本文主要是介绍【Semantic Embedding】: DSSM模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文下载地址
代码实现
DSSM现在应该已经算是经典的文章了,有些年头了。网上已经有很多优秀的博客对该算法进行分析,建议去看那些文章,讲的比较全面。
DSSM的思想是利用搜索点击数据,分别将query和documents利用DNN映射到高纬语义空间,然后将query和document的高纬语义向量利用余弦相似度,对向量进行相似度计算。
训练阶段,对于点击数据,如果在当前query下,被点击的document认为是正样本,没有点击的document认为是负样本,正常的搜索行为,每个query会返回很多的相关documents,而用户则会找到最需要的进行点击查看。所以模型需要做的就是对全部的document进行排序,让最相关document的排序分值最高。但是每个query对应的document数量比较大,所以并不需要对全部的documents,因此可以对documents进行采用,训练的时候只报表被点击的document(正样本),没有点击的随机采样若干个(论文里采样了四个)。
后续也有人直接利用query-document样本对来进行训练,训练数据格式为(label,query,document),如果在query下,document被点击则label为1,如果没有点击则label为0。然后对负样本进行采样。尽量不要让正负样本悬殊过大。
模型

上图为模型结构,最下面的term vector是将query和document做词袋模型展开,形成一个很长的稀疏向量,作为模型的输入。
这里,因为英文单次量很大,这样做词袋模型的话,维度太大,输入数据很稀疏,因为为了解决这个问题,用了一个hash trick来解决这个问题,叫做WordHashing。就是上图的倒数第二层。
词hash其实就是把一个英文单词,利用n-grams把单词切开,比如把good用tri-gram切,切完就是(#go,goo,ood,od#),然后按切好的tri-gram对整个query或者doc做词袋模型。这样就能显著降低输入特征的维度。就和中文一样,中文其实字的数量并不多,可能几万个字就能覆盖很多的场景了,但是一旦扩展的词的量就会很大。
但是这个方法在中文里,基本没啥用,当然有能力可以把中文的字拆成各个部首也可以试试,这个之前在看NER相关文章的时候还真有这样做的。
针对中文的话,直接分词就可以了,然后统计query和doc的词袋模型作为输入。
到这以后,输入就传入上图中的multi-layer non-liner projection了,这其实就是几层全连接层,全连接层的最后一层输出就是我们要获取的隐藏语义向量。也就是上图中的semantic feature。
最后就是对query和doc的semantic feature进行相似度计算,通过query和不同的doc进行相似度计算,就能获得多个相似度值,
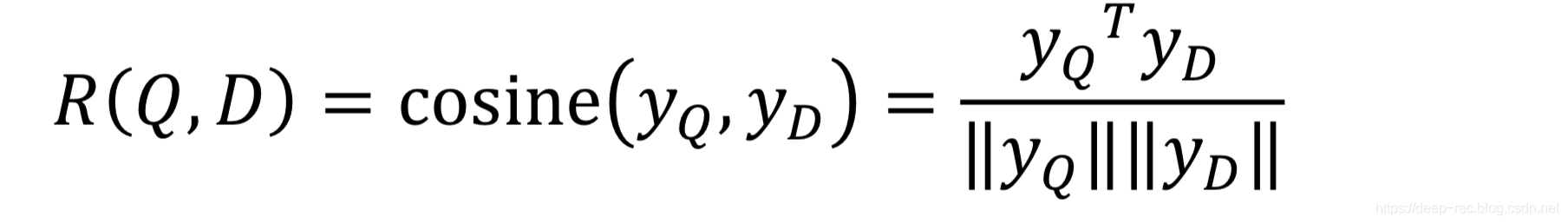
有了相似度值后就可以对文档进行排序了 去求query和doc的最大似然,这里直接用softmax来计算query和doc之间的分值,其中标签数据为:query和被点击的doc相似度为1,query和没有点击的doc的相似度为0,训练拟合:
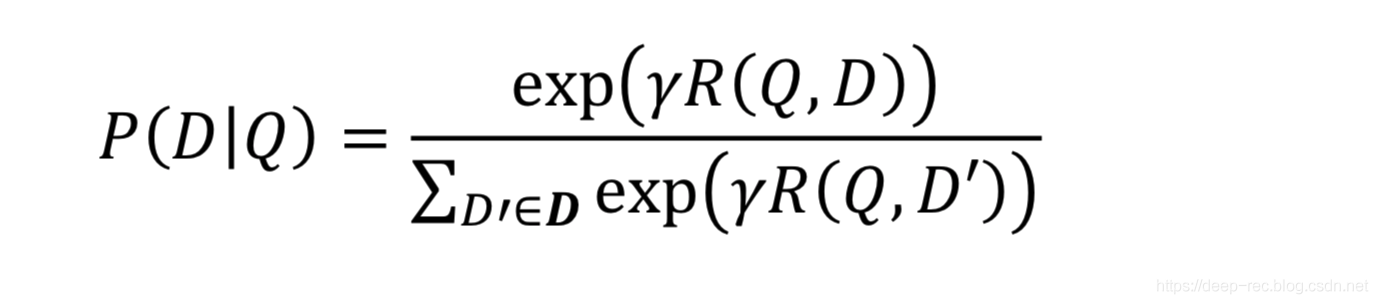
这里的r是平滑系数,实现定义好的。
现在损失函数有, 模型结构有,训练数据也有了,然后就用梯度下降优化就可以了。
完。
这篇关于【Semantic Embedding】: DSSM模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









