本文主要是介绍机器学习实战笔记9—人工神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:此系列文章里的部分算法和深度学习笔记系列里的内容有重合的地方,深度学习笔记里是看教学视频做的笔记,此处文章是看《机器学习实战》这本书所做的笔记,虽然算法相同,但示例代码有所不同,多敲一遍没有坏处,哈哈。(里面用到的数据集、代码可以到网上搜索,很容易找到。)。Python版本3.6
机器学习十大算法系列文章:
机器学习实战笔记1—k-近邻算法
机器学习实战笔记2—决策树
机器学习实战笔记3—朴素贝叶斯
机器学习实战笔记4—Logistic回归
机器学习实战笔记5—支持向量机
机器学习实战笔记6—AdaBoost
机器学习实战笔记7—K-Means
机器学习实战笔记8—随机森林
机器学习实战笔记9—人工神经网络
此系列源码在我的GitHub里:https://github.com/yeyujujishou19/Machine-Learning-In-Action-Codes
一,算法原理:
实例推导可以看我之前写的这篇文章:深度学习基础课程1笔记-神经网络算法(ANN)
1.1 前言
神经网络是一门重要的机器学习技术。它是目前最为火热的研究方向--深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。
让我们来看一个经典的神经网络。这是一个包含三个层次的神经网络。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。
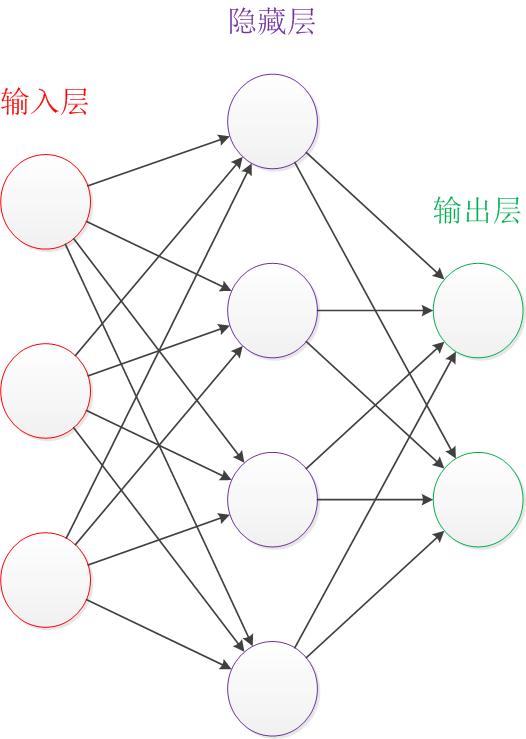
在开始介绍前,有一些知识可以先记在心里:
- 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
- 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
- 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
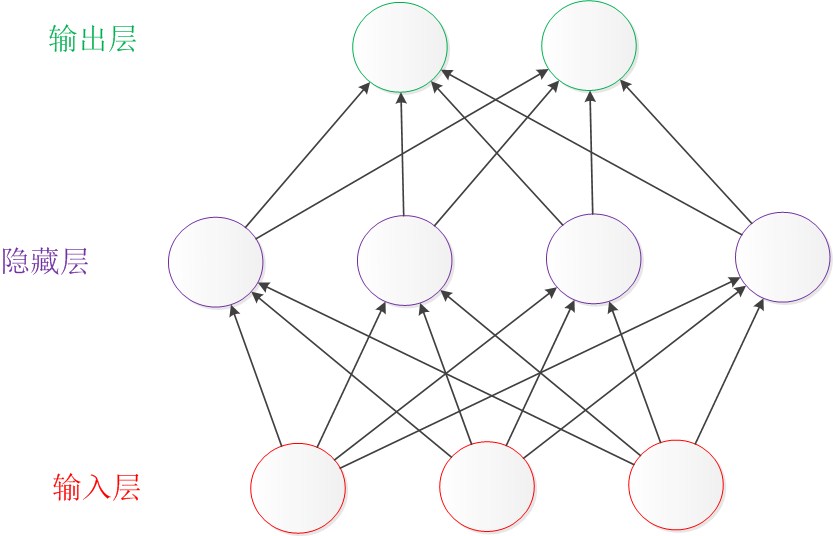
除了从左到右的形式表达的结构图,还有一种常见的表达形式是从下到上来表示一个神经网络。这时候,输入层在图的最下方。输出层则在图的最上方,如下图:
1.2 神经元
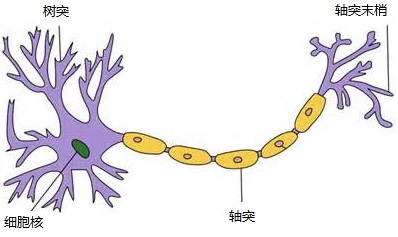
对于神经元的研究由来已久,1904年生物学家就已经知晓了神经元的组成结构。
一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。
人脑中的神经元形状可以用下图做简单的说明:
神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。
下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能。
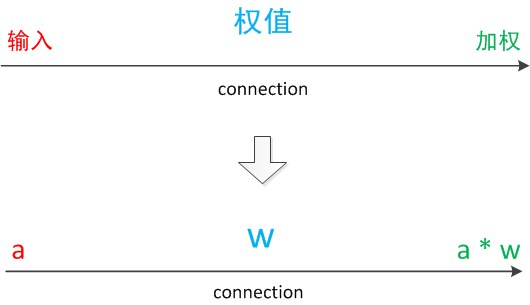
注意中间的箭头线。这些线称为“连接”。每个上有一个“权值”。

连接是神经元中最重要的东西。每一个连接上都有一个权重。
一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
我们使用a来表示输入,用w来表示权值。一个表示连接的有向箭头可以这样理解:在初端,传递的信号大小仍然是a,端中间有加权参数w,经过这个加权后的信号会变成a*w,因此在连接的末端,信号的大小就变成了a*w。
在其他绘图模型里,有向箭头可能表示的是值的不变传递。而在神经元模型里,每个有向箭头表示的是值的加权传递。
如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图。
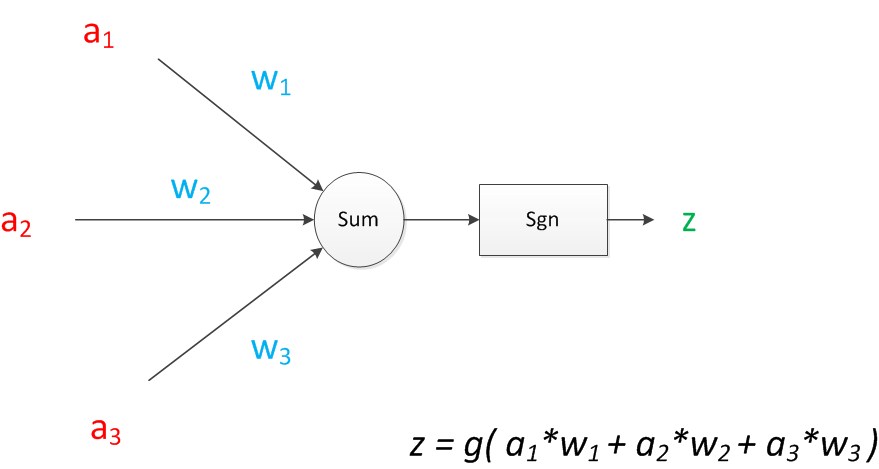
可见z是在输入和权值的线性加权和叠加了一个函数g的值。在MP模型里,函数g是sgn函数,也就是取符号函数。这个函数当输入大于0时,输出1,否则输出0。
下面对神经元模型的图进行一些扩展。首先将sum函数与sgn函数合并到一个圆圈里,代表神经元的内部计算。其次,把输入a与输出z写到连接线的左上方,便于后面画复杂的网络。最后说明,一个神经元可以引出多个代表输出的有向箭头,但值都是一样的。
神经元可以看作一个计算与存储单元。计算是神经元对其的输入进行计算功能。存储是神经元会暂存计算结果,并传递到下一层。

当我们用“神经元”组成网络以后,描述网络中的某个“神经元”时,我们更多地会用“单元”(unit)来指代。同时由于神经网络的表现形式是一个有向图,有时也会用“节点”(node)来表达同样的意思。
具体的可以看看原文和我另一篇文章,这里就不多说了。
上面的理论内容参考的这篇文章:https://www.cnblogs.com/ranjiewen/p/6115272.html
二,算法的优缺点:
优点:
- 分类的准确度高,
- 并行分布处理能力强,
- 分布存储及学习能力强,
- 对噪声神经有较强的鲁棒性和容错能力,
- 能充分逼近复杂的非线性关系,
- 具备联想记忆的功能等。
缺点:
- 神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;
- 不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;
- 学习时间过长,甚至可能达不到学习的目的。
三,实例代码:
这部分代码是工作中用到的,利用ANN对OCR进行分类。
3.1 多进程读图提取特征存npy
import multiprocessing
import os, time, random
import numpy as np
import cv2
import os
import sys
from time import ctime# image_dir = r"D:/sxl/处理图片/汉字分类/train85/" #图像文件夹路径
image_dir = r"E:/2万汉字分类/train21477/" #图像文件夹路径
# image_dir = r"D:/sxl/处理图片/汉字分类/train85/" #图像文件夹路径
data_type = 'test'
save_path = r'E:/sxl_Programs/Python/ANN/npy3/' #存储路径
data_name = 'Img21477' #npy文件名char_set = np.array(os.listdir(image_dir)) #文件夹名称列表
np.save(save_path+'ImgHanZiName21477.npy',char_set) #文件夹名称列表
char_set_n = len(char_set) #文件夹列表长度read_process_n = 4 #进程数
repate_n = 4 #随机移动次数
data_size = 1000000 #1个npy大小shuffled = True #是否打乱#可以读取带中文路径的图
def cv_imread(file_path,type=0):cv_img=cv2.imdecode(np.fromfile(file_path,dtype=np.uint8),-1)# print(file_path)# print(cv_img.shape)# print(len(cv_img.shape))if(type==0):if(len(cv_img.shape)==3):cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)return cv_img#多个数组按同一规则打乱数据
def ShuffledData(features,labels):'''@description:随机打乱数据与标签,但保持数据与标签一一对应@author:RenHui'''permutation = np.random.permutation(features.shape[0])shuffled_features = features[permutation,:] #多维shuffled_labels = labels[permutation] #1维return shuffled_features,shuffled_labels#叠加两张图片,输入皆是黑白图,img1是底层图片,img2是上层图片,返回叠加后的图片
def ImageOverlay(img1,img2):# 把logo放在左上角,所以我们只关心这一块区域h = img1.shape[0]w = img1.shape[1]rows = img2.shape[0]cols = img2.shape[1]roi = img1[int((h - rows) / 2):rows + int((h - rows) / 2), int((w - cols) / 2):cols + int((w - cols) / 2)]# 创建掩膜img2gray = img2.copy()ret, mask = cv2.threshold(img2gray, 0, 255, cv2.THRESH_OTSU)mask_inv = cv2.bitwise_not(mask)# 保留除logo外的背景img1_bg = cv2.bitwise_and(roi, roi, mask=mask)dst = cv2.add(img1_bg, img2) # 进行融合img1[int((h - rows) / 2):rows + int((h - rows) / 2),int((w - cols) / 2):cols + int((w - cols) / 2)] = dst # 融合后放在原图上return img1#函数功能:处理白边
#找到上下左右的白边位置
#剪切掉白边
#二值化
#将图像放到64*64的白底图像中心
def HandWhiteEdges(img):ret, thresh1 = cv2.threshold(img, 249, 255, cv2.THRESH_BINARY)# OpenCV定义的结构元素kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))# 膨胀图像thresh1 = cv2.dilate(thresh1, kernel)row= img.shape[0]col = img.shape[1]tempr0 = 0 #横上tempr1 = 0 #横下tempc0 = 0 #竖左tempc1 = 0 #竖右# 765 是255+255+255,如果是黑色背景就是0+0+0,彩色的背景,将765替换成其他颜色的RGB之和,这个会有一点问题,因为三个和相同但颜色不一定同for r in range(0, row):if thresh1.sum(axis=1)[r] != 255 * col:tempr0 = rbreakfor r in range(row - 1, 0, -1):if thresh1.sum(axis=1)[r] != 255 * col:tempr1 = rbreakfor c in range(0, col):if thresh1.sum(axis=0)[c] != 255 * row:tempc0 = cbreakfor c in range(col - 1, 0, -1):if thresh1.sum(axis=0)[c] != 255 * row:tempc1 = cbreak# 创建全白图片imageTemp = np.zeros((64, 64, 3), dtype=np.uint8)imageTemp = cv2.cvtColor(imageTemp, cv2.COLOR_BGR2GRAY)imageTemp.fill(255)if(tempr1-tempr0==0 or tempc1-tempc0==0): #空图return imageTemp #返回全白图new_img = img[tempr0:tempr1, tempc0:tempc1]#二值化retval,binary = cv2.threshold(new_img,0,255,cv2.THRESH_OTSU)#叠加两幅图像rstImg=ImageOverlay(imageTemp, binary)return rstImg#函数功能:简单网格
#函数要求:1.无关图像大小;2.输入图像默认为灰度图;3.参数只有输入图像
#返回数据:64*1维特征
def SimpleGridFeature(image):'''@description:提取字符图像的简单网格特征@image:灰度字符图像@return:长度为64字符图像的特征向量feature@author:RenHui'''new_img=HandWhiteEdges(image) #白边处理#new_img=image#图像大小归一化image = cv2.resize(new_img,(64,64))img_h = image.shape[0]img_w = image.shape[1]#二值化retval,binary = cv2.threshold(image,0,255,cv2.THRESH_OTSU)#定义特征向量grid_size1 = 16grid_size2 = 8grid_size3 = 4feature = np.zeros(grid_size1*grid_size1+grid_size2*grid_size2+grid_size3*grid_size3,dtype=np.int16)#计算网格大小1grid_h1 = binary.shape[0]/grid_size1grid_w1 = binary.shape[1]/grid_size1for j in range(grid_size1):for i in range(grid_size1):grid = binary[int(j*grid_h1):int((j+1)*grid_h1),int(i*grid_w1):int((i+1)*grid_w1)]feature[j*grid_size1+i] = grid[grid==0].size#计算网格大小2grid_h2 = binary.shape[0]/grid_size2grid_w2 = binary.shape[1]/grid_size2for j in range(grid_size2):for i in range(grid_size2):grid = binary[int(j*grid_h2):int((j+1)*grid_h2),int(i*grid_w2):int((i+1)*grid_w2)]feature[grid_size1*grid_size1+j*grid_size2+i] = grid[grid==0].size#计算网格大小3grid_h3 = binary.shape[0]/grid_size3grid_w3 = binary.shape[1]/grid_size3for j in range(grid_size3):for i in range(grid_size3):grid = binary[int(j*grid_h3):int((j+1)*grid_h3),int(i*grid_w3):int((i+1)*grid_w3)]feature[grid_size1*grid_size1+grid_size2*grid_size2+j*grid_size3+i] = grid[grid==0].sizereturn feature#随机移动图像,黑白图
def randomMoveImage(img):img_h = img.shape[0]img_w = img.shape[1]# 0 上,1 下,2 左,3 右idirection=random.randrange(0, 4) #随机产生0,1,2,3#随机移动距离iPixsNum=random.randrange(1, 3) #随机产生1,2if (idirection == 0): #上# 平移矩阵M:[[1,0,x],[0,1,y]]M = np.float32([[1, 0, 0], [0, 1, -iPixsNum]])dst = cv2.warpAffine(img, M, (img_w, img_h))for h in range(iPixsNum): # 从上到下for w in range(img_w): # 从左到右dst[img_h-h-1, w] = 255if (idirection == 1): #下# 平移矩阵M:[[1,0,x],[0,1,y]]M = np.float32([[1, 0, 0], [0, 1, iPixsNum]])dst = cv2.warpAffine(img, M, (img_w, img_h))for h in range(iPixsNum): # 从上到下for w in range(img_w): # 从左到右dst[h, w] = 255if (idirection == 2): #左# 平移矩阵M:[[1,0,x],[0,1,y]]M = np.float32([[1, 0, -iPixsNum], [0, 1, 0]])dst = cv2.warpAffine(img, M, (img_w, img_h))for w in range(iPixsNum): # 从左到右for h in range(img_h): # 从上到下dst[h, img_w - w - 1] = 255if (idirection == 3): #右# 平移矩阵M:[[1,0,x],[0,1,y]]M = np.float32([[1, 0, iPixsNum], [0, 1, 0]])dst = cv2.warpAffine(img, M, (img_w, img_h))for w in range(iPixsNum): # 从左到右for h in range(img_h): # 从上到下dst[h, w] = 255return dst# 写数据进程执行的代码:
def read_image_to_queue(queue):print('Process to write: %s' % os.getpid())for j,dirname in enumerate(char_set): # dirname 是文件夹名称label = np.where(char_set==dirname)[0][0] #文件夹名称对应的下标序号print('序号:'+str(j),'读 '+dirname+' 文件夹...时间:',ctime() )for parent,_,filenames in os.walk(os.path.join(image_dir,dirname)):for filename in filenames:if(filename[-4:]!='.jpg'):continueimage = cv_imread(os.path.join(parent,filename),0)# cv2.imshow(dirname,image)# cv2.waitKey(0)queue.put((image,label))for i in range(read_process_n):queue.put((None,-1))print('读图结束!')return True# 读数据进程执行的代码:
def extract_feature(queue,lock,count):'''@description:从队列中取出图片进行特征提取@queue:先进先出队列lock:锁,在计数时上锁,防止冲突count:计数'''print('Process %s start reading...' % os.getpid())global data_nfeatures = [] #存放提取到的特征labels = [] #存放标签flag = True #标志着进程是否结束while flag:image,label = queue.get() #从队列中获取图像和标签if len(features) >= data_size or label == -1: #特征数组的长度大于指定长度,则开始存储array_features = np.array(features) #转换成数组array_labels = np.array(labels)array_features,array_labels = ShuffledData(array_features,array_labels) #打乱数据lock.acquire() # 锁开始# 拆分数据为训练集,测试集split_x = int(array_features.shape[0] * 0.8)train_data, test_data = np.split(array_features, [split_x], axis=0) # 拆分特征数据集train_labels, test_labels = np.split(array_labels, [split_x], axis=0) # 拆分标签数据集count.value += 1 #下标计数加1str_features_name_train = data_name+'_features_train_'+str(count.value)+'.npy'str_labels_name_train = data_name+'_labels_train_'+str(count.value)+'.npy'str_features_name_test = data_name+'_features_test_'+str(count.value)+'.npy'str_labels_name_test = data_name+'_labels_test_'+str(count.value)+'.npy'lock.release() # 锁释放np.save(save_path+str_features_name_train,train_data)np.save(save_path+str_labels_name_train,train_labels)np.save(save_path+str_features_name_test,test_data)np.save(save_path+str_labels_name_test,test_labels)print(os.getpid(),'save:',str_features_name_train)print(os.getpid(),'save:',str_labels_name_train)print(os.getpid(),'save:',str_features_name_test)print(os.getpid(),'save:',str_labels_name_test)features.clear()labels.clear()if label == -1:break# 获取特征向量,传入灰度图feature = SimpleGridFeature(image) # 简单网格features.append(feature)labels.append(label)# # 随机移动4次# for itime in range(repate_n):# rMovedImage = randomMoveImage(image)# feature = SimpleGridFeature(rMovedImage) # 简单网格# features.append(feature)# labels.append(label)print('Process %s is done!' % os.getpid())if __name__=='__main__':time_start = time.time() # 开始计时# 父进程创建Queue,并传给各个子进程:image_queue = multiprocessing.Queue(maxsize=1000) #队列lock = multiprocessing.Lock() #锁count = multiprocessing.Value('i',0) #计数#将图写入队列进程write_sub_process = multiprocessing.Process(target=read_image_to_queue, args=(image_queue,))read_sub_processes = [] #读图子线程for i in range(read_process_n):read_sub_processes.append(multiprocessing.Process(target=extract_feature, args=(image_queue,lock,count)))# 启动子进程pw,写入:write_sub_process.start()# 启动子进程pr,读取:for p in read_sub_processes:p.start()# 等待进程结束:write_sub_process.join()for p in read_sub_processes:p.join()time_end=time.time()time_h=(time_end-time_start)/3600print('用时:%.6f 小时'% time_h)print ("读图提取特征存npy,运行结束!")3.2 读取npy文件,利用ANN训练模型
#!/usr/bin/env python
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
import cv2
import math
from math import ceil #向上取整
import time
import os
import random
import gc #释放内存
import tensorflow as tf
from tensorflow.python.framework import graph_utillogdir='./model/'#全局变量
inpyNUM = 8 # npy文件数量
n_fc1 = 672 #第一层隐藏层神经元个数
n_fc2 = 336 #第二层隐藏层神经元个数
n_feature = 336 #特征维度
n_label = 21477 #标签维度
# learning_rate = 1e-4 #学习率
batch_size = 5000 #最小数据集大小
training_iters = 20000 #训练次数
test_step = 1000 #测试数据步长
display_step = 100 #显示数据步长 100
MODEL_SAVE_PATH=r"./model/"
MODEL_NAME="ANN_model_21477"
#指数衰减型学习率
LEARNING_RATE_BASE=1e-4 #最初学习率
LEARNING_RATE_DECAY=0.5 #学习率衰减率
LEARNING_RATE_STEP=10000 #喂入多少轮BATCH_SIZE后,更新一次学习率,一般为总样本数/batch_size#############################################################################多个数组按同一规则打乱数据
def ShuffledData(features,labels):'''@description:随机打乱数据与标签,但保持数据与标签一一对应'''permutation = np.random.permutation(features.shape[0])shuffled_features = features[permutation,:]shuffled_labels = labels[permutation]return shuffled_features,shuffled_labels#叠加两张图片,输入皆是黑白图,img1是底层图片,img2是上层图片,返回叠加后的图片
def ImageOverlay(img1,img2):# 把logo放在左上角,所以我们只关心这一块区域h = img1.shape[0]w = img1.shape[1]rows = img2.shape[0]cols = img2.shape[1]roi = img1[int((h - rows) / 2):rows + int((h - rows) / 2), int((w - cols) / 2):cols + int((w - cols) / 2)]# 创建掩膜img2gray = img2.copy()ret, mask = cv2.threshold(img2gray, 0, 255, cv2.THRESH_OTSU)mask_inv = cv2.bitwise_not(mask)# 保留除logo外的背景img1_bg = cv2.bitwise_and(roi, roi, mask=mask)dst = cv2.add(img1_bg, img2) # 进行融合img1[int((h - rows) / 2):rows + int((h - rows) / 2),int((w - cols) / 2):cols + int((w - cols) / 2)] = dst # 融合后放在原图上return img1# 处理白边
#找到上下左右的白边位置
#剪切掉白边
#二值化
#将图像放到64*64的白底图像中心
def HandWhiteEdges(img):ret, thresh1 = cv2.threshold(img, 249, 255, cv2.THRESH_BINARY)# OpenCV定义的结构元素kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))# 膨胀图像thresh1 = cv2.dilate(thresh1, kernel)row= img.shape[0]col = img.shape[1]tempr0 = 0 #横上tempr1 = 0 #横下tempc0 = 0 #竖左tempc1 = 0 #竖右# 765 是255+255+255,如果是黑色背景就是0+0+0,彩色的背景,将765替换成其他颜色的RGB之和,这个会有一点问题,因为三个和相同但颜色不一定同for r in range(0, row):if thresh1.sum(axis=1)[r] != 255 * col:tempr0 = rbreakfor r in range(row - 1, 0, -1):if thresh1.sum(axis=1)[r] != 255 * col:tempr1 = rbreakfor c in range(0, col):if thresh1.sum(axis=0)[c] != 255 * row:tempc0 = cbreakfor c in range(col - 1, 0, -1):if thresh1.sum(axis=0)[c] != 255 * row:tempc1 = cbreak# 创建全白图片imageTemp = np.zeros((64, 64, 3), dtype=np.uint8)imageTemp = cv2.cvtColor(imageTemp, cv2.COLOR_BGR2GRAY)imageTemp.fill(255)if(tempr1-tempr0==0 or tempc1-tempc0==0): #空图return imageTemp #返回全白图new_img = img[tempr0:tempr1, tempc0:tempc1]#二值化retval,binary = cv2.threshold(new_img,0,255,cv2.THRESH_OTSU)#叠加两幅图像rstImg=ImageOverlay(imageTemp, binary)return rstImg#字符图像的特征提取方法
#要求:1.无关图像大小;2.输入图像默认为灰度图;3.参数只有输入图像
def SimpleGridFeature(image):'''@description:提取字符图像的简单网格特征@image:灰度字符图像@return:长度为64字符图像的特征向量feature'''new_img = HandWhiteEdges(image) # 白边处理#图像大小归一化image = cv2.resize(new_img,(64,64))img_h = image.shape[0]img_w = image.shape[1]#二值化retval,binary = cv2.threshold(image,0,255,cv2.THRESH_OTSU)#计算网格大小grid_size=16grid_h = binary.shape[0]/grid_sizegrid_w = binary.shape[1]/grid_size#定义特征向量feature = np.zeros(grid_size*grid_size)for j in range(grid_size):for i in range(grid_size):grid = binary[int(j*grid_h):int((j+1)*grid_h),int(i*grid_w):int((i+1)*grid_w)]feature[j*grid_size+i] = grid[grid==0].sizereturn feature#可以读取带中文路径的图
def cv_imread(file_path,type=0):cv_img=cv2.imdecode(np.fromfile(file_path,dtype=np.uint8),-1)# print(file_path)# print(cv_img.shape)# print(len(cv_img.shape))if(type==0):if(len(cv_img.shape)==3):cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)return cv_img#预测函数
def prediction(logits):with tf.name_scope('prediction'):pred = tf.argmax(logits,1)return pred
#############################################################################将数据集和标签分成小块
def gen_batch(data,labels,batch_size):global flag #全局标记位if(flag+batch_size>data.shape[0]):flag = 0#最后一个batch_size从末尾向前取数据data_batch = data[data.shape[0]-batch_size:data.shape[0]]labels_batch = labels[data.shape[0]-batch_size:data.shape[0]]return data_batch, labels_batchdata_batch = data[flag:flag+batch_size]labels_batch = labels[flag:flag+batch_size]flag = flag+batch_sizereturn data_batch,labels_batch# w,b
def weight_variable(layer,shape,stddev,name):with tf.name_scope(layer): #该函数返回用于定义 Python 操作系统的上下文管理器,生成名称范围。return tf.Variable(tf.truncated_normal(shape,stddev=stddev,name=name))
def bias_variable(layer, value, dtype, shape, name):with tf.name_scope(layer):return tf.Variable(tf.constant(value, dtype=dtype, shape=shape, name=name))#前向计算
def inference(features):# 计算第一层隐藏层 a=x*w+bwith tf.name_scope('fc1'):fc1 = tf.add(tf.matmul(features,weight_variable('fc1',[n_feature,n_fc1],0.04,'w_fc1')),bias_variable('fc1',0.1,tf.float32,[n_fc1],'b_fc1'))fc1 = tf.nn.relu(fc1) #激励函数# 计算第二层隐藏层 a=x*w+bwith tf.name_scope('fc2'):fc2 = tf.add(tf.matmul(fc1,weight_variable('fc2',[n_fc1, n_fc2],0.04,'w_fc2')),bias_variable('fc2',0.1,tf.float32,[n_fc2],'b_fc2'))fc2 = tf.nn.relu(fc2) #激励函数with tf.name_scope('output'):fc3 = tf.add(tf.matmul(fc2,weight_variable('fc3',[n_fc2,n_label],0.04,'w_fc3')),bias_variable('fc3',0.1,tf.float32,[n_label],'b_fc3'), name="output") ####这个名称很重要!!)return fc3#损失函数
def loss(logits,labels):with tf.name_scope('cross_entropy'):cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,labels=labels))tf.summary.scalar('cost',cost)return cost#训练,减小损失函数
def train(cost):#此函数是Adam优化算法:是一个寻找全局最优点的优化算法,引入了二次方梯度校正。#相比于基础SGD算法,1.不容易陷于局部优点。2.速度更快with tf.name_scope('train'):optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost,global_step=global_step)return optimizer#准确率
def accuracy(labels,preds):with tf.name_scope('accuracy'):correct_prediction = tf.equal(tf.argmax(labels,1),tf.argmax(preds,1))acc = tf.reduce_mean(tf.cast(correct_prediction,'float'))return acc# 从数字标签转换为数组标签 [0,0,0,...1,0,0]
def InitImagesLabels(labels_batch):labels_batch_new=[]for id in labels_batch:aa = np.zeros(n_label, np.int16)aa[id] = 1labels_batch_new.append(aa)return labels_batch_new# ---------------------------------------------------------------------------------------------------------
# ---------------------------------------------------------------------------------------------------------
#此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
#
# 定义输入和参数
# 用placeholder实现输入定义(sess.run中喂一组数据)
features_tensor = tf.placeholder(tf.float32,shape=[None,n_feature], name="input") ####这个名称很重要!!!
labels_tensor = tf.placeholder(tf.float32,shape=[None,n_label], name='labels')#------------指数衰减型学习率----------------------------
#运行了几轮batch_size的计数器,初值给0,设为不被训练
global_step=tf.Variable(0,trainable=False)
#定义指数下降学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,LEARNING_RATE_STEP,LEARNING_RATE_DECAY,staircase=True)
#-----------指数衰减型学习率-----------------------------#前向计算
# logits = inference(features_tensor)
keep_prob=tf.placeholder(tf.float32) #drop_out比率# 计算第一层隐藏层 a=x*w+b
with tf.name_scope('fc1'):fc1 = tf.add(tf.matmul(features_tensor, weight_variable('fc1', [n_feature, n_fc1], 0.04, 'w_fc1')),bias_variable('fc1', 0.1, tf.float32, [n_fc1], 'b_fc1'))fc1 = tf.nn.relu(fc1) # 激励函数L1_drop = tf.nn.dropout(fc1, keep_prob)
# 计算第二层隐藏层 a=x*w+b
with tf.name_scope('fc2'):fc2 = tf.add(tf.matmul(L1_drop, weight_variable('fc2', [n_fc1, n_fc2], 0.04, 'w_fc2')),bias_variable('fc2', 0.1, tf.float32, [n_fc2], 'b_fc2'))fc2 = tf.nn.relu(fc2) # 激励函数L2_drop = tf.nn.dropout(fc2, keep_prob)logits = tf.add(tf.matmul(L2_drop, weight_variable('fc3', [n_fc2, n_label], 0.04, 'w_fc3')),bias_variable('fc3', 0.1, tf.float32, [n_label], 'b_fc3'))y = tf.nn.softmax(logits, name="output") # 预测值 这个名称很重要!! 输出概率值#损失函数
cost = loss(logits,labels_tensor)
#训练减小损失函数
optimizer = train(cost)merged_summary_op = tf.summary.merge_all() #合并默认图形中的所有汇总#返回准确率
acc = accuracy(labels_tensor,logits)# 我们经常在训练完一个模型之后希望保存训练的结果,
# 这些结果指的是模型的参数,以便下次迭代的训练或者用作测试。
# Tensorflow针对这一需求提供了Saver类。
saver = tf.train.Saver(max_to_keep=1) #保存网络模型
# ---------------------------------------------------------------------------------------------------------
# ---------------------------------------------------------------------------------------------------------
#会话graph=tf.Graph()
with tf.Session() as sess:print("启动执行...")time_start = time.time() #计时sess.run(tf.global_variables_initializer()) #用于初始化所有的变量sess.run(tf.local_variables_initializer())#----------断点续训--------------------------ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)if ckpt and ckpt.model_checkpoint_path:saver.restore(sess, ckpt.model_checkpoint_path)# ----------断点续训--------------------------#logs是事件文件所在的目录,这里是工程目录下的logs目录。第二个参数是事件文件要记录的图,也就是tensorflow默认的图。summary_writer = tf.summary.FileWriter('logs',graph=tf.get_default_graph())#==============循环读取-训练-数据进行训练==================================================================flag = 0icounter=0while icounter<training_iters: # training_iters 训练次数for iNo in range(inpyNUM): # npy文件数量# 读取数据train_data_npyPath = (r".\npy3\Img21477_features_train_%d.npy" % (iNo + 1)) #npy路径train_labels_npyPath = (r".\npy3\Img21477_labels_train_%d.npy" % (iNo + 1)) #npy路径#print("共%d个训练数据集,加载第%d训练数据集中..." % (inpyNUM, iNo + 1))train_data = np.load(train_data_npyPath).astype(np.int16) #加载数据train_labels = np.load(train_labels_npyPath).astype(np.int16) #加载数据# print(train_data.shape, train_labels.shape) # 打印数据参数# len_train_data=int(len(train_data)/batch_size) #训练集被分成了n个batch_sizelen_train_data =int(ceil(len(train_data)/batch_size)) #ceil(3.01)=4 向上取整for i_batchSize in range (len_train_data): #对当前训练集逐个获取batch_size块的数据data_batch,labels_batch = gen_batch(train_data,train_labels,batch_size) #获取一块最小数据集# data_batch, labels_batch = ShuffledData(data_batch, labels_batch) #每次读取都打乱数据labels_batch_new = InitImagesLabels(labels_batch) #从数字标签转换为数组标签 [0,0,0,...1,0,0]#_,c,summary = sess.run([optimizer,cost,merged_summary_op],feed_dict={features_tensor:data_batch,labels_tensor:labels_batch})_, c, icounter = sess.run([optimizer, cost, global_step],feed_dict={features_tensor: data_batch,labels_tensor: labels_batch_new,keep_prob:1})#----------指数衰减型学习率--------------------learning_rate_val=sess.run(learning_rate)global_step_val=sess.run(global_step)print("After %s steps,global_step is %f,learing rate is %f"%(icounter,global_step_val, learning_rate_val))#----------指数衰减型学习率--------------------icounter+=1 #执行轮数if (icounter) % test_step == 0: # test_step = 1000# ==============循环读取-测试-数据进行测试==================================================================sumAccuracy = 0countNum=0 #测试数据总共多少轮for iNo in range(inpyNUM):# 读取测试数据test_data_npyPath = (r".\npy3\Img21477_features_test_%d.npy" % (iNo + 1))test_labels_npyPath = (r".\npy3\Img21477_labels_test_%d.npy" % (iNo + 1))test_data = np.load(test_data_npyPath).astype(np.int16)test_labels = np.load(test_labels_npyPath).astype(np.int16)len_test_data = int(ceil(len(test_data) / batch_size)) # ceil(3.01)=4 向上取整for i_batchSize in range(len_test_data): # 对当前训练集逐个获取batch_size块的数据test_data_batch, test_labels_batch = gen_batch(test_data, test_labels, batch_size) # 获取一块最小数据集# test_data_batch, test_labels_batch = ShuffledData(test_data_batch, test_labels_batch) # 每次读取都打乱数据test_labels_batch_new = InitImagesLabels(test_labels_batch) # 从数字标签转换为数组标签 [0,0,0,...1,0,0]a = sess.run(acc, feed_dict={features_tensor: test_data_batch,labels_tensor: test_labels_batch_new, keep_prob: 1}) # 测试数据countNum += 1sumAccuracy = sumAccuracy + a # 计算正确率和avgAccuracy = sumAccuracy / countNumprint(("测试数据集正确率为%f:" % (avgAccuracy)))# ==============循环读取-测试-数据进行测试==================================================================if (icounter) % display_step == 0: # display_step = 100# ----------断点续训--------------------------saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)# ----------断点续训--------------------------# ----------显示消息--------------------------print("Iter" + str(icounter) +",learing rate="+ "{:.8f}".format(learning_rate_val)+",Training Loss=" + "{:.6f}".format(c))# ----------显示消息--------------------------# ----------保存pb----------------------------constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def, ["output"]) #["inputs", "outputs"] 此处字符串和前面对应上with tf.gfile.FastGFile("./model/OCRsoftmax21477.pb", mode='wb') as f:f.write(constant_graph.SerializeToString())# ----------保存pb----------------------------#for iNo in range(inpyNUM): # npy文件数量summary_writer.close() # log记录文件关闭time_end = time.time()time_h = (time_end - time_start) / 3600print('训练用时:%.2f 小时' % time_h)print("Optimization Finished!")#==============循环读取-训练-数据进行训练==================================================================# saver.save(sess, r"./save_ANN.ckpt") #保存模型# ###############预测##############################################################
# # char_set = ['嫒', '扳', '板', '苯', '笨', '币', '厕', '侧', '厂', '憧', '脆', '打', '大', '钉', '丢', '懂',
# # '儿', '非', '干', '古', '诂', '诡', '乎', '话', '几', '己', '减', '減', '韭', '钜', '决', '決',
# # '扛', '钌', '昧', '孟', '末', '沐', '钼', '蓬', '篷', '平', '亓', '千', '去', '犬', '壬', '晌',
# # '舌', '十', '士', '市', '拭', '栻', '適', '沭', '耍', '巳', '趟', '天', '土', '王', '枉', '未',
# # '味', '文', '兀', '淅', '晰', '响', '写', '要', '已', '盂', '与', '元', '媛', '丈', '趙', '谪',
# # '锺', '鍾', '柱', '状', '狀']
# char_set = np.load(r"./npy/ImgHanZiName653.npy")
# char_set = char_set.tolist()
# data_dir=r"D:\sxl\处理图片\汉字分类\train653"
# pred = prediction(logits)
# error_n = 0
# print ("预测图像中...")
# precount=0
# for dirname in os.listdir(data_dir): #返回指定路径下所有文件和文件夹的名字,并存放于一个列表中。
# #os.walk 返回的是一个3个元素的元组 (root, dirs, files) ,分别表示遍历的路径名,该路径下的目录列表和该路径下文件列表
# for parent, _, filenames in os.walk(data_dir + '/' + dirname):
# for filename in filenames:
# if (filename[-4:] != '.jpg'):
# continue
# precount+=1
# if (precount % 100 == 0):
# print("正在执行第%d个..." % (precount))
# image = cv_imread(parent + '/' + filename, 0)
# feature =SimpleGridFeature(image).reshape(-1, 256) #提取特征 reshape(-1, 64) 行数未知,列数等于64
# p = sess.run(pred, feed_dict={features_tensor: feature}) #当前图片和之前训练好的模型比较,返回预测结果
# if (char_set[p[0]] != dirname):
# error_n += 1
# cv2.imencode('.jpg', image)[1].tofile(
# 'error_images/' + dirname+ '_'+char_set[p[0]] + '_' + str(error_n) + '.jpg')
# ###############预测##############################################################
time_end=time.time()
time_h=(time_end-time_start)/3600
print('总用时:%.6f 小时'% time_h)
print ("运行结束!")
#####################################################
3.3 结果
这里就不贴结果了,当时运行时没有截图,现在再运行一次挺麻烦的
欢迎扫码关注我的微信公众号

这篇关于机器学习实战笔记9—人工神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




