本文主要是介绍芯来科技发布最新NI系列内核,NI900矢量宽度可达512/1024位,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:芯来科技发布最新NI系列内核,NI900矢量宽度可达512/1024位 (qq.com)
本土RISC-V CPU IP领军企业——芯来科技正式发布首款针对人工智能应用的专用处理器产品线Nuclei Intelligence(NI)系列,以及NI系列的第一款AI专用RISC-V处理器CPU IP——NI900系列内核。
随着Chatgpt的横空出世,全球掀起一股AI的浪潮,从云端数据中心到边缘侧对AI的需求进一步提升。AI应用主要分布在训练和推理,需要大量的并行计算和NPU来完成,更离不开高性能CPU的算力加持。CPU有着广泛的普及性、兼容性、可扩展性和可靠性,并通过多核多节点进行串行计算、混合计算和安全防护等复杂任务;除此之外,CPU的通用矢量(Vector)指令集也可以提供强大且通用的并行计算能力,在AI领域进行高效的并行计算、前处理、后处理、激活函数等工作,更加灵活地处理GPU和NPU相对难以处理的复杂计算任务。
近期OpenAI发布的Sora模型将AI能够理解和生成的内容模态从文字和图片拓展到视频,进一步证明基础模型能力上限不断被突破,想象空间被打开,对算力基础设施的需求也远没有停止。芯来科技此次推出的NI900重点布局AI应用场景,助力本土芯片设计公司快速完成AI产品的设计。
NI900基于900系列处理器,针对“AI应用”进行了多项特性优化
Nuclei Intelligence —— NI900系列之于“AI应用”的优势
NI900基于Nuclei成熟的900系列处理器,针对“AI应用”进行了多项特性优化
NI900主要特性如下:
- 基础标量处理器:可以配置为900系列的RV32或RV64的任何一款——N900/U900/NX900/UX900
- RVV1.0 VPU:可配置基于RISC-V V Extension(RVV1.0 Vector指令集)的VPU单元,VPU的VLEN可配置为512b或者1024b
- 可配Per-Core-VPU:NI900支持Cluster内的每个Core均可以配置VPU
- 或可配多核共享Shared-VPU:NI900也可支持Cluster内的多个Core共享一份VPU单元
- NPU加速器:可通过NI900的IOCP(IO Coherent Port)与处理器紧耦合,实现对CPU内部Cache的一致性
- 用户自定义指令扩展接口:用户可以使用Nuclei的NICE硬件扩展接口,增加自己自定义的指令,包括Scalar或Vector指令

NI900支持RISC-V Vector1.0标准
- 矢量扩展被称之为RV指令集标准最重要的一组扩展,2015年发起,2021年正式生成标准。
- RVV 1.0支持的数据类型广泛,运算类型丰富且可动态扩展,同一套指令可无修改适配各种微架构实现。
- RISC-V GCC从10.2版本已经支持RVV1.0指令,目前GCC13对应的intrinsic API接口已经升级到最新v0.12版本,且已部分支持自动向量化;预计GCC14正式发布,GCC的自动向量化会更加完备。RISC-V CLANG17版本也已支持最新v0.12版本intrinsic APl, 支持自动向量化。
- RISC-V Linux 6.5 版本开始支持RVV,其它各种计算库及应用中间件都快速支持了RVV1.0。
- 有了RVV1.0标准和软件生态的完备,为应对AI算力的需求,需要RISC-V CPU 在微架构设计上做更多有针对性的设计。
Nuclei 900系列基础处理器
900系列处理器包括N900(32位)、U900(32位+MMU)、NX900(64位)和UX900(64位+MMU)四个产品系列,其中U900、UX900带MMU可以运行重型操作系统,如Linux等。900系列非常适合对标ARM Cortex-M7、A7、R8、A35、A53、A55等内核,可应用于AIoT边缘计算、数据中心、网络设备和基带通信等领域。

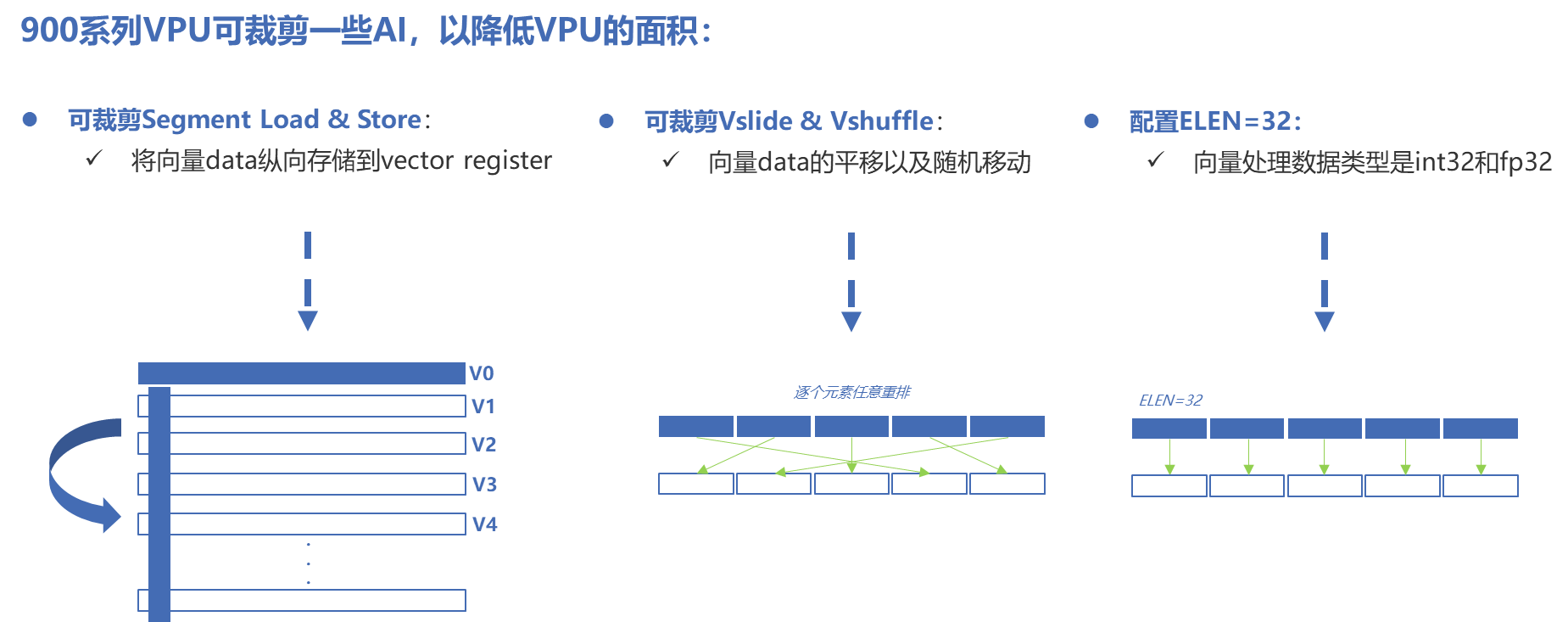
NI900的VPU可进行多种参数配置
参数描述
- VLEN:一个向量寄存器的总bit数(宽度)
- DLEN:内部运算单元能够并行处理的一个向量元素的最大bit数
- ELEN:并行处理的数据类型的最大宽度,如果ELEN=32,则最大的处理数据类型是INT32和FP32
| 可配选项 | 参数值 |
| VLEN_512 | VLEN = 512, DLEN = 512,ELEN = 32/64 |
| VLEN_1024 | VLEN = 1024, DLEN = 1024,ELEN = 32/64 |
NI900的VPU特性与配置
VPU特性:
- Follow RISC-V V Extension (RVV1.0) instruction set with 32 Vector registers
- Dual vector arithmetic computing pipeline and one Load/Store pipeline
- Vector registers can be combined (LMUL) up to VLEN*8bits vector operations
- Full Vector Load/Store memory operations
- Support Vector Instruction Chaining
VPU支持数据类型:
- Data type: INT8/16/32, BFP16/FP16/FP32
- 如果ELEN等于64的配置则也支持INT64与FP64


900系列双发射机制:
- Scalar标量部分:
- ALU指令,Ld/St指令,可以任意组合双发射
- 乘除、浮点以及DSP指令无法进行双发射,但是他们可以和ALU搭配进行双发射
- CSR/WFE/WFI等特殊指令只能单发射
- Vector矢量部分:
- Vector Ld/St,Vector A类型和Vector B类型可以两两组合双发射
- A类运算单元包含:
- vmul/vmac
- vfpu for single precesion
- B类运算单元包含:
- 除了上述A类指令和Vector Load Store指令之外的其他运算类型指令
- (可配置的)第二份vfpu vfadd/vfsub/vfmul/vfmac类型
- Example: Vector Ld/St + Vector A, Vector Ld/St + Vector B, Vector A + Vector B
- Scalar指令和Vector指令可以任意双发射
- Example: Vector Ld/St +ALU
- Scalar流水线和Vector流水线可以乱序执行
- Scalar和Vector共享内存资源(DCache,DLM,External Memory等)






NI900的功耗——Dhrystone与矩阵运算示例

NI900的VPU与主Core的内存空间实现完全的Coherent
- VPU和Core LSU共享MMU资源
- VPU并非独立的协处理器,而是与主Core的内存空间实现完全的Coherent
- Vector指令与普通Scalar一样,支持虚拟地址访问,使得NI900的Vector指令可以无缝运行与大型操作系统之上
- VPU和Core LSU共享Memory资源与通道
- VPU拥有最高512b位宽访问直接访问DCache
- VPU拥有最高1024b位宽访问直接访问DLM
- DLM具备1024b的Slave Port供SoC访问
- 可单独配置VLM port以进一步增加性能
- VLM port可以直接连接到外部加速器或者内存
- VLM port位宽=VLEN(目前支持最多1024b)
- Scalar Core也可以通过Load Store访问到VLM区间

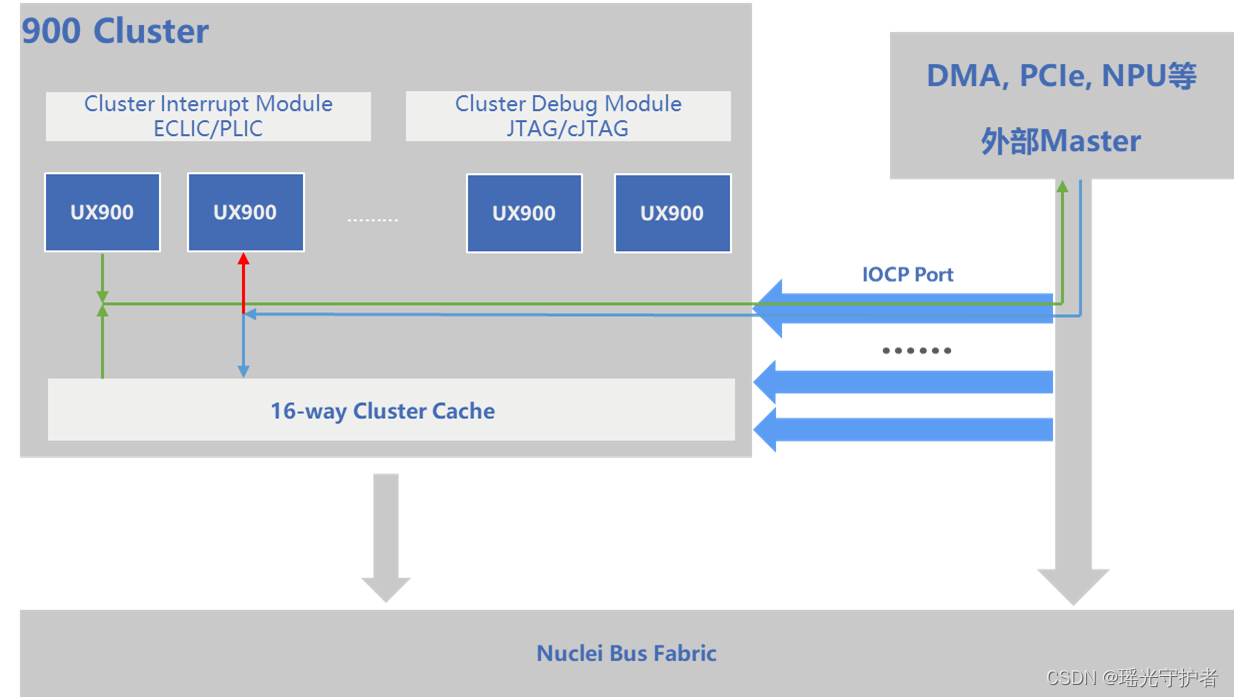
NI900的IOCP接口可用于连接硬件加速器单元
I/O Coherent Port (IOCP):
- 支持外部master和所有层级的缓存保持一致性
- 从IOCP读取:
- 从私有cache中获取数据
- 如果cache miss则将从系统级缓存获取数据
- 从IOCP写入:
- Invalidate所有私有缓存
- 写入系统级缓存
- IOCP接口数量可以进行配置
- IOCP可以被DMA, PCIe, NPU等外部master使用
NI900的Scalar/Vector NICE自定义指令接口
 NICE(Nuclei Instruction Co-unit Extension)是芯来CPU IP的一种用户可扩展指令接口机制,允许用户基于芯片的标准通用CPU内核定义自己的扩展指令集:
NICE(Nuclei Instruction Co-unit Extension)是芯来CPU IP的一种用户可扩展指令接口机制,允许用户基于芯片的标准通用CPU内核定义自己的扩展指令集:
- NI900提供用于Scalar指令扩展的NICE接口
- 可支持单周期,多周期,流水线等不同指令类型
- NI900提供用于Vector指令扩展的NICE接口
- 可支持单周期,多周期,流水线等不同指令类型
- NI900的NICE扩展单元不仅可以进行运算型的自定义指令扩展,还可以通过专用总线访问Core的存储资源(DCache等)实现与主Core的内存一致性
- 总线位宽可以达到VLEN(最高1024b)
用户可以结合自己的应用扩展自定义指令,将NI900处理器内核扩展成为面向AI领域进一步强化的专用处理器
NI900系列NICE示例 – 通过Vector NICE扩展其私有的访存通路

图例解释如下:
- 可以通过Vector NICE机制扩展“用户自定义的硬件单元”
- 该“硬件单元”可以拥有其私有的访存通路,图例中称为VNP(Vector Nice Port)
- 外部可以有一个多Banks或多Ports的Memory模块
- 该VNP Port可以直接接到外部的Memory模块
- Core的VLM Port也可以直接接到外部的Memory模块
- 来自系统内其他AI加速器的读写Port也可以直接接到外部的Memory模块
- 用户可以在该“硬件单元”中扩展一条VNP_Load指令
- 该VPN_Load指令可以从VNP Port批量读出数据写入标准Vector Regfile
- 可以使用标量寄存器rs1作为基地址, Vector寄存器作为结果寄存器
- 用户可以在该“硬件单元”中扩展一条VNP_Store指令
- 该VNP_Store指令可以将标准Vector Regfile中的数据批量写出VNP Port
- 可以使用标量寄存器rs1作为基地址, Vector寄存器作为源操作数寄存器
- 标准的VLoad/Store指令和VNP_Load/Store可以同时并行访问,如下列伪代码程序序列所示
- VLoad V7~V0 mem[VLM] #从VLM地址区间读数据写入V0到V7八个Vector Registers
- VEXU V15~V8,V7~V0,rs1 #对V0到V7八个Vector Registers的数据进行Vector计算,结果写入V8到V15八个Vector Registers
- VNP_Store V15~V8 mem[VNP] #将V8到V15八个Vector Registers写出VNP地址区间

这篇关于芯来科技发布最新NI系列内核,NI900矢量宽度可达512/1024位的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





