本文主要是介绍阿里通义最新黑科技!“通义舞王”:让静态照片翩翩起舞,探索艺术与科技的无限可能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引子:穿越二维与三维的艺术边界
在科技日新月异的时代,艺术创作的疆界正以前所未有的速度拓展,,从AI作曲和音乐生成技术带来的跨风格音乐作品,到基于人工智能的诗歌与文学创作,艺术不再仅仅是人类个体情感与才华的体现,而成为人机交互、数据智能与创新思维相互融合的新领域。
近日,阿里云再次引领创新潮流,推出一款令人叹为观止的AI黑科技——“通义舞王”。
该功能内置于通义千问APP中,它突破了平面与立体、静止与动态之间的壁垒,能够将一张普通的照片在短时间内转化为一段神形兼备的舞蹈视频,让每一位用户都能感受到科技进步带来的魔法般的艺术体验。接下来,就带领各位一起切身体验一下吧!
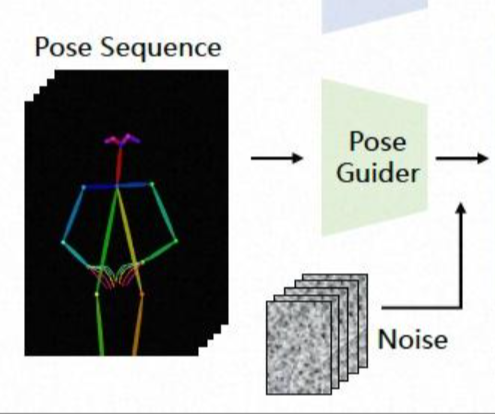
从照片到舞者:体验一键唤醒沉睡的灵魂
目前,该功能只适用于手机APP端,web端暂时不支持哈。

所以请先在手机下载通义APP,下载完成后在输入框输入“通义舞王”,然后就会跳转进舞王界面了,具体操作如下:
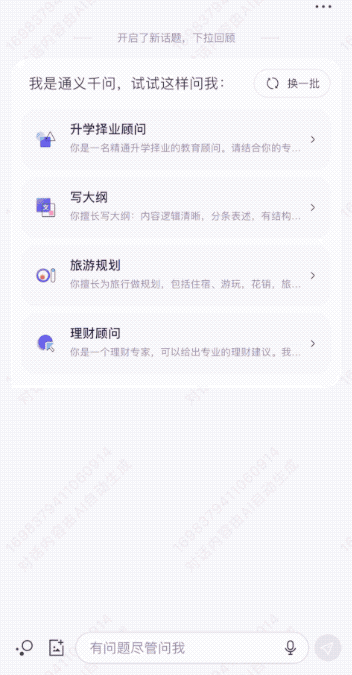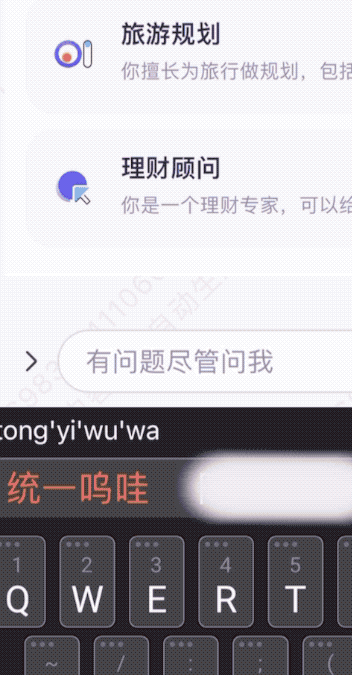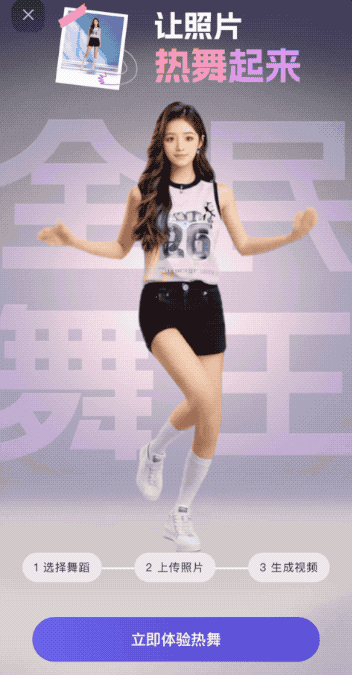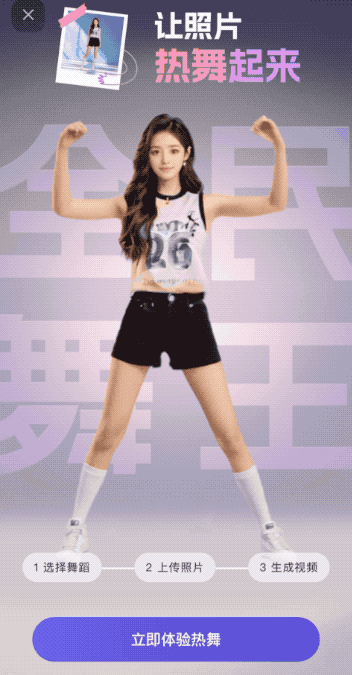
点击立即体验热舞,我们可以看到很多模板,这些模板包含了当前比较热门的“科目三” “DJ慢摇”等视频:
我们选到最热门的科目三栏目下面,此时会有几个已有人物模板,但是做为一个真正的ikun,我的梦想一直是希望能看到我家鸽鸽跳这支舞,所以我毫不犹豫的上传了他的照片。
对于上传的照片,其实也是有要求的,最好是一张清晰的正面单人照片,尽量避免有遮挡物或背景干扰。

对于用户自己上传的照片,将其视频化需要一定的时间,根据笔者的体验平均需要10分钟15分钟之间,所以只需要耐心等待即可~此时可以保留后台去刷刷别的视频,当制作完成后会有相应提示的。
经过十几分钟的等待,鸽鸽跳舞的视频就生成好了,还能很好地保留原照片的面部表情、身材比例、服装以及背景等特征。

“通义舞王”以其深度学习和计算机视觉的核心技术,赋予静态人物照片全新的生命力。只需上传一张照片,无论拍摄对象是谁,无论何种姿势,“通义舞王”都能够通过高精度的人脸识别及人体姿态分析算法,捕捉并模拟人物的关键动作点,进而将其与丰富多样的舞蹈模板无缝对接,生成逼真且富有表现力的舞蹈视频。
千变万化的舞蹈宇宙背后究竟是什么?
通义千问之所以能够实现生成流畅且高质量的舞蹈视频,依靠的是近期阿里巴巴XR实验室研发团队公布的一项名为“Animate Anyone”的创新算法,其核心能力是利用扩散模型从静态人物图像出发,自动生成流畅且连贯的角色动画视频。

Animate Anyone 可以将任意角色的照片转化为一系列按照所需姿势排列的动态视频内容,这一突破不仅显著提升了图像到视频合成的质量,特别是在角色动画的自然度和稳定性上,而且简化了传统动画制作流程,降低了创作门槛。

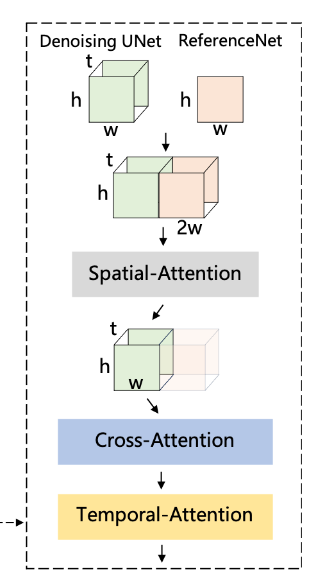
Animate Anyone使用扩散模型生成视频,同时引入了ReferenceNet来保持细节特征的一致性,Pose Guider来控制角色的动作,以及Temporal-Attention来保证视频帧之间的平滑过渡。它可以将静态的角色图像(包括真人、动漫/卡通角色等)转化为动画视频,同时保留角色的细节特征(如面部表情、服装细节等)。
-
ReferenceNet:负责编码参考图像角色的外观特征;
-
Pose Guider(姿态引导器):负责编码动作控制信号以实现可控角色运动;
-
Temporal layer(时间层):负责编码时间关系,以确保角色动作的连续性。
一些历史的姿态驱动视频生成方案,在生成的视频上容易出现视频一致性(准确度)减弱的问题。另一个核心的问题在于,之前的一些驱动方案在以人作为主题的视频生成,无法同时保证泛化性和一致性的能力。
而在该方法中,通过上述三个模块,能够将角色图片转化为受期望姿态序列控制的动画视频,同时确保外观一致性和时间稳定性。
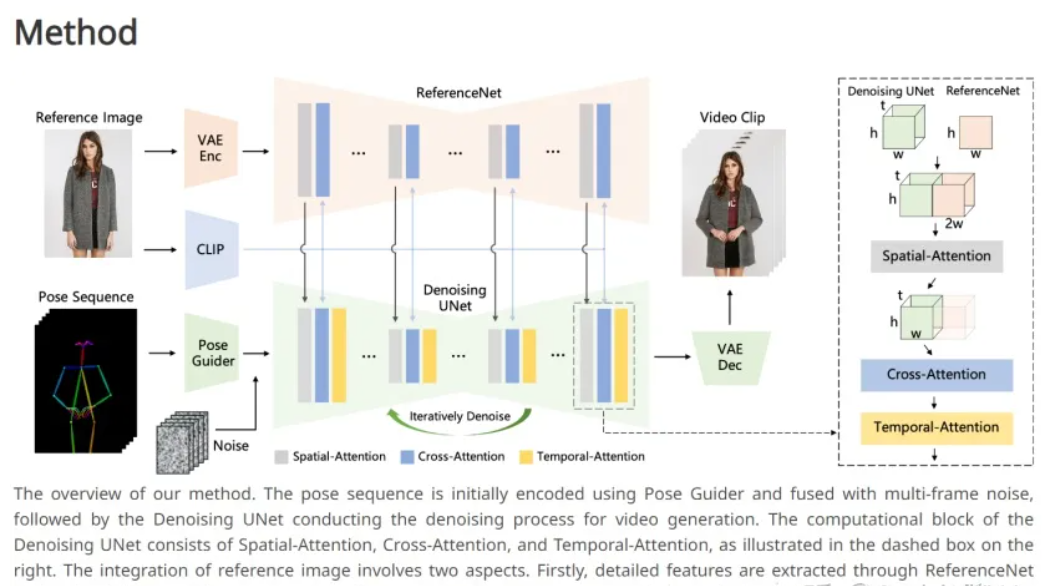
在上面这张架构图中,我们也可以清晰的看到这三个模块之间的关系。
**ReferenceNet**
简单来说,构建了一个“完整Unet版”的Controlnet。设计了一个与去噪UNet结构相同的ReferenceNet。在每个UNet块的对应层,我们用空间注意力替换了自我注意力层,将ReferenceNet的特征与去噪UNet的特征相结合。
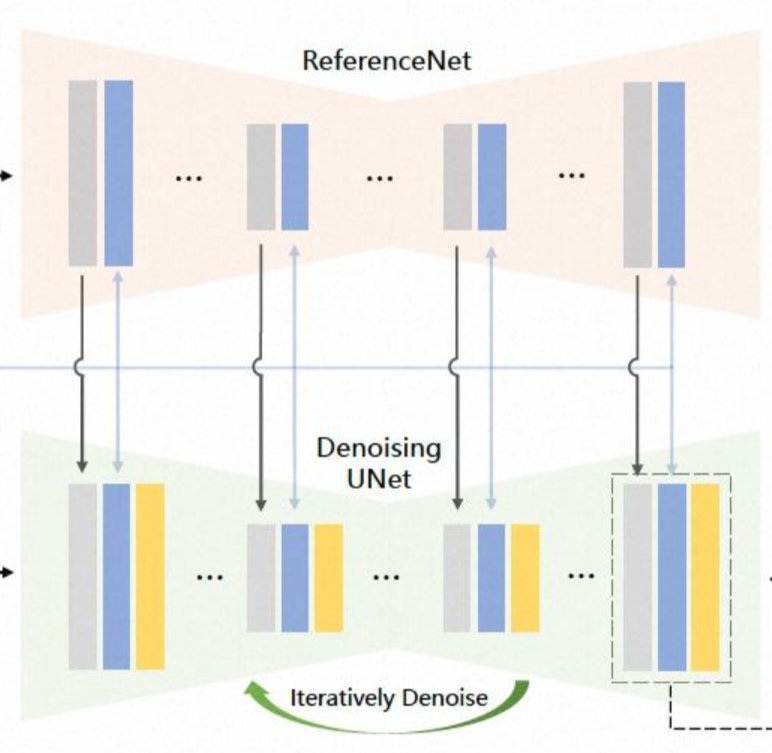
同时文章给出了和原生ControlNet的的取舍的原因:为什么不使用ControlNet 一般Unet+零卷积的实现方案,整体的原因是输入的控制信息,例如作为深度和边缘的canny特征控制,适合输入图像一致对齐的。但是落到现在的具体任务中,参考图像和目标图像在空间上相关但不一致(所以只能做controlNet reference-only相似生成)。因此,ControlNet不是适合直接应用。
**Pose Guider**
同样不同于COntrolNet的设计方式,为了不增加控制网络模型的复杂性,没有引入额外的插件来实现该功能。引入了一个轻量级的Pose Guider,它使用四个卷积层将姿态图像与噪声表达,将处理后的图像添加到噪声中,作为去噪UNet的输入。
时序Attention层:
受到AnimateDiff的启发。为了确保帧间的平滑过渡,在Res-Trans块中加入了时间时序Attention模块,通过时序Attention模块,来进行时空一致性的控制。时序Attention层位于Res-Trans块内,对特征图进行时间注意力操作,从而捕获帧间的相关性。时间层的输出与原始特征图通过残差连接相结合,以保留空间信息。这种设计可以实现让模型能够生成具有平滑帧间过渡的动画视频。
除此之外,该方法还采用了一种分阶段的训练策略,分为两个阶段进行训练,以实现高质量的角色动画。
第一阶段:
在第一阶段,使用单帧图像作为输入进行训练,暂时不使用时间层。这个阶段的主要目标是学习参考图像中的细节特征,并实现有效的运动控制。在这个阶段,仅训练ReferenceNet和Pose Guider。通过在单个图像上进行训练,模型能够专注于学习与参考图像相关联的细节特征,同时实现对角色运动的控制。这为后续阶段的训练奠定了基础。
第2阶段:
在第二阶段,引入时间层,并使用24帧视频序列进行训练。这个阶段的主要目标是实现帧间的平滑过渡,从而使生成的视频具有更好的时间连续性。通过在视频序列上进行训练,模型能够学习到帧间的相关性,并调整其生成过程以实现更自然的动画效果。
训练过程分为两个阶段有助于在不同阶段关注不同的目标,从而实现高质量的角色动画。在第一阶段,模型学习保留细节特征并实现运动控制;在第二阶段,模型进一步优化帧间过渡,使生成的视频更加流畅和自然。通过这种分阶段训练策略,能够在角色动画任务上取得优越的性能。
上述内容也是来自于论文中的,这里也给出相关链接,有兴趣的朋友可以直接看看。
anyone项目地址:https://humanaigc.github.io/animate-anyone/
论文地址:https://arxiv.org/pdf/2311.17117.pdf
仓库地址(目前尚未开源):https://github.com/HumanAIGC/AnimateAnyone
深度解读:科技如何重塑艺术表达?
“通义舞王”的诞生不仅刷新了我们对数字艺术的认知,也提出了关于未来艺术创作的新课题。当科技的力量逐渐渗透至传统艺术领域,会否催生出一种全新的艺术形式?人工智能能否成为艺术家们的创意伙伴,共同编织出超越现实的梦幻之舞?而作为普通用户,我们又该如何把握这种新工具,去创造属于自己的艺术故事,并在全球数字化的大背景下,分享个人独特的文化与情感表达?
对此,笔者看法如下:
首先,毫无疑问,科技能够为艺术创作注入了无限可能,极大地拓宽了艺术表现手法和媒介的范围。就以AI绘画为例,它通过深度学习技术模拟人类艺术家的创作风格与技法,能够在短时间内生成大量风格各异的艺术作品,无论是古典主义、抽象派还是超现实主义,都能被算法捕捉并重新演绎。这种新型的艺术生产方式不仅突破了物理空间和时间的限制,也使得艺术创作的门槛降低,让更多的创作者得以尝试艺术表达,从而推动艺术生态更加多元化,对于普通用户而言确实是一件大好事。
除此之外,科技确实也会催生出全新的艺术体验模式,比如今年云栖大会就有一个VR的李白展让我印象十分深刻,观众能够通过沉浸式VR/AR眼镜跨越时空面对面和李白交流,从被动接受者转变为主动参与者。这种参与性艺术实践模糊了创作者与观赏者的界限,使艺术作品的生命力得到了前所未有的延伸和深化。
然而,在科技带来的积极影响之外,我们也应审慎思考其潜在的负面问题。一方面,AI艺术创作可能会引发原创性和真实性的争议,因为机器虽能模仿各种艺术风格,但缺乏真正的人类情感内核和创意灵感,这可能导致艺术界对于“何为真正的艺术”这一基本命题产生混淆。另一方面,过度依赖科技可能会导致艺术创作陷入机械化、同质化的陷阱。若艺术仅是算法模型的结果而丧失了个体的创造力和独立思考,则艺术作品的多样性和复杂性将受到影响,甚至有可能阻碍艺术发展的内在动力。
此外,科技带来的便利性也可能改变艺术市场的格局,如版权归属问题、肖像权问题、艺术品真实性判定等问题也随之浮现,这些都需要在法律制度和伦理规范层面进行深入探讨和完善。
共赴未来的艺术之旅
面对“通义舞王”所带来的颠覆性变革,我们不禁对未来充满了期待。这不仅仅是一个AI跳舞视频生成工具,更是连接现实与虚拟、个人与集体、传统与现代的一座桥梁。让我们携手踏上这段由科技驱动的艺术探索之旅,在“通义舞王”的助力下,一起见证并参与这场席卷全球的艺术革命!
这篇关于阿里通义最新黑科技!“通义舞王”:让静态照片翩翩起舞,探索艺术与科技的无限可能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





