本文主要是介绍案例系列:银行信用卡欺诈_预测是否欺诈_ 自编码器AutoEncoder二分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
案例系列:银行信用卡欺诈_预测是否欺诈_ 自编码器AutoEncoder二分类
代码:
https://download.csdn.net/download/wjjc1017/88641713
简介
按照定义,机器学习可以被定义为从数据集中学习最佳和最相关的模式、关系或关联的复杂过程,这些可以用来预测未知数据的结果。广义上讲,存在三种不同的机器学习过程:
1. 监督学习 是在一个带有标签的数据集上训练机器学习模型的过程,即目标变量已知的数据集。在这种技术中,模型旨在找到自变量和因变量之间的关系。监督学习的例子包括分类、回归和预测。
2. 无监督学习 是在一个目标变量未知的数据集上训练机器学习模型的过程。在这种技术中,模型旨在找到数据中最相关的模式或数据段。无监督学习的例子包括聚类、分割、降维等。
3. 半监督学习 是监督学习和无监督学习过程的结合,其中未标记的数据也用于训练模型。在这种方法中,利用无监督学习的特性来学习数据的最佳表示,利用监督学习的特性来学习表示中的关系,然后用于进行预测。
在这个内核中,我解释了如何使用半监督学习方法进行分类任务。这种方法利用自动编码器来学习数据的表示,然后训练一个简单的线性分类器将数据集分类到相应的类别中。
使用半监督学习进行欺诈检测
我使用了信用卡欺诈检测数据集,该数据集由ULB机器学习组提供。之后,我还将同样的技术应用于Titanic数据集。许多Kagglers分享了不同的方法,如数据集平衡、异常检测、提升模型、深度学习等,但这种方法是不同的。
信用卡欺诈检测数据链接:https://www.kaggle.com/mlg-ulb/creditcardfraud
Titanic幸存者数据链接:https://www.kaggle.com/c/titanic
内容
- 数据集准备
- 可视化欺诈交易与非欺诈交易
- 自动编码器:提取潜在表示
- 获取潜在表示
- 可视化潜在表示:欺诈 vs 非欺诈
- 简单线性分类器
- 在Titanic数据集上应用相同的技术
1. 数据集准备
首先,我们将加载所有所需的库,并使用pandas dataframe加载数据集。
# 导入所需的库
from keras.layers import Input, Dense
from keras.models import Model, Sequential
from keras import regularizers
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score
from sklearn.manifold import TSNE
from sklearn import preprocessing
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
sns.set(style="whitegrid")
np.random.seed(203)# 读取数据集
data = pd.read_csv("../input/creditcardfraud/creditcard.csv")# 将时间转换为小时,并取余24,得到一天中的小时数
data["Time"] = data["Time"].apply(lambda x : x / 3600 % 24)# 显示数据集的前几行
data.head()
数据集包含28个匿名变量,1个“amount”变量,1个“time”变量和1个目标变量 - Class。让我们来看一下目标的分布。
# 统计每个类别的样本数量
vc = data['Class'].value_counts().to_frame().reset_index()# 计算每个类别样本数量占总样本数量的百分比
vc['percent'] = vc["Class"].apply(lambda x : round(100*float(x) / len(data), 2))# 重命名列名
vc = vc.rename(columns = {"index" : "Target", "Class" : "Count"})# 返回结果
vc
只考虑1000行非欺诈案例
# 从数据中选择非欺诈交易样本
non_fraud = data[data['Class'] == 0].sample(1000)# 从数据中选择欺诈交易样本
fraud = data[data['Class'] == 1]# 将非欺诈交易样本和欺诈交易样本合并,并打乱顺序
df = non_fraud.append(fraud).sample(frac=1).reset_index(drop=True)# 从合并后的数据中提取特征变量X,去除目标变量'Class'
X = df.drop(['Class'], axis=1).values# 从合并后的数据中提取目标变量Y
Y = df["Class"].values
2. 可视化欺诈和非欺诈交易
让我们使用T-SNE来可视化欺诈和非欺诈交易的性质。T-SNE(t-分布随机邻居嵌入)是一种数据集分解技术,它减少了数据的维度,并仅生成具有最大信息的前n个组件。
以下每个点代表一笔交易。非欺诈交易以绿色表示,而欺诈交易以红色表示。两个轴是由tsne提取的组件。
# 导入必要的库
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE# 定义函数 tsne_plot,用于绘制 t-SNE 图
def tsne_plot(x1, y1, name="graph.png"):# 创建一个 t-SNE 对象tsne = TSNE(n_components=2, random_state=0)# 对输入数据进行降维处理X_t = tsne.fit_transform(x1)# 创建一个图像窗口plt.figure(figsize=(12, 8))# 绘制非欺诈样本的散点图plt.scatter(X_t[np.where(y1 == 0), 0], X_t[np.where(y1 == 0), 1], marker='o', color='g', linewidth='1', alpha=0.8, label='Non Fraud')# 绘制欺诈样本的散点图plt.scatter(X_t[np.where(y1 == 1), 0], X_t[np.where(y1 == 1), 1], marker='o', color='r', linewidth='1', alpha=0.8, label='Fraud')# 添加图例,位置为最佳位置plt.legend(loc='best')# 保存图像plt.savefig(name)# 显示图像plt.show()# 调用函数 tsne_plot,传入参数 X, Y 和图像名称 "original.png"
tsne_plot(X, Y, "original.png")
3. AutoEncoder自动编码器来拯救
什么是自动编码器AutoEncoder - 自动编码器是一种特殊类型的神经网络架构,其输出与输入相同。自动编码器以无监督的方式进行训练,以学习输入数据的极低级别表示。然后,这些低级特征被变形回来以投影实际数据。自动编码器是一个回归任务,网络被要求预测其输入(换句话说,模拟身份函数)。这些网络在中间有少量神经元的紧密瓶颈,迫使它们创建有效的表示,将输入压缩成低维代码,可以由解码器用于再现原始输入。
关于自动编码器的更多信息 - 如果您想更多了解自动编码器,可以参考以下内核:https://www.kaggle.com/shivamb/how-autoencoders-work-intro-and-usecases
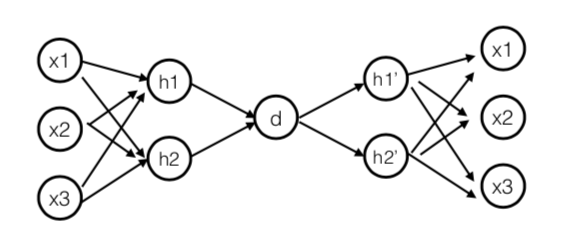
我们将创建一个自动编码器模型,其中只显示模型的非欺诈案例。模型将尝试学习非欺诈案例的最佳表示。同样的模型将用于生成欺诈案例的表示,并且我们期望它们与非欺诈案例不同。
创建一个具有一个输入层和一个输出层的网络,其维度相同,即非欺诈案例的形状。我们将使用keras包。
## 输入层
input_layer = Input(shape=(X.shape[1],)) # 创建一个输入层,形状为X的列数## 编码部分
encoded = Dense(100, activation='tanh', activity_regularizer=regularizers.l1(10e-5))(input_layer) # 创建一个具有100个神经元的全连接层,激活函数为tanh,使用L1正则化
encoded = Dense(50, activation='relu')(encoded) # 创建一个具有50个神经元的全连接层,激活函数为relu## 解码部分
decoded = Dense(50, activation='tanh')(encoded) # 创建一个具有50个神经元的全连接层,激活函数为tanh
decoded = Dense(100, activation='tanh')(decoded) # 创建一个具有100个神经元的全连接层,激活函数为tanh## 输出层
output_layer = Dense(X.shape[1], activation='relu')(decoded) # 创建一个具有X列数个神经元的全连接层,激活函数为relu
创建模型架构,通过编译输入层和输出层。还要添加优化器和损失函数,我使用"adadelta"作为优化器,"mse"作为损失函数。
# 创建一个自编码器模型
autoencoder = Model(input_layer, output_layer)# 使用adadelta优化器和均方误差损失函数编译自编码器模型
autoencoder.compile(optimizer="adadelta", loss="mse")
在训练之前,让我们进行最小最大缩放。
# 从数据中删除"Class"列,得到特征数据x
x = data.drop(["Class"], axis=1)# 获取目标变量"Class"的值,存储在y中
y = data["Class"].values# 使用MinMaxScaler对特征数据x进行归一化处理
scaler = preprocessing.MinMaxScaler()
x_scale = scaler.fit_transform(x.values)# 将归一化后的特征数据分为正常样本和欺诈样本
x_norm = x_scale[y == 0] # 正常样本
x_fraud = x_scale[y == 1] # 欺诈样本
这种方法的优点在于我们不需要太多的数据样本来学习好的表示。我们将使用仅2000行的非欺诈案例来训练自编码器。此外,我们不需要运行这个模型很多个时期。
解释: 从原始数据集中选择小样本的选择是基于这样的直觉,即一个类别的特征(非欺诈)将与另一个类别(欺诈)不同。为了区分这些特征,我们需要向自编码器展示只有一个类别的数据。这是因为自编码器将尝试只学习一个类别,并自动区分另一个类别。
# 使用前2000个样本进行训练和验证
autoencoder.fit(x_norm[0:2000], x_norm[0:2000], batch_size=256, epochs=10, shuffle=True, validation_split=0.20)# 在训练过程中,每次从训练集中随机选择256个样本进行训练,共进行10个epoch的训练
# shuffle参数设置为True,表示每个epoch之前都会将训练集打乱顺序
# validation_split参数设置为0.20,表示将训练集的20%作为验证集,用于评估模型的性能
4. 获取潜在表示
现在,模型已经训练完成。我们对于获取模型学习到的输入的潜在表示非常感兴趣。这可以通过训练模型的权重来访问。我们将创建另一个包含顺序层的网络,并且只添加训练好的权重,直到存在潜在表示的第三层为止。
# 创建一个新的Sequential模型对象hidden_representation
hidden_representation = Sequential()# 将autoencoder模型的第一个层添加到hidden_representation中
hidden_representation.add(autoencoder.layers[0])# 将autoencoder模型的第二个层添加到hidden_representation中
hidden_representation.add(autoencoder.layers[1])# 将autoencoder模型的第三个层添加到hidden_representation中
hidden_representation.add(autoencoder.layers[2])
生成两个类别的隐藏表示:非欺诈和欺诈,通过使用上述模型预测原始输入。
# 使用预训练的模型对正常数据进行隐藏表示的预测
norm_hid_rep = hidden_representation.predict(x_norm[:3000])# 使用预训练的模型对欺诈数据进行隐藏表示的预测
fraud_hid_rep = hidden_representation.predict(x_fraud)
5. 可视化潜在表示:欺诈 vs 非欺诈
现在,我们将使用获得的潜在表示创建一个训练数据集,并可视化欺诈与非欺诈案例的性质。
# 将正常隐藏表示和欺诈隐藏表示按垂直方向拼接起来
rep_x = np.append(norm_hid_rep, fraud_hid_rep, axis=0)# 创建一个与正常隐藏表示的行数相同的全零数组
y_n = np.zeros(norm_hid_rep.shape[0])# 创建一个与欺诈隐藏表示的行数相同的全一数组
y_f = np.ones(fraud_hid_rep.shape[0])# 将正常隐藏表示的标签和欺诈隐藏表示的标签按垂直方向拼接起来
rep_y = np.append(y_n, y_f)# 使用t-SNE算法对隐藏表示进行降维,并绘制散点图
def tsne_plot(rep_x, rep_y, output_file):# 使用t-SNE算法对隐藏表示进行降维,降至2维tsne = TSNE(n_components=2, random_state=0)rep_x_tsne = tsne.fit_transform(rep_x)# 创建一个新的图形窗口plt.figure(figsize=(10, 8))# 绘制正常隐藏表示的散点图plt.scatter(rep_x_tsne[rep_y == 0, 0], rep_x_tsne[rep_y == 0, 1], color='b', label='Normal')# 绘制欺诈隐藏表示的散点图plt.scatter(rep_x_tsne[rep_y == 1, 0], rep_x_tsne[rep_y == 1, 1], color='r', label='Fraud')# 添加图例plt.legend()# 设置图形标题plt.title('Latent Representation')# 保存图形为指定文件名的图片plt.savefig(output_file)# 调用函数进行绘图,并保存为"latent_representation.png"
tsne_plot(rep_x, rep_y, "latent_representation.png")
什么一个完美的图表,我们可以观察到现在欺诈和非欺诈交易非常明显,并且可以线性分离。现在我们不需要任何复杂的模型来分类,甚至简单的模型也可以用来预测。以下是欺诈和非欺诈交易的前后对比视图。
# 导入所需的模块
from IPython.display import display, Image, HTML# 使用HTML模块中的display函数,将HTML代码显示在Jupyter Notebook中
display(HTML("""<table align="center">
<tr ><td><b>Actual Representation (Before) </b></td><td><b>Latent Representation (Actual)</b></td></tr>
<tr><td><img src='original.png'></td><td><img src='latent_representation.png'></td></tr></table>"""))
现在,我们可以在数据集上训练一个简单的线性分类器。
6. 简单线性分类器
# 导入所需的库
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score# 将数据集划分为训练集和验证集
train_x, val_x, train_y, val_y = train_test_split(rep_x, rep_y, test_size=0.25)# 创建逻辑回归分类器对象,并使用训练集进行训练
clf = LogisticRegression(solver="lbfgs").fit(train_x, train_y)# 使用训练好的分类器对验证集进行预测
pred_y = clf.predict(val_x)# 输出分类报告
print ("")
print ("Classification Report: ")
print (classification_report(val_y, pred_y))# 输出准确率
print ("")
print ("Accuracy Score: ", accuracy_score(val_y, pred_y))
7. 应用到不同的数据集:泰坦尼克号
让我们将这种方法应用到另一个数据集上。我将使用流行的泰坦尼克号数据集来进行这个目的。
# 从指定路径读取训练数据集train.csv,并将其存储在train变量中
train = pd.read_csv("../input/titanic/train.csv")# 从指定路径读取测试数据集test.csv,并将其存储在test变量中
test = pd.read_csv("../input/titanic/test.csv")
特征工程:
import re # 导入re模块,用于正则表达式操作full_data = [train, test] # 将train和test数据集放入full_data列表中train['Name_length'] = train['Name'].apply(len) # 计算训练集中乘客姓名的长度,并将结果存储在新的列Name_length中
test['Name_length'] = test['Name'].apply(len) # 计算测试集中乘客姓名的长度,并将结果存储在新的列Name_length中train['Has_Cabin'] = train["Cabin"].apply(lambda x: 0 if type(x) == float else 1) # 判断训练集中是否有船舱信息,有则在新的列Has_Cabin中标记为1,没有则标记为0
test['Has_Cabin'] = test["Cabin"].apply(lambda x: 0 if type(x) == float else 1) # 判断测试集中是否有船舱信息,有则在新的列Has_Cabin中标记为1,没有则标记为0for dataset in full_data: # 遍历full_data列表中的数据集dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1 # 计算家庭成员数量,并将结果存储在新的列FamilySize中for dataset in full_data: # 遍历full_data列表中的数据集dataset['IsAlone'] = 0 # 初始化IsAlone列为0dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1 # 如果FamilySize列的值为1,则将IsAlone列的值设为1for dataset in full_data: # 遍历full_data列表中的数据集dataset['Embarked'] = dataset['Embarked'].fillna('S') # 将Embarked列中的缺失值填充为'S'for dataset in full_data: # 遍历full_data列表中的数据集dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median()) # 将Fare列中的缺失值填充为训练集中Fare列的中位数
train['CategoricalFare'] = pd.qcut(train['Fare'], 4) # 将训练集中的Fare列分为4个区间,并将结果存储在新的列CategoricalFare中for dataset in full_data: # 遍历full_data列表中的数据集age_avg = dataset['Age'].mean() # 计算年龄的平均值age_std = dataset['Age'].std() # 计算年龄的标准差age_null_count = dataset['Age'].isnull().sum() # 统计年龄列中的缺失值数量age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count) # 生成随机数列表,用于填充年龄列中的缺失值dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list # 将年龄列中的缺失值用随机数列表中的值进行填充dataset['Age'] = dataset['Age'].astype(int) # 将年龄列的数据类型转换为整型train['CategoricalAge'] = pd.cut(train['Age'], 5) # 将训练集中的Age列分为5个区间,并将结果存储在新的列CategoricalAge中def get_title(name): # 定义一个函数,用于从姓名中提取称号title_search = re.search(' ([A-Za-z]+)\.', name) # 使用正则表达式从姓名中匹配出称号if title_search:return title_search.group(1) # 返回匹配到的称号return "" # 如果没有匹配到称号,则返回空字符串for dataset in full_data: # 遍历full_data列表中的数据集dataset['Title'] = dataset['Name'].apply(get_title) # 从姓名中提取称号,并将结果存储在新的列Title中for dataset in full_data: # 遍历full_data列表中的数据集dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare') # 将Title列中的特殊称号替换为'Rare'dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss') # 将Title列中的'Mlle'替换为'Miss'dataset['Title'] = dataset['Title'].replace('Ms', 'Miss') # 将Title列中的'Ms'替换为'Miss'dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs') # 将Title列中的'Mme'替换为'Mrs'for dataset in full_data: # 遍历full_data列表中的数据集dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int) # 将Sex列中的'female'映射为0,'male'映射为1,并将结果转换为整型数据类型title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5} # 定义一个字典,用于将Title列中的称号映射为数字dataset['Title'] = dataset['Title'].map(title_mapping) # 将Title列中的称号映射为数字dataset['Title'] = dataset['Title'].fillna(0) # 将Title列中的缺失值填充为0dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int) # 将Embarked列中的'S'映射为0,'C'映射为1,'Q'映射为2,并将结果转换为整型数据类型dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0 # 将Fare列中小于等于7.91的值设为0dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1 # 将Fare列中大于7.91且小于等于14.454的值设为1dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2 # 将Fare列中大于14.454且小于等于31的值设为2dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3 # 将Fare列中大于31的值设为3dataset['Fare'] = dataset['Fare'].astype(int) # 将Fare列的数据类型转换为整型dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0 # 将Age列中小于等于16的值设为0dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1 # 将Age列中大于16且小于等于32的值设为1dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2 # 将Age列中大于32且小于等于48的值设为2dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3 # 将Age列中大于48且小于等于64的值设为3dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 # 将Age列中大于64的值设为4drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp'] # 定义一个列表,包含需要删除的列名
train = train.drop(drop_elements, axis = 1) # 在训练集中删除指定的列
train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1) # 在训练集中删除CategoricalAge和CategoricalFare列
test = test.drop(drop_elements, axis = 1) # 在测试集中删除指定的列
下一步,定义自编码器模型
# 将目标变量和特征变量分开
X = train.drop(["Survived"], axis=1)
y = train["Survived"]
y = y.values# 定义模型
# 输入层
input_layer = Input(shape=(X.shape[1],))
# 编码层
encoded = Dense(100, activation='tanh', activity_regularizer=regularizers.l1(10e-5))(input_layer)
encoded = Dense(50, activation='relu')(encoded)
# 解码层
decoded = Dense(50, activation='tanh')(encoded)
decoded = Dense(100, activation='tanh')(decoded)
# 输出层
output_layer = Dense(X.shape[1], activation='relu')(decoded)# 构建自编码器模型
autoencoder = Model(input_layer, output_layer)
# 编译模型
autoencoder.compile(optimizer="adadelta", loss="mse")
训练模型
# 创建一个MinMaxScaler对象,用于将特征值缩放到指定的范围
scaler = preprocessing.MinMaxScaler()# 使用训练数据X来拟合(计算)缩放器的参数
scaler.fit(X.values)# 使用拟合好的缩放器对训练数据X进行缩放处理
X_scale = scaler.transform(X.values)# 使用拟合好的缩放器对测试数据test进行缩放处理
test_x_scale = scaler.transform(test.values)# 将训练数据X_scale按照标签y的值分为两个子集:y为0的样本和y为1的样本
x_perished, x_survived = X_scale[y == 0], X_scale[y == 1]# 使用x_perished作为输入和输出训练模型,进行20轮的训练,打乱样本顺序,同时使用25%的数据作为验证集
autoencoder.fit(x_perished, x_perished, epochs=20, shuffle=True, validation_split=0.25)
获取隐藏表示
# 创建一个新的Sequential模型对象hidden_representation
hidden_representation = Sequential()# 向hidden_representation模型中添加autoencoder模型的第一个层
hidden_representation.add(autoencoder.layers[0])# 向hidden_representation模型中添加autoencoder模型的第二个层
hidden_representation.add(autoencoder.layers[1])# 向hidden_representation模型中添加autoencoder模型的第三个层
hidden_representation.add(autoencoder.layers[2])
# 使用hidden_representation模型对x_perished进行预测,得到perished_hid_rep
perished_hid_rep = hidden_representation.predict(x_perished)# 使用hidden_representation模型对x_survived进行预测,得到survived_hid_rep
survived_hid_rep = hidden_representation.predict(x_survived)# 将perished_hid_rep和survived_hid_rep按照列方向进行拼接,得到rep_x
rep_x = np.append(perished_hid_rep, survived_hid_rep, axis=0)# 创建一个形状与perished_hid_rep相同的全零数组,作为标签y_n
y_n = np.zeros(perished_hid_rep.shape[0])# 创建一个形状与survived_hid_rep相同的全一数组,作为标签y_f
y_f = np.ones(survived_hid_rep.shape[0])# 将y_n和y_f按照行方向进行拼接,得到rep_y
rep_y = np.append(y_n, y_f)
训练分类器
# 将语料分为训练集和验证集,其中验证集占总语料的25%
train_x, val_x, train_y, val_y = train_test_split(rep_x, rep_y, test_size=0.25)# 使用逻辑回归模型进行训练
clf = LogisticRegression().fit(train_x, train_y)# 使用训练好的模型对验证集进行预测
pred_y = clf.predict(val_x)# 输出分类报告,包括精确率、召回率、F1值等指标
print(classification_report(val_y, pred_y))# 输出准确率
print(accuracy_score(val_y, pred_y))
# 读取测试数据集的PassengerId列,并创建一个DataFrame对象
temp = pd.DataFrame(pd.read_csv("../input/titanic/test.csv")['PassengerId'])# 使用hidden_representation模型对测试数据集进行预测
test_rep_x = hidden_representation.predict(test_x_scale)# 使用clf模型对预测结果进行分类,并将结果转换为整数类型
temp['Survived'] = [int(x) for x in clf.predict(test_rep_x)]# 将结果保存为submission.csv文件,不包含索引列
temp.to_csv("submission.csv", index = False)# 显示temp的前几行数据
temp.head()
因此,我们可以看到这种方法给出了不错的结果。随着更多的数据,可以肯定地期望有所改进。
这篇关于案例系列:银行信用卡欺诈_预测是否欺诈_ 自编码器AutoEncoder二分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




