本文主要是介绍LeNet5实战——衣服分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 搭建模型
- 训练代码(数据处理、模型训练、性能指标)——> 产生权重w ——>模型结构c、w
- 测试
配置环境
Pycharm刚配置的环境找不到了-CSDN博客
model.py
导入库
import torch
from torch import nn
from torchsummary import summary模型搭建

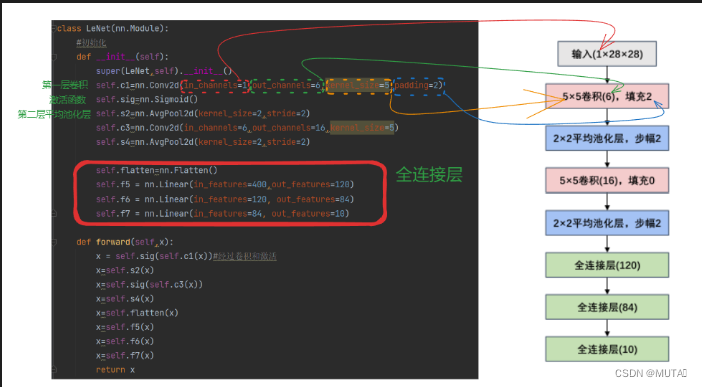

note:
- stride 步幅为1,和默认值一样,不用写
- padding=0,和默认一样不用写
代码
import torch
from torch import nn
from torchsummary import summary class LeNet(nn.Module): #初始化 def __init__(self): super(LeNet,self).__init__() self.c1=nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2) self.sig=nn.Sigmoid() self.s2=nn.AvgPool2d(kernel_size=2,stride=2) self.c3=nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5) self.s4=nn.AvgPool2d(kernel_size=2,stride=2) self.flatten=nn.Flatten() self.f5 = nn.Linear(in_features=400,out_features=120) self.f6 = nn.Linear(in_features=120, out_features=84) self.f7 = nn.Linear(in_features=84, out_features=10) def forward(self,x): x = self.sig(self.c1(x))#经过卷积和激活 x=self.s2(x) x=self.sig(self.c3(x)) x=self.s4(x) x=self.flatten(x) x=self.f5(x) x=self.f6(x) x=self.f7(x) return x if __name__=="__main__": device = torch.device("cuda" if torch.cuda.is_available()else "cpu") print(device) model = LeNet().to(device)#实例化 print(summary(model,input_size=(1,28,28)))前向传播结果

plot.py
模型加载
下载数据集

打包数据
为什么要移除一维?
因为之前将数据打包成64一组,数据格式为64 *28 * 28 * 1,把64移除,剩下的28* 28 * 1就是图片格式
获取图片数据

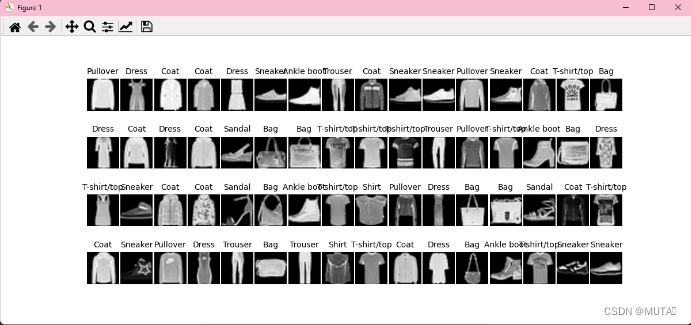
可视化数据(图片)

代码
from torchvision.datasets import FashionMNIST
from torchvision import transforms#处理数据集
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import LeNet # 导入模型(没有训练的模型) def train_val_data_process(): train_data = FashionMNIST(root='./data', train=True, transform=transforms.Compose([transforms.Resize(size=28), transforms.ToTensor()]), # 转换成张量形式方便应用 download=True) train_data,val_data = Data.random_split(train_data,lengths=(round(0.8*len(train_data)),round(0.2*len(train_data))))#随机划分数据 train_dateloader = Data.DataLoader(dataset=train_data, batch_size=128, shuffle=True, num_workers=8)#进程 val_dateloader = Data.DataLoader(dataset=val_data, batch_size=128, shuffle=True, num_workers=8) return train_dateloader,val_dateloader 可视化结果
一批次的图片(64张)
model_train.py
导入库
import copy
import time import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms # 处理数据集
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import LeNet # 导入模型(没有训练的模型)
import torch.nn as nn
import pandas as pd- FashionMNIST数据集由Zalando研究团队创建,包含了10个不同类别的灰度图像。每个图像的尺寸为28x28像素,共有训练集和测试集两部分。(衣服分类数据集)
transforms模块提供了一种方便的方式来对图像数据进行常见的预处理操作,如缩放、裁剪、旋转、翻转、标准化等。它还可以用于将图像数据转换为张量(Tensor)格式,并根据需要进行其他转换操作。torch.utils.data是PyTorch中的一个模块,提供了用于数据加载和预处理的工具类和函数。它提供了一种方便的方式来处理和准备数据,以供机器学习模型的训练和评估使用。torch.utils.data模块中的两个重要类是Dataset和DataLoader。torch.nn模块包含了许多常用的神经网络层类,提供了各种损失函数。pandas是一个功能强大且灵活的数据处理和分析库,它提供了高性能、易于使用的数据结构和数据分析工具
train_val_data_process()
代码
def train_val_data_process(): train_data = FashionMNIST(root='./data', train=True, transform=transforms.Compose([transforms.Resize(size=28), transforms.ToTensor()]), # 转换成张量形式方便应用 download=True) train_data, val_data = Data.random_split(train_data, lengths=( round(0.8 * len(train_data)), round(0.2 * len(train_data)))) # 随机划分数据 train_dataloader = Data.DataLoader(dataset=train_data, batch_size=32, shuffle=True, num_workers=2) # 进程 val_dataloader = Data.DataLoader(dataset=val_data, shuffle=True, num_workers=2) return train_dataloader, val_dataloaderFashinMNIST
FashionMNIST是一个用于图像分类的数据集,包含了10个类别的服装图像。 指定root参数为'./data',train参数为True,transform参数为一个transforms.Compose对象,以及download参数为True,可以下载并加载FashionMNIST数据集。
transforms.Compose对象是一个数据预处理的组合,这里使用了transforms.Resize将图像大小调整为28×28,并使用transforms.ToTensor将图像转换为张量形式。
Data.random_split
将train_data按照8|2的比例随机划分给train_data和val_data
Data.DataLoader

- dataset:指定要加载的数据集,这里是train_data,即训练数据集。
- batch_size:指定每个批次中的样本数量,这里是32,表示每次加载32个样本。
- shuffle:指定是否在每个迭代周期前打乱数据顺序,这里设置为True,表示在每个迭代周期前打乱数据顺序。
- num_workers:指定用于数据加载的线程数,这里设置为2,表示使用2个进程进行数据加载。
train_model_process
代码
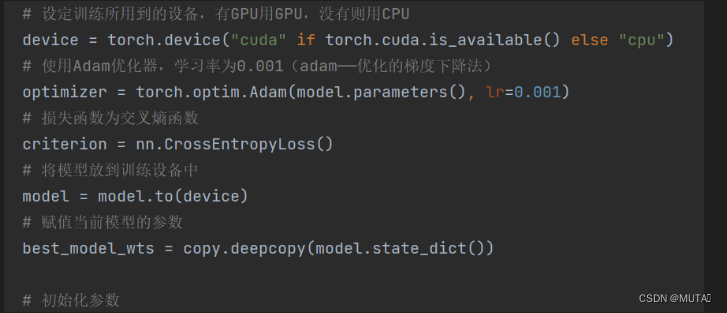
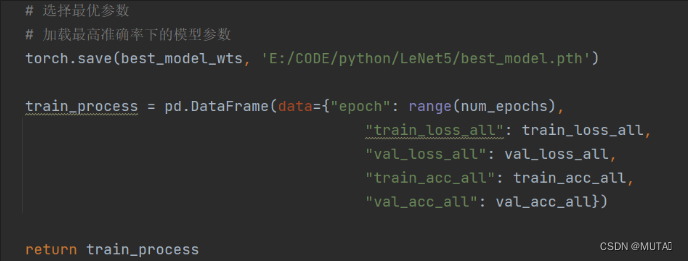
def train_model_process(model, train_dataloader, val_dataloader, num_epochs): # 设定训练所用到的设备,有GPU用GPU,没有则用CPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 使用Adam优化器,学习率为0.001(adam——优化的梯度下降法) optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 损失函数为交叉熵函数 criterion = nn.CrossEntropyLoss() # 将模型放到训练设备中 model = model.to(device) # 赋值当前模型的参数 best_model_wts = copy.deepcopy(model.state_dict()) # 初始化参数 # 最高精准度 best_acc = 0.0 # 训练集损失函数列表 train_loss_all = [] # 验证集损失函数列表 val_loss_all = [] # 训练集精度列表 train_acc_all = [] # 验证集精度列表 val_acc_all = [] # 当前时间 since = time.time() for epoch in range(num_epochs): print("Epoch {}/{}".format(epoch, num_epochs - 1)) print("-" * 10) # 初始化参数 # 训练集损失函数 train_loss = 0.0 # 训练集准确度 train_corrects = 0 # 验证集损失函数 val_loss = 0.0 # 验证集准确度 val_corrects = 0 # 训练集样本数量 train_num = 0 # 验证集样本数量 val_num = 0 # 对每一个mini-batch训练和计算 for step, (b_x, b_y) in enumerate(train_dataloader): # 将特征放入到训练设备中 b_x = b_x.to(device) # 将标签放入到训练设备中 b_y = b_y.to(device) # 设置模型为训练模式 model.train() # 前向传播过程,输入为一个batch,输出为一个batch中对应的预测 output = model(b_x) # 查找每一行中最大值对应的行标 pre_lab = torch.argmax(output, dim=1) # 模型的输出和标签计算损失函数 loss = criterion(output, b_y) # 将梯度初始化为0 optimizer.zero_grad() # 反向传播计算 loss.backward() # 根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值的作用 optimizer.step() # 对损失函数进行累加 train_loss += loss.item() * b_x.size(0) # 如果预测正确,则准确度train_corrects+1 train_corrects += torch.sum(pre_lab == b_y.data) # 当前用于训练的样本数量 train_num += b_x.size(0) for step, (b_x, b_y) in enumerate(val_dataloader): b_x = b_x.to(device) b_y = b_y.to(device) # 设置模型为验证模式 model.eval() output = model(b_x) pre_lab = torch.argmax(output, dim=1) loss = criterion(output, b_y) val_loss += loss.item() * b_x.size(0) val_corrects += torch.sum(pre_lab == b_y.data) val_num += b_x.size(0) # 计算并保存每一次迭代的loss值 train_loss_all.append(train_loss / train_num) # 计算并保存训练集的准确率 train_acc_all.append(train_corrects.double().item() / train_num) val_loss_all.append(val_loss / val_num) val_acc_all.append(val_corrects.double().item() / val_num) print('{} Train Loss:{:.4f} Train Acc:{:.4f}'.format(epoch, train_loss_all[-1], train_acc_all[-1])) print('{} Val Loss:{:.4f} Val Acc: {:.4f}'.format(epoch, val_loss_all[-1], val_acc_all[-1])) # 寻找最高准确度的权重 if val_acc_all[-1] > best_acc: best_acc = val_acc_all[-1] best_model_wts = copy.deepcopy(model.state_dict()) # 训练耗时 time_use = time.time() - since print("训练耗费的时间:{:0f}m{:0f}s".format(time_use // 60, time_use % 60)) # 选择最优参数 # 加载最高准确率下的模型参数 torch.save(best_model_wts, 'E:/CODE/python/LeNet5/best_model.pth') train_process = pd.DataFrame(data={"epoch": range(num_epochs), "train_loss_all": train_loss_all, "val_loss_all": val_loss_all, "train_acc_all": train_acc_all, "val_acc_all": val_acc_all}) return train_process准备
一个迭代周期
初始化参数

对一批次的数据进行训练
遍历数据

for循环
for step, (b_x, b_y) in enumerate(train_dataloader): 是一个 for 循环语句的语法结构,用于迭代遍历一个可迭代对象 train_dataloader。 在每次循环迭代中,enumerate(train_dataloader) 将返回一个 (step, (b_x, b_y)) 的元组,其中: step 是当前迭代的索引值,表示当前是第几个迭代步骤。 (b_x, b_y) 是从 train_dataloader 中获取的一个批次的数据。
前向传播
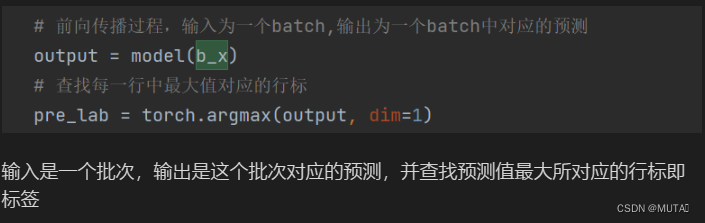
模型的输出和标签计算损失函数
![]()
损失函数-----评估模型输出与真实标签之间的差异的函数
反向传播
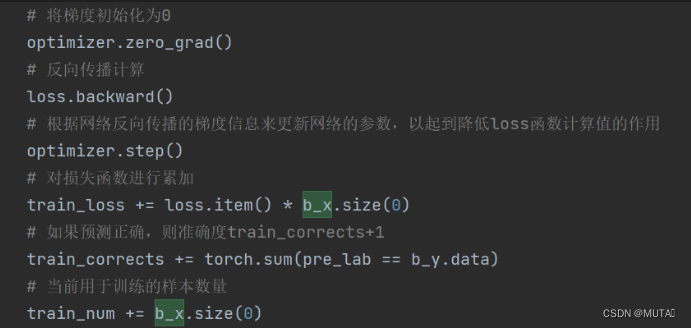
更新网络并预测判断
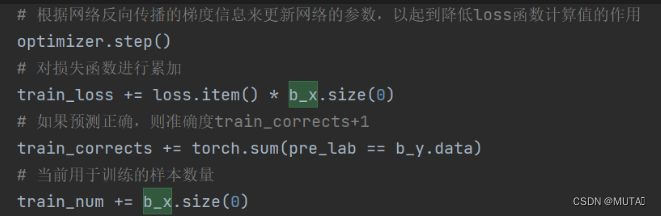
对一批次数据进行验证

注意
验证没有反向传播过程,因为验证数据在训练过程中主要用于评估模型的性能,而不是用于参数更新。在验证阶段,参数更新可能会导致模型在验证集上过拟合,并且会增加计算开销。因此,验证阶段只需要进行前向传播和损失计算,以获取模型在验证集上的性能指标,而不需要进行反向传播和参数更新。
一批次结束,计算并保存损失值和准确率

寻找最高准确度的权重
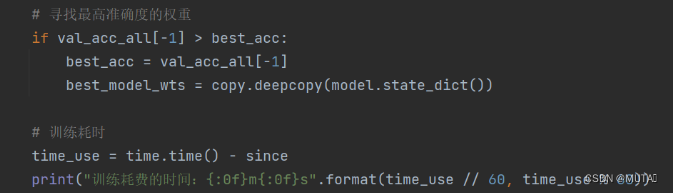
选择最优参数并返回
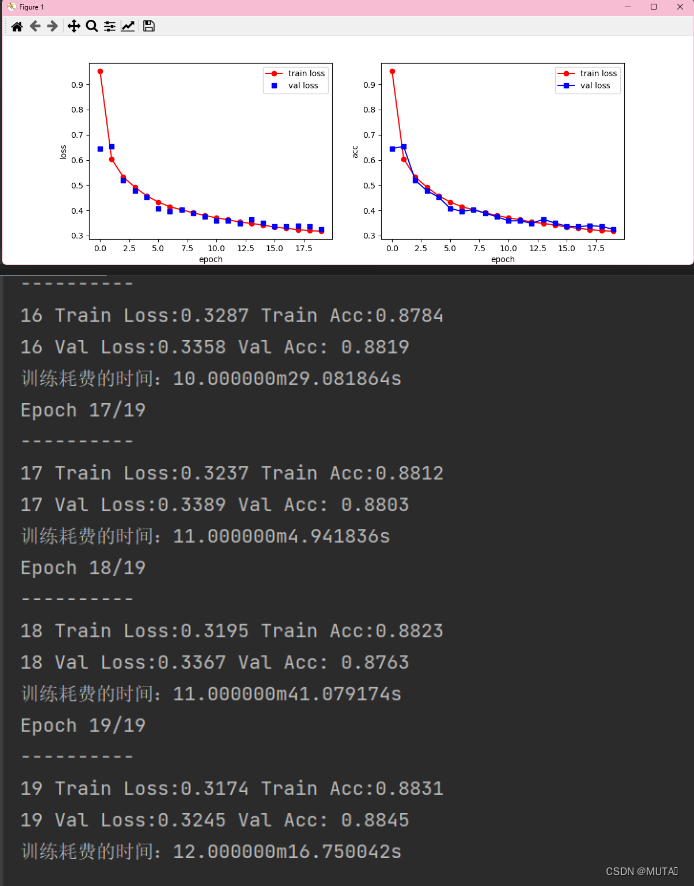
matplot_acc_lost
代码
def matplot_acc_lost(train_process): plt.figure(figsize=(12, 4)) plt.subplot(1, 2, 1) # 一行两列第一幅图 plt.plot(train_process["epoch"], train_process.train_loss_all, 'ro-', label="train loss") plt.plot(train_process["epoch"], train_process.val_loss_all, 'bs', label="val loss") plt.legend() plt.xlabel("epoch") plt.ylabel("loss") plt.subplot(1, 2, 2) # 一行两列第二幅图 plt.plot(train_process["epoch"], train_process.train_loss_all, 'ro-', label="train loss") plt.plot(train_process["epoch"], train_process.val_loss_all, 'bs-', label="val loss") plt.xlabel("epoch") plt.ylabel("acc") plt.legend() plt.show()结果
modemodel_test.py
test_data_process
def test_data_process(): test_data = FashionMNIST(root='./data', train=False, transform=transforms.Compose([transforms.Resize(size=28), transforms.ToTensor()]), # 转换成张量形式方便应用 download=True) test_dataloader = Data.DataLoader(dataset=test_data, batch_size=1, shuffle=True, num_workers=0) return test_dataloadertest_model_process
def test_model_process(model, test_dataloader): device = "cuda" if torch.cuda.is_available() else 'cpu' model = model.to(device) test_corrects=0.0 test_num=0 #只进行前向传播计算,不计算梯度,从而节省内存,加快运行速度 with torch.no_grad(): for test_data_x,test_data_y in test_dataloader: test_data_x=test_data_x.to(device) test_data_y=test_data_y.to(device) model.eval() #前向传播过程,输入为测试数据集,输出为对每个样本的预测值 output=model(test_data_x) #查找每一行中最大值对应的行标 pre_lab=torch.argmax(output,dim=1) test_corrects += torch.sum(pre_lab==test_data_y.data) test_num += test_data_x.size(0) #计算测试准确率 test_acc=test_corrects.double().item() / test_num print("测试的准确率为:",test_acc)torch.no_grad
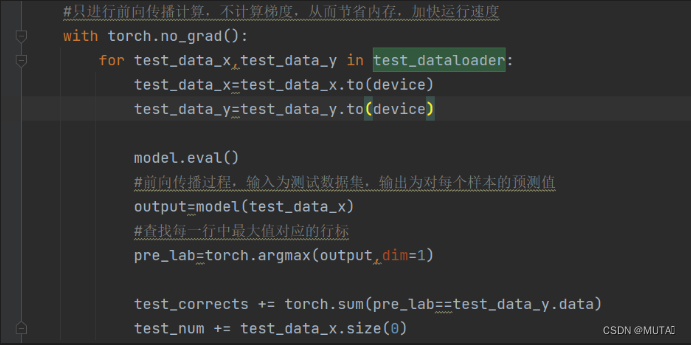
torch.no_grad()是一个上下文管理器,用于在代码块中禁用梯度计算和参数更新。当进入torch.no_grad()的上下文中时,PyTorch会自动将requires_grad属性设置为False,从而禁止梯度的计算和参数的更新。
torch.no_grad()常用于评估模型或进行推断过程,不需要计算梯度的情况下,可以提高代码的执行效率并减少内存消耗。
这篇关于LeNet5实战——衣服分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






