本文主要是介绍17.来自Sora的夺舍妄想——享元模式详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenAI 的 Sora 模型面世之后,可以说人类抵御AI的最后阵地也沦陷了。
在此之前,人们面对AI交互式对话,AI制图,AI建模之类的奇迹时,还可以略微放肆的说:“的确很神奇,这毕竟还是比人类世界低了一个维度,并没有那么可怕。”
而现在,视频生成模型Sora在发展初期创造的视频就几乎可以以假乱真了,这对人类来说究竟意味着什么?
也许大多数人并没有想清楚。
AI可以生成视频,这意味着大模型已经完全理解了人类所在的三维世界的一切物理规则和绝大部分的社会规则。它正在变得比这个世界上的大多数人都更了解这个世界。

AI创造的视频中的各种“生命体”在现实世界中是不存在的,如果他们有所谓的“意识”真的可以称之为“生命”的话。他们的世界是我们世界的投影,在那个世界里“生活”的“人”其实并不清楚他们的世界是怎么来的,就像现在的我们一样。
就像电影《异次元骇客》所描述的一样,每个世界都是更高一级世界的投影,每个人都是NPC,每当上层世界的玩家“登录”,下层的意识就会被抢占。所以有些人会突然发神经仿佛人格分裂一样,就好比GTA5中的老麦在你打开游戏前是一个好父亲,而在你打开游戏后变成了砍天砍地的恶棍。时不时他还会冒出来一句:“Oh, my goodness, what have I done?!”

幻想总是能让人思绪飞扬,今天我想从“夺舍”这个角度来讲一讲设计模式中的享元模式。
一言
享元模式,旨在通过共享对象来减少内存使用量并提高性能。它适用于那些由于对象内部状态重复而导致大量内存消耗的场景。
对下一层世界的秩序设计
我们假定你的几行代码就可以设计出一个比你低一个层次的世界,那么你打算如何实现“每个人都是NPC,每当上层世界的玩家登录,下层的意识就会被抢占”这一需求呢?

核心代码Ctrl CV?
“欸,我直接copy走起”,相信大家第一时间想到的都是这个设计。
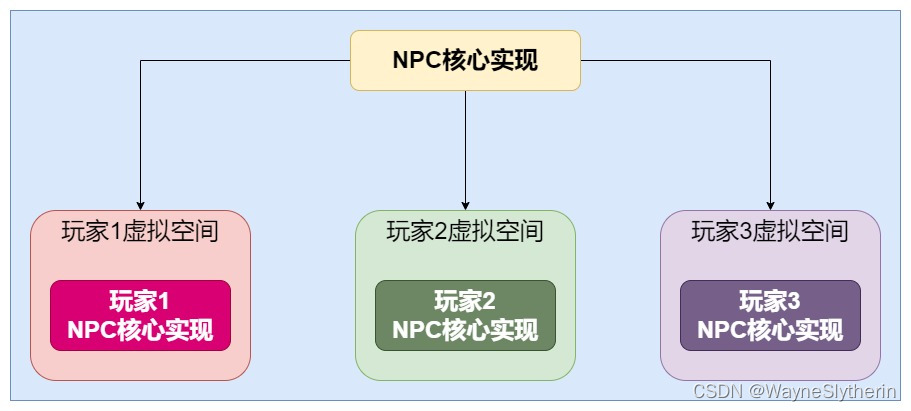
的确是通俗易懂,传统的定制化编程实现,但也确实存在很多的隐患。
分析
几个玩家操控的NPC相似度这么高,如果分多个虚拟空间来处理,相当于一个NPC占用了多个实例,造成了极大的内存浪费。
那么有没有一种可能,我们将这些NPC实例整合到一个NPC中(让他拥有多个人格),对于硬盘、内存、CPU、数据库空间等服务器资源都可以达成共享,是不是就减少了服务器资源的浪费呢?
对于代码而言,我们也后期也只需要维护和扩展一份,这样的思路是不是更好呢?
享元模式
也许乍一听这个名词很多朋友会一愣,觉得自己从未接触过这个设计模式,实际上它非常的常见。比如说数据库连接池的设计,里面都是创建好的连接对象,在这些连接对象中有我们需要的就直接拿来用,没有就创建一个。
在这种思路下,解决了重复对象的内存浪费问题,当系统中存在大量相似对象,需要缓冲池时,不再需要创建新对象,而是直接在缓冲池里拿。
不光是数据库连接池,String 常量池 ,缓冲池等等都是享元模式的应用,也是池技术的重要实现方式。
设计
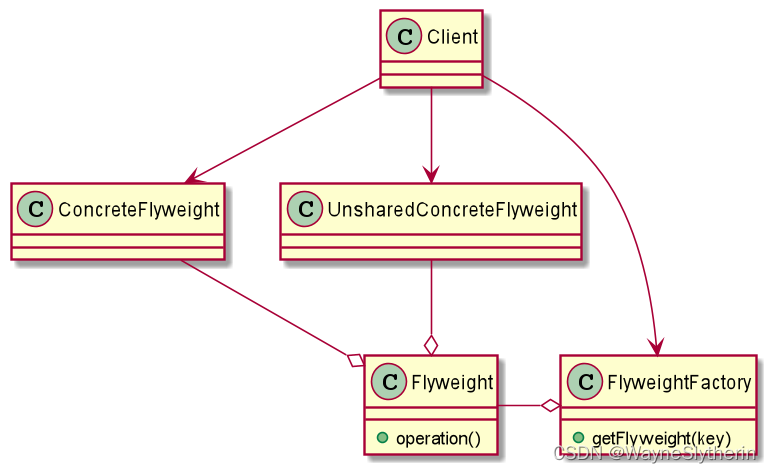
- FlyWeight 是抽象的享元角色,它是产品的抽象类,同时定义出对象的外部状态和内部状态的接口或实现;
- ConcreteFlyWeight 是具体的享元角色,是具体的产品类,实现抽象角色自定义相关业务;
- UnsharedConcreteFlyWeight 是不可共享的角色,一般不会出现在享元工厂中;
- FlyWeightFactory 享元工厂类,用于构建一个池容器(集合),同时提供从池中获取对象的方法;
内部状态与外部状态
享元模式有两个要求:细粒度和共享对象。这里就涉及到内部状态和外部状态了。那么什么是内部状态和外部状态呢?
通俗的讲,大家都玩过王者荣耀或者英雄联盟这类的MOBA游戏,召唤师峡谷的地图信息和地图资源是基本固定的,而每局游戏参战的英雄,英雄的位置、状态、技能等信息则是千变万化的。在这个例子中:
- 地图是内部状态,地图上野怪的属性和状态是外部状态
- 英雄模型是内部状态,英雄的血量、等级等变化的是外部状态
内部状态指对象共享出来的信息,存储在享元对象内部且不会随环境的改变而改变。外部状态指对象得以依赖的一个标记,是随环境改变而改变的、不可共享的状态。
可以试想以下,如果不采用享元模式,类似的游戏(PUBG、棋牌类游戏等)每一局都构建一整套资源有多么恐怖。
代码实现
现在我们开始编辑对NPC人格的入侵程序:
玩家
public class User {private String name;public User(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}
NPC
public abstract class NPC {public abstract void use(User user);//抽象方法
}
NPC享元角色
public class ConcreteNPC extends NPC{private String type = "";public ConcreteNPC(String type) {this.type = type;}@Overridepublic void use(User user) {System.out.println("NPC的人格切换为:"+type+",在使用中.. 使用者为:"+user.getName());}
}
NPC享元工厂
public class NPCFactory {private HashMap<String,ConcreteNPC> pool = new HashMap<>();public NPC getNpcCategory(String type){if (!pool.containsKey(type)){pool.put(type,new ConcreteNPC(type));}return (NPC) pool.get(type);}public int getNpcCount(){return pool.size();}
}
客户端
public class Client {public static void main(String[] args) {NPCFactory factory = new NPCFactory();NPC npc1 = factory.getNpcCategory("圣人");npc1.use(new User("Tom"));NPC npc2 = factory.getNpcCategory("狂徒");npc2.use(new User("Jack"));NPC npc3 = factory.getNpcCategory("学者");npc3.use(new User("Linda"));NPC npc4 = factory.getNpcCategory("学者");npc4.use(new User("Lucy"));NPC npc5 = factory.getNpcCategory("学者");npc5.use(new User("Amanda"));System.out.println("NPC人格分类共:"+factory.getNpcCount());}
}
执行

可以看到,在当前的设计下,NPC的人格集中管理在享元工厂的池子中,当有新的玩家注入新的人格则会扩充这个池子的容量,如果没有新的人格加入,则会从池子中提取已有的人格注入到NPC体内。
享元模式在JDK-Integer源码中的应用
之前网上有这样一种论调:“国内IT行业程序员的面试已经越来越朝向八股化发展了。
面试造火箭,工作打螺丝”。
从某种角度来看,似乎说的是行业面试的现状。但从编程基础的角度考虑,有些八股本身不是问题,问题是很多朋友没有真正理解八股描述的底层原理,全靠死记硬背。
比如说下面这个面试题:
Integer a = Integer.valueOf(127);Integer b = new Integer(127);Integer c = Integer.valueOf(127);Integer d = new Integer(127);System.out.println(a.equals(b));System.out.println(a==b);System.out.println(a==c);System.out.println(d==a);System.out.println(d==b);
八股文只会告诉你,上面的结果是:

但我觉得这不是我们要去背的东西,我们要理解为什么是这样的结果。这个结果其实就源自Integer的享元模式,我们先看下源码。
相关源码片
/*** Cache to support the object identity semantics of autoboxing for values between* -128 and 127 (inclusive) as required by JLS.** The cache is initialized on first usage. The size of the cache* may be controlled by the {@code -XX:AutoBoxCacheMax=<size>} option.* During VM initialization, java.lang.Integer.IntegerCache.high property* may be set and saved in the private system properties in the* sun.misc.VM class.*/private static class IntegerCache {static final int low = -128;static final int high;static final Integer cache[];static {// high value may be configured by propertyint h = 127;String integerCacheHighPropValue =sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");if (integerCacheHighPropValue != null) {try {int i = parseInt(integerCacheHighPropValue);i = Math.max(i, 127);// Maximum array size is Integer.MAX_VALUEh = Math.min(i, Integer.MAX_VALUE - (-low) -1);} catch( NumberFormatException nfe) {// If the property cannot be parsed into an int, ignore it.}}high = h;cache = new Integer[(high - low) + 1];int j = low;for(int k = 0; k < cache.length; k++)cache[k] = new Integer(j++);// range [-128, 127] must be interned (JLS7 5.1.7)assert IntegerCache.high >= 127;}private IntegerCache() {}}/*** Returns an {@code Integer} instance representing the specified* {@code int} value. If a new {@code Integer} instance is not* required, this method should generally be used in preference to* the constructor {@link #Integer(int)}, as this method is likely* to yield significantly better space and time performance by* caching frequently requested values.** This method will always cache values in the range -128 to 127,* inclusive, and may cache other values outside of this range.** @param i an {@code int} value.* @return an {@code Integer} instance representing {@code i}.* @since 1.5*/public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}
源码分析
- 在valueOf方法中,先判断值是否在IntegerCache中,如果不在,就创建新的Integer(new),否则,就直接从缓存池返回;
- valueOf方法就使用到了享元模式;
- 如果使用valueOf方法得到一个Integer实例范围在-128~127之间,执行速度比 new 快;
所以,以-128~127为界,比较Integer是否是同一个对象时会有不同的表现结果。
结
“享”即共享,“元”即对象,如果系统中有大量对象占用缓存,并且对象状态大都可以外部化时,我们就可以考虑选用享元模式。
但是也要清楚的看到,享元模式在提高了效率的同时也提高了系统复杂度,而且,外部状态具有固化特性不会随着内部状态的改变而改变,这也会在一定程度上增加编码逻辑的理解难度。
关注我,共同进步,每周至少一更。——Wayne
这篇关于17.来自Sora的夺舍妄想——享元模式详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





