本文主要是介绍HDFS简介与部署以及故障排错(超简单),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、HDFS介绍
- 1、简介
- 2、结构模型
- 3、文件写入过程
- 4、文件读取过程
- 5、文件块的存放
- 6、存储空间管理机制
- 6.1 文件删除和恢复删除
- 6.2 复制因子配置
- 6.3 文件命名空间
- 6.4 数据复制机制
- 二、环境搭建(单机版)
- 1、修改主机名
- 2、配置ssh免密登录
- 3、Hadoop安装
- 3.1 下载 Hadoop
- 3.2 配置环境变量(前提需要 java环境,自行安装)
- 3.3 配置HDFS
- 3.4 启动Hadoop(命令都在sbin文件夹下)
- 三、出现问题及解决办法
- 1、错误一(没有为启动脚本配置用户)
- 2、错误二(没有配置ssh免密登录)
一、HDFS介绍
1、简介
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。
- HDFS是一个高度容错性的系统,适合部署在廉价的机器上;
- HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用;
- HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
2、结构模型
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的,在Hadoop2.2以上版本已经实现多个NameNode的配置。
NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户真实数据永远不会经过NameNode节点。
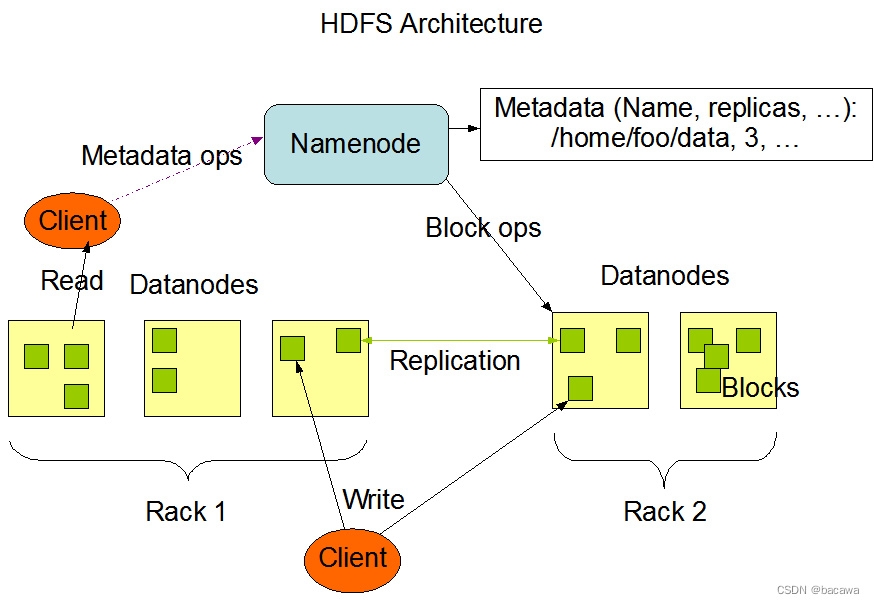
3、文件写入过程
-
Client向NameNode发起文件写入的请求;
-
NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息;
-
Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
4、文件读取过程
-
Client向NameNode发起读取文件的请求;
-
NameNode返回文件存储的DataNode信息;
-
Client读取文件信息。
5、文件块的存放
结构模型(本文1.2 章节)中的图例中 Block表示一个文件的一部分,即HDFS会将文件拆成多个块存储。
- 一个Block会有三份备份,一份在NameNode指定的DateNode上, 一份放在与指定的DataNode不在同一台机器的DataNode上, 一份放在指定的DataNode在同一Rack上的DataNode上;
- 备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题。
HDFS的设计是用于支持大文件的。这些程序仅写一次数据,一次或多次读数据请求,并且这些读操作要求满足流式传输速度。HDFS支持文件的一次写多次读操作。HDFS中典型的块大小是64MB,一个HDFS文件可以被切分成多个64MB大小的块,如果需要,每一个块可以分布在不同的数据节点上。默认块的大小是128M
HDFS是设计来存储和管理大数据的,因此典型的HDFS块大小明显比平时我们看到的传统文件系统块大得多,块大小的设置用来将大文件切割成一个数据块,再将这些数据块分发到集群上,
例如集群的块大小设置为64MB,一个128MB的文件上传到HDFS上,HDFS会将这个文件切分成2(128/64)个数据块,再将这两块数据分发到集群的数据节点上。
设置块大小:打开 hdfs-site.xml,(在hadoop安装目录下的etc文件夹里)
操作步骤:设置 hdfs-site.xml下面的属性值:
<property><name>dfs.block.size</name><value>134217728</value> --修改为128M<description>Block size</description>
</property>
hdfs-site.xml是HDFS的配置文件,修改hdfs-site.xml配置文件的dfs.block.size属性值就会改变上传到HDFS所有文件的默认块大小。修改这个值并不会对HDFS上现存的任何文件的块大小产生影响,只会改变新上传文件的块大小。
6、存储空间管理机制
6.1 文件删除和恢复删除
当一个文件被用户或程序删除时,它并没有立即从HDFS中删除。HDFS将它重新命名后转存到/trash目录下,这个文件只要还在/trash目录下保留就可以重新快速恢复。文件在/trash中存放的时间是可配置的。存储时间超时后,名字节点就将目标文件从命名空间中删除,同时此文件关联的所有文件块都将被释放。注意,用户删除文件的时间和HDFS系统回收空闲存储之间的时间间隔是可以估计的。
删除一个文件之后,只要它还在/trash目录下,用户就可以恢复删除一个文件。如果一个用户希望恢复删除他已经删除的文件,可以查找/trash目录获得这个文件。/trash目录仅保存最新版本的删除文件。/trash目录也像其他目录一样,只有一个特殊的功能,HDFS采用一个特定的策略去自动地删除这个目录里的文件,当前默认的策略是删除在此目录存放超过6小时的文件。以后这个策略将由一个定义好的接口来配置。
6.2 复制因子配置
当文件的复制因子减少了,NameNode 节点选择删除多余的副本,下一次的心跳包的回复就会将此信息传递给 DataNode 节点。然后,DataNode节点移除相应的块,对应的空闲空间将回归到集群中,需要注意的就是,在setReplication函数调用后和集群空闲空间更新之间会有一段时间延迟。
6.3 文件命名空间
HDFS支持传统的继承式的文件组织结构。
- 一个用户或一个程序可以创建目录,存储文件到很多目录之中。
- 文件系统的命名空间层次和其他的文件系统相似。可以创建、移动文件,将文件从一个目录移动到另外一个,或重命名。
- HDFS还没有实现用户的配额和访问控制。
- HDFS还不支持硬链接和软链接。然而,HDFS结构不排斥在将来实现这些功能。
NameNode 节点维护文件系统的命名空间,任何文件命名空间的改变和或属性都被 NameNode 节点记录。应用程序可以指定文件的副本数,文件的副本数被称作文件的复制因子,这些信息由 NameNode 节点来负责存储。
6.4 数据复制机制
默认一个文件被分成多块,且每块有默认3个备份。
HDFS设计成能可靠地在集群中大量机器之间存储大量的文件,它以块序列的形式存储文件。文件中除了最后一个块,其他块都有相同的大小。属于文件的块为了故障容错而被复制。块的大小和复制数是以文件为单位进行配置的,应用可以在文件创建时或者之后修改复制因子。HDFS中的文件是一次写的,并且任何时候都只有一个写操作。
NameNode 节点负责处理所有的块复制相关的决策。它周期性地接受集群中 DataNode 节点的心跳和块报告。一个心跳的到达表示这个DataNode节点是正常的。一个块报告包括该 DataNode 节点上所有块的列表。
二、环境搭建(单机版)
1、修改主机名
##修改主机名(可以自己修改)
hostnamectl set-hostname hadoop001##查看主机名,进行验证
hostname
2、配置ssh免密登录
- 先进入到~/.ssh/路径
cd ~/.ssh/
- 创建公钥/私钥
ssh-keygen -t rsa
按三下Enter键即可
- 复制公钥id到hadoop001
ssh-copy-id hadoop001
- 查看能否免密登录成功
ssh hadoop001
出现以下信息即成功:
[root@hadoop001 .ssh]# ssh hadoop001
Last login: Tue Mar 5 15:44:20 2024 from localhost
3、Hadoop安装
3.1 下载 Hadoop
## 下载Hadoop
[root@hadoop001 hdfs]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.3.6.tar.gz
## 解压
[root@hadoop001 hdfs]# tar -zxvf hadoop-3.3.6.tar.gz
3.2 配置环境变量(前提需要 java环境,自行安装)
##配置环境变量
[root@hadoop001 hdfs]# vim /etc/profile
增加以下内容,路径根据自己的环境适当修改
export HADOOP_HOME=/hdfs/hadoop-3.3.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
##环境生效
[root@hadoop001 hdfs]# source /etc/profile
[root@hadoop001 hadoop]# hadoop version

3.3 配置HDFS
- 配置 hadoop-env.sh
[root@hadoop001 hadoop]# pwd
/hdfs/hadoop-3.3.6/etc/hadoop
[root@hadoop001 hadoop]# vim hadoop-env.sh
找到对应配置项,配置java环境
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
- 配置 core-site.xml
进入目录:hadoop-3.3.6/etc/hadoop 修改 core-site.xml 文件,并在中增加如下的内容。请仔细阅读代码块的注释。
<!--1.配置默认采用的文件系统。(由于存储层和运算层松耦合,要为它们指定使用hadoop原生的分布式文件系统hdfs。value填入的是uri,参数是 分布式集群中主节点的地址 : 指定端口号)2.其中IP根据自己环境进行配置-->
<property><name>fs.defaultFS</name><value>hdfs://IP:9000/</value>
</property><!-- 配置hadoop的公共目录(指定hadoop进程运行中产生的数据存放的工作目录,NameNode、DataNode等就在本地工作目录下建子目录存放数据。但事实上在生产系统里,NameNode、DataNode等进程都应单独配置目录,而且配置的应该是磁盘挂载点,以方便挂载更多的磁盘扩展容量)/hdfs/data_hadoop路径需要提前建好
-->
<property><name>hadoop.tmp.dir</name><value>/hdfs/data_hadoop</value>
</property>- 配置 hdfs-site.xml
提前建好 NameNode 和 DataNode 的数据目录
<!--## 副本备份的数量-->
<property><name>dfs.replication</name><value>2</value>
</property><!-- #设置NameNode数据存储目录-->
<property><name>dfs.namenode.name.dir</name><value>file:/hdfs/namenode</value>
</property><!--#设置DataNode数据存储目录-->
<property><name>dfs.datanode.data.dir</name><value>file:/hdfs/datanode</value>
</property><!-- #这里在不加的话 hdfs的网站访问不了-->
<property><name>dfs.http.address</name><value>0.0.0.0:50070</value>
</property><!--#这里可以考虑取消写入权限限制否则只能通过命令hadoop fs -chmod 777 /soft/hadoop/warehouse/student 来增加针对某个目录的写权限--><property><name>dfs.permissions</name><value>false</value>
</property>3.4 启动Hadoop(命令都在sbin文件夹下)
- 必须在启动前格式化HDFS中的数据(从命令上看是清除 NameNode 上存储的数据)
[root@hadoop001 sbin]# hadoop namenode -format
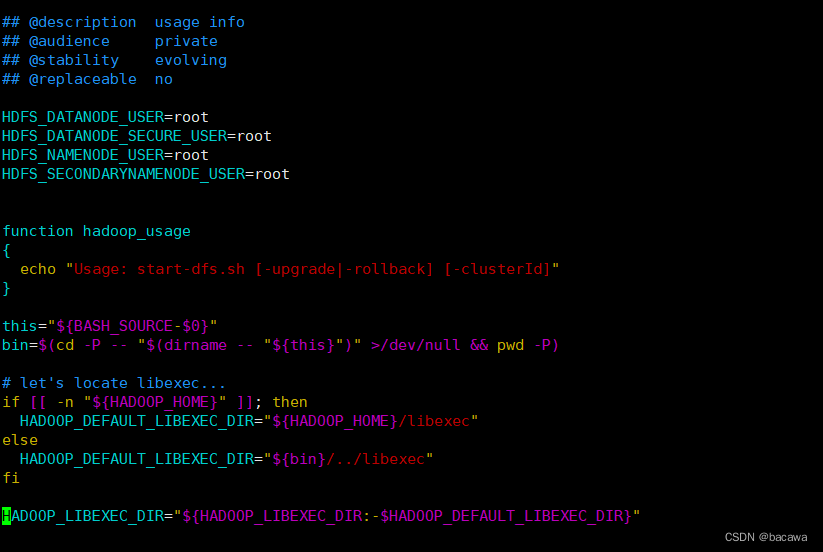
- 配置启动脚本,增加如下内容 (如下图所示)
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 启动HDFS服务
[root@hadoop001 sbin]# ./start-dfs.sh
查看服务启动情况
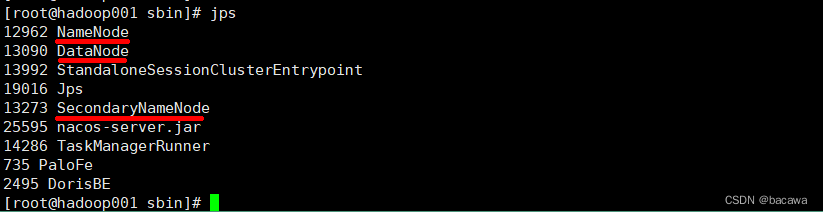
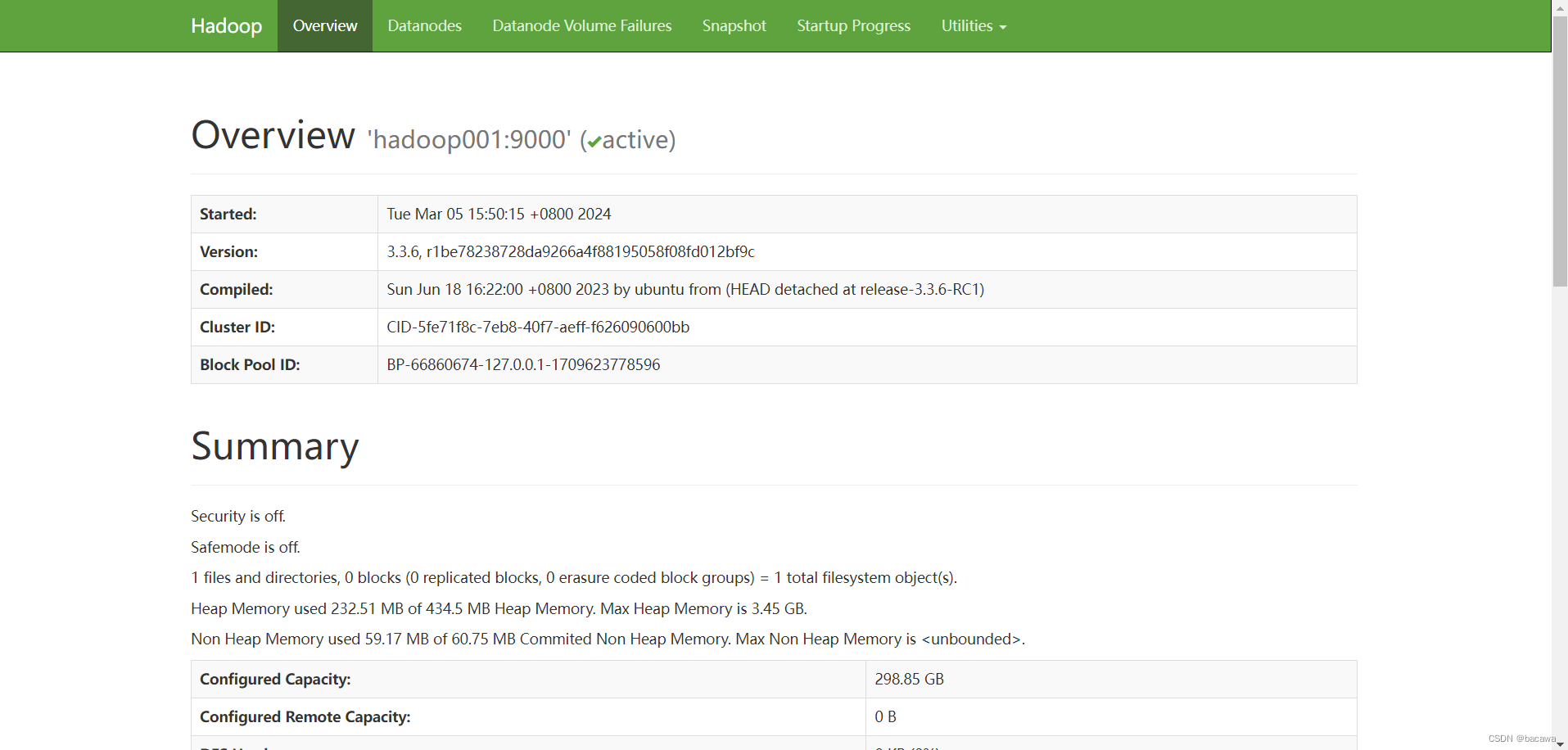
看到上图勾出的几个进程,说明服务已经启动成功,通过界面查看HDFS Web UI,注意替换自己的IP
http://IP:50070/dfshealth.html#tab-overview
三、出现问题及解决办法
1、错误一(没有为启动脚本配置用户)
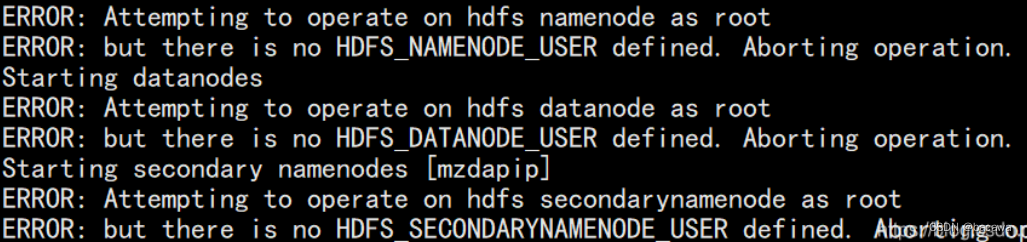
解决办法: 出现这个错误,请确认下步骤 2.3.4 章节是不是执行。
2、错误二(没有配置ssh免密登录)

hadoop001 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
解决办法: 出现这个错误,说明 没有配置ssh免密登录 请确认下步骤2.2 章节是不是执行。
结束!
这篇关于HDFS简介与部署以及故障排错(超简单)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








