本文主要是介绍日志平台--graylog-web配置、接入微服务日志,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
第一章 搭建es集群
第二章 mongodb搭建
第三章 graylog搭建与反向代理
文章目录
- 系列文章目录
- 前言
- 一、graylog-web界面操作
- 二、分流操作
- 三、分流示例
- 四、graylog查看某个服务的日志
- 五、graylog创建不同用户的流程及权限分类
- 总结
前言
通过第三章内容,已成功搭建完成graylog,并且使用nginx实现了反向代理。因此在本章中,主要是针对graylog-web界面的熟悉、配置、微服务日志接入为目标,展开详细说明。
一、graylog-web界面操作
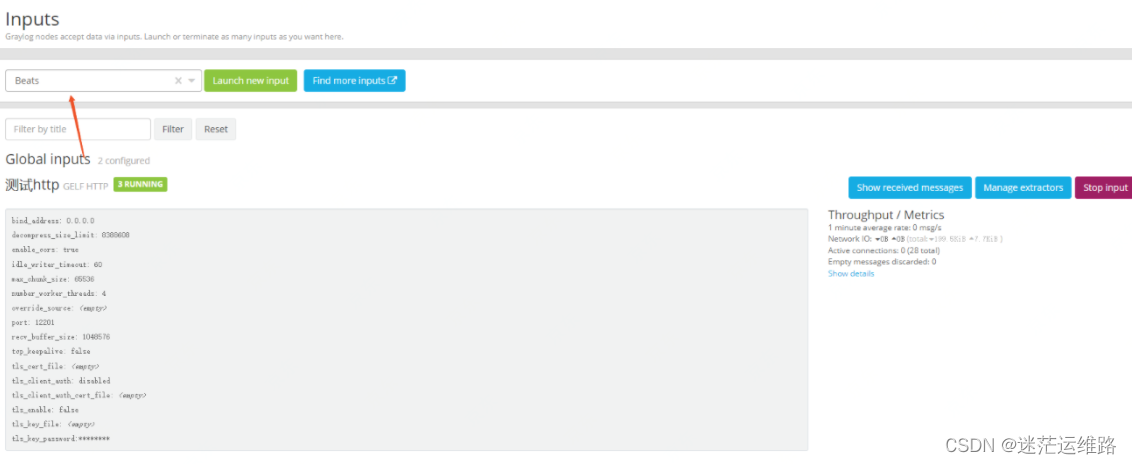
1、配置graylog首先在Web管理界面进入System/Inputs,进行如下操作:选择Beats类型,点击 Launch new input。如下图所示接着填入参数,端口根据需要进行修改,然后保存即可:
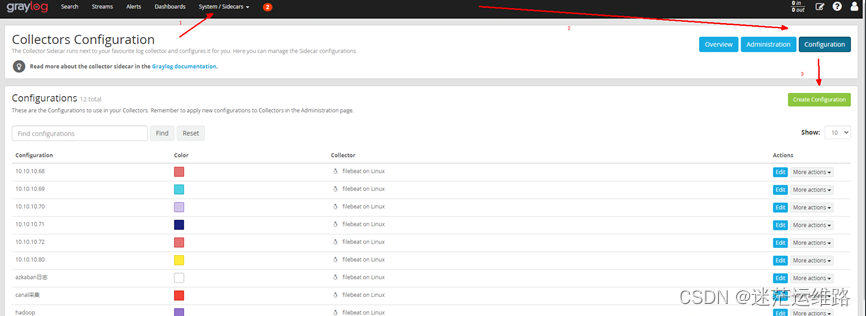
2、页面配置:创建sidecar采集器Web界面进入System/SidecarsCollector根据需要这里选择了:filebeat on Linuxpaths处填写你Nginx服务器上日志所在位置hosts处填写Graylog服务器的IP+端口(上面System/Inputs时候填入的端口):
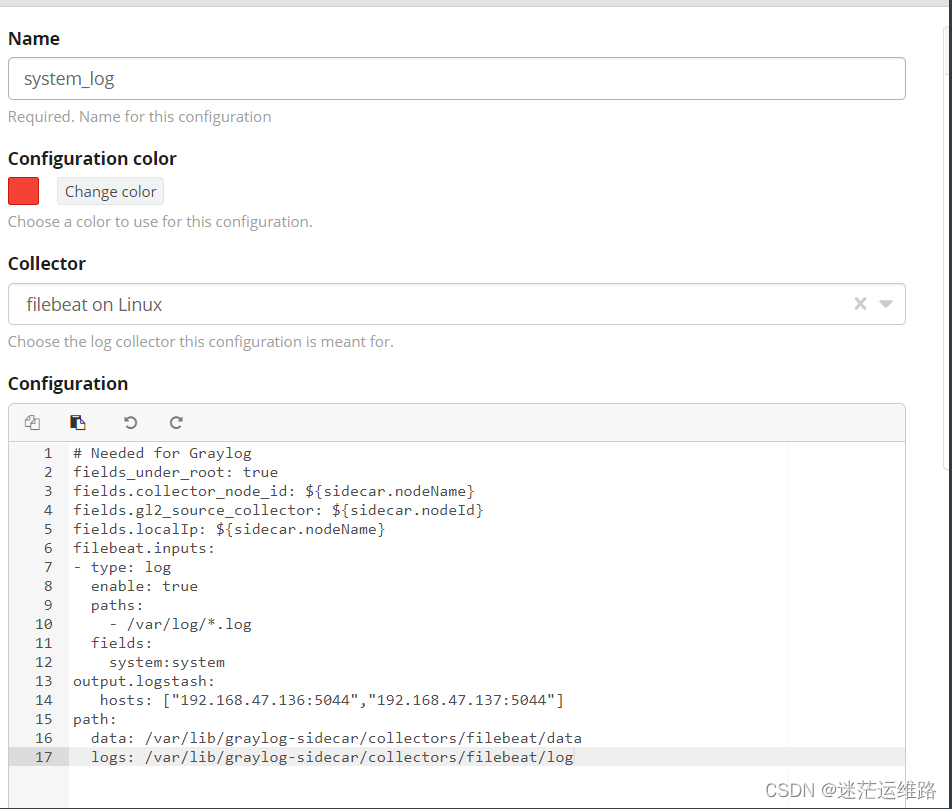
3、详细的configuration配置说明
#该文件适用于日志目录统一的情况fields_under_root: true #自定义字段将直接位于输出文档的最外层,而不是嵌套在 fields 子字典中。fields.collector_node_id: ${sidecar.nodeName} #当 Graylog 集群中有多个 Collector 节点时,这个字段可以用来追踪每个日志事件的来源。fields.gl2_source_collector: ${sidecar.nodeId} #指定消息的来源采集器,其值为 Sidecar 节点 IDfields.localIp: ${sidecar.nodeName} #指定消息的本地 IP 地址,其值为 Sidecar节点名称fields.inputType: agent #指定消息的输入类型,其值为“agent”,表示该消息是来自 Agent 的日志数据。filebeat.registry.flush: 60s #指定 Filebeat 注册表的刷新时间filebeat.shutdown_timeout: 10s #指定 Filebeat 的关闭超时时间max_procs: 2 #指定 Filebeat 的最大进程数,默认值为逻辑 CPU 数量的两倍 该参数用于限制 Filebeat 运行时的并发度,防止系统资源被占用过多filebeat.inputs:- type: logenabled: trueignore_older: 48htail_files: falsepaths:- /export/Logs/*/app_error.log- /export/Logs/*/app_info.log- /export/Logs/*/system_info.log- /export/Logs/*/system_error.log- /export/Logs/*/all.log- /export/Logs/*/error.log- /export/Logs/*/coredns-66bff467f8-k8n9b.log- /export/Logs/*/coredns-66bff467f8-r5598.log- /export/Logs/*/coredns-66bff467f8-sxsnh.logfields: #此处的配置适用于日志城市平台systemCode: Etown #系统codeappId: coupons #应用codemultiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:|^org|^com|^java.|^\,|^###|^;|^For|^feign|^from|^to|^class|^Desired|^par|^concurrent|^eden|^Metaspace'multiline.negate: false #设置为false表示不否定多行模式multiline.match: after #设置为after表示在多行模式下,从当前行的末尾开始匹配multiline.max_lines: 200 #设置允许的最大行数,超过此限制的多行日志将被截断output.logstash:hosts: ["ip:5044","ip:5044"] #此处为graylog地址path:data: /var/lib/graylog-sidecar/collectors/filebeat/datalogs: /var/lib/graylog-sidecar/collectors/filebeat/log
#如遇到相同节点日志目录不统一的情况下则需要根据一下配置进行调整fields_under_root: truefields.collector_node_id: ${sidecar.nodeName}fields.gl2_source_collector: ${sidecar.nodeId}fields.localIp: ${sidecar.nodeName}fields.inputType: agentfilebeat.registry.flush: 60sfilebeat.shutdown_timeout: 10smax_procs: 2filebeat.inputs:- type: logenabled: trueignore_older: 48htail_files: falsepaths:- /export/Logs/xxx/*/app_error.logfields:systemCode: proappId: app_proserviceId: test1multiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:|^org|^com|^java.|^\,|^###|^;|^For|^feign|^from|^to|^class|^Desired|^par|^concurrent|^eden|^Metaspace'multiline.negate: falsemultiline.match: aftermultiline.max_lines: 200- type: logenabled: trueignore_older: 48htail_files: falsepaths:- /export/icity/*/all.logfields:systemCode: proappId: app_proserviceId: test1multiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:|^org|^com|^java.|^\,|^###|^;|^For|^feign|^from|^to|^class|^Desired|^par|^concurrent|^eden|^Metaspace'multiline.negate: falsemultiline.match: aftermultiline.max_lines: 200output.logstash:hosts: ["ip:5044","ip:5044"]path:data: /var/lib/graylog-sidecar/collectors/filebeat/datalogs: /var/lib/graylog-sidecar/collectors/filebeat/log
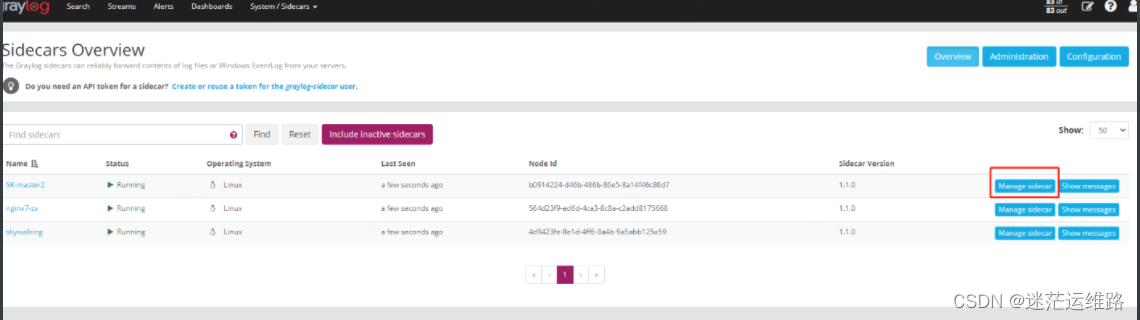
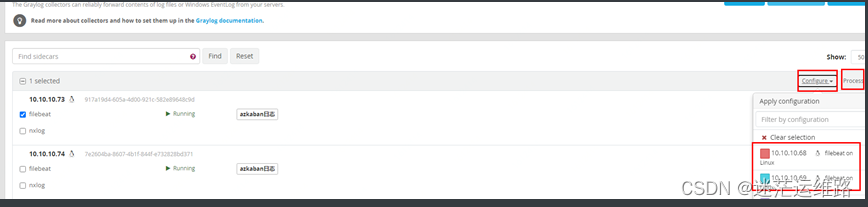
4、管理sidecar并配置日志采集项,与sidecar绑定完成后,等待几秒日志便会采集上来,在界面中可以看到相关日志
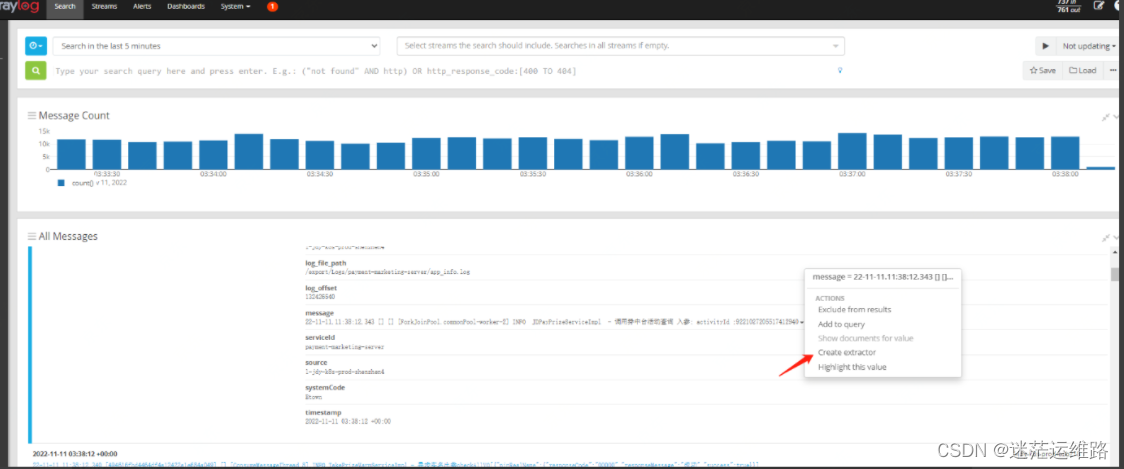
5、提取日志级别和时间戳配置点击其中一条日志,然后右键会出来如箭头所示的文件
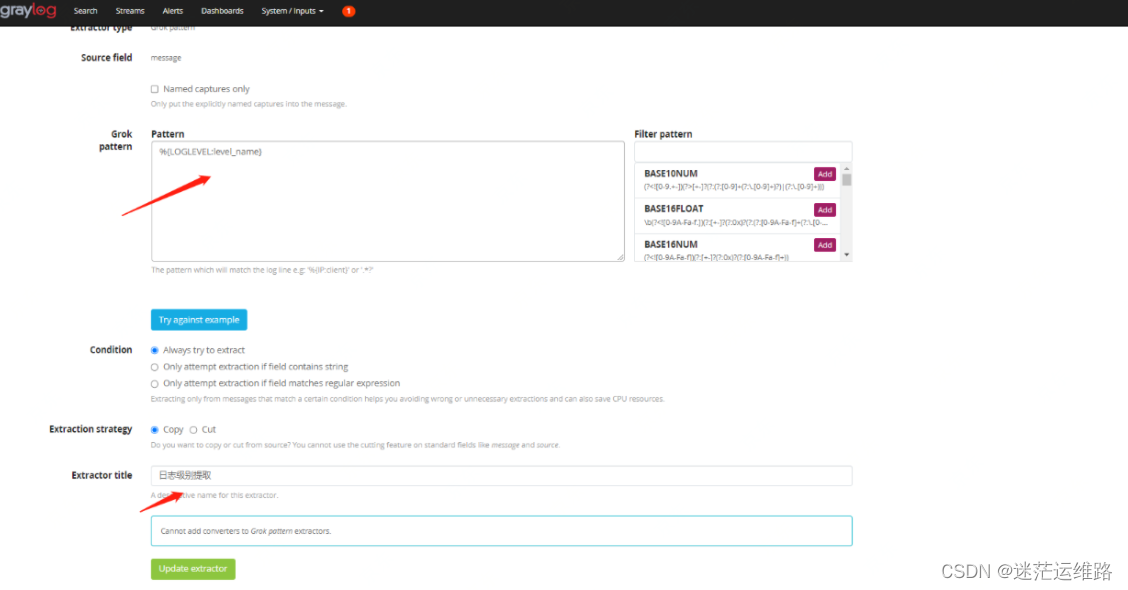
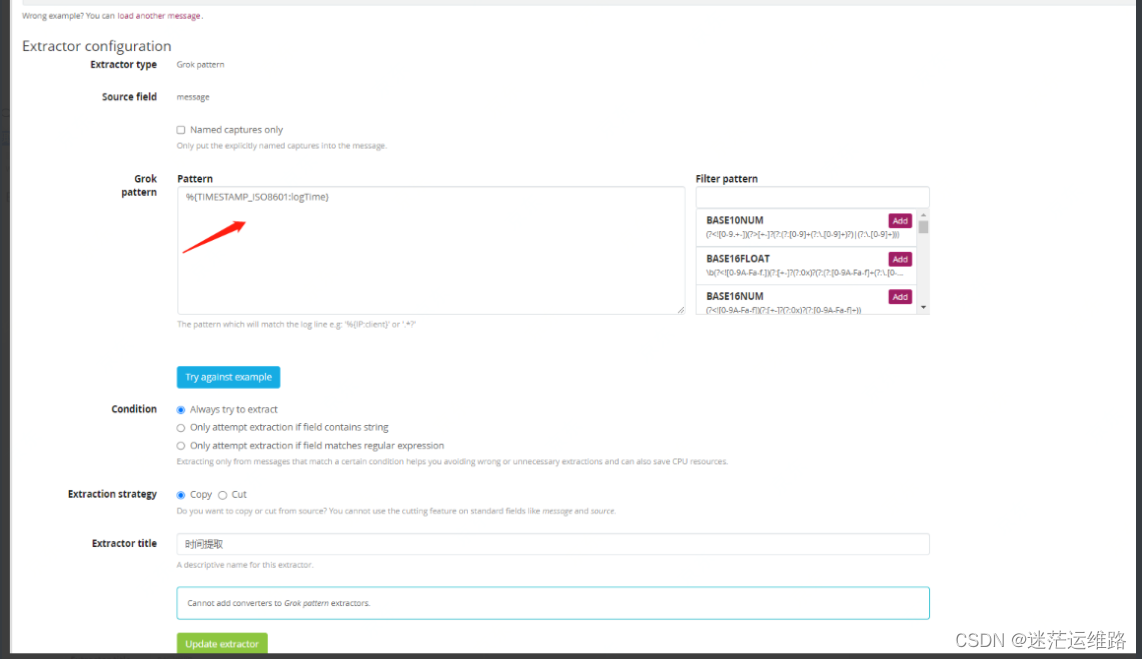
6、配置日志清洗转换脚本
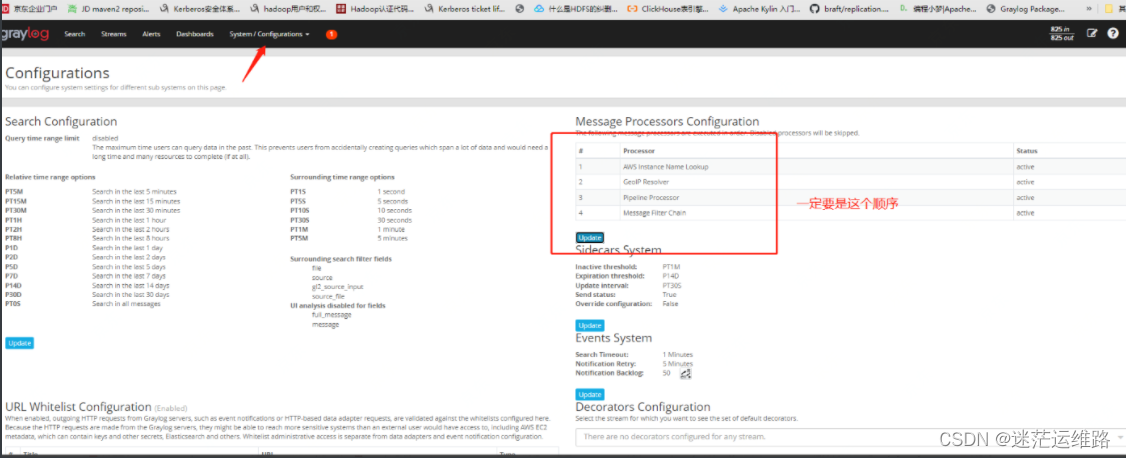
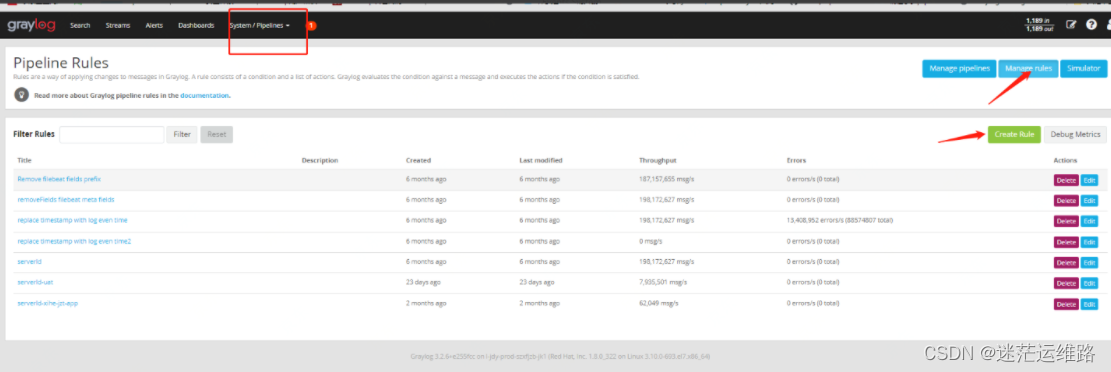
1、上述图片中添加了三个日志处理规则
第一个 serverId
rule "serverId"
whenhas_field("log_file_path")
thenlet pathArray = split("/",to_string($message.log_file_path));set_field("serviceId",to_string(pathArray[3])); 如果是/export/Logs/xx.log 就为3;如果是/export/Logs/xx/xxx.log 就为4
end第二个 Remove filebeat fields prefix(删除filebeat字段前缀)
rule "Remove filebeat fields prefix"
whenhas_field("fields_appId")
thenrename_field("fields_systemCode", "systemCode");rename_field("fields_appId", "appId");rename_field("fields_serviceId", "serviceId");
end第三个 replace timestamp with log even time(将时间戳替换为日志偶数时间)
rule "replace timestamp with log even time"
whenhas_field("logTime")
then
let new_date = parse_date(value: to_string($message.logTime),pattern: "yyyy-MM-dd HH:mm:ss.SSS",timezone: "Asia/Shanghai");set_field("timestamp", new_date);
end
可选的转换脚本如果日志格式是非yyyy-MM-dd HH:mm:ss.SSS格式则需要使用字符串截取等方式提取时间
rule "replace timestamp with log even time"
whenhas_field("timestamp")
then
let eventTime = substring(to_string($message.message), 0, 21);
let new_date = parse_date(value: eventTime,pattern: "yy-MM-dd.HH:mm:ss.SSS",timezone: "Asia/Shanghai");set_field("timestamp", new_date);
end
7、pipelines规则添加
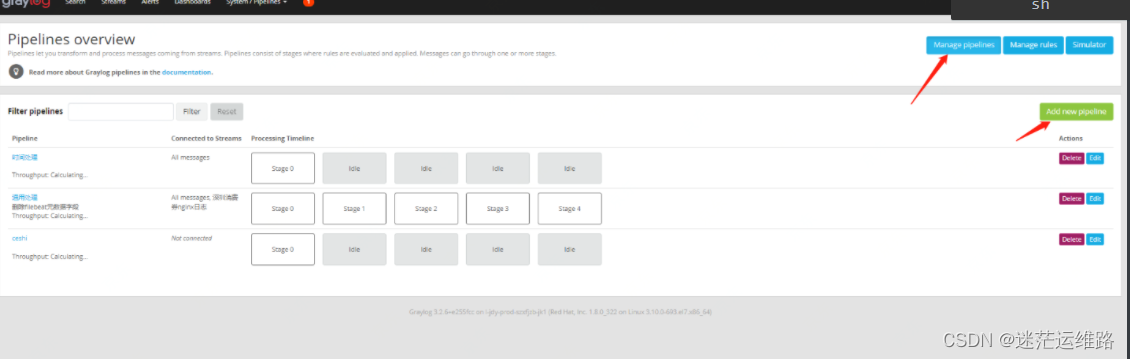
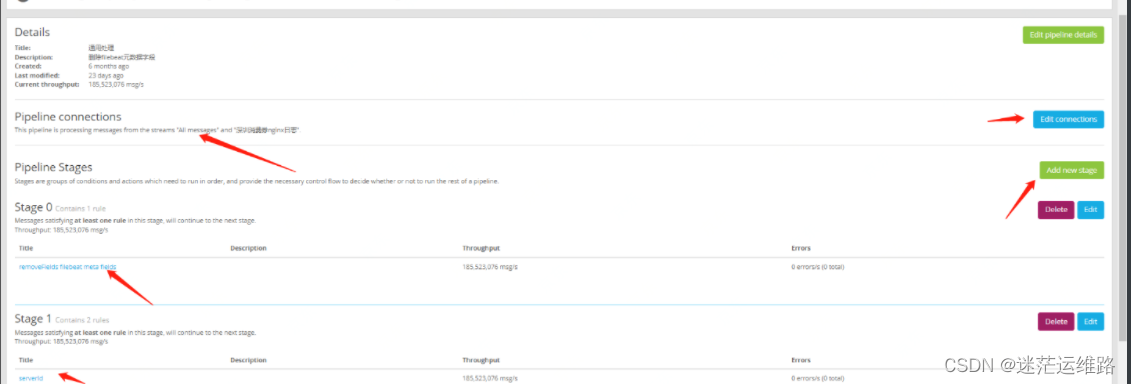
8、至此,所有关键字均已提取完成
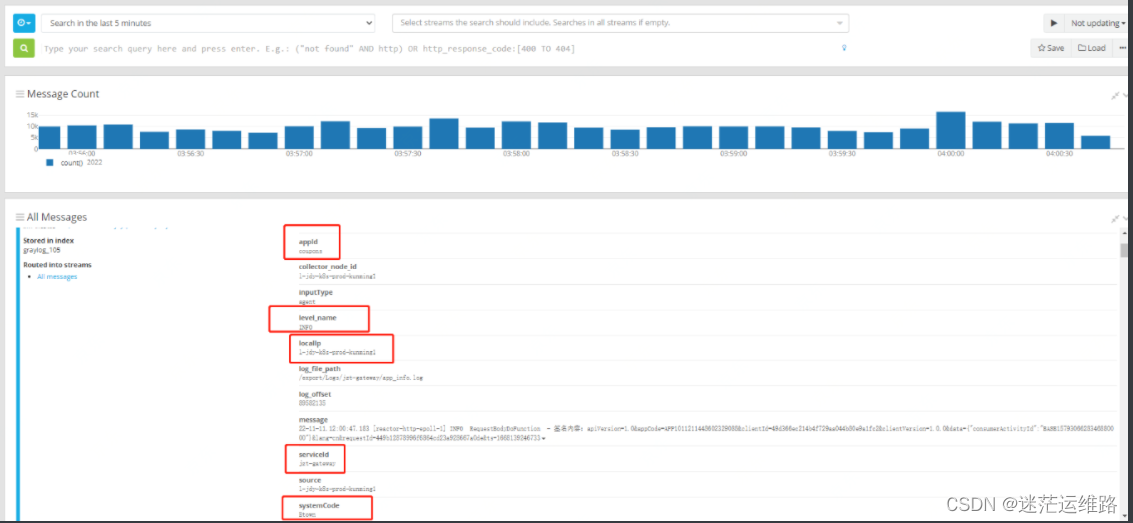
二、分流操作
分流的意思是创建一定的流规则,然后可以根据此规则,将日志分流,例如hbase的日志放到hbase的流中,然后放到hbase的索引中存储起来.因为在实际生产环境中,日志来源并不是单一的,除了应用服务日志外,还有nginx日志、系统日志等.这种时候就会产生重要性的问题,比如,生产环境的nginx访问日志要保存1年。而测试环境的应用服务日志,只需要保存7天就可以了这种不同情况的需求,为了能更好的区分不同类型的日志,我们就可以创建不同的索引,来储存不同类型的日志.比如创建test环境,prod环境的索引来区分环境,创建nginx,web-app等来区分nginx和应用web服务等.
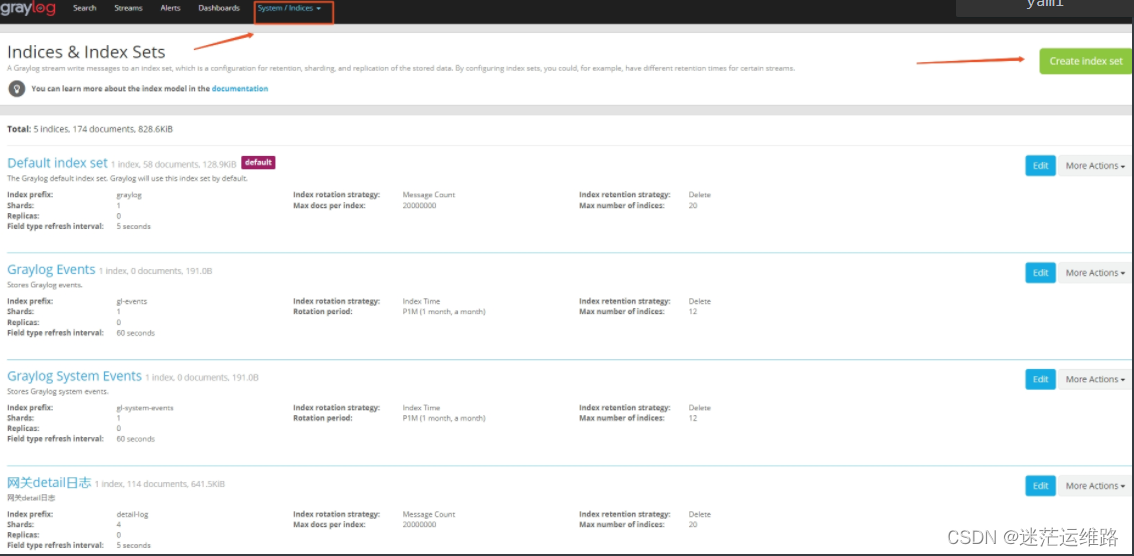
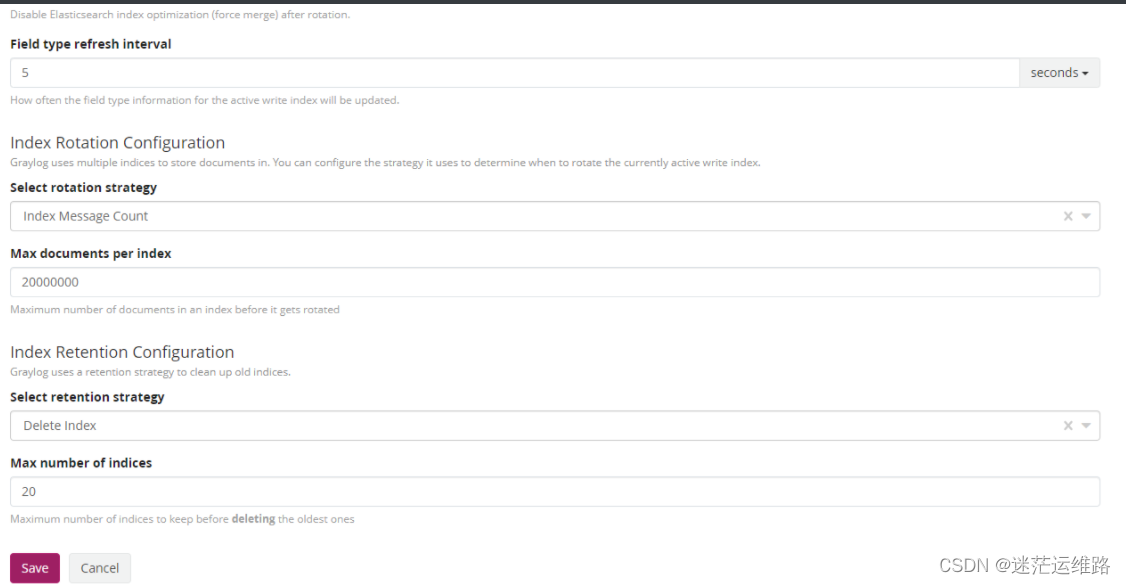
1、创建indices 如下图所示elasticsearch是以索引来存储数据的,启动graylog后,会自动生产一个默认的索引,索引地段值就为graylog,如下图。我们还可以在其中配置数据存储限制,可以通过时间,大小,数量来进行存储限制。2、分流的相关配置参数Title 标题Descriptions 描述index prefix 索引前缀analyzer 分词方法 standardindex shards 分片数量index replicas 副本数Max.number of segments 最大分段数Field type refresh interval 字段刷新时间select rotation strategy 保存策略 时间(Index time)、字节大小(Index size)、信息统计数量(Index Msg Count)Rotation period 如果保存策略是以时间为单位 这里可以写P1~nD(天数)、P1M(一个月)、PT6H(6小时) 根据实际情况修改如果保存策略是以大小为单位 1073741824(1GB)、MB 根据实际情况修改如果保存策略是以数量为单位 默认是20000000个Select retention strategy 选择保留策略删除分片(Delete Index) 关闭分片(close index) 什么也不做(do nothing)Max number of indices如果保留策略是删除分片 ,则设定最大的索引数量,当超过设定的最大索引数量时,会删除旧的索引
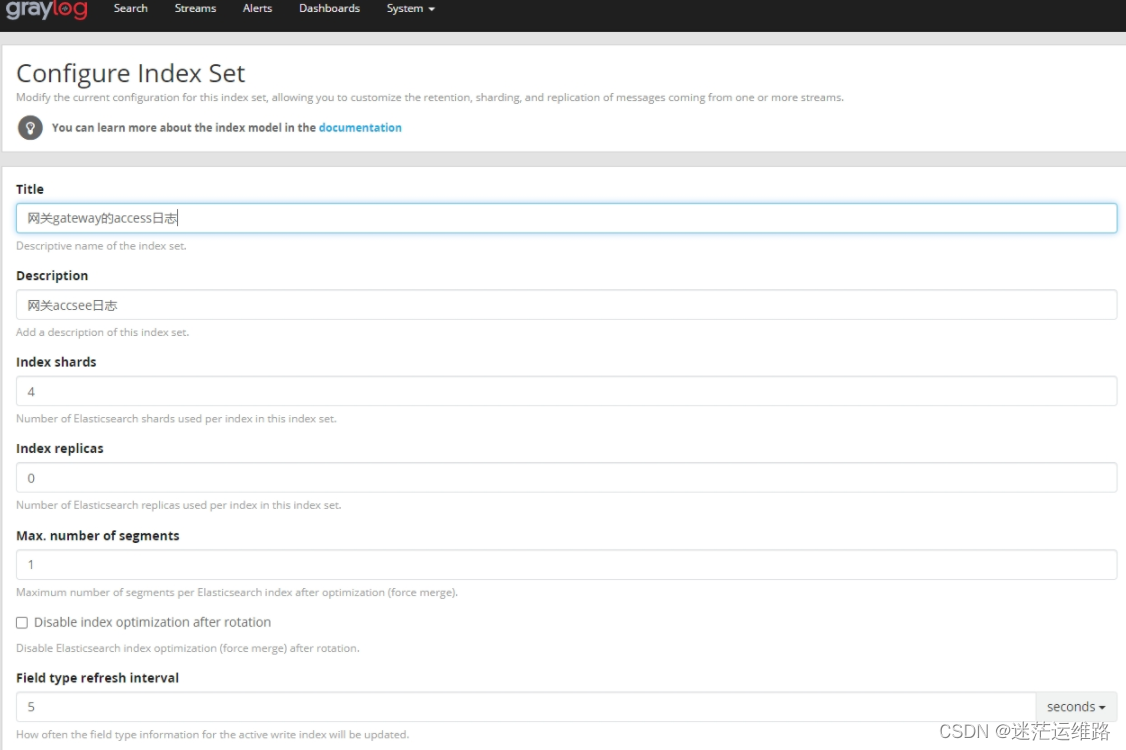
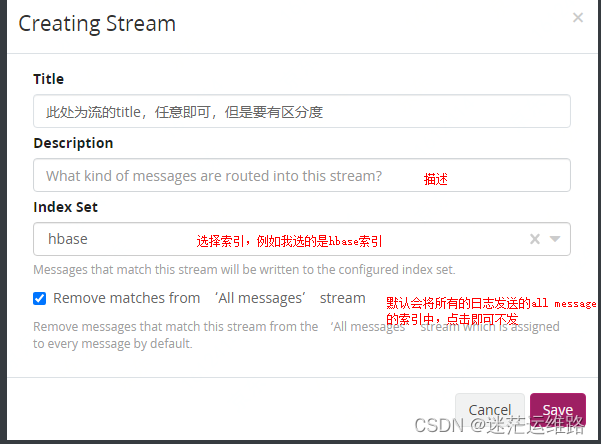
3、点击streams 完成创建流
三、分流示例
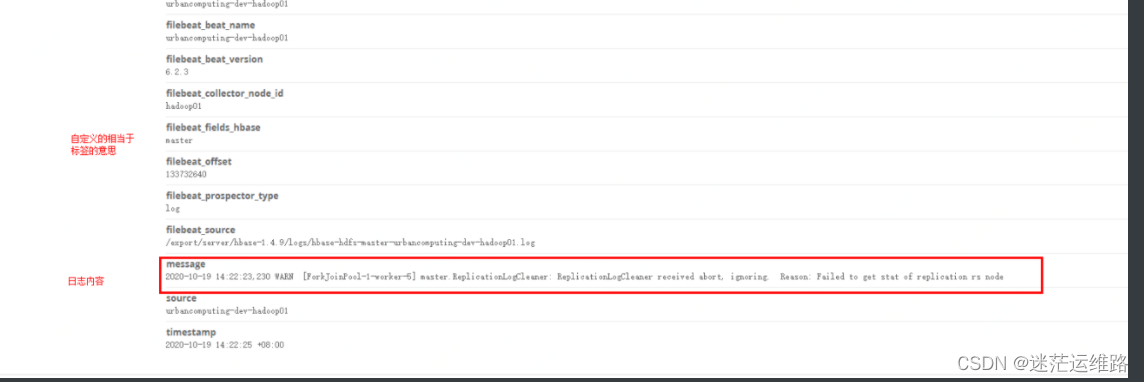
1、查看一条具体的日志内容,如下图所示
2、创建流规则流规则中Type的类型有以下几种:match exactly (精确匹配) 设定的Field字段在日志中必须符合设定的value值match regular expression(匹配正则表达式)contain (包含)greater than(大于)smaller than(小于)field presence(字段存在) 主要就是告诉graylog只要字段设定的字段是存在的,就放入设定字段的这个stream中,方便我们日后查阅。always match (始终匹配)

下面配置的那个key就是上图中的,必须符合value才可以进入到这个流中,进而存到流对应的索引中
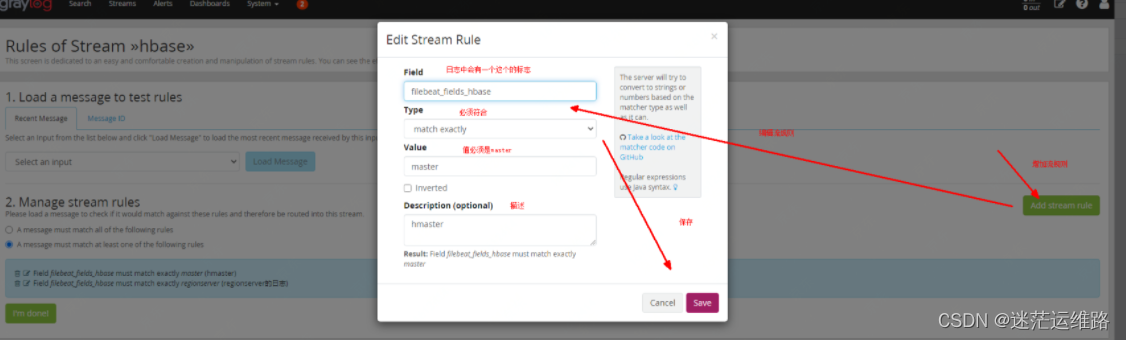
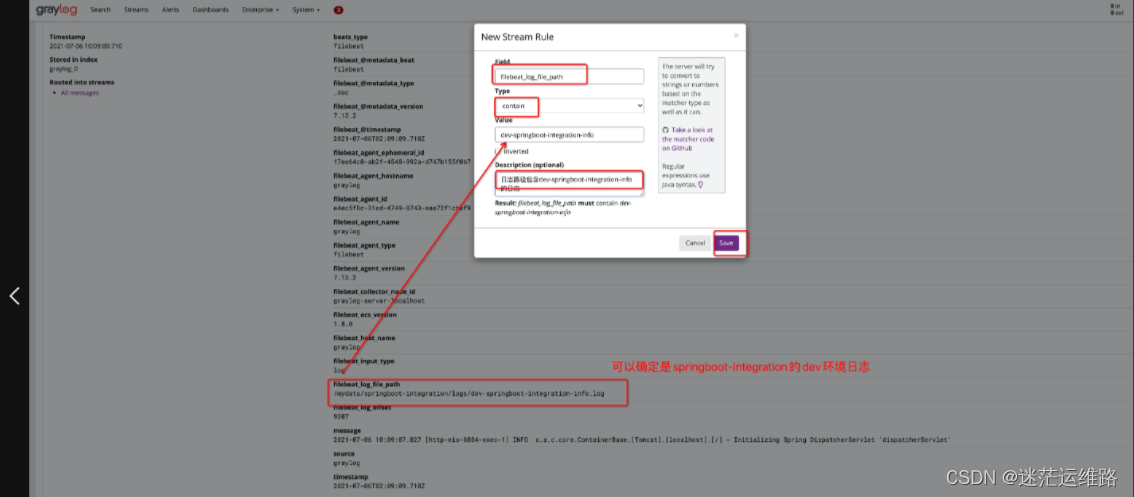
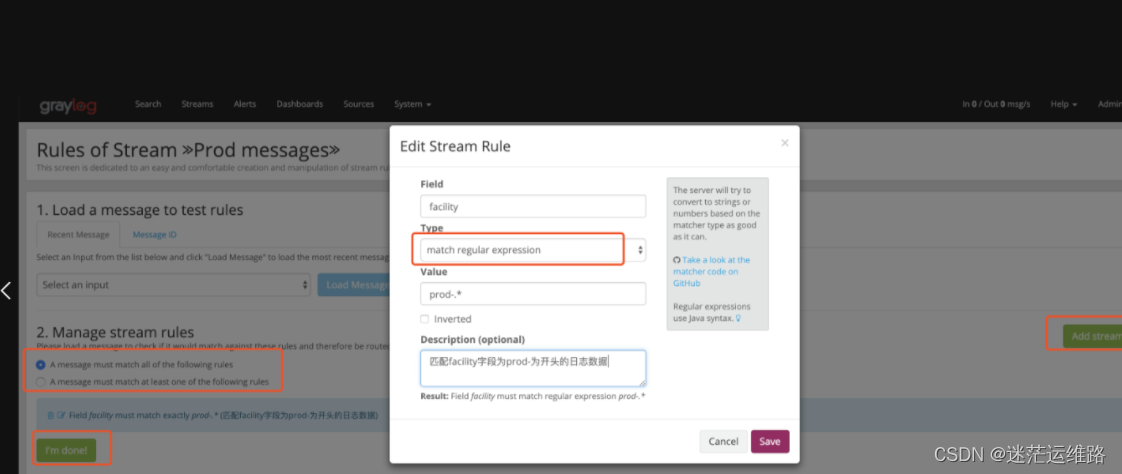
完成规则创建后,点击start即可开启流
四、graylog查看某个服务的日志
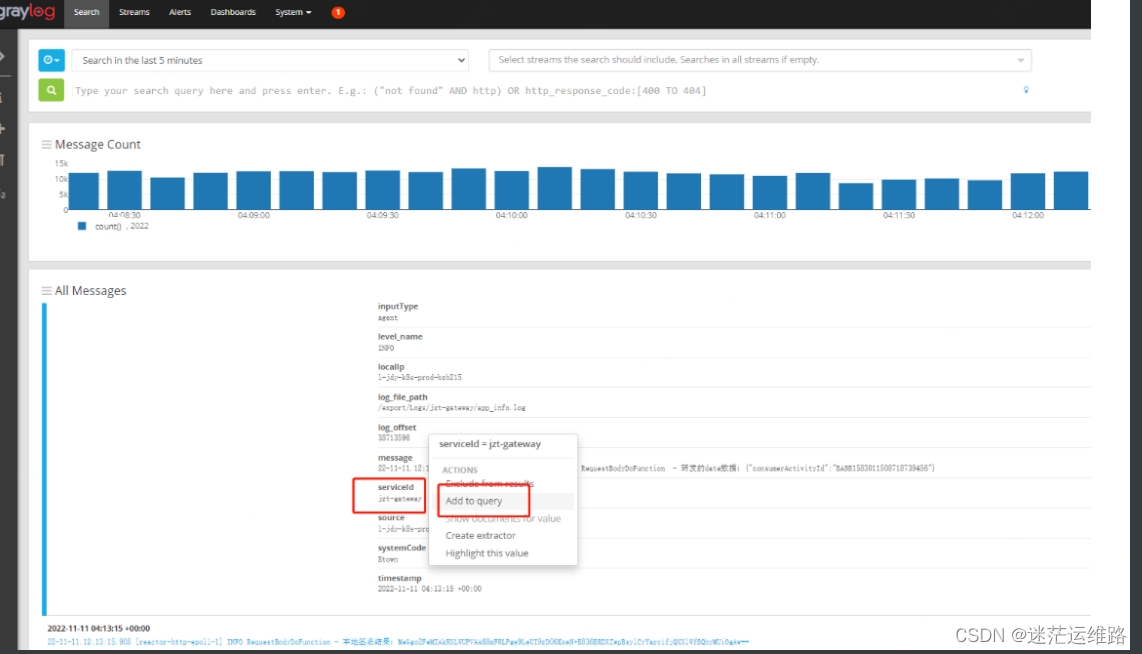
根据创建的serviceId即可查询到
五、graylog创建不同用户的流程及权限分类
1、使用管理员帐户登录到Graylog的Web界面。2、单击顶部菜单栏中的 “System” 选项卡,然后单击左侧侧边栏中的 “Authentication”。3、在 “Authentication” 屏幕上,单击 “Users” 选项卡。4、然后单击右上角的 “Create User” 按钮。5、在弹出的 “Create User” 窗口中,输入要创建的用户名、电子邮件地址和密码。你还可以选择为此用户分配角色,从而控制他们在Graylog中的访问权限。例如,如果你想让他们只能查看特定的流(stream),则可以为其分配 “Reader” 角色,并授予该流的只读权限。6、单击 “Save” 按钮保存新用户。
Admin 所有Manager权限,以及可以管理全局用户、角色和仪表板的权限。Reader 只能查看和搜索自己有访问权限的数据。不能修改任何配置和内容。Sidecar System (Internal) 内部技术角色。授予对Sidecar节点的注册和拉取配置的访问权限(内置)Alerts Manager 允许读取和写入所有事件定义和事件通知Views Manager 允许读取和写入所有视图和扩展搜索
总结
以上就是今天要讲的内容,本文对graylog的界面操作做出了大量的讲解,并配合着graylog中的日志转换规则、清洗脚本等,对原本复杂的日志进行简单化处理,拿到自己想看到的日志字段。
这篇关于日志平台--graylog-web配置、接入微服务日志的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






