本文主要是介绍淘淘商城第115讲——使用Mycat实现分库分表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
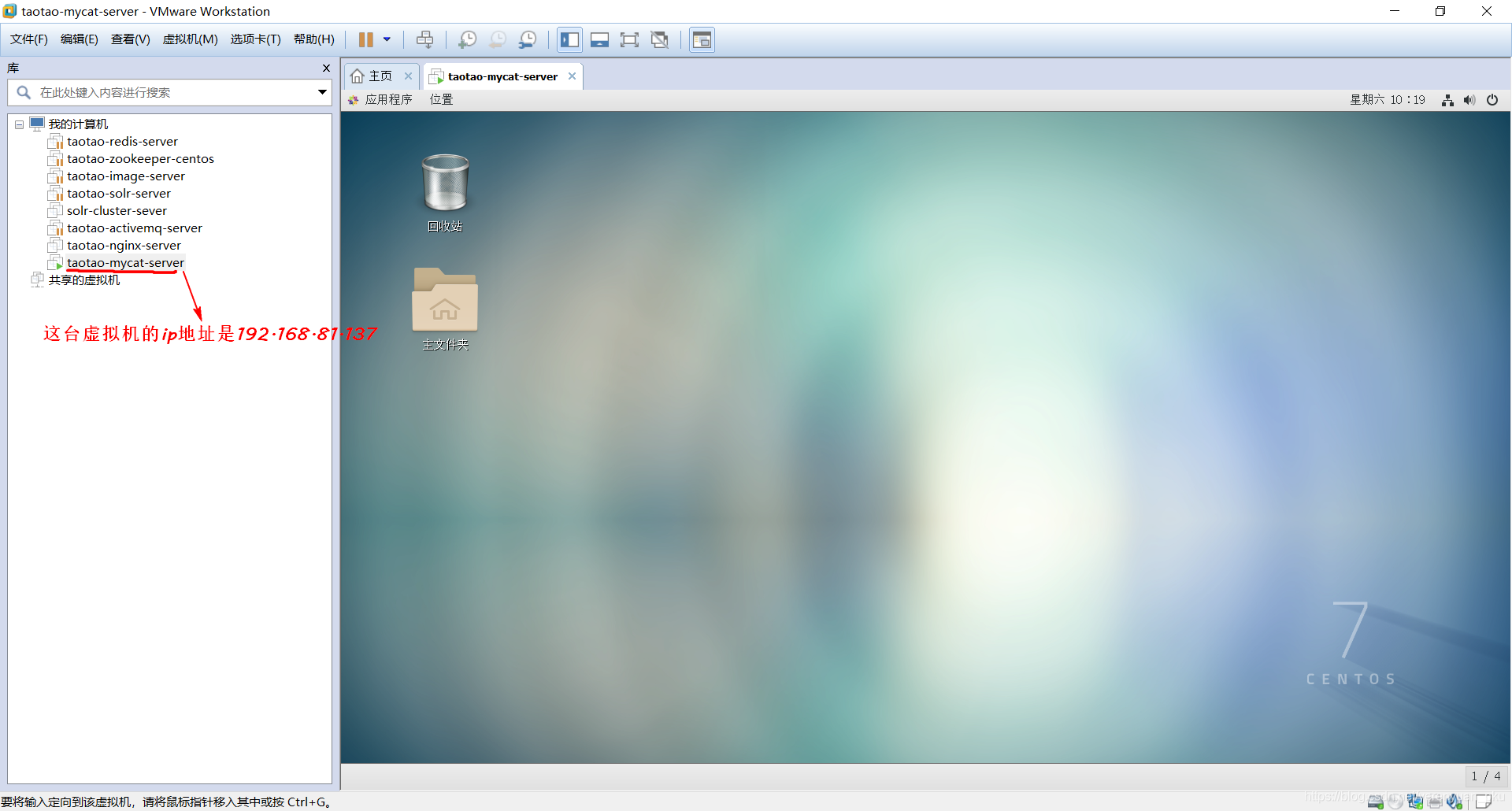
上一讲中,咱们新建了一台虚拟机,而且也为其设置了一个固定IP地址,例如192.168.81.137,如下图所示。
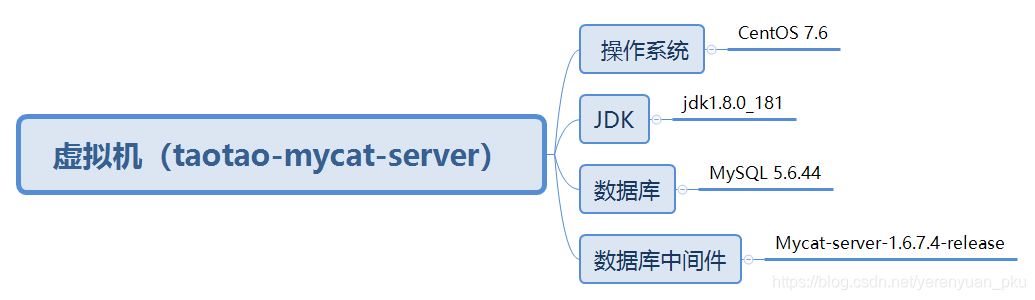
而且在这台虚拟机中我安装好了如下一些东东。
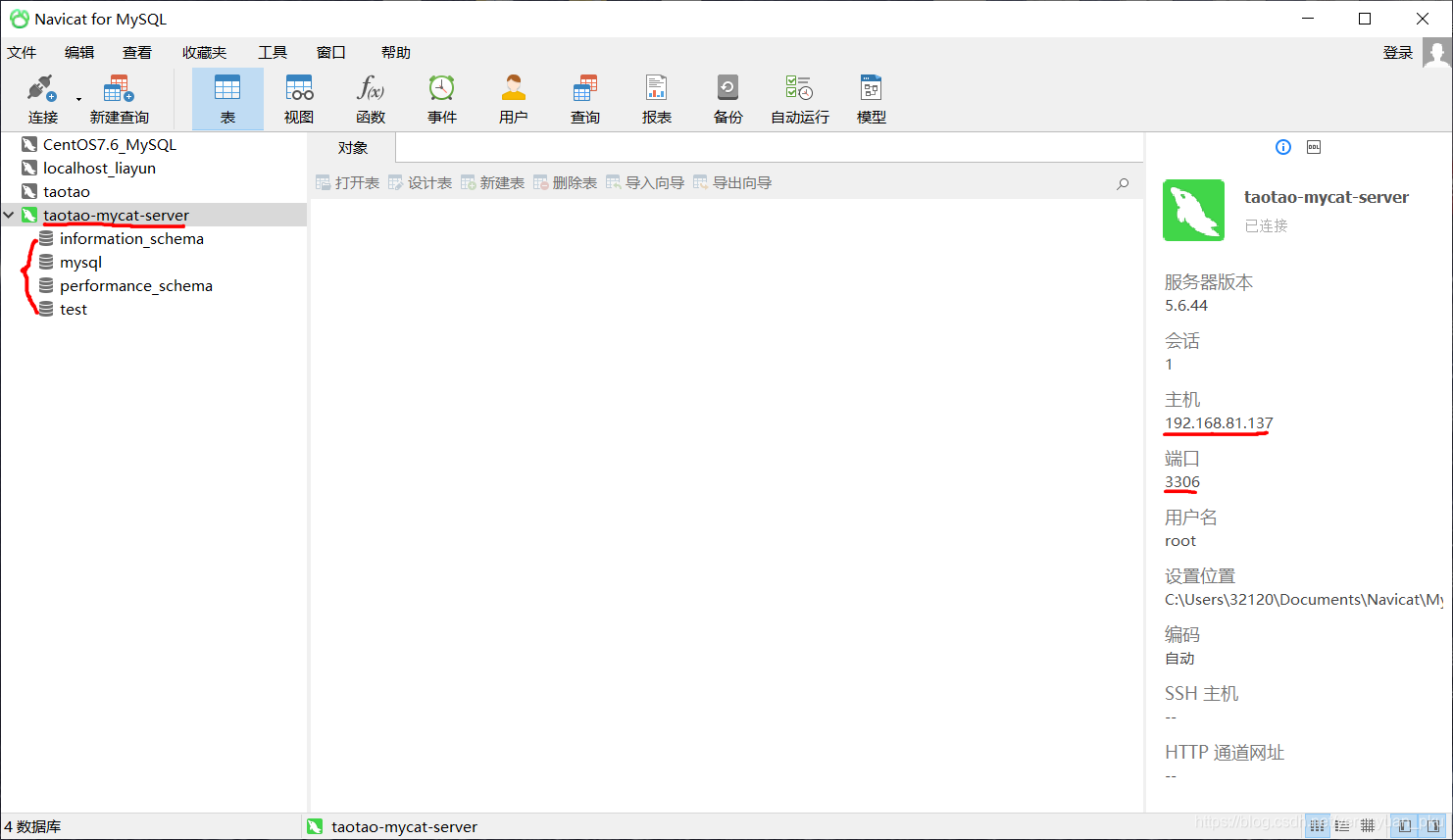
如果这时我们想远程访问以上这台虚拟机中安装好的MySQL数据库,那么该怎么办呢?可以在本地使用MySQL的图形化开发工具(例如Navicat for MySQL)来访问服务器上的MySQL数据库。如果你不知道怎么做,那也没有关系,具体步骤可以参考我写的《Linux入门第十五讲——远程访问Linux CentOS 7.6系统上安装的MySQL5.6》这篇文章。
使用Navicat for MySQL来访问服务器上的MySQL数据库时,访问成功之后的效果如下图所示。
什么是分库分表呢?
当数据库表中的数据非常大的时候,例如有上千万条数据,查询性能就非常低了,这个时候我们就可以把一张表中的数据拆分保存到不同数据库中的不同的表里面。
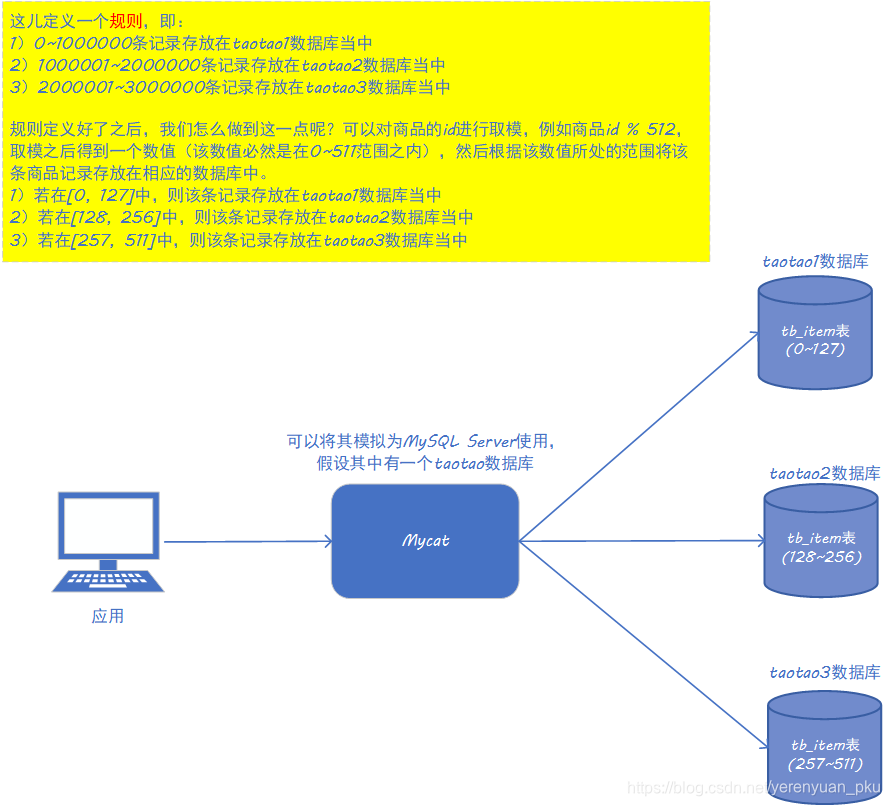
根据经验,对于MySQL来说,表中的数据达到2000W及以上时就需要分库分表了,对于Oracle 11g来说,表中的数据达到1亿及以上时也需要分库分表。
那么如何进行分库分表呢?可以使用一个数据库中间件,例如Mycat,它是一个国产开源项目,前身是cobar项目(原属阿里巴巴)。
使用Mycat实现分库分表
在使用Mycat实现分库分表之前,咱们得做一些准备工作。首先使用MySQL的图形化开发工具(例如Navicat for MySQL)在服务器上新建一个MySQL数据库,例如taotao,详细步骤如下所示。
第一步,右键数据库连接,例如taotao-mycat-server,在弹出的下拉列表中选中新建数据库。
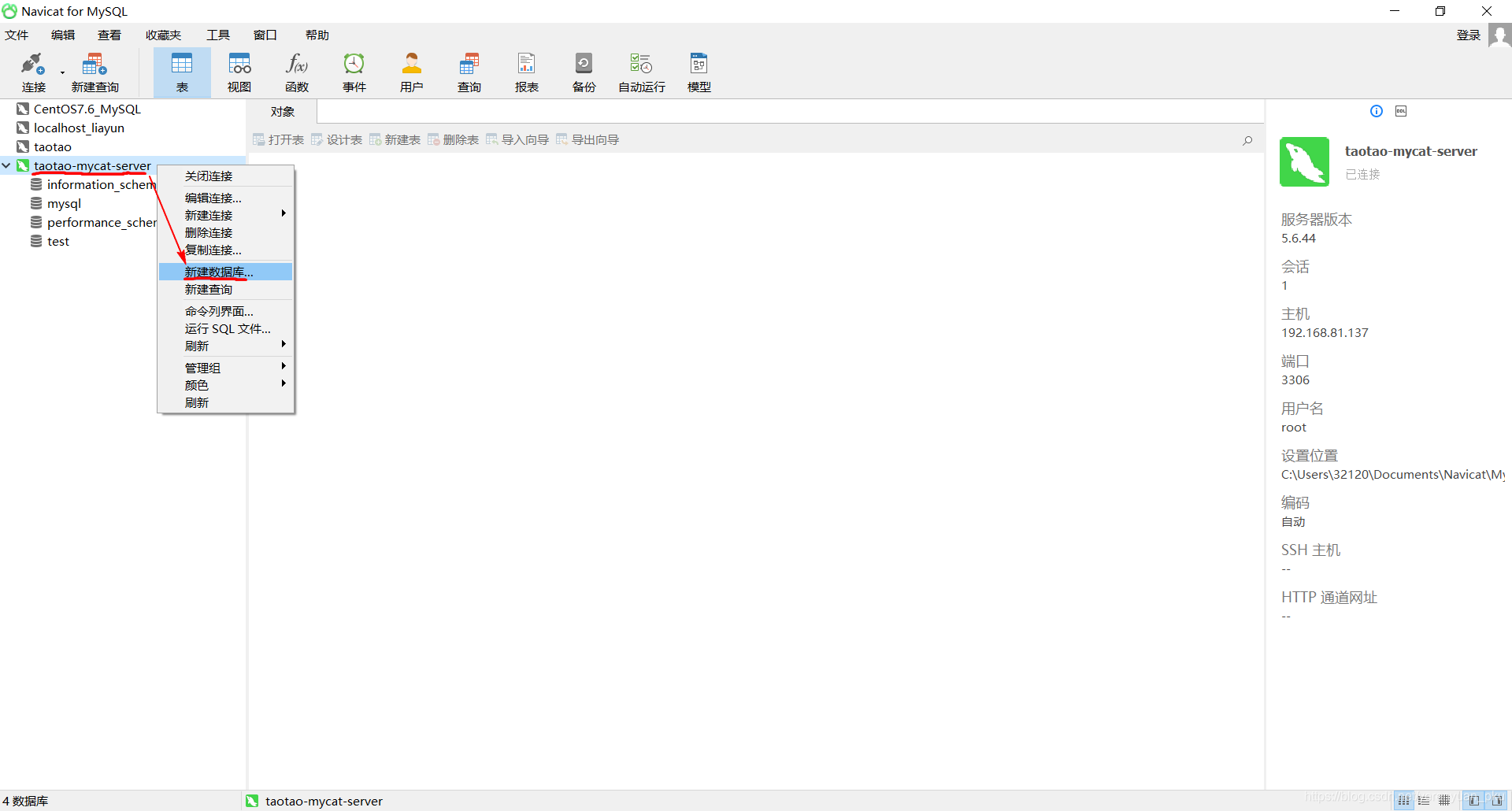
第二步,在弹出的窗口中输入数据库的名称,而且还要选择字符集为utf8。
点击确定按钮之后,名称为taotao的数据库就新建好了。
然后,将一个名称为taotao.sql的sql脚本文件导入到以上taotao数据库中。你可能要问了,我该怎么获取到这个sql脚本文件呢?从我下面给出的百度网盘链接地址中下载就行了。
链接:https://pan.baidu.com/s/1simeTbyekLJc3z_73GCKWw,提取码:217m
下载下来taotao.sql脚本文件之后,记得导入到以上taotao数据库当中。导入成功之后,你就能看到taotao数据库中有如下一些表了。
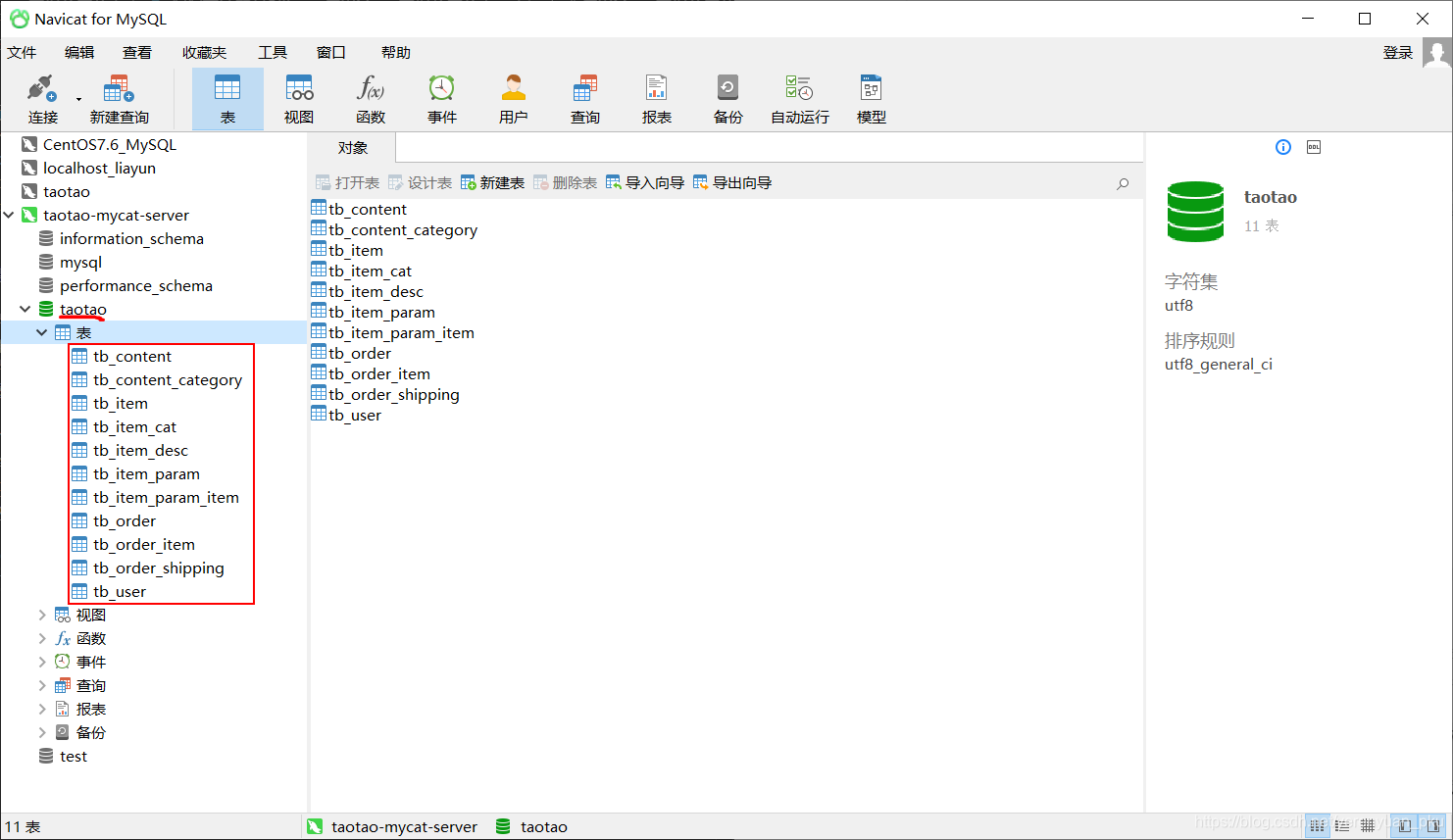
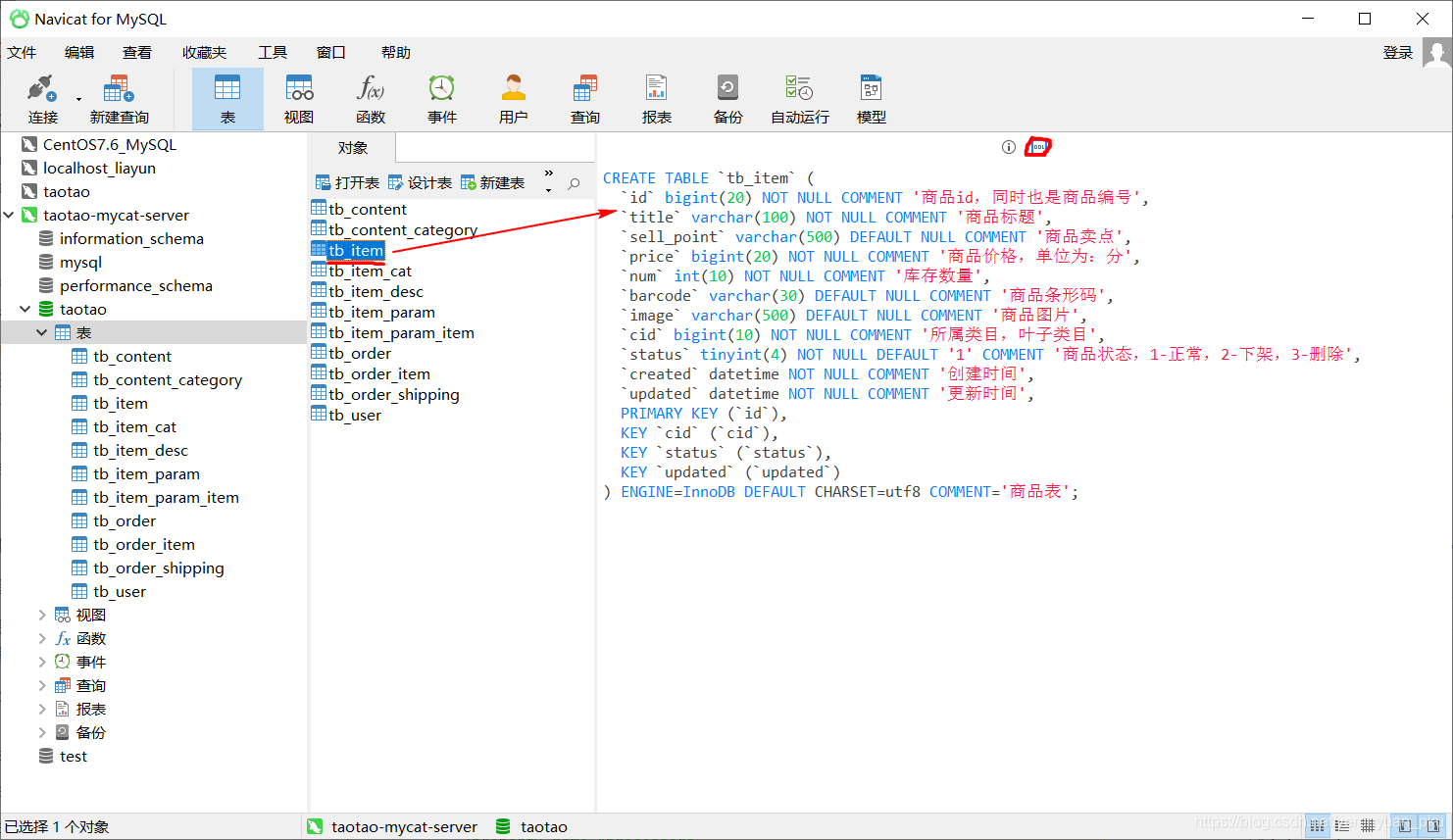
其中tb_item表就是我们要进行分片的表,其表结构设计如下图所示。
最后,我们还得在服务器上再新建三个MySQL数据库,它们的名称分别是taotao1、taotao2以及taotao3。之所以还要新建这三个MySQL数据库,是因为我们得把taotao数据库里面的tb_item表中的数据分到它们里面去。
配置server.xml文件
Mycat中的配置文件有很多,我们经常使用到的是server.xml、schema.xml以及rule.xml这三个配置文件。
这一小节,我们先来详细介绍一下server.xml这个配置文件,介绍完之后,你就知道该怎么配置它了。
该文件中定义了Mycat系统的配置和Mycat的登录用户信息,它里面主要有两个标签,分别是:

接下来,我们就要配置server.xml文件了。为了更加方便操作server.xml文件,我们可以用Nodepad++来编辑该文件,具体怎么做可以参考笔者写的《使用Nodepad++来编辑我们服务器的配置文件》这篇文章!
我们在server.xml文件配置的内容如下图所示。
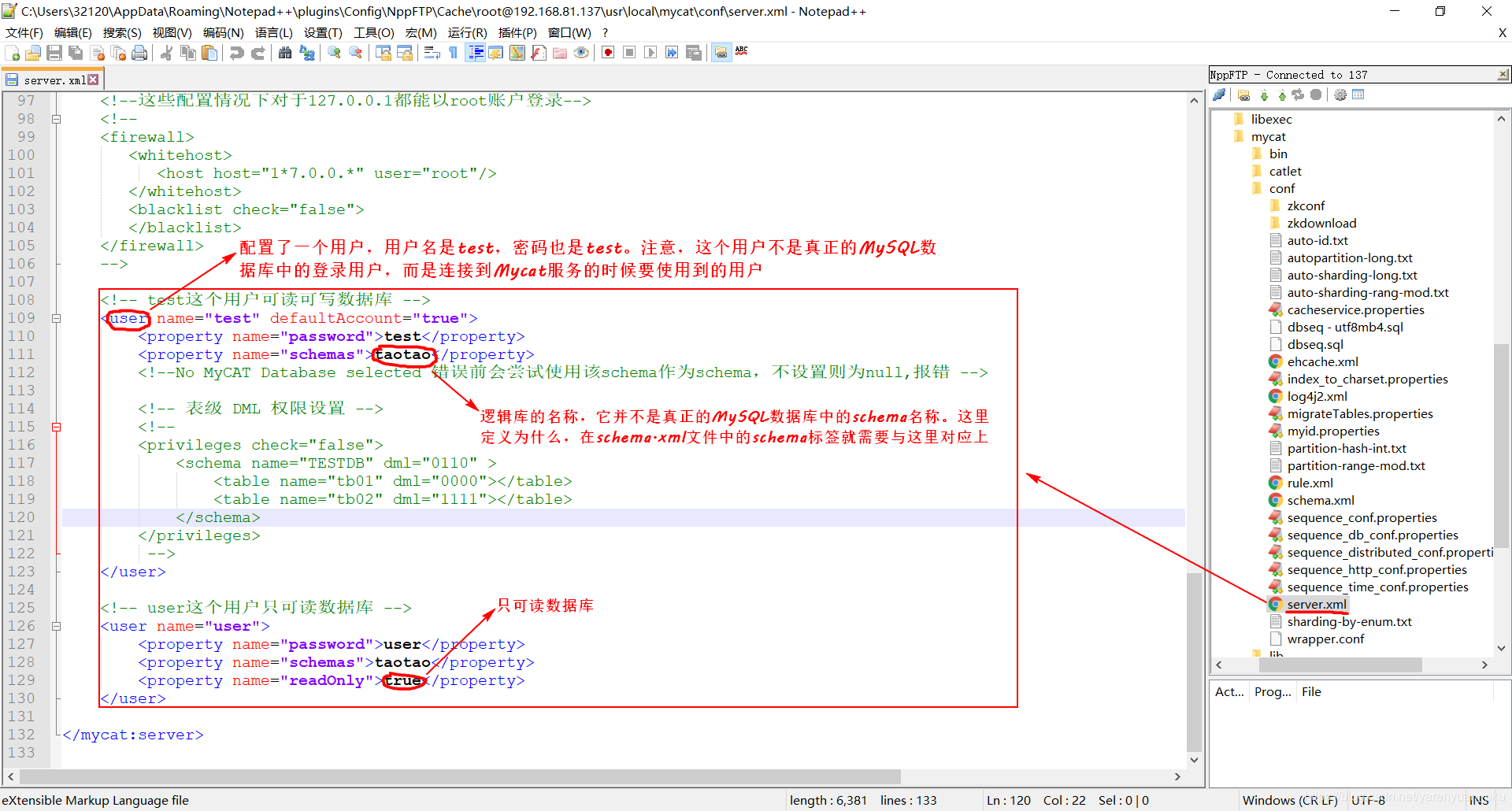
从以上配置文件中的内容可知,现在咱们配置了两个用户,一个用户的用户名是test,密码是test,另外一个用户的用户名是user,密码是user。注意,这儿配置的用户并不是真正的MySQL数据库中的登录用户,而是连接到Mycat服务的时候要使用到的用户,因为在连接Mycat服务的时候需要输入对应的用户名和密码。
配置schema.xml文件
schema.xml作为Mycat中重要的配置文件之一,管理着Mycat的逻辑库、表、分片规则、DataNode以及DataSource,弄懂这些配置是正确使用Mycat的前提。这里笔者就一层层对该文件进行解析。

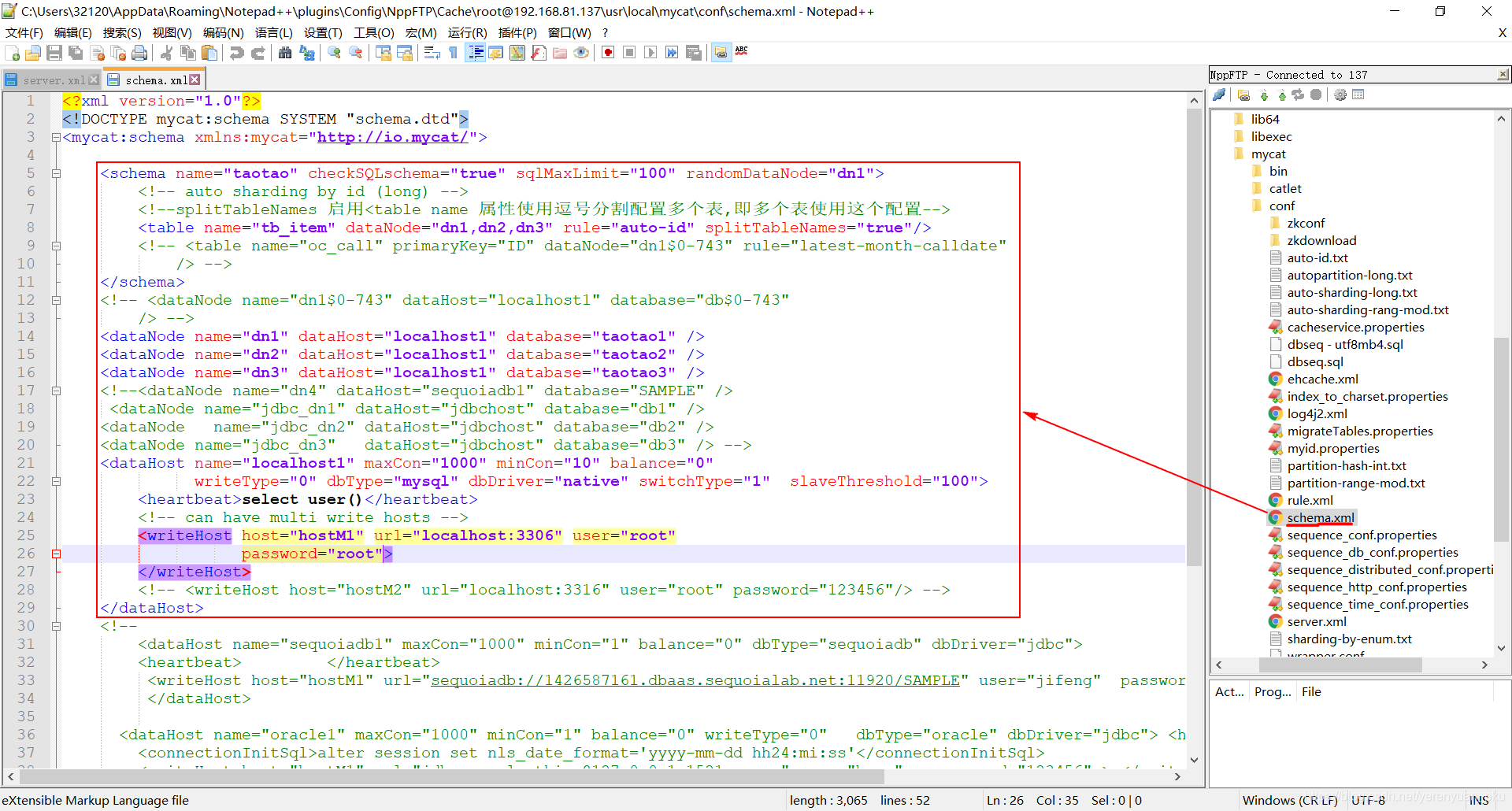
了解了schema.xml文件中的一些配置之后,接下来,咱们就要配置该文件了,配置好后的schema.xml文件的内容如下图所示。
配置role.xml文件
rule.xml文件定义了分库分表的规则。水平分表的时候便会用到该配置文件,因为这涉及到把一个表中的数据如何水平拆分到各个数据库实例中。
由于我们在schema.xml文件中使用到了一个名称为auto-id的分片规则,所以还得在rule.xml文件中定义好该分片规则。
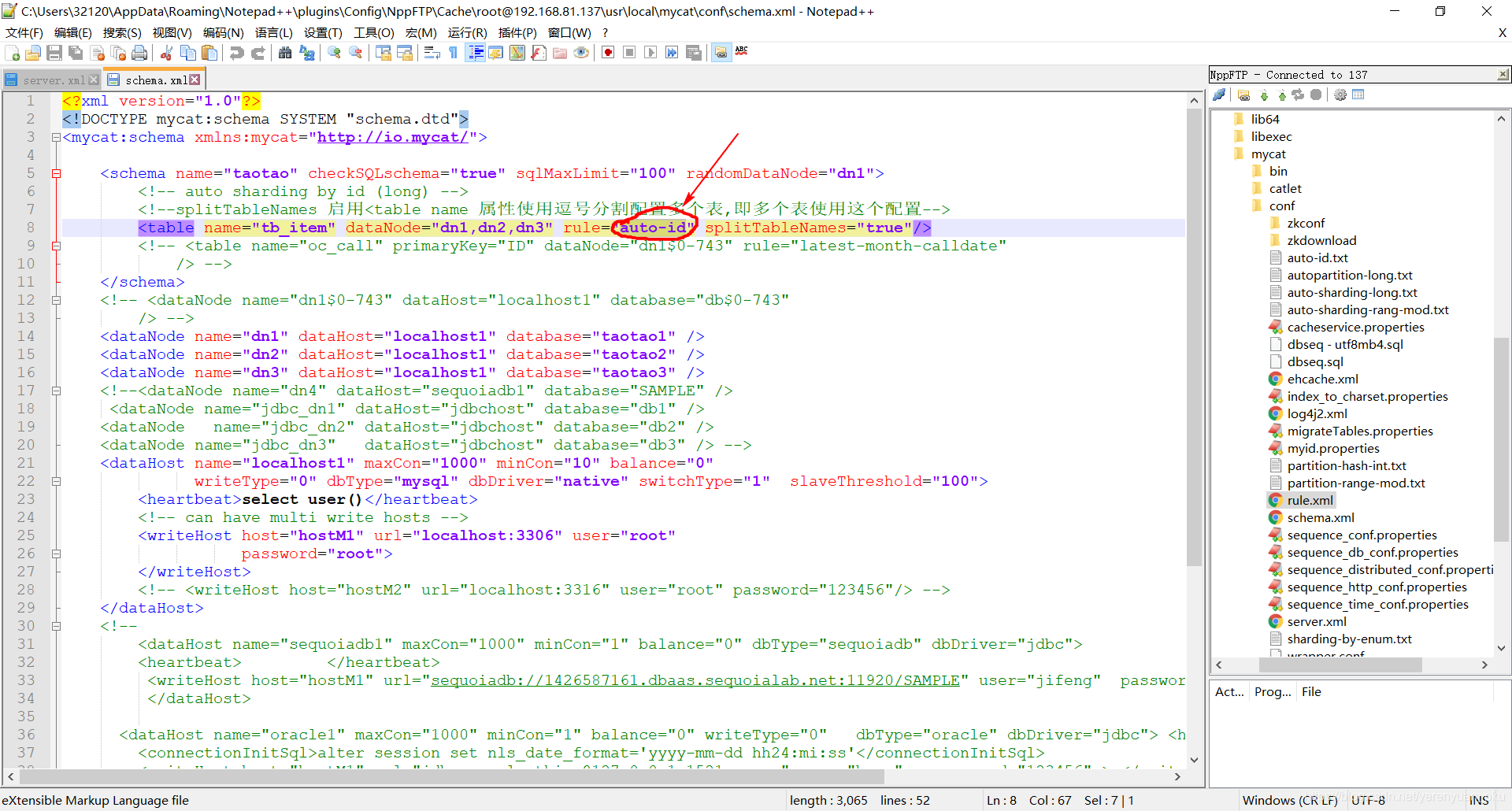
哎,这个分片规则是啥呢?你肯定会有这样的疑惑。我上面也已经讲过了,这里的分片规则是对商品id进行取模(模数暂定为512)。
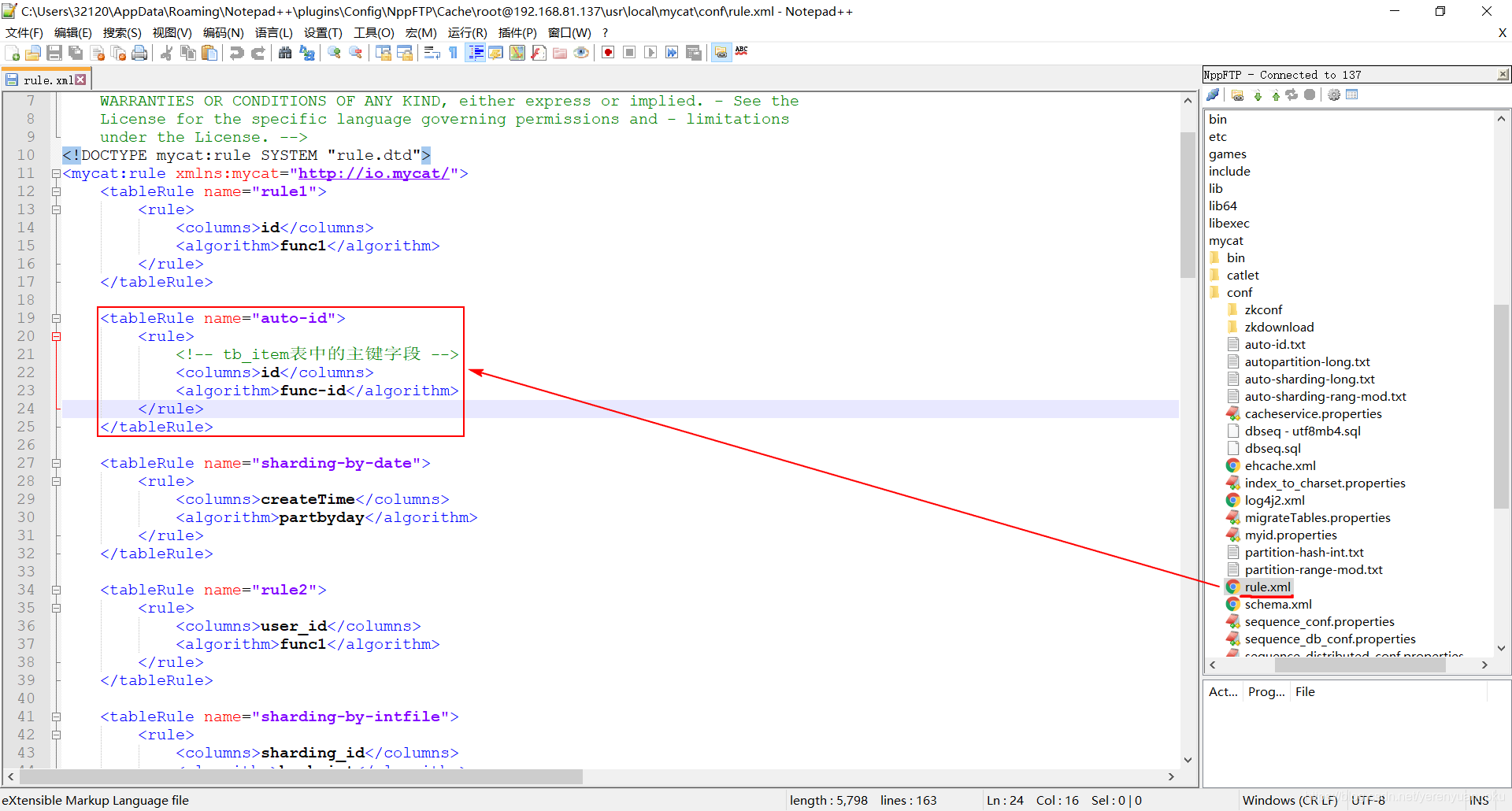
知道了分片规则之后,那么我们就要在rule.xml文件中定义该分片规则了。如何定义这样一个分片规则呢?首先在rule.xml文件中添加一段如下配置:
<tableRule name="auto-id"><rule><!-- tb_item表中的主键字段 --><columns>id</columns><algorithm>func-id</algorithm></rule>
</tableRule>
截图如下:
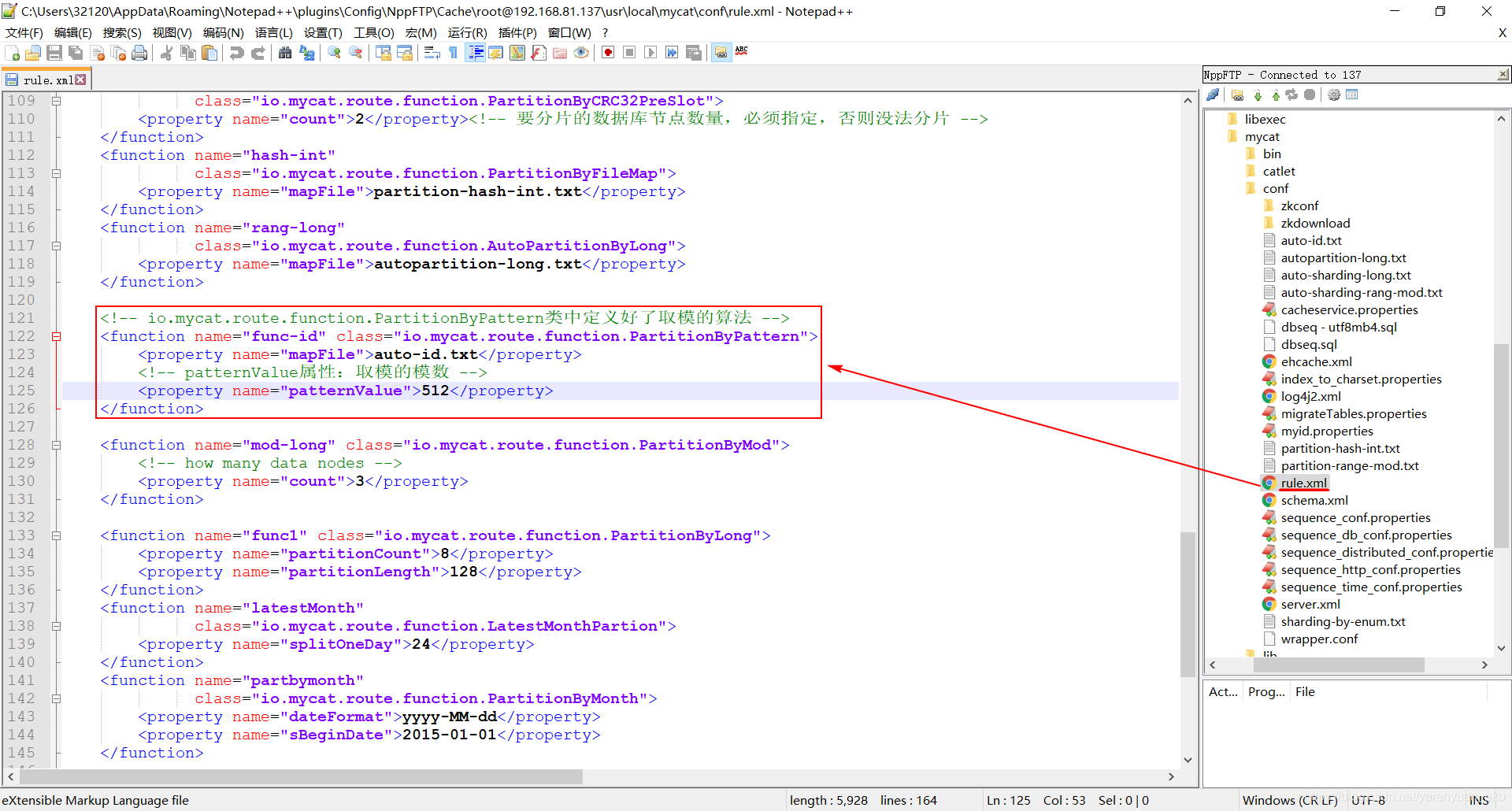
然后再在rule.xml文件中添加一段如下配置:
<!-- io.mycat.route.function.PartitionByPattern类中定义好了取模的算法 -->
<function name="func-id" class="io.mycat.route.function.PartitionByPattern"><property name="mapFile">auto-id.txt</property><!-- patternValue属性:取模的模数 --><property name="patternValue">512</property>
</function>
截图如下:
接着我们还要在/usr/local/mycat/conf目录下新建一个名称为auto-id.txt的文件,其内容如下图所示。
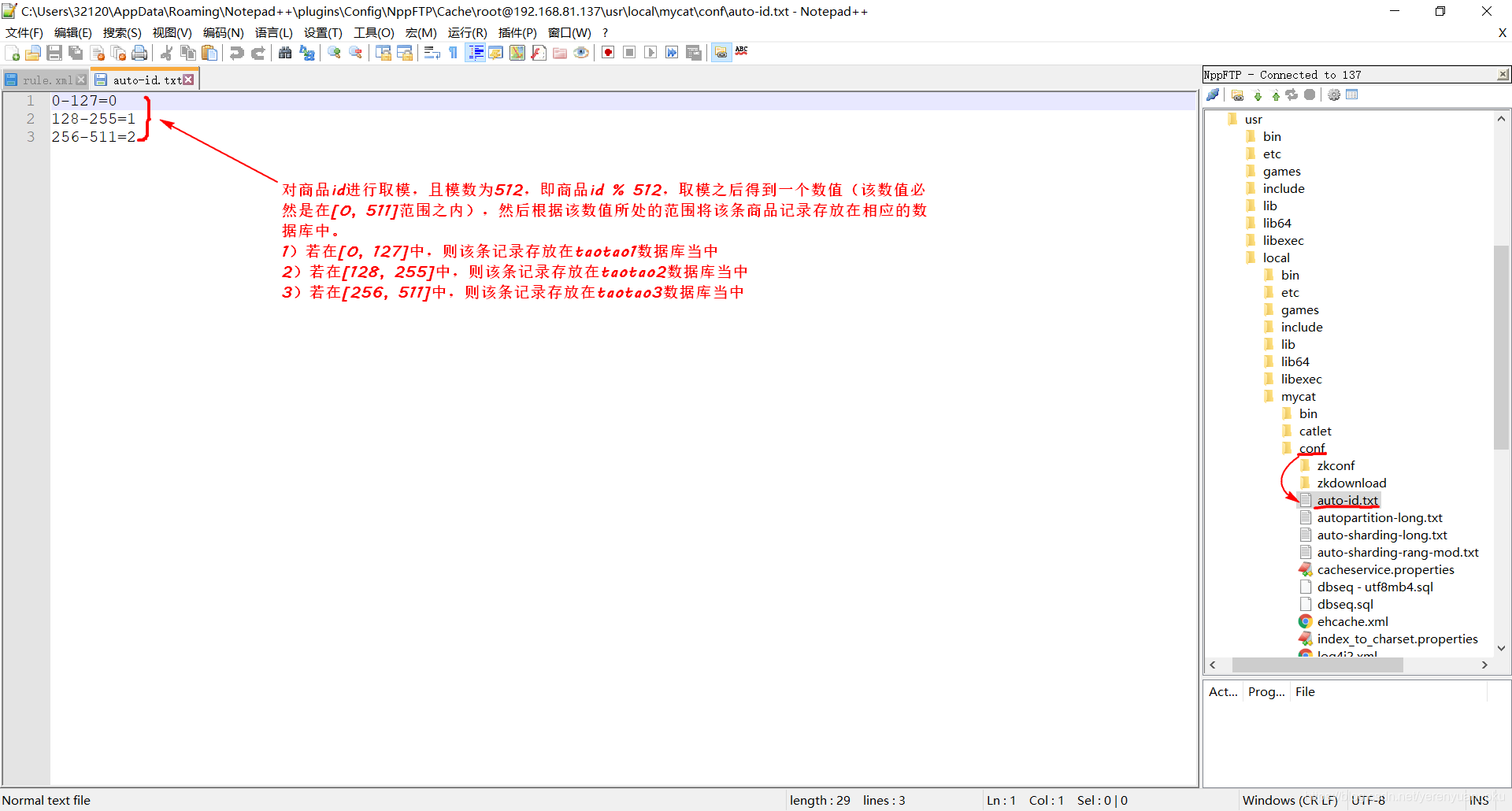
温馨提示:以上文件中的内容可以参考auto-sharding-long.txt文件来配置哟!
测试
配置好以上三个非常重要的文件之后,接下来我们就要测试一下,看看效果了。
在开始测试之前,我得提醒大家一点,若是Linux版本的MySQL,则需要设置为MySQL大小写不敏感,否则可能会出现表找不到的情况。另外,据我测试,使用Mycat来建表的话会乱码,要解决乱码问题就需要设置一下数据库的编码格式。想要做到这两点,大家只须在MySQL的配置文件(即/etc/my.cnf)中的[mysqld]下方添加如下两行配置即可。
lower_case_table_names = 1
character_set_server=utf8
注意,一定要给所有参与分片的Linux系统中的MySQL都添加如上两行配置,配置好之后,重启MySQL,使用的命令是service mysql status。
然后我们来启动Mycat,启动后查看是否正常启动,如下图所示。
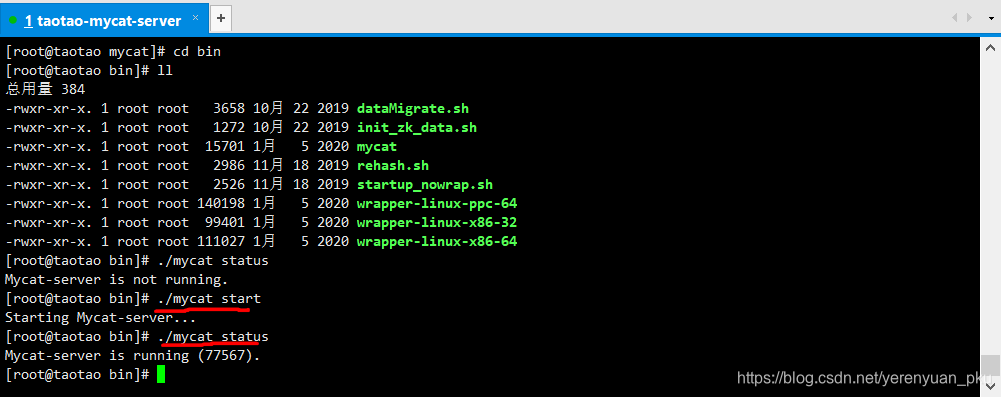
接着我们便要来连接Mycat了。如何来连接Mycat呢?遵循如下步骤即可。
第一步,打开MySQL的图形化开发工具(例如Navicat for MySQL),因为这儿我们使用该工具来连接Mycat的。然后点击左上角的连接,并在弹出的下拉列表中选中MySQL...,如下图所示。
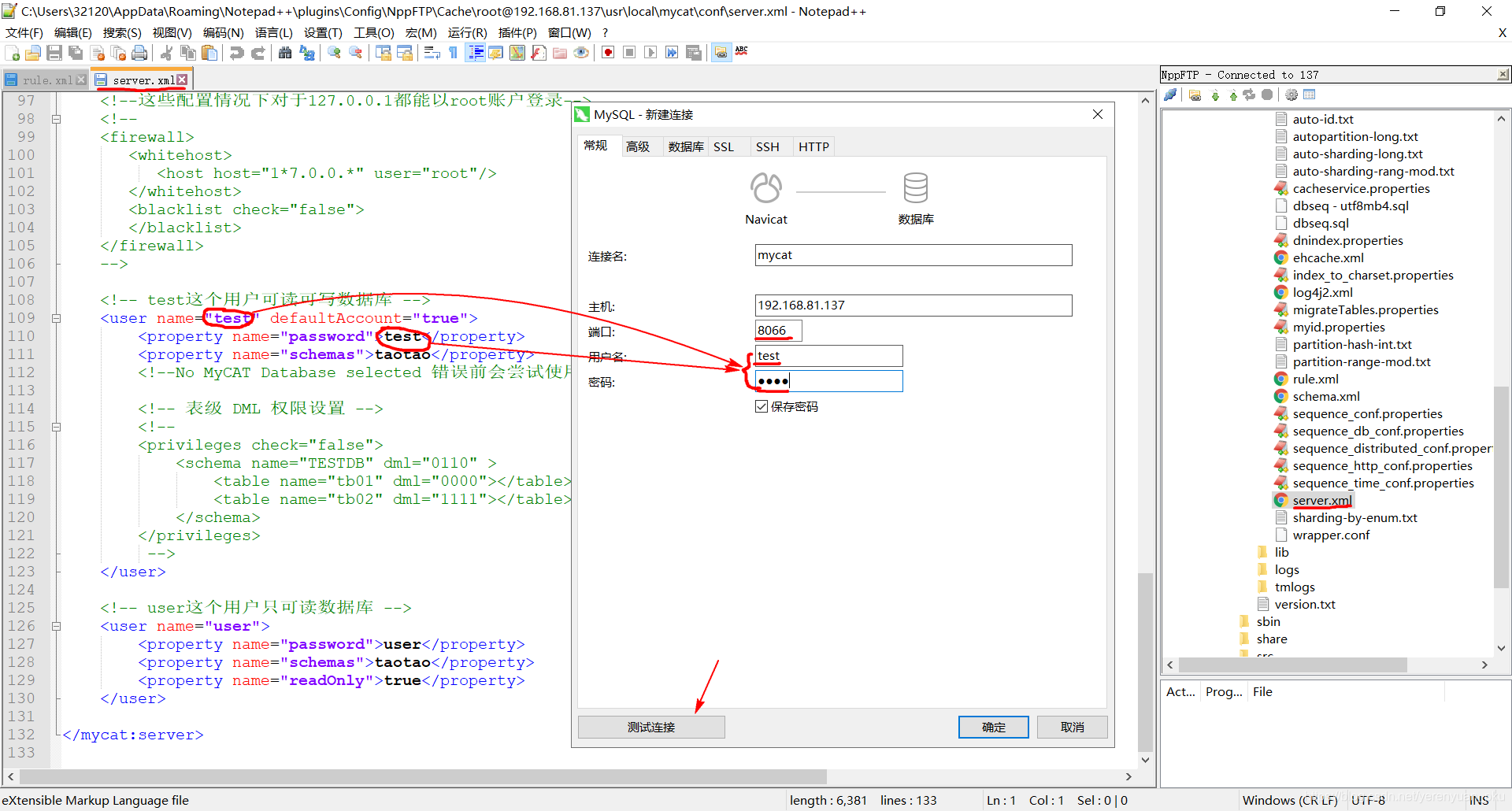
第二步,在弹出的如下窗口中依次连接Mycat的相关信息,比如Mycat的默认端口8066、用户名和密码(这俩我们就用server.xml文件中配置的那个可读可写数据库的用户的用户名和密码)。
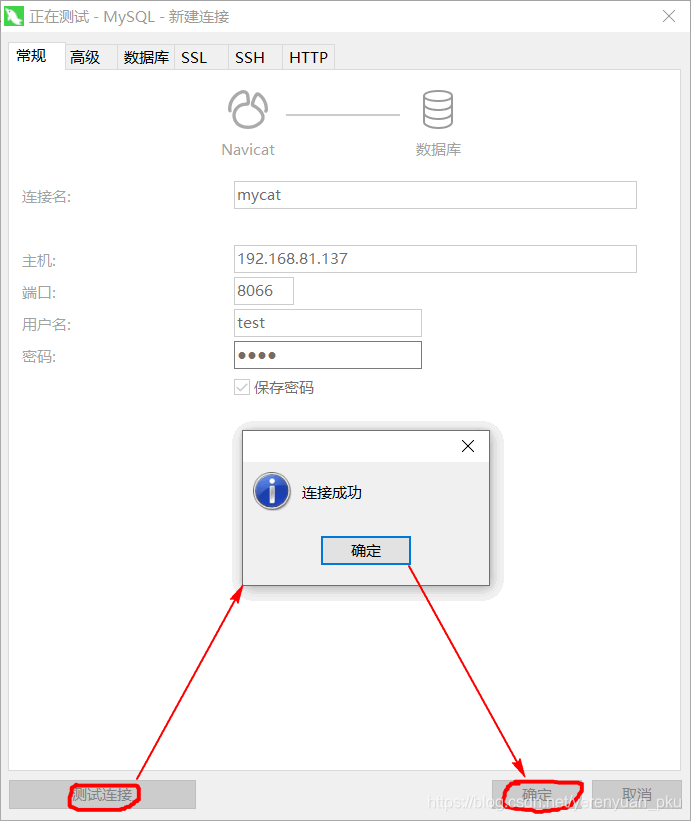
第三步,点击测试连接按钮,若弹出连接成功的对话框,则表明连接Mycat没有任何问题,之后我们再点击确定按钮关闭新建连接窗口。
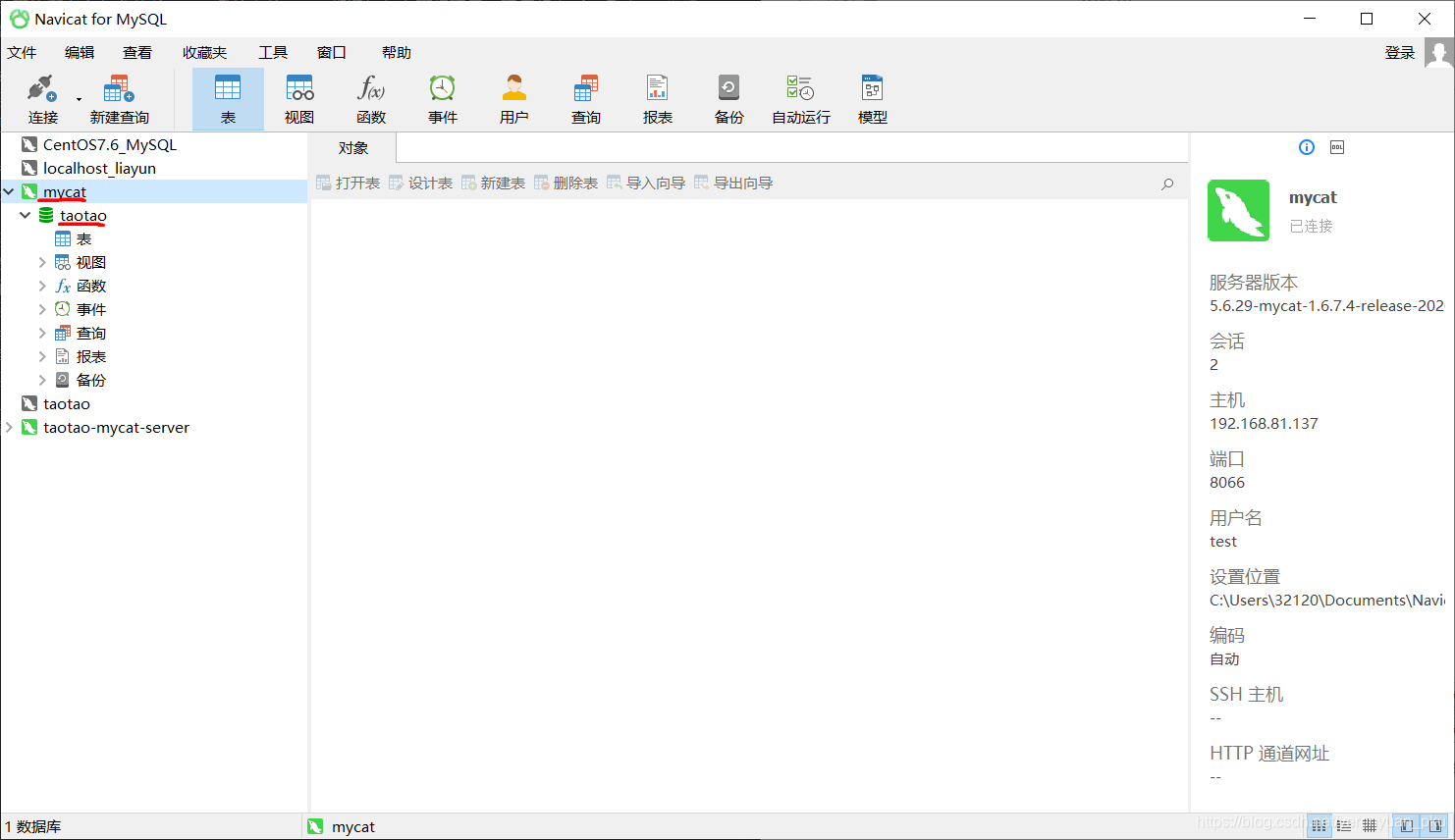
成功连接上Mycat之后,打开新建的mycat连接,发现里面有一个名称为taotao的数据库,而且库中无任何表,如下图所示。
既然库中没表,那我们便在taotao这个数据库中新建一张tb_item表,建表语句如下:
DROP TABLE IF EXISTS tb_item;
CREATE TABLE `tb_item` (`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',`title` varchar(100) NOT NULL COMMENT '商品标题',`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',`num` int(10) NOT NULL COMMENT '库存数量',`barcode` varchar(30) DEFAULT NULL COMMENT '商品条形码',`image` varchar(500) DEFAULT NULL COMMENT '商品图片',`cid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目',`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',`created` datetime NOT NULL COMMENT '创建时间',`updated` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`),KEY `cid` (`cid`),KEY `status` (`status`),KEY `updated` (`updated`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
在taotao这个数据库中建完表之后,我们立即到192.168.81.137这台服务器的taotao1、taotao2以及taotao3这三个数据库中去查看是否也生成了同样的表,如下图所示,可以看到Mycat所在服务器(192.168.81.137)上的taotao1、taotao2以及taotao3这三个数据库中都有了tb_item这张表。
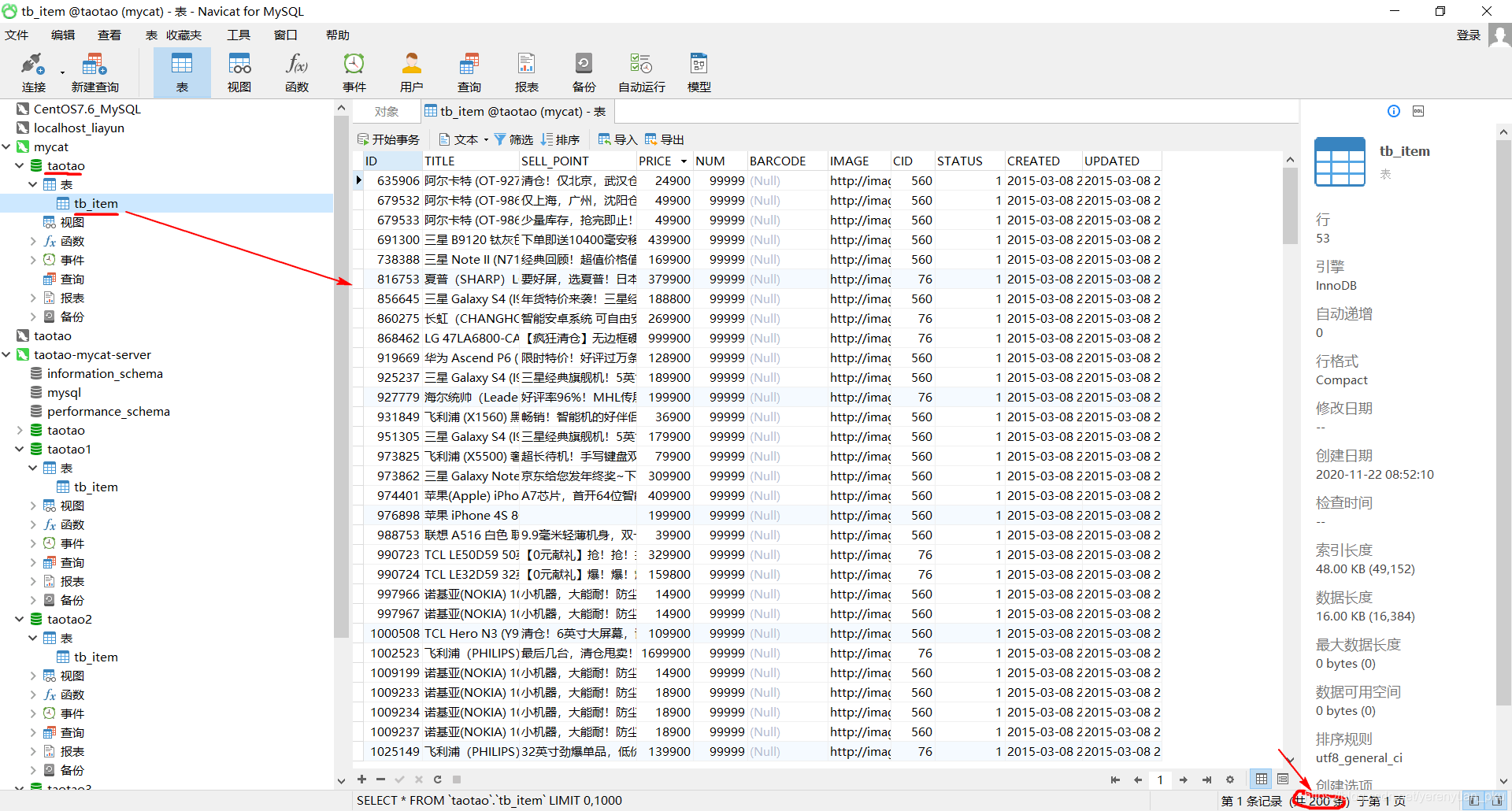
接着我们就向taotao数据库中的tb_item这张表中添加200条商品记录了,如下图所示。
温馨提示:向taotao数据库中的tb_item这张表中添加200条商品记录的sql脚本文件可以从我下面给出的百度网盘连接地址中进行下载。
链接:https://pan.baidu.com/s/113LS6bjbSWaO_3WHEj-BxA,提取码:nmi3
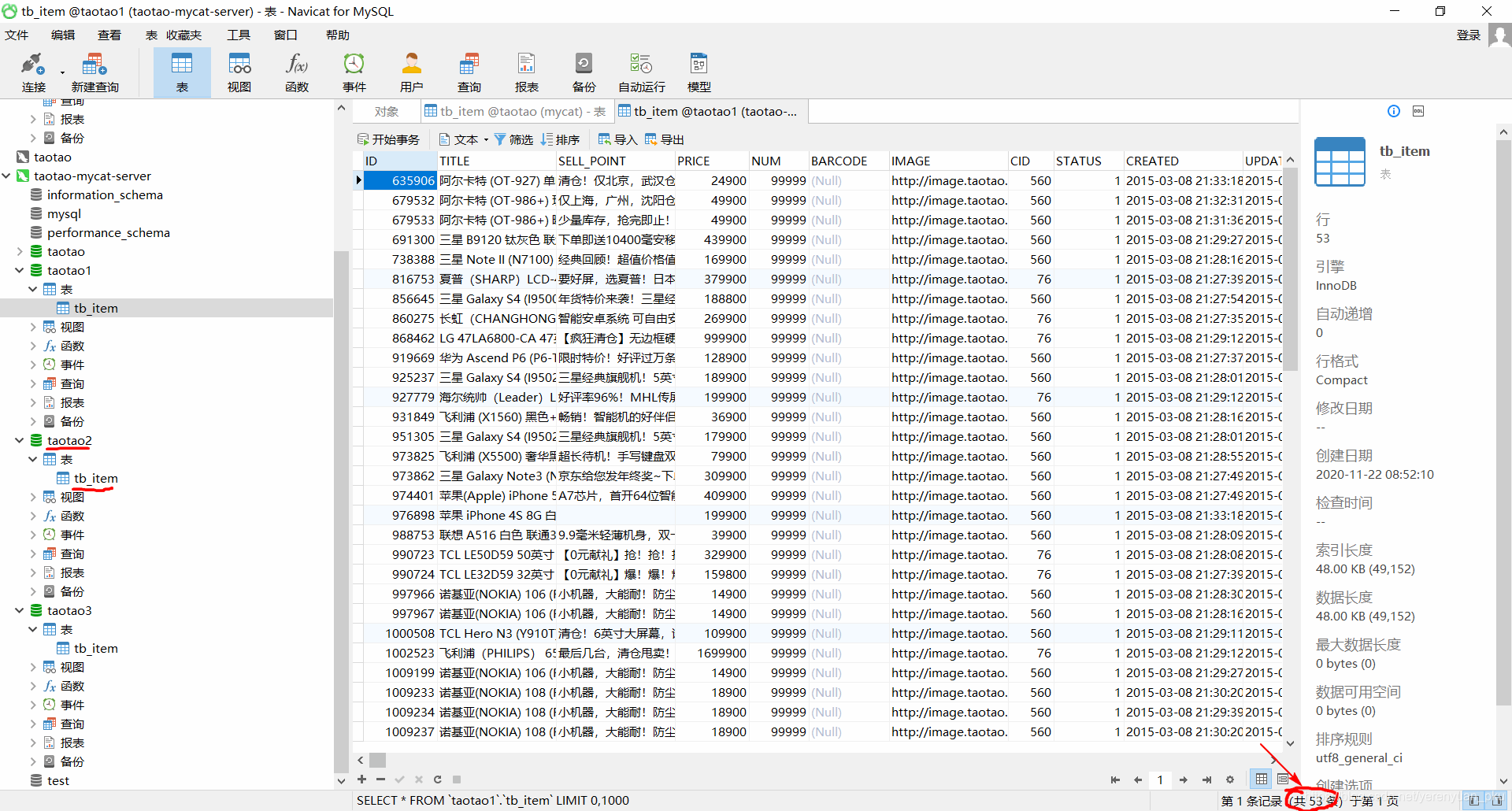
插入完之后,我们到taotao1、taotao2以及taotao3这三个数据库中进行查看,发现taotao1这个数据库中的tb_item表有了53条记录,之前是空的,如下图所示。
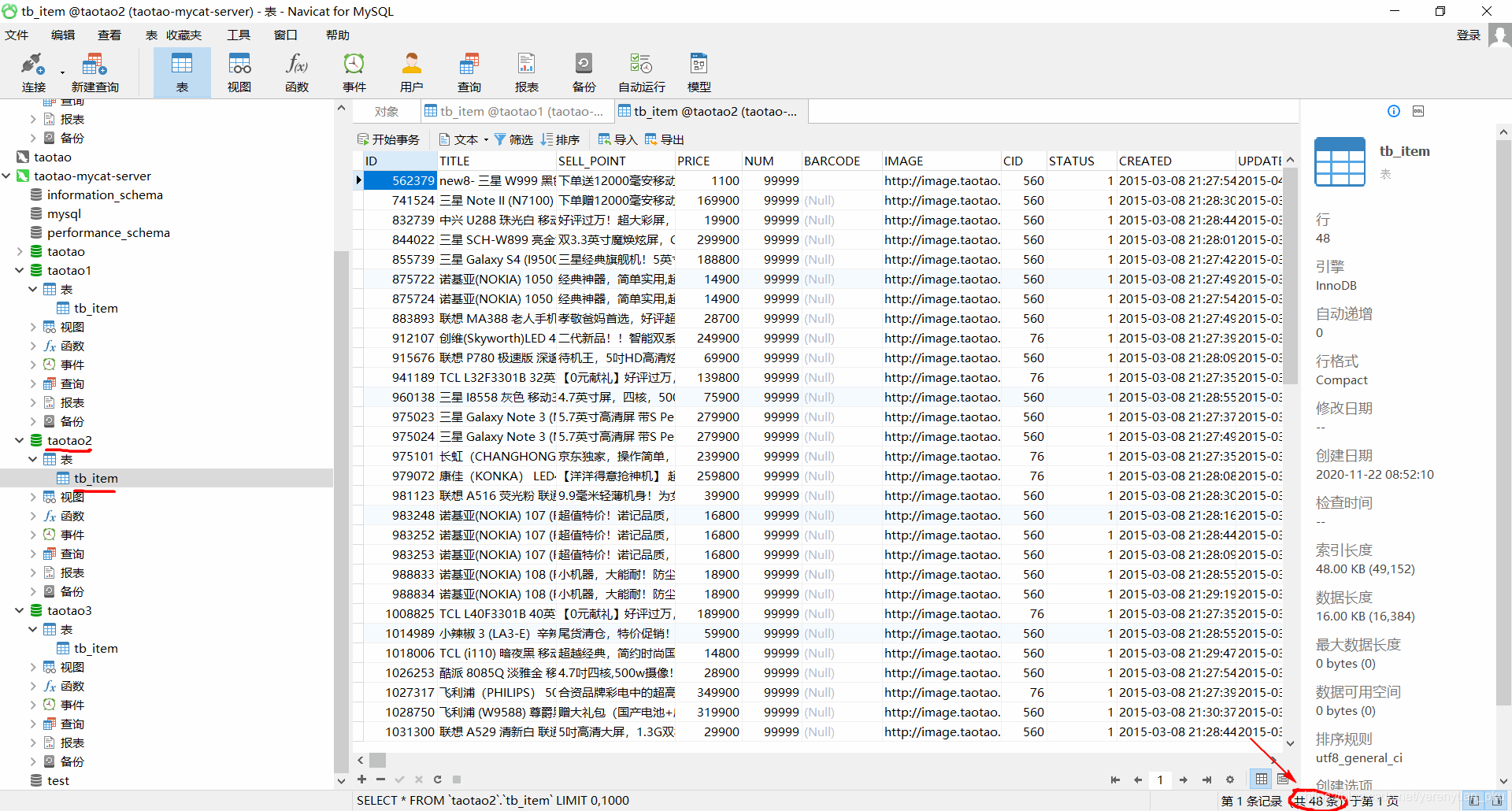
taotao2这个数据库中的tb_item表有了48条记录,之前是空的,如下图所示。
taotao3这个数据库中的tb_item表有了99条记录,之前是空的,如下图所示。
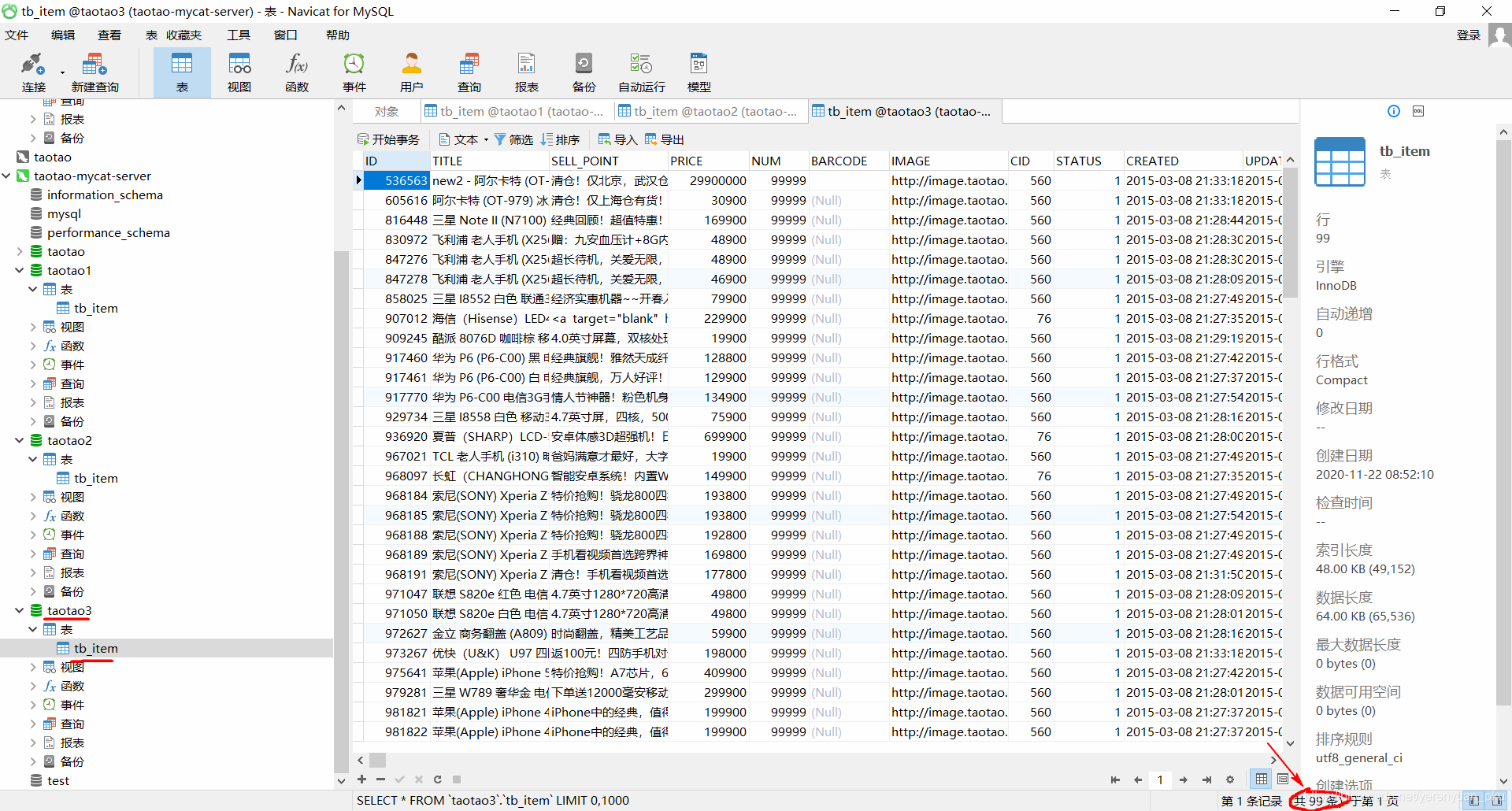
以上三张表中的记录数加起来总共有200条,刚刚好是我们往taotao数据库中的tb_item这张表中插入的总记录数。这已然说明了我们的分片是没任何问题的。
这篇关于淘淘商城第115讲——使用Mycat实现分库分表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



