本文主要是介绍大数据生态圈面试题(Hadoop、Hive、Spark),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Hadoop 专区
- HDFS 存储小文件问题
- HDFS 的存储机制
- Spark 专区
- 如何解决 Job 运行效率低的问题
- Spark 的数据本地性有哪几种,分别表示什么?
- 如何解决数据倾斜问题
- Hive 专区
- 数据仓库中怎么处理缓慢变化维,有哪几种方式?
- Hive 是什么? 跟数据仓库区别?
- 为什么要使用 Hive? 它的优缺点以及作用是什么?
- Hive 架构
- Hive 运行原理
- 查询建表与 like 建表
- Hive 默认分隔符
- Hive 外部表与内部表的区别
- Hive 删除外部表删除的是什么?如何恢复?
- Hive 中的分区与排序区别
- Hive 分区表的作用是什么,是否越多越好,为什么?
- Hive 中的分桶表
- Hive 数据倾斜以及解决方案
- Hive 的用户自定义函数实现步骤与流程
- 简述对于 UDF/UDAF/UDTF 的理解
- 对数据进行分层作用(数仓的作用)的理解
- Hive SQL 转化为 MR 的过程?
- Hive 的存储引擎和计算引擎
- Hive 中如何调整 Mapper 和 Reducer 的数目
- Hive 中的 MapJoin
- Hive 的执行顺序
- Hive 使用的时候会将数据同步到 HDFS,小文件问题怎么解决的?
- Hive 有哪些保存元数据的方式,都有什么特点?
- Hive count(distinct) 有几个 reduce,海量数据会有什么问题?
- 了解 Hive SQL 吗?讲讲分析函数?
- 说说 over partition by 与 group by 的区别
- 分析函数中加 Order By 和不加 Order By 的区别?
- Hive 中 Metastore 服务作用
- HiveServer2 是什么?
- Hive 表字段换类型怎么办
- Parquet 文件优势
Hadoop 专区
HDFS 存储小文件问题
在 HDFS 数据存储是常常遇到小文件问题,小文件带来的危害有哪些?你知道的解决小文件问题的方法有哪些?
危害:
-
NameNode 宕机。 因为 HDFS 为了加速数据的存储速度,将文件的存放位置数据(元数据)存在了 NameNode 的内存,而 NameNode 又是单机部署,如果小文件过多,将直接导致 NameNode 的内存溢出,而文件无法写入。
-
严重影响 HDFS 访问文件性能,还可能会造成 HDFS 系统的崩溃。
解决方法:
-
利用 Apache 官方提供的工具 Hadoop Archive 来实现小文件的合并。Hadoop Archive 是一个高效地将小文件放入 HDFS 块中的文件存档工具,它能够将多个小文件打包成一个 HAR 文件,这样在减少 NameNode 内存使用的同时,仍然允许对文件进行透明的访问。
-
利用 Hadoop 提供的 SequenceFile 对小文件进行合并。它支持二进制文件。
HDFS 的存储机制
写流程
- 客户端向 NameNode 发送写请求。
- NameNode 记录一条数据的存储位置,然后将其告诉客户端。
- 客户端根据反馈的指定位置存储到 DataNode 中。
- DataNode 对数据完成备份,然后反馈给客户端。
- 客户端将结果反馈给 NameNode,NameNode 将元数据同步到内存中,完成写的过程。
读流程
- 客户端向 NameNode 发送读请求,获取数据的存储位置。
- 客户端根据位置读取 HDFS 中的数据,完成读的过程。
Spark 专区
如何解决 Job 运行效率低的问题
你认为可能是哪些情况造成?有什么相关的解决方法吗?
引发的原因:
-
数据倾斜
-
调度器问题
-
大量 shuffle 操作所引起
解决方法:
-
看本文中数据倾斜的解决方法。
-
检查服务是否正常运行,队列是否阻塞。
-
减少 shuffle 操作,对数据进行预处理。
Spark 的数据本地性有哪几种,分别表示什么?
-
PROCESS_LOCAL ,进程本地化,表示 task 要计算的数据在同一个 Executor 中。
-
NODE_LOCAL ,节点本地化,速度稍慢,因为数据需要在不同的进程之间传递或从文件中读取。
-
NO_PREF,没有最佳位置,数据从哪访问都一样快,不需要位置优先。比如: Spark SQL 从 Mysql 中读取数据。
-
RACK_LOCAL,机架本地化,数据在同一机架的不同节点上。
-
ANY, 跨机架,数据在非同一机架的网络上,速度最慢。
本题参考文章:一文搞清楚 Spark 数据本地化级别
如何解决数据倾斜问题
当使用 Spark 产生了数据倾斜的情况时,请问有哪些方法可以解决这个问题呢?
数据倾斜的产生: 不同的 key 对应的数据量不同,导致程序运行时分配给不同 task 处理的数据量也不同。
解决方法:
-
提高 shuffle 操作的并行度,但是只能起到缓解作用。
-
过滤掉少数几个导致数据倾斜的 key。 前提是不影响计算结果。
-
在 Hive 中进行预处理。如果数据源存储在 Hive 中,那么我们可以在 Hive 中进行 group by 或者 join 操作等,对数据进行预处理,Spark 可以直接使用 Hive 预处理好的数据。虽然还是会在 Hive 中产生数据倾斜,但是极大的提高了 Spark 作业的性能,减少了在 Spark 中的 shuffle 操作。
-
在进行 join 操作时,将 reduce join 转为 map join。只适用于大表 join 小表的场景。
Hive 专区
数据仓库中怎么处理缓慢变化维,有哪几种方式?
缓慢变化维是指一些维度表的数据不是静态的,而是会随着时间而缓慢地变化,简称:SCD 问题,那么在数仓设计中有哪些方式应对这些问题?
-
保留原始值
-
改写属性值
-
增加维度新行
-
增加维度新列
-
添加历史表
本题参考文章:通俗易懂讲数据仓库之【缓慢变化维】
Hive 是什么? 跟数据仓库区别?
Hive 是基于 Hadoop 的开源的数据仓库工具,用于处理海量结构化数据。
区别:
-
存储不同。Hive 是存储在 HDFS 上的。
-
语言不同。Hive 使用的是 HQL 语言,而传统的数仓使用的是 SQL。
-
Hive 的灵活性更好。Hive 元数据存储独立于数据存储之外,从而解耦元数据和数据。
-
分析速度更快。Hive 计算依赖于 MapReduce 和集群规模,还可以与 Spark 进行交互。
-
可靠性高。Hive 的数据存储在 HDFS 中,容错性高,因为磁盘是可以进行持久化的。
本题参考文章:1.Hive与传统数据仓库的比较
为什么要使用 Hive? 它的优缺点以及作用是什么?
Hive 能够把 HDFS 中结构化的数据映射成表,可以处理海量的结构化数据。
优点:
-
采用类似 SQL 的语法,上手容易。
-
Hive 对 MapReduce 进行了包装,开发人员不需要写 MapReduce,减少了学习成本。
-
能够处理海量结构化数据。
Hive 的缺点:
-
由于 Hive 主要用于数据分析,因此延时比较高,不适用于实时场景,主要用于做离线大数据分析;
-
Hive 的 HQL 表达能力有限;
-
数据挖掘方面不擅长;
-
Hive 的效率比较低;
-
Hive 自动生成的 MapReduce 作业,通常情况下不够智能化;
-
Hive调优比较困难,粒度较粗。
本题参考文章:Hive的概念,作用,优缺点
Hive 架构

本题参考文章:一篇文章搞懂 Hive 的系统架构
Hive 运行原理
-
用户将查询语句发送给 Driver;
-
Driver 调用解析器(Antlr),将查询语句解析成抽象语法树,发送给编译器;
-
编译器拿到抽象语法树,向元数据库请求并获取对应的元数据信息;
-
元数据库接收请求并返回元数据信息;
-
编译器根据元数据生成逻辑执行计划,返回给 Driver;
-
Driver 调用优化器对逻辑执行计划进行优化,减少 shuffle 数据量,发送给执行器;
-
执行器拿到优化好的逻辑执行计划,将其转化成可运行的 Job,并发送给 Hadoop;
-
执行计划,返回结果。
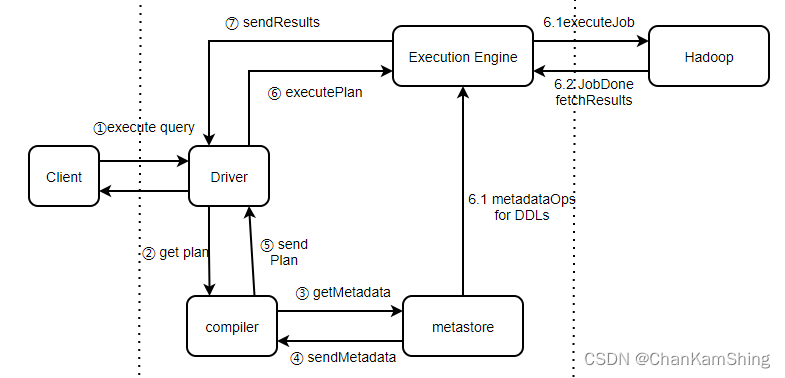
本题参考文章:Hive执行流程原理
查询建表与 like 建表
查询建表缺点:所有的数据类型默认是最大范围
CREATE [TEMPORARY,EXTERNAL] TABLE [if not exist]
[db_ name. ]name [ROW FORMAT row_ format] [STORED AS
file_ format] AS select_ statement
like 建表:
CREATE TABLE table2 like table1;
Hive 默认分隔符
默认行分隔符为 /n,默认字段分隔符为 \001。
Hive 外部表与内部表的区别
内部表的数据由 Hive 管理,且存储在 hive.metastore.warehouse.dir 配置的路径中。
external 外部表的数据由 HDFS 存储,路径可以自己指定。
删除表时,内部表会把元数据及真实数据删除,而外部表不会删除真实数据。
Hive 删除外部表删除的是什么?如何恢复?
我们可以通过 drop table tb_name 的命令将外部表删除。但是外部表只会将元数据删除,HDFS 上依旧存在外部表的所有数据。
如果想要恢复,我们可以先创建原来的外部表,然后直接通过表的修复命令 MSCK REPAIR TABLE table_name; 进行数据恢复。
Hive 中的分区与排序区别
-
order by: 对数据进行全局排序,在 reduce 中进行排序,只有一个 reduce 工作。
-
sort by: 对数据进行局部排序,进入 reduce 前完成排序,一般和
distribute by使用。当设置set mapred.reduce.tasks=1时,效果和order by一样。 -
distribute by: 对 key 进行分区,结合
sort by实现分区排序 -
partition by: 同样也是对 key 进行分区,但它只能用在窗口函数中,结合
order by实现分区排序。 -
cluster by: 当
distribute by和sort by的字段相同时,可以使用cluster by代替,但cluster by只能进行升序排列,不能指定排序规则。
Hive 分区表的作用是什么,是否越多越好,为什么?
作用: 分区表本质上对应的就是 HDFS 中的一个文件夹,其中存储的就是分区表的数据。分区表就是将数据通过指定的分区字段存储到各自的文件夹中,在海量数据中可以加快查询效率。
分区表的数量不宜过多。 因为 Hive 的底层数据就是存储在 HDFS 上,如果分区表中的文件数据量很小,会造成小文件过多,给 NameNode 带来很大压力,会导致内存溢出,严重还会导致 HDFS 直接崩溃。
Hive 中的分桶表
Hive 中的分桶表主要是通过获取 clustered by(col) 指定的字段哈希值与分桶的数量进行取模分组,最后根据指定字段对每个桶进行排序sort by(col) ,完成分桶。
在物理层面上,分桶其实就是根据规则,创建文件的过程,而分区则是创建文件夹的过程。
Hive 数据倾斜以及解决方案
数据计算时发生了 shuffle 操作,导致对数据进行了重新分区。
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 某个或某几个key比较集中,或者存在大量null key | 分发到某一个或者某几个Reduce上的数据远高于平均值 |
| group by | 维度过小,某值的数量过多 | 某个维度或者某几个维度且这些维度的数据量特别大,集中在一个reduce |
join 操作导致的倾斜:
- 同字段数据但不同类型关联产生数据倾斜。
转换成统一类型。
- null key关联。
让 null key 不参与关联,使用 union all 与关联后的数据进行合并。或者为 null key 加盐,赋予固定字符串+随机值的形式。
-
提高 reduce 并行度
-
过滤倾斜 join,单独进行 join 然后再合并。
group by 操作导致的倾斜:
-
开启负载均衡
-
group by 双重聚合
本题参考文章:Hive数据倾斜原因及解决方案
Hive 的用户自定义函数实现步骤与流程
- 新建项目
- 导入 jar 包
- 开发函数(继承UDF,重写evaluate。用hadoop的数据类型。)
- 打成 jar 包
- 上传到 linux
- 上传到 hdfs
- 进入 hive 客户端
- 创建 UDF 函数
- 使用函数
本题参考文章:Hive的用户自定义函数UDF开发步骤详解
简述对于 UDF/UDAF/UDTF 的理解
他们的区别是什么,分别解决了什么问题?
-
UDF: 自定义函数,一进一出。类似于
year,month,day... -
UDAF: 自定义聚合函数,多进一出。类似于
avg,sum,max... -
UDTF: 自定义表生成函数,一进多出。类似于
lateral view + explode
能够让开发者针对现有场景设计不同种类的自定义函数解决问题,极大的丰富了可定制化的业务需求。
对数据进行分层作用(数仓的作用)的理解
数仓: 数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。
数仓分层:
-
ODS 源数据层,顾名思义,存放源数据。
-
DW 数据仓库层,存放清洗过滤后的数据。在 DW 层中可以分为三层:
-
DWD 明细层,存放明细数据。数据来源于:ODS
-
DWM 中间层,存储中间数据,为数据统计创建中间表数据。数据来源于:DWD
-
DWS 业务层,存储宽表数据,根据实际业务对数据进行聚合。数据来源于:DWD 与 DWM
-
-
DA 数据应用层,直接调用的数据源。
作用:
-
清晰数据结构
-
数据血缘追踪
-
减少重复开发
-
屏蔽原始数据的异常
-
屏蔽业务之间的影响
Hive SQL 转化为 MR 的过程?
先说一点,Hive 并不是所有的查询都需要走 MR,如:全局查找、字段查找、过滤查询、limit 查询,都不会走 MR,直接 fetch 抓取,提高查询效率(其余的还是走 MR)。
简单叙述一个将 join 操作转为 MR 的过程:
- map 阶段生产 k,v 键值对,将 join 的连接字段作为 value,打上 tag;
- shuffle 阶段根据 key 进行分组,将 k,v 一致的发送给reduce;
- reduce 阶段将相同 key 进行连接操作,识别 tag 进行 value 配对。
Hive 的存储引擎和计算引擎
存储引擎:textfile、orcfile、parquet 、rcfile、sequencefile
计算引擎:mr、spark 、tez
Hive 中如何调整 Mapper 和 Reducer 的数目
首先明白一点,map 或 reduce 数量并不是越多越好。如果有过多的小文件(大小远不够 128M),则每个小文件也会当做一个块,甚至计算时间没有 map 或 reduce 任务的启动和初始化时间,则会造成资源的浪费,reduce 过多也会导致输出的小文件过多,同样会出现效率问题。
解决方案:合并小文件,减少 map 数
可通过设置如下参数解决:
#执行 Map 前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #每个 Map 最大输入大小,单位为 KB
set mapred.max.split.size=128000000; #一个节点上 split 的至少的大小,单位为 KB
set mapred.min.split.size.per.node=100000000; #一个交换机下 split 的至少的大小,单位为 KB
set mapred.min.split.size.per.rack=100000000;

reduce 设置:
- 调整每个 reduce 可以处理的大小,hive 会进行自动推算 reduce 个数,单个任务最大
999个,可以通过hive.exec.reducers.max参数进行调整;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
- 直接调整
reduce个数,固定。
set mapred.reduce.tasks = 15;
Hive 中的 MapJoin
Join 操作在 Map 阶段完成,如果需要的数据在 Map 的过程中可以访问到则不再需要 Reduce。
小表关联一个超大表时,容易发生数据倾斜,可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。
通过如下参数进行设置:
--是否开自动 MapJoin
set hive.auto.convert.join = true;--MapJoin 的表size大小,默认25m。
set hive.mapjoin.smalltable.filesize;
Hive 的执行顺序
from … on … join … where … group by … having … select … distinct … order by … limit
Hive 使用的时候会将数据同步到 HDFS,小文件问题怎么解决的?
Hive 在进行增量导入或者动态分区的时候往往都有可能会产生大量的小文件。
我们可以采用如下这种策略:
insert overwrite tb_name select * from tb_name distribute by floor(rand()*5)
将 reduce 的个数控制在 5 个以内,根据实际业务场景来,这样就可以有效的减少小文件的数量。
Hive 有哪些保存元数据的方式,都有什么特点?
-
内嵌模式:将元数据保存在本地内嵌的 derby 数据库中,内嵌的 derby 数据库每次只能访问一个数据文件,也就意味着它不支持多会话连接。
-
本地模式:将元数据保存在本地独立的数据库中(一般是 mysql),这可以支持多会话连接。
-
远程模式:把元数据保存在远程独立的 mysql 数据库中,避免每个客户端都去安装mysql数据库。
特点:
-
内存数据库 derby,安装小,但是数据存在内存,并且数据存储目录不固定,不适合多用户操作。
-
mysql 数据库,数据存储模式可以自己设置,持久化好,查看方便。
本题参考文章:Hive元数据存储的三种模式,hive有哪些保存元数据的方式,各有什么特点。
Hive count(distinct) 有几个 reduce,海量数据会有什么问题?
count(distinct) 只会产生一个 reduce,即使你设置的 reduce 数量比它大。
后果:
在海量数据时会产生严重的数据倾斜。
解决方法:
在海量数据面前一般使用 count + group by 来进行统计,如果数据量不是很大,则可以直接使用 count(distinct) 的方式来进行统计。
了解 Hive SQL 吗?讲讲分析函数?
-
聚合函数。比如:sum(…)、 max(…)、min(…)、avg(…)等
-
数据排序函数。比如 :rank(…)、row_number(…)等
-
统计和比较函数。比如:lead(…)、lag(…)、 first_value(…)等
说说 over partition by 与 group by 的区别
group by 会改变数据的行数,返回分组之后的数据结果,而partition by是数据原本多少行,分区之后仍有多少行。
分析函数中加 Order By 和不加 Order By 的区别?
当为排序函数,如:row_number(),rank() 等时,over中的order by只起到窗口内排序作用。
当为聚合函数,如:max,min,count 等时,over中的order by不仅起到窗口内排序,还起到窗口内从当前行到之前所有行的聚合(多了一个范围)。
示例:
-- 不加 order by
select spu_id,sum(price) over(partition by spu_id) from sku_info;-- 加 order by
select spu_id,sum(price) over(partition by spu_id order by id) from sku_info;
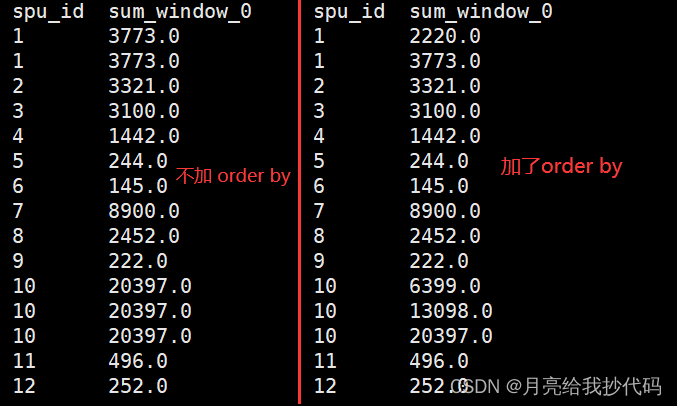
从结果中可以看出,在窗口中如果进行聚合函数的操作,加了 order by 会添加一个限定范围,当前分区内的第一行到当前行。
Hive 中 Metastore 服务作用
客户端连接 metastore 服务,metastore 再去连接 MySQL 数据库来存取元数据。有了 metastore 服务,就可以有多个客户端同时连接,而且这些客户端不需要知道 MySQL 数据库的用户名和密码,只需要连接 metastore 服务即可。
本题参考文章:Hive Metastore服务
HiveServer2 是什么?
HiveServer2 是一个服务接口,能够允许远程的客户端去执行 SQL 请求且得到检索结果。
Hive 表字段换类型怎么办
- 没有数据,直接修改
alter table 表名 change column 原字段名 新字段名 字段类型;
- 有数据
先使用 like 创建一个与原表结构一样的新表,然后修改新表的字段类型,导入原表数据到新表,删除原表。
Parquet 文件优势
Parquet 文件以二进制方式存储,不可以直接读取和修改,Parquet 文件是自解析的,文件中包括该文件的数据和元数据。
Parquet 可以使用较少的存储空间表示复杂的嵌套格式,可以通过 RLE 算法对其进行压缩,进一步降低存储空间;
持续更新中…
这篇关于大数据生态圈面试题(Hadoop、Hive、Spark)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





