本文主要是介绍机器学习:数据处理基操,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在处理完数据之后,选择好模型,就可以用训练集训练模型,用测试集输入模型 然后输出需要预测的结果啦~
一、模块导入
import numpy as np
import pandas as pd #读入数据二、pandas数据
一、dataframe基础
一、dataframe的创建
- 通过字典来创建DataFrame
字典的键值表示列号,value用列表格式,表示该列的行数据。
外层key做列索引,内层key做行索引
persons = {'name': ['小睿', '小丽', '小明', '小红'],'age': [19, 18, 18, 17],'sex': ['男', '男', '女', '男'], } # 字典的key作为列索引 data_frame1 =pd.DataFrame(persons)

二、从csv中读入
pd.read_csv()有很多参数
raw_data=pd.read_csv(path,names=names,header=None,delim_whitespace=True)path指定文件路径,names指定列名,header指明csv文件中是否有列名,delim_whitespace、sep可以用来将同一列的数据分割成多列,usecols 可以选择数据中的列放入dataframe
names=['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS',
'RAD','TAX','PRTATIO','B','LSTAT','MEDV']
path='E:\Python项目程序\人工智能企业实训\housing.csv'
raw_data=pd.read_csv(path,names=names,header=None,delim_whitespace=True)
print(raw_df.head(3))#head用于读取多少行print(raw_df.describe())#按一列的来算
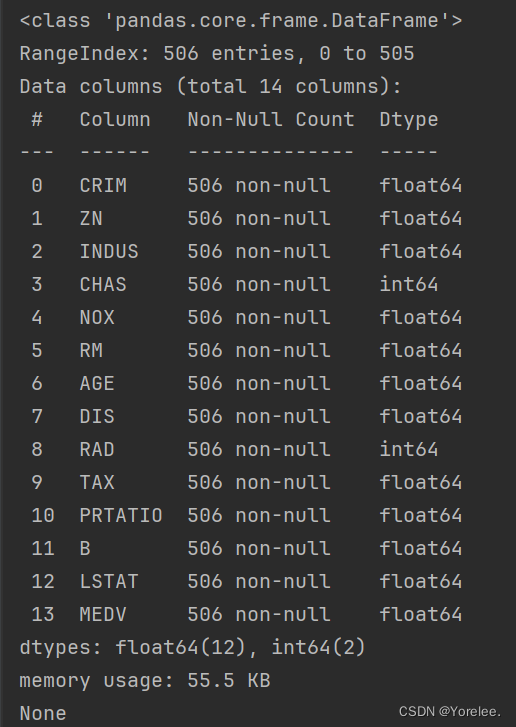
print(raw_df.info())#查看数据类型,如果有obj需要编码,最好用32类型的;也可以看是否存在空值三、数据探索
我们可以查看数据是否有空值,数据的均值方差等来查看数据的特征,如果数据存在空值,我们可能需要进行缺失值处理。查看数据特征和异常值还可以通过画图来观察到。
使用dataframe的数据基本信息
方法:
- head()
- describe()
- info()

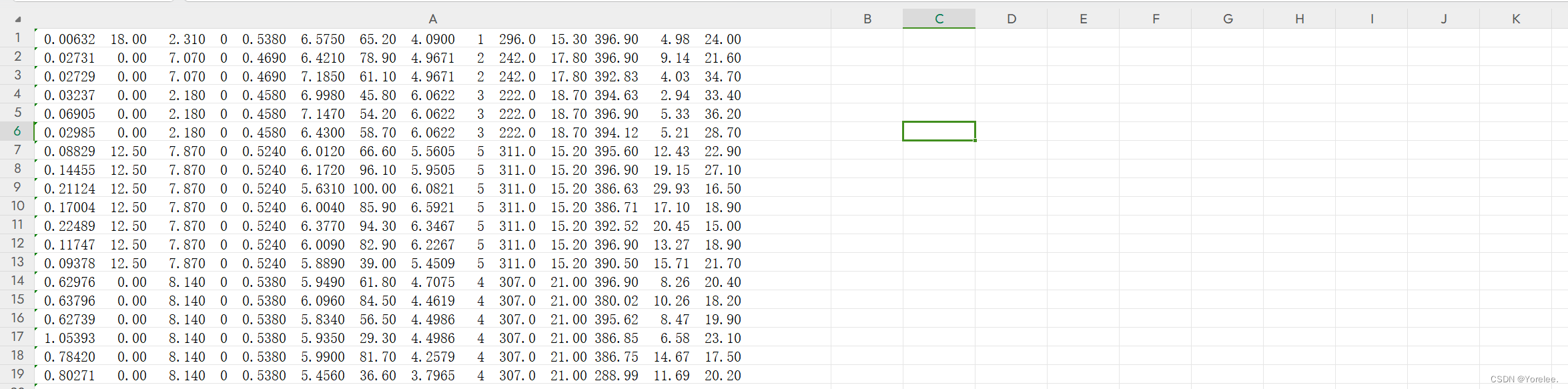
由于数据集在同一列中,并且没有列名,因此我们需要使用sep将一列中的多个数据拆开,由于没有列名,需要使用header=None:
import pandas as pd
names=['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PRTATIO','B','LSTAT','MEDV']
df=pd.read_csv('./dataset.csv',names=names,header=None,delim_whitespace=True)#默认是当前路径下的文件,如果没有names=names,则列名默认从0开始编号
print(df.head())注意:接下来的df全是这里用pd.read_csv()得到的。
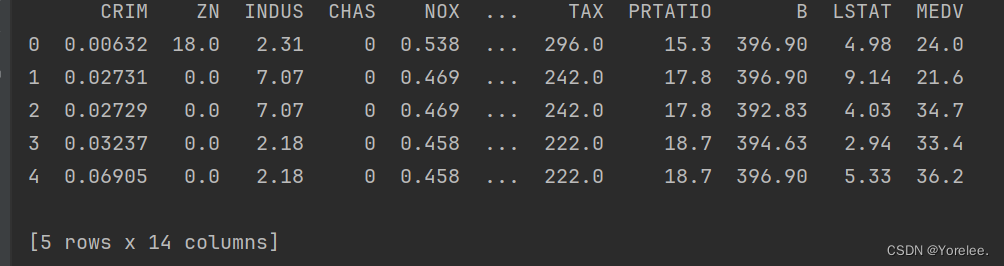
一、head方法(查看前n行)
- 输出dataframe中的前n行,标识出列名和行号
print(df.head())#默认输出数据前五行
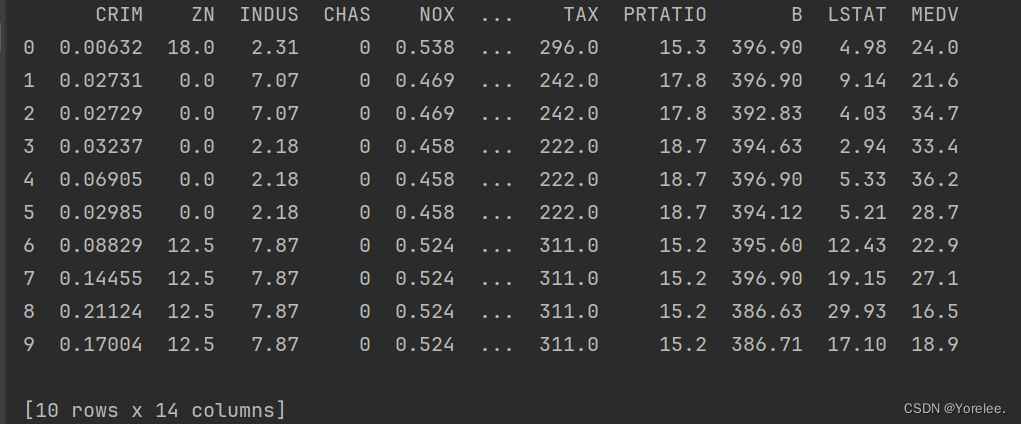
print(df.head(10))#输出数据前10行
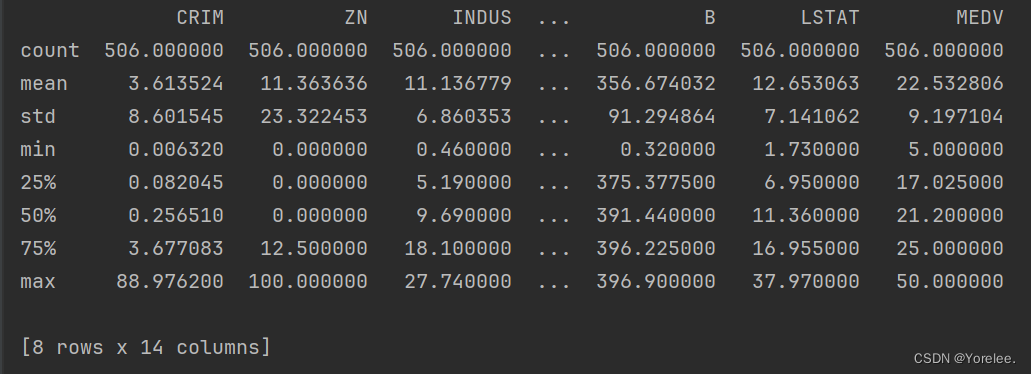
二、describe方法(查看列的数学统计)
- 输出dataframe中每一列的数学统计值。
print(df.describe())
它将打印每一列特征的个数,平均数,方差,最小值,最大值,以及箱型图中的25%、50%、75%。
三、info方法(查看空值和数据类型)
- 输出每一列是否存在空值,以及类型
print(df.info())
None被认为是空值
四、isnull方法(转换数据为是否为空)
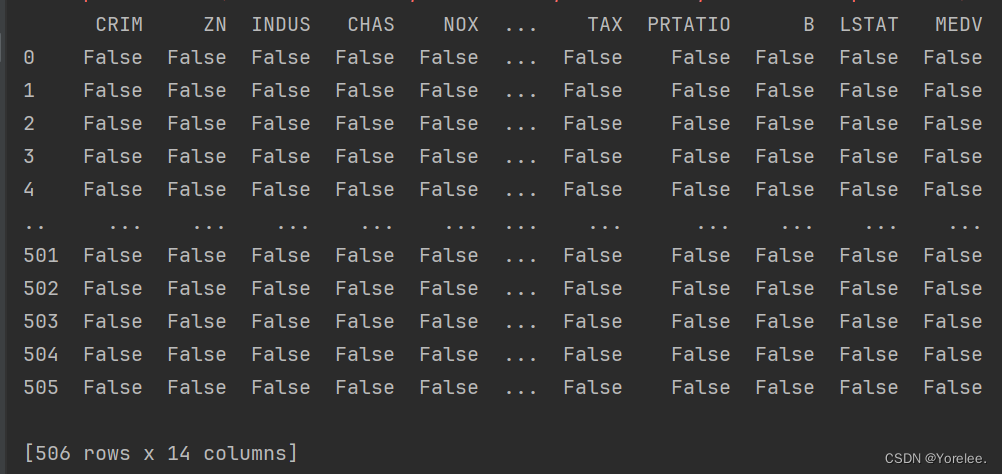
- 对每一个数据判断是否为空,不为空值为False(和notnull()方法相反)
- 搭配sum()方法可以直接找到空值个数
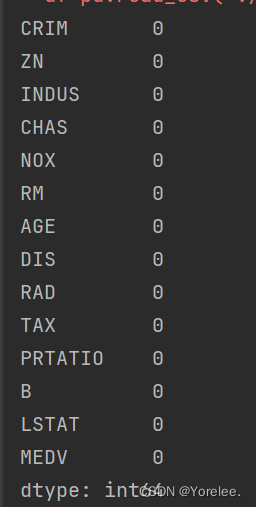
- df.isnull().sum() 每一列空值个数
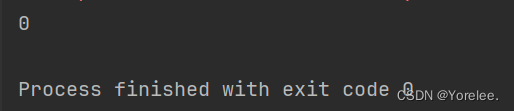
- df.isnull().sum().sum()数据中存在空值的个数
print(df.isnull())
print(df.isnull().sum())
sum()方法类似于数据库中的聚集函数,对每一列求总和,输出出来,返回的是一个Series类型。还可以再使用一次sum(),求出series中元素的总和。
print(df.isnull().sum().sum())
五、查看是否有空值
path='./data.csv'
df=pd.read_csv(path)print(df.isnull().sum())#输入每一列的空值个数
print(df.isnull().sum().sum())#输入总共的空值个数四、数据预处理
我们要将需要预测的数据,和训练数据合并之后再进行一起处理,因为输入模型的数据格式要相同。之前在查看空值时,也应该合并。
train_data = pd.read_csv( "./data./train.csv")
test_data = pd.read_csv( "./data./test.csv")
# 合并train, test
data = pd.concat([train_data, test_data], axis=0)#因为要对列进行统一处理
'''axis=0是指在y轴上合并,即按行合并'''一、缺失值处理
缺失值处理有很多种方式,这里只写两个。将这些方法当做类调用即可,不需要关注实现。调用之后直接使用被填充后的数据。

①IterativeImputer多变量缺失值填补
#df是df=pd.read_csv(path),从csv中读取到的文件,Dataframe格式 from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputerimp_mean = IterativeImputer(random_state=0)#random_state是随机种子 imp_mean.fit(df) filled_data =imp_mean.transform(df) '''filled_data和df的区别就是 filled_data是数据已经被填充了的,并且filled_data不是Dataframe类型'''save_df=pd.DataFrame(filled_data)#保存填充后的文件 csv_path='./IterativeImputer.csv' save_df.to_csv(csv_path,index=False)②KNNImputer K近邻缺失值填补
该方法是借助 包含缺失值数据附近的 其他特征和它最像的 n_neighbors个数据的 该特征值的平均值来填补缺失值的。
from sklearn.impute import KNNImputerimputer=KNNImputer(n_neighbors=2) df=pd.Dataframe(imputer.fit_transform(df))解释:
'''使用具有缺失值的样本的两个最近邻居的平均特征值替换编码为np.nan的缺失值:''' from sklearn.impute import KNNImputer data = [[2, 4, 8], [3, np.nan, 7], [5, 8, 3], [4, 3, 8]] imputer = KNNImputer(n_neighbors=1) imputer.fit_transform(data) '''可以看到,因为第二个样本的第一列特征3和第三列特征7,与第一行样本的第一列特征2和第三列特征8的欧氏距离最近,所以缺失值按照第一个样本来填充,填充值为4。那么n_neighbors=2呢?''' imputer = KNNImputer(n_neighbors=2) imputer.fit_transform(data) '''此时根据欧氏距离算出最近相邻的是第一行样本与第四行样本,此时的填充值就是这两个样本第二列特征4和3的均值:3.5。'''

二、数据标准化
一、最大最小值缩放
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler(feature_range=(0,1))
X1=scaler.fit_transform(df)
二、正态化数据
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler().fit(df)
X1=scaler.transform(df)
三、标准化数据(归一化)
Normalize Data 处理是将每一行数据的距离处理成1的数据,又叫归一化 适合处理稀疏数据(有很多0), 归一处理的数据对使用权重输入的神经网络和使用距离的K近邻准确度有显著提升
from sklearn.preprocessing import Normalizer
scaler=Normalizer().fit(df)
X1=transformer.transform(df)
三、数据编码、异常值处理
部分处理方式。日期需要特殊处理,对于一些值也可能需要进行数据清洗。
一、one-hot编码
data=data[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','TicketGroup']]
#上面
data=pd.get_dummies(data)#ont-hot编码二、标签编码
from sklearn.preprocessing import LabelEncoder
cat_columns = data.select_dtypes(include='O').columns
for col in cat_columns:le = LabelEncoder()data[col] = le.fit_transform(data[col])
'''对非数值特征进行标签编码,即非数值编码成0,1,2,3,4'''
'''A,B,C变成0,1,2这种'''
'''one-hot编码需要大量存储空间'''data.drop(['id'], axis=1, inplace=True)
train = data[data['label'].notnull()]
test = data[data['label'].isnull()].drop(['label'], axis=1)五、特征选择
PCA主成分分析法、递归特征消除RFE、多维标度法MDS等等。
一、随机森林重要性得分(有很多种方式)
from sklearn.ensemble import ExtraTreesClassifier
model=ExtraTreesClassifier()
fit=model.fit(X,y) #X是从train中抽出的特征,y是标签
print(fit.feature_importances_)
二、递归特征消除RFE
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
rfe=RFE(model,3)
fit=rfe.fit(X,y)
print('被选定的特征',fit.support_)
print('特征排名:',fit.ranking_)
六、划分训练测试集
正确做法:先划分数据集,再分别进行同样的特征选择,防止数据泄露。
因为测试集对于模型来说应该是“看不见”的,而对于计算特征得分,或者主成分分析,递归下降法等特征选择算法都需要对整个数据集进行考虑,因此为了使得测试集对于模型而言是完全未知的,就需要我们先将训练集和测试集分离之后,再分别用同样的方式进行特征选择。
注意这样即使是使用降维的特征选择也是不会有问题的。因为我们在划分出测试集时,是进行随机抽取的,换句话说,由于随机性,测试集也具有数据的代表性。
from sklearn.model_selection import train_test_split'''-----------------选出特征和标签------------------------''' #X选择特征列(一般不包含id号), Y选择标签列 X=raw_data.iloc[:,0:13]#dataframe 可以用iloc[行范围,列范围]选择特征列 Y=raw_data.iloc[:,13]#选择标签列'''----------划分训练集和测试集(如果没有可以测试模型得分的测试集时)------------''' x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.1,random_state=11) #按照test:train=0.1进行随机划分训练集和测试集 ,这里随机种子=11 #x_train -- y_train ; x_test -- y_test #将训练集进一步划分成训练集和验证集 x_train,x_val,y_train,y_val=train_test_split(x_train,y_train,test_size=0.1,random_state=11)#x_train 和 y_train作为输入用来进行模型训练。
七、绘图常用模块
import matplotlib.pyplot as plt
import seaborn as sns这篇关于机器学习:数据处理基操的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







