本文主要是介绍CBAM: Convolutional Block Attention Module 论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
该论文提出 Convolutional Block Attention Module (CBAM),一个简单但是有效的用于前馈卷积注意力模块。给出中间特征图,模块可以顺序的从两个维度——通道和空间来推断 attention map,然后将 attention map 和 input feature map 相乘得到自适应的特征细化。并且CBAM是轻量级的,可以无缝整合到任何CNN结构中,并且开销可忽略不计,还可以和CNN一起端到端的进行训练。
Introduction
为提高 CNN 的性能,现有的研究主要关注三个重要的方面:深度、宽度和基数(cardinality)。
与这些方面不同,论文的研究聚焦于另一个架构设计的方面:attention。Attention 不仅仅告诉模型该关注哪里,还提升了兴趣点的表示。论文的目标就是通过使用注意力机制来提升表达能力:关注重要特征、抑制不重要的。我们的模型强调空间和通道这两个主要维度的有意义的特征。为达成这个目标,论文顺序采用通道和空间注意力模型。这样不同的分支可以分别学习去 attend ‘what’ and ‘where’。
主要贡献:
- 提出CBAM,一个简单有效的注意力模型,可以广泛应用来增强CNN的表示能力。
- 通过大量的 ablation studies 验证该注意力模型的有效性。
- 通过插入我们的轻型模块,我们验证了各种网络的性能在多个 benchmarks (ImageNet-1K、MS COCO和VOC 2007)上有很大提高。
Related Work
为了更好地捕捉视觉结构,人类利用一系列 partial glimpses,有选择地聚焦于显著部分。
我们不是直接计算3d注意力图,而是将学习通道注意力和空间注意力的过程分解。这样获得了更少的计算和参数开销。
和之前只使用 average pool 不同,CBAM同时使用了 max pool 和 average pool。这样可以更好的计算 channel 和 spatial attention。
Convolutional Block Attention Module
整体公式概括如下:
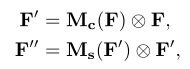
F为中间特征图,Mc是通道注意图,Ms是空间注意图。F’’ 是最后的细化输出。
总体图示如下:

Channel Attention Module
我们使用通道注意图来利用通道间特征的关系。为了高效计算 channel attention,论文缩小了输入特征图的空间维度。至今为止,平均池化通常被用来聚合空间信息。论文认为最大池化收集了另一个重要的信息来推断更精细的通道方向的注意力。因此论文同时使用平均池化和最大池化特征,并认为这样可以大幅提升网络的表达能力。
进行两种池化后得到的平均池化特征和最大池化特征被送入到一个共享的MLP网络,其中含有一个隐藏层。为减少参数开销,隐藏激活层被设置为 C/r * 1 * 1。其中 r 为减小倍率。
总体 channel attention 可描述如下:
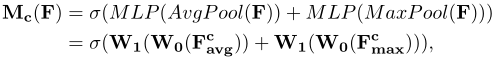
Spatial Attention Module
我们生成一个空间注意图通过利用特征的空间关系。空间注意关注于有信息的部分在哪,是对通道注意的一个补充。为计算空间关注,首先在通道维度使用平均池化和最大池化,然后合并他们来生成一个特征描述。使用通道维度上的池化操作,可以 highlight informative regions。对于生成的特征描述,使用一个卷积层来生成空间特征图,该图编码了哪里应该强调或抑制。
总体可描述为:
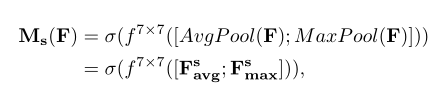
最后,论文发现,sequential arrangement 是比 parallel arrangement 效果要好的。
Experiments






这篇关于CBAM: Convolutional Block Attention Module 论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








