本文主要是介绍CV方向好看的主图分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
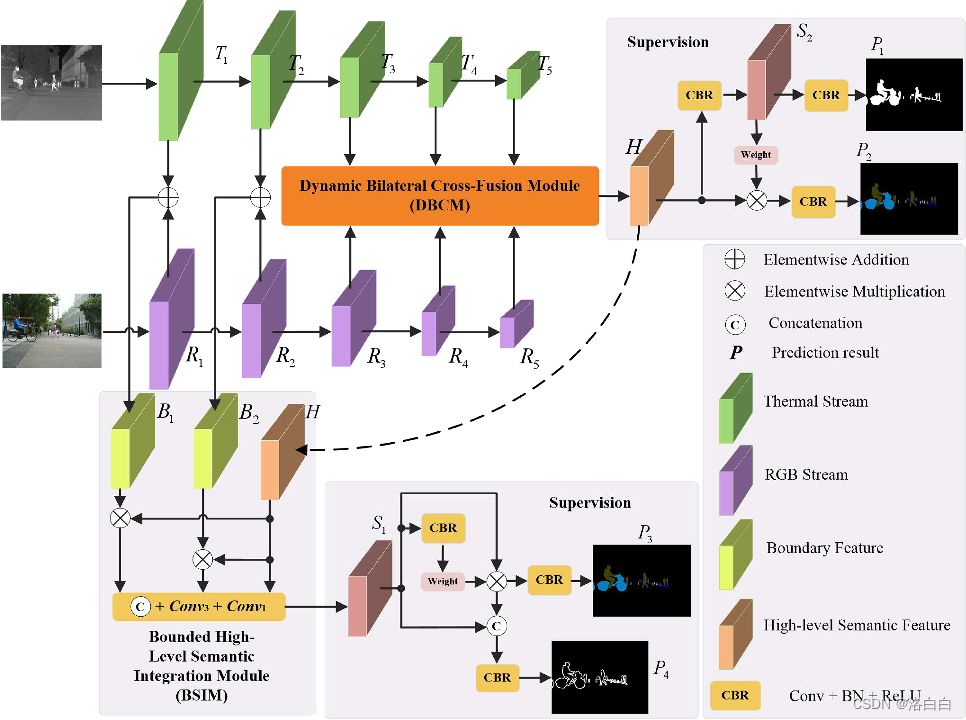
1. DBCNet: Dynamic Bilateral Cross-Fusion Network for RGB-T Urban Scene Understanding in Intelligent Vehicles
用于智能车辆RGB-T城市场景理解的动态双边交叉融合网络
概览:本文提出了一种名为DBCNet的动态双边交叉融合网络,用于智能车辆中RGB-T城市场景的理解。作者利用了RGB-T图像中的多模态信息,通过引入DBCNet来进行RGB-T城市场景理解。实验表明,DBCNet能够有效地聚合多层次的深层特征,并优于最先进的深度学习场景理解方法。
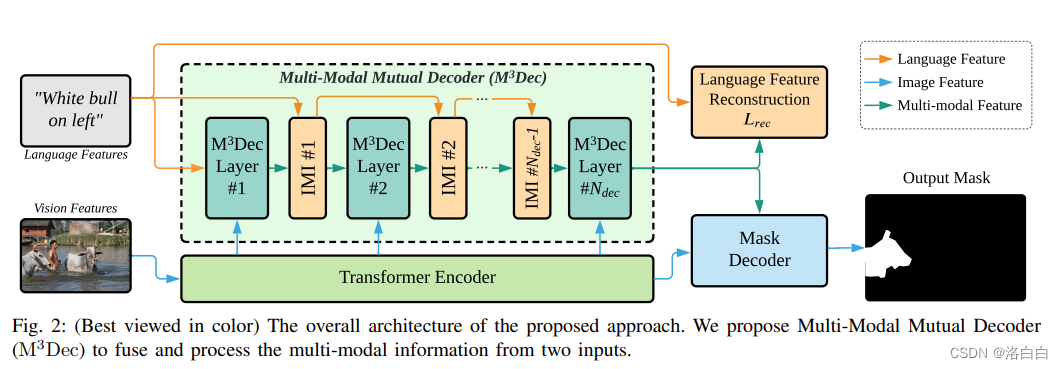
2. Multi-Modal Mutual Attention and Iterative Interaction for Referring Image Segmentation
多模态相互关注和迭代交互用于参考图像分割
概览:本文提出了一种名为多模态相互关注和多模态相互解码器的方法来解决参考图像分割问题。该方法通过更好地融合语言和视觉信息来提高模型对多模态信息的理解能力,并引入了迭代多模态交互和语言特征重建来允许连续和深入的交互以及防止丢失或扭曲语言信息。实验表明,该方法显著改善了基线并始终优于最先进的参考图像分割方法。
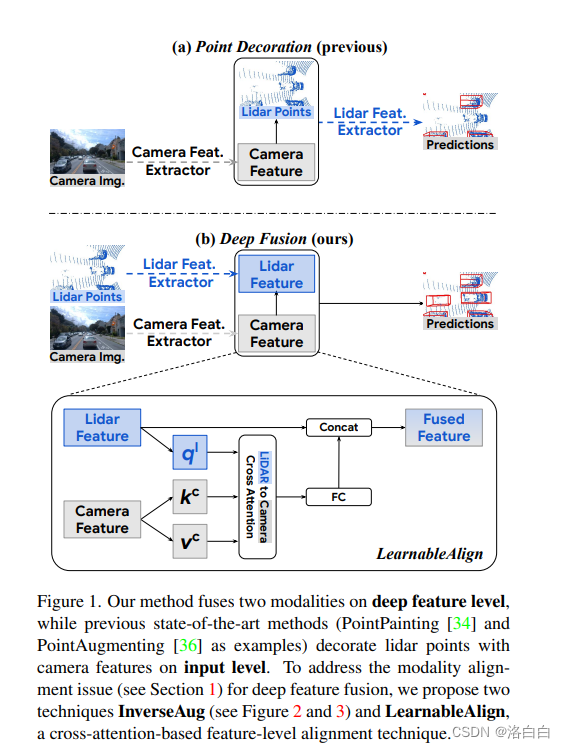
3. DeepFusion:Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
用于多模态3D对象检测的激光雷达-相机深度融合
概览:本文提出了一种通用多模态3D检测模型,用于自动驾驶中激光雷达和相机的深度融合。作者认为融合深层激光雷达特征和相机特征可以获得更好的性能。为了解决两种模态的特征对齐问题,作者提出了InverseAug和LearnableAlign两种新技巧。基于这些技巧,作者开发了一组名为DeepFusion的通用多模态3D检测模型,该模型比以前的方法更准确。
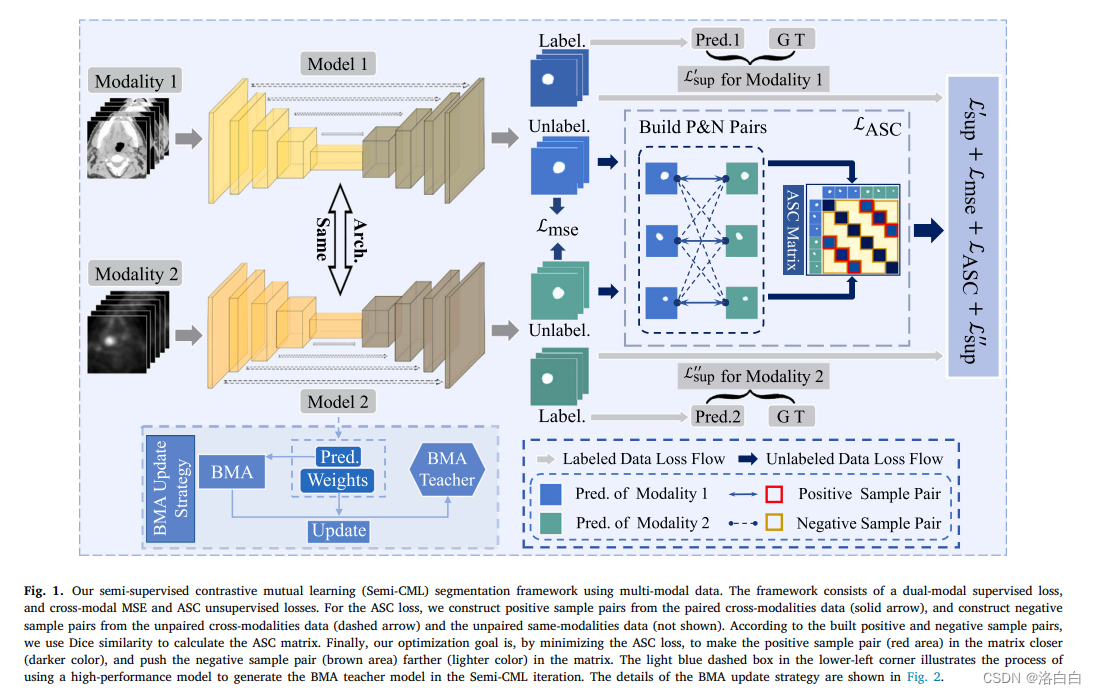
4. DeepFusion:Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
半监督医学图像分割的多模态对比互学习与伪标签再学习
概览:本文提出了一种半监督对比互学习分割框架Semi-CML,该框架利用跨模态信息和不同模态之间的预测一致性进行对比互学习。虽然Semi-CML可以同时提高两种模态的分割性能,但两种模态之间存在性能差距,即存在一种模态的分割性能通常优于另一种模态的情况。因此,作者进一步开发了一种软伪标签再学习(PReL)方案来弥补这种差距。
5. TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
基于Transformer的多曝光图像融合框架
概览:本文提出了一种基于Transformer的多曝光图像融合框架TransMEF,该框架使用自监督多任务学习。该框架通过三个自监督重建任务来学习多曝光图像的特征并提取更通用的特征。同时,为了弥补CNN架构在建立长期依赖关系方面的缺陷,设计了一个结合了CNN模块和Transformer模块的编码器。在多曝光图像融合基准数据集上,该方法在主观和客观评估中都取得了最佳性能。

这篇关于CV方向好看的主图分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





