NewCore(encoder, zapcore.AddSync(errF), zap.ErrorLevel)// 使用NewTee将c1和c2合并到corecore := zapcore.NewTee(c1, c2)logger = zap.New(core, zap.AddCaller())
}
四、使用Lumberjack进行日志切割归档
这个日志程序中唯一缺少的就是日志切割归档功能。
Zap本身不支持切割归档日志文件,但我们可以使用第三方库Lumberjack来实现。
目前只支持按文件大小切割,原因是按时间切割效率低且不能保证日志数据不被破坏。详情戳https://github.com/natefinch/lumberjack/issues/54。
想按日期切割可以使用github.com/lestrrat-go/file-rotatelogs这个库,虽然目前不维护了,但也够用了。
// 使用file-rotatelogs按天切割日志import rotatelogs "github.com/lestrrat-go/file-rotatelogs"l, _ := rotatelogs.New(filename+".%Y%m%d%H%M",rotatelogs.WithMaxAge(30*24*time.Hour), // 最长保存30天rotatelogs.WithRotationTime(time.Hour*24), // 24小时切割一次
)
zapcore.AddSync(l)
1. 安装
执行下面的命令安装 Lumberjack v2 版本。
go get gopkg.in/natefinch/lumberjack.v2
2. zap logger中加入Lumberjack
要在zap中加入Lumberjack支持,我们需要修改WriteSyncer代码。我们将按照下面的代码修改getLogWriter()函数:
注意:这种方式每次重新运行都是新建test.log初始文件,因为没有地方指定是内容追加到文件后面
func getLogWriter() zapcore.WriteSyncer {lumberJackLogger := &lumberjack.Logger{Filename: "44-zap/test.log",MaxSize: 1,MaxBackups: 5,MaxAge: 30,Compress: false,}return zapcore.AddSync(lumberJackLogger)
}
Lumberjack Logger采用以下属性作为输入:
- Filename: 日志文件的位置
- MaxSize:在进行切割之前,日志文件的最大大小(以MB为单位)
- MaxBackups:保留旧文件的最大个数
- MaxAges:保留旧文件的最大天数
- Compress:是否压缩/归档旧文件
五、测试所有功能
最终,使用Zap/Lumberjack logger的完整示例代码如下:
package mainimport ("net/http""go.uber.org/zap""go.uber.org/zap/zapcore""gopkg.in/natefinch/lumberjack.v2"
)// 定义全局日志对象,方便后续直接使用
var logger *zap.Logger
var sugarLogger *zap.SugaredLoggerfunc main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {logger.Error("Error fetching url..",zap.String("url", url),zap.Error(err)) // key为error} else {logger.Info("Success..",zap.String("statusCode", resp.Status),zap.String("url", url))resp.Body.Close()}
}// InitLogger 初始化logger对象
func InitLogger() {writeSyncer := getLogWriter()encoder := getEncoder()core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)logger = zap.New(core, zap.AddCaller())sugarLogger = logger.Sugar()
}func getEncoder() zapcore.Encoder {encoderConfig := zap.NewProductionEncoderConfig()encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoderencoderConfig.EncodeLevel = zapcore.CapitalLevelEncoderreturn zapcore.NewConsoleEncoder(encoderConfig)
}func getLogWriter() zapcore.WriteSyncer {lumberJackLogger := &lumberjack.Logger{Filename: "44-zap/test.log",MaxSize: 1,MaxBackups: 5,MaxAge: 30,Compress: false,}return zapcore.AddSync(lumberJackLogger)
}执行上述代码,下面的内容会输出到文件test.log中。
4-03-06T16:35:49.023+0800 ERROR 44-zap/main.go:26 Error fetching url.. {"url": "www.baidu.com", "error": "Get \"www.baidu.com\": unsupported protocol scheme \"\""}
2024-03-06T16:35:49.135+0800 INFO 44-zap/main.go:31 Success.. {"statusCode": "200 OK", "url": "http://www.baidu.com"}
同时,可以在main函数中循环记录日志,测试日志文件是否会自动切割和归档(日志文件每1MB会切割并且在当前目录下最多保存5个文件)。
func main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()for i := 0; i < 100000; i++ {simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")}
}
切割后,新建的日志文件在基础文件名后加创建时间作为文件名

可以看到,随着日志越来越多,之前较早产生的test-2024-03-06T08-43-10.979.log文件被自动删除了,因为设置的最多保留五个日志文件

至此,我们总结了如何将Zap日志程序集成到Go应用程序项目中。
这篇关于3. 在Go语言项目中使用Zap日志库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





