本文主要是介绍Multi-task face analyses through adversarial learning【PR 2021】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Abstract
Introduction
Proposed method
Experiments
数据集
训练细节
一些理解
Abstract
关键点检测、头部姿态估计、性别识别、人脸属性估计等多个人脸分析任务之间的内在关系和人脸分析任务之间的内在关系是提高每个任务绩效的关键,但由于这些多重人脸分析任务通常作为单独的任务进行,因此尚未得到深入的探索。在本文中,我们提出了一种新的深度多任务对抗性学习方法,通过从图像表征级和标签级来探索它们的依赖性,来定位面部地标、估计头部姿态和共同识别性别或同时估计多个人脸属性。具体来说,该方法由深度识别网络R和鉴别器D组成。利用深度识别网络学习共享的中层图像表示,并同时进行多个人脸分析任务。识别网络通过多任务学习机制,从图像表示层面探索多个人脸分析任务之间的依赖关系。引入了鉴别器来加强多重人脸分析任务的分布,使其收敛于地面真实标签中固有的分布。在训练过程中,识别器试图混淆鉴别器,而鉴别器通过区分预测的标签组合与地面真实的标签组合来与识别器竞争。通过对抗性学习,我们从标签层面探讨了多个人脸分析任务之间的依赖关系。在基准数据库上的实验结果表明了该方法在多任务人脸分析中的有效性。
Introduction
近年来,由于人脸分析在人机交互中的广泛应用而受到越来越多的关注。人脸分析包括面部地标检测、头部姿态估计、人脸识别、面部表情分类、性别识别和多重人脸属性估计等任务。这些任务是相互关联的。例如,如图1所示,戴项链和耳环的人更可能是女性,不太可能是男性;鬓角和山羊胡的人更可能是男性,更不可能是女性;地标的位置受头部姿势的影响;面部表情的变化明显影响地标的位置。这种面部标志、头部姿势和表情或多个面部属性之间的内在联系可以用于多个面部分析任务,但尚未被彻底探索,因为通常的面部分析任务是单独处理的。

直到最近,一些作品才转向共同解决几个人脸分析任务。
据我们所知,尽管表征级依赖和标签级依赖对多个人脸分析任务都至关重要,但到目前为止,很少有工作同时解决它们。因此,在本文中,我们通过从表征级和标签级探索多人脸分析任务的依赖性,提出了一种针对多任务对抗的深度学习方法。具体来说,我们构建了一个深度网络作为多任务识别器,通过表征水平来探索多个面部分析任务之间的联系。这些任务包括与面部关键相关的多任务面部分析,共同预测面部关键点、关键点可见度、人脸姿态和性别,以及面部属性估计。然后,在对抗学习框架下,识别器与鉴别器竞争,多任务识别器预测的标签的联合分布收敛于地面真实标签固有的联合分布。因此,还捕获了来自标签级的多任务依赖关系。在基准数据库上的实验结果表明,该方法成功地利用了表示和目标标签中固有的任务依赖性,从而在多重人脸分析任务上取得了最先进的性能。
Proposed method
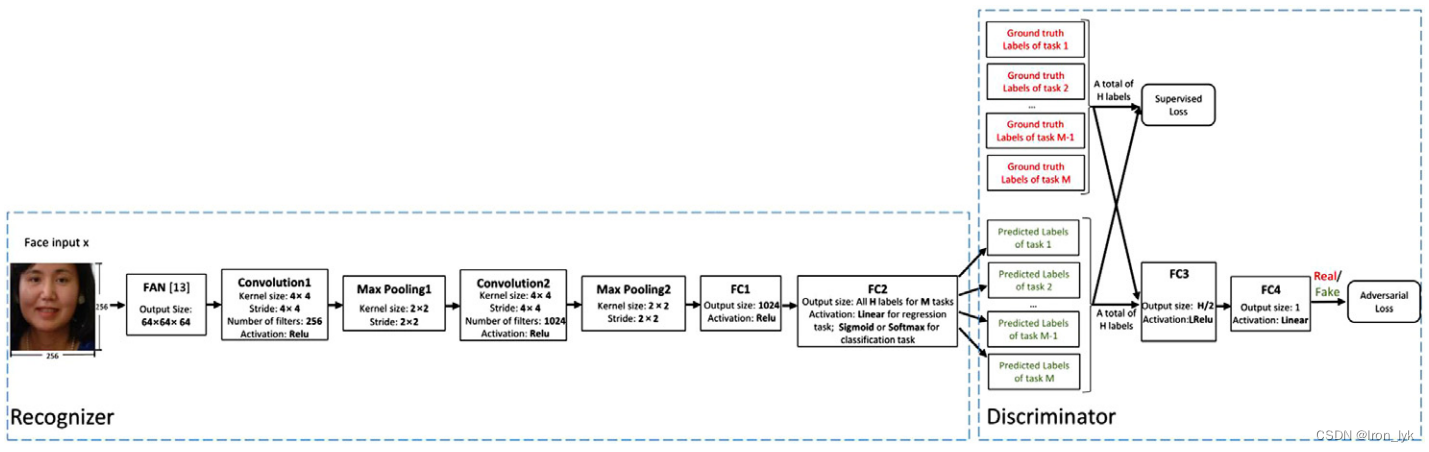
框架如上图所示。网络包括一个识别器R(Recognizer)和一个鉴别器D(Discriminator)。总体思路就是,在识别器部分,作者使用的是FAN网络(https://www.adrianbulat.com/face-alignment)来编码人脸表征信息,然后使用CNN和全连接层得到一个预测的combination。在鉴别器部分,负责将ground-truth的distribution与R预测的combination区分开来,不断地去学习,直至这两个分布的距离小于某个值才停止学习。
Experiments
数据集
AFLW和Multi-PIE数据集同时包含了人脸关键点、相应的可见度、头部姿态和性别信息。
AFLW数据集包含了21997张照片,共有25993个面孔,标注了21个关键点,姿态,表情,种族,年龄和性别信息。在AFLW数据集中对每张人脸都标注了一个可见度信息,0或1,代表这张人脸是否被遮挡。也标注了每个关键点的可见度信息,但所有的关键点的可见度标注都是0(可见),因为AFLW数据集在手工标注时就是只标注了可见的关键点。在本文中作者与文章Hyperface[1]中划分训练集、测试集的方法一样。
Multi-PIE数据集包含了337个被试,在13个yaw角下拍摄,有19中照明情况,共75万张照片。有6152张图片标注了关键点,关键点的数量从39到68不等。该数据集也包含了visibility的标注,但是是人脸的可见度visibility,对于一张人脸只标注了一个0或1代表这个人脸是否被遮挡,并没有标注每个关键点的可见度visibility。按照Wu等[2]相同的样本选择策略,本文使用前150名被试的面部图像作为训练数据,并使用id在151-200的被试作为测试数据。
IBUG数据库包含了135张图片,每个他们都标注了68个人脸关键点。在本文中用作测试集。
CelebA数据库是一个大规模的无约束的人脸属性数据库,包含超过10,000个人,每个人都有20张图像,总共超过20万张图像。LFWA数据库有13223张图像,包含5749个人。CelebA数据库和LFWA数据库中的每一张图像都标注了40个人脸属性。这两个数据库在属性估计方面都具有挑战性,因为在表情、姿态、种族、照明、背景等方面都有很大的变化。
训练细节
当训练集是AFLW时,判别器的输入维度是:21+21+3+1=46,也就是识别器需对输入的图像识别出21个关键点的坐标x(21),坐标y(21),以及人脸的yaw、pitch和roll姿态角(3),和可见度(1)。需要注意的是,最后的可见度信息是人脸的可见度,并不是每个关键点的可见度。
一些理解
“从表征级和标签级探索多人脸分析任务的依赖性”:表征级与标签级的意思,就是使用同一个图像的表征来预测出多个label的combination,并将这个combination作为一个整体输入给判别器D,然后将这个整体各个部分与各个任务的label进行比较。作者说这样做的目的可以从表征级和标签级探索多人脸分析任务的依赖性,从而提升任务的性能。
[1]. R. Ranjan, V.M. Patel, R. Chellappa, HyperFace: a deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition, TPAMI 41 (1) (2019) 121–135.
[2]. Y. Wu, C. Gou, Q. Ji, Simultaneous facial landmark detection, pose and deformation estimation under facial occlusion, in: CVPR, 2017, pp. 3471–3480.
这篇关于Multi-task face analyses through adversarial learning【PR 2021】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






