本文主要是介绍SQL调优指南笔记13:Gathering Optimizer Statistics,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文为SQL Tuning Guide第13章“Gathering Optimizer Statistics”的笔记。
重要基本概念
- cost
A numeric internal measure that represents the estimated resource usage for an execution plan. The lower the cost, the more efficient the plan.
一个数字内部度量,表示执行计划的估计资源使用情况。 成本越低,计划越有效。
本章说明如何使用 DBMS_STATS.GATHER_*_STATS 程序单元。
13.1 Configuring Automatic Optimizer Statistics Collection
Oracle 数据库可以自动收集优化器统计信息。
13.1.1 About Automatic Optimizer Statistics Collection
自动维护任务基础结构(称为 AutoTask)安排任务在称为维护窗口的 Oracle 调度程序窗口中自动运行。
自动和手动统计收集之间的区别
主要区别在于自动收集优先考虑需要统计信息的数据库对象。 在维护窗口关闭之前,自动收集会评估所有对象并优先考虑没有统计信息或非常旧的统计信息的对象。
手动收集统计信息时,您可以使用 DBMS_AUTO_TASK_IMMEDIATE 包重现自动收集的对象优先级。 这个包运行在自动夜间统计收集作业期间执行的相同统计收集作业。
自动统计信息收集的工作原理
自动优化器统计信息收集作为 AutoTask 的一部分运行。 默认情况下,该集合在所有预定义的维护时段中运行。 为一周中的每一天安排一个窗口。
为了收集优化器统计信息,数据库调用一个内部过程,该过程与带有 GATHER AUTO 选项的 GATHER_DATABASE_STATS 过程类似。 自动统计收集尊重数据库中设置的所有首选项。
当自动优化器统计信息收集任务为 PDB 收集数据时,它会将这些数据存储在 PDB 中。 如果拔下 PDB,则包含此数据。 当前容器为 CDB 根的普通用户可以查看 PDB 的优化器统计数据。 当前容器是 PDB 的用户只能查看 PDB 的优化器统计数据。
13.1.2 Configuring Automatic Optimizer Statistics Collection Using Cloud Control
您可以使用 Cloud Control 启用和禁用所有自动维护任务,包括自动优化器统计信息收集。
默认窗口时间适用于大多数情况。 但是,您可能会在窗口期间进行批量加载等操作。 在这种情况下,为避免与自动统计收集同时发生的操作导致的潜在冲突,Oracle 建议您相应地更改窗口。

13.1.3 Configuring Automatic Optimizer Statistics Collection from the Command Line
如果您不使用 Cloud Control 来配置自动优化器统计信息收集,那么您必须使用命令行。
您有以下选择:
- 运行 DBMS_AUTO_TASK_ADMIN PL/SQL 包中的 ENABLE 或 DISABLE 过程。
这个包是推荐的命令行技术。 对于 ENABLE 和 DISABLE 过程,您可以使用 window_name 参数指定特定的维护时段。 - 将 STATISTICS_LEVEL 初始化级别设置为 BASIC 以禁用所有建议和统计信息的收集,包括 Automatic SQL Tuning Advisor。
注意:由于禁用了监控和许多自动功能,Oracle 强烈建议您不要将 STATISTICS_LEVEL 设置为 BASIC。
启用自动化任务:
BEGINDBMS_AUTO_TASK_ADMIN.ENABLE ( client_name => 'auto optimizer stats collection'
, operation => NULL
, window_name => NULL
);
END;
/
禁用自动化任务:
BEGINDBMS_AUTO_TASK_ADMIN.DISABLE ( client_name => 'auto optimizer stats collection'
, operation => NULL
, window_name => NULL
);
END;
/
查询自动化任务:
COL CLIENT_NAME FORMAT a31SELECT CLIENT_NAME, STATUS
FROM DBA_AUTOTASK_CLIENT;
-- WHERE CLIENT_NAME = 'auto optimizer stats collection';
CLIENT_NAME STATUS
------------------------------- --------
auto optimizer stats collection ENABLED
auto space advisor ENABLED
sql tuning advisor ENABLED
更改自动统计收集的窗口属性,例如,要更改周一维护时段,使其从早上 5 点开始:
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ('MONDAY_WINDOW'
, 'repeat_interval'
, 'freq=daily;byday=MON;byhour=05;byminute=0;bysecond=0'
);
END;
/
13.2 Configuring High-Frequency Automatic Optimizer Statistics Collection
这个轻量级任务补充了标准的自动统计收集。这是19c开始支持的Exadata独有特性。
alter system set "_exadata_feature_on"=true scope=spfile;
shutdown immediate;
startup;
13.2.1 About High-Frequency Automatic Optimizer Statistics Collection
您可以将自动统计信息收集配置为更频繁地发生。
高频自动优化器统计收集的目的
AutoTask 安排任务在维护窗口中自动运行。 默认情况下,为一周中的每一天安排一个窗口。 自动优化器统计信息收集 (DBMS_STATS) 在所有预定义的维护窗口中运行。
统计信息可能在两个连续的统计信息收集任务之间过时。 如果数据频繁更改,陈旧的统计信息可能会导致性能问题。 例如,一家经纪公司可能会在交易时间内收到大量数据,导致优化器在此期间执行的查询使用陈旧的统计数据。
高频自动优化器统计信息收集补充了标准统计信息收集作业。 默认情况下,收集每 15 分钟发生一次,这意味着统计信息的陈旧时间更短。
高频自动优化器统计信息收集的工作原理
要启用和禁用高频任务、设置执行间隔和设置最大运行时间,请使用 DBMS_STATS.SET_GLOBAL_PREFS 过程。 高频任务是“轻量级的”,只收集陈旧的统计数据。 它不执行诸如清除不存在对象的统计信息或调用 Optimizer Statistics Advisor 之类的操作。 标准自动化作业执行这些附加任务。
在维护窗口中运行的自动统计收集作业不受高频作业的影响。 高频任务可能会在维护窗口执行,但不会在维护窗口自动统计收集作业执行时执行。 您可以通过查询 DBA_AUTO_STAT_EXECUTIONS 来监控任务。
13.2.2 Setting Preferences for High-Frequency Automatic Optimizer Statistics Collection
要启用和禁用任务,请使用 DBMS_STATS.SET_GLOBAL_PREFS。
您可以使用 DBMS_STATS.SET_GLOBAL_PREFS 将首选项设置为以下任何值:
- AUTO_TASK_STATUS
启用或禁用高频自动优化器统计信息收集。 值为:- ON — 启用高频自动优化器统计信息收集。
- OFF — 禁用高频自动优化器统计信息收集。 这是默认设置。
- AUTO_TASK_MAX_RUN_TIME
配置执行高频自动优化器统计信息收集的最大运行时间(以秒为单位)。 最大值为 3600(等于 1 小时),这是默认值。 - AUTO_TASK_INTERVAL
指定执行高频自动优化器统计信息收集的时间间隔(以秒为单位)。 最小值为 60。默认值为 900(等于 15 分钟)。
要配置高频任务,您必须具有管理员权限。
示例:
-- 启用高频自动任务
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_STATUS','ON');
-- 将最长运行时间设置为 10 分钟
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_MAX_RUN_TIME','600');
-- 将频率设置为 8 分钟
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_INTERVAL','240');
13.2.3 High-Frequency Automatic Optimizer Statistics Collection: Example
在此示例中,您运行 DML 语句,然后启用高频统计收集作业。
此示例假定以下内容:
- 您以管理员身份登录到数据库。
- sh 模式的统计信息是最新的。
exec dbms_stats.gather_schema_stats('SH'); - 高频自动优化器统计信息收集未启用。
SET LINESIZE 170
SET PAGESIZE 5000
COL TABLE_NAME FORMAT a20
COL PARTITION_NAME FORMAT a20
COL NUM_ROWS FORMAT 9999999
COL STALE_STATS FORMAT a3SELECT TABLE_NAME, PARTITION_NAME, NUM_ROWS, STALE_STATS
FROM DBA_TAB_STATISTICS
WHERE OWNER = 'SH'
AND TABLE_NAME IN ('CUSTOMERS','SALES')
ORDER BY TABLE_NAME, PARTITION_NAME;TABLE_NAME PARTITION_NAME NUM_ROWS STA
-------------------- -------------------- -------- ---
CUSTOMERS 55500 NO
SALES SALES_1995 0 NO
SALES SALES_1996 0 NO
SALES SALES_H1_1997 0 NO
SALES SALES_H2_1997 0 NO
SALES SALES_Q1_1998 43687 NO
SALES SALES_Q1_1999 64186 NO
SALES SALES_Q1_2000 62197 NO
SALES SALES_Q1_2001 60608 NO
SALES SALES_Q1_2002 0 NO
SALES SALES_Q1_2003 0 NO
SALES SALES_Q2_1998 35758 NO
SALES SALES_Q2_1999 54233 NO
SALES SALES_Q2_2000 55515 NO
SALES SALES_Q2_2001 63292 NO
SALES SALES_Q2_2002 0 NO
SALES SALES_Q2_2003 0 NO
SALES SALES_Q3_1998 50515 NO
SALES SALES_Q3_1999 67138 NO
SALES SALES_Q3_2000 58950 NO
SALES SALES_Q3_2001 65769 NO
SALES SALES_Q3_2002 0 NO
SALES SALES_Q3_2003 0 NO
SALES SALES_Q4_1998 48874 NO
SALES SALES_Q4_1999 62388 NO
SALES SALES_Q4_2000 55984 NO
SALES SALES_Q4_2001 69749 NO
SALES SALES_Q4_2002 0 NO
SALES SALES_Q4_2003 0 NO
SALES 918843 NO 30 rows selected.
以上输出显示没有任何统计信息是陈旧的。
对销售和客户表执行 DML:
-- insert 918,843 rows in sales
INSERT INTO sh.sales SELECT * FROM sh.sales;
-- update around 29% of sales rows (271,338)
UPDATE sh.sales SET amount_sold = amount_sold + 1 WHERE amount_sold > 100;
-- insert 1 row into customers
INSERT INTO sh.customers(cust_id, cust_first_name, cust_last_name, cust_gender, cust_year_of_birth, cust_main_phone_number, cust_street_address, cust_postal_code, cust_city_id, cust_city, cust_state_province_id, cust_state_province, country_id, cust_total, cust_total_id) VALUES(188710, 'Jenny', 'Smith', 'F', '1966', '555-111-2222', '400 oracle parkway','94065',51402, 'Redwood Shores', 52564, 'CA', 52790, 'Customer total', '52772');
COMMIT;
将优化器统计信息保存到磁盘:
EXEC DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO;
再次查询表统计信息:
ABLE_NAME PARTITION_NAME NUM_ROWS STA
-------------------- -------------------- -------- ---
CUSTOMERS 55500 NO
SALES SALES_1995 0 NO
SALES SALES_1996 0 NO
SALES SALES_H1_1997 0 NO
SALES SALES_H2_1997 0 NO
SALES SALES_Q1_1998 43687 YES
SALES SALES_Q1_1999 64186 YES
SALES SALES_Q1_2000 62197 YES
SALES SALES_Q1_2001 60608 YES
SALES SALES_Q1_2002 0 NO
SALES SALES_Q1_2003 0 NO
SALES SALES_Q2_1998 35758 YES
SALES SALES_Q2_1999 54233 YES
SALES SALES_Q2_2000 55515 YES
SALES SALES_Q2_2001 63292 YES
SALES SALES_Q2_2002 0 NO
SALES SALES_Q2_2003 0 NO
SALES SALES_Q3_1998 50515 YES
SALES SALES_Q3_1999 67138 YES
SALES SALES_Q3_2000 58950 YES
SALES SALES_Q3_2001 65769 YES
SALES SALES_Q3_2002 0 NO
SALES SALES_Q3_2003 0 NO
SALES SALES_Q4_1998 48874 YES
SALES SALES_Q4_1999 62388 YES
SALES SALES_Q4_2000 55984 YES
SALES SALES_Q4_2001 69749 YES
SALES SALES_Q4_2002 0 NO
SALES SALES_Q4_2003 0 NO
SALES 918843 YES30 rows selected.
前面的输出显示统计数据对于客户表来说不是陈旧的,但对于销售表来说是陈旧的。
配置高频自动优化器统计收集:
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_STATUS','ON');
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_MAX_RUN_TIME','180');
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_INTERVAL','240');
等待几分钟,然后查询数据字典:
COL OPID FORMAT 9999
COL STATUS FORMAT a11
COL ORIGIN FORMAT a20
COL COMPLETED FORMAT 99999
COL FAILED FORMAT 99999
COL TIMEOUT FORMAT 99999
COL INPROG FORMAT 99999SELECT OPID, ORIGIN, STATUS, TO_CHAR(START_TIME, 'DD/MM HH24:MI:SS' ) AS BEGIN_TIME,TO_CHAR(END_TIME, 'DD/MM HH24:MI:SS') AS END_TIME, COMPLETED, FAILED,TIMED_OUT AS TIMEOUT, IN_PROGRESS AS INPROG
FROM DBA_AUTO_STAT_EXECUTIONS
ORDER BY OPID;
输出显示高频作业执行了2次,标准的自动统计收集作业执行了4次:
OPID ORIGIN STATUS BEGIN_TIME END_TIME COMPLETED FAILED TIMEOUT INPROG
----- -------------------- ----------- -------------- -------------- --------- ------ ------- ------487 AUTO_TASK COMPLETED 04/06 06:43:12 04/06 06:44:38 1987 1 0 0548 AUTO_TASK COMPLETED 04/06 15:45:52 04/06 15:46:21 468 1 0 0580 AUTO_TASK COMPLETED 05/06 15:55:14 05/06 15:55:41 353 1 0 0662 AUTO_TASK COMPLETED 05/06 19:58:08 05/06 19:58:21 145 1 0 0667 HIGH_FREQ_AUTO_TASK COMPLETED 05/06 20:36:34 05/06 20:36:53 233 1 0 0669 HIGH_FREQ_AUTO_TASK COMPLETED 05/06 20:40:44 05/06 20:40:48 53 1 0 06 rows selected.
复位:
EXEC DBMS_STATS.SET_GLOBAL_PREFS('AUTO_TASK_STATUS','OFF');
13.3 Gathering Optimizer Statistics Manually
作为自动统计收集的替代或补充,您可以使用 DBMS_STATS 包手动收集优化器统计信息。
13.3.1 About Manual Statistics Collection with DBMS_STATS
使用 DBMS_STATS 包来操作优化器统计信息。 您可以收集各种粒度级别的对象和列的统计信息:对象、模式和数据库。 您还可以收集物理系统的统计信息。
下表总结了收集优化器统计信息的 DBMS_STATS 过程。 此软件包不收集表集群的统计信息。 但是,您可以收集表集群中各个表的统计信息。
- GATHER_INDEX_STATS :收集索引统计信息
- GATHER_TABLE_STATS:收集表、列和索引统计信息
- GATHER_SCHEMA_STATS :收集模式中所有对象的统计信息
- GATHER_DICTIONARY_STATS :收集所有系统模式的统计信息,包括 SYS 和 SYSTEM,以及其他可选模式,例如 CTXSYS 和 DRSYS
- GATHER_DATABASE_STATS :收集数据库中所有对象的统计信息
当 OPTIONS 参数设置为 GATHER STALE 或 GATHER AUTO 时,GATHER_SCHEMA_STATS 和 GATHER_DATABASE_STATS 过程为任何具有陈旧统计信息的表和任何缺少统计信息的表收集统计信息。 如果受监视的表已修改超过 10%,则数据库会认为这些统计信息已过时并再次收集它们。
注意:如“配置自动优化器统计信息收集”中所述,您可以配置夜间作业以自动收集统计信息。
13.3.2 Guidelines for Gathering Optimizer Statistics Manually
在大多数情况下,自动统计信息收集对于以中等速度修改的数据库对象足够了。
自动收集有时可能不充分或不可用,如下所示:
- 您执行某些类型的批量加载并且不能等待维护窗口收集统计信息,因为查询必须立即执行。
- 在非代表性工作负载期间,自动统计信息收集会收集固定表的统计信息。
- 自动统计信息收集不收集系统统计信息。
- 易失性表被删除或截断,然后在当天重建。
13.3.2.1 Guideline for Setting the Sample Size
在优化器统计的上下文中,抽样是从表行的随机子集中收集统计信息。通过使数据库能够避免全表扫描和对整个表进行排序,采样可以最大限度地减少收集统计信息所需的资源。
数据库在处理表中的所有行时收集最准确的统计信息,这是一个 100% 的样本。但是,较大的样本量会增加统计数据收集操作的时间。挑战在于确定在合理时间内提供准确统计数据的样本量。
DBMS_STATS 在用户指定参数 ESTIMATE_PERCENT 时使用采样,该参数控制表中要采样的行的百分比。为了在获得必要的统计准确性的同时最大限度地提高性能,Oracle 建议 ESTIMATE_PERCENT 参数使用默认设置 DBMS_STATS.AUTO_SAMPLE_SIZE。在这种情况下,Oracle 数据库会自动选择样本大小。此设置允许使用以下内容:
- 一种比采样快得多的基于哈希的算法
该算法读取所有行并生成几乎与 100% 样本的统计数据一样准确的统计数据。 使用这种技术计算的统计数据是确定性的。 - 增量统计
- 并发统计
- 新的直方图类型
DBA_TABLES.SAMPLE_SIZE 列指示用于收集统计信息的实际样本大小。
13.3.2.2 Guideline for Gathering Statistics in Parallel
默认情况下,数据库以表或索引级别指定的并行度收集统计信息。
您可以使用 DBMS_STATS 收集过程的 degree 参数覆盖此设置。 Oracle 建议将 degree 设置为 DBMS_STATS.AUTO_DEGREE。 此设置使数据库能够根据对象大小和与并行度相关的初始化参数的设置来选择适当的并行度。
数据库可以串行或并行收集大多数统计信息。 但是,数据库不会并行收集一些索引统计信息,包括集群索引、域索引和位图连接索引。 收集并行统计信息时,数据库可以使用抽样。
注意:不要将并行收集统计信息(一个对象)与同时收集统计信息混淆(多个对象)。
13.3.2.3 Guideline for Partitioned Objects
对于分区表和索引,DBMS_STATS 可以为每个分区收集单独的统计信息,并为整个表或索引收集全局统计信息。
同样,对于复合分区,DBMS_STATS 可以为子分区、分区和整个表或索引收集单独的统计信息。
要确定要收集的分区统计信息的类型,请为 DBMS_STATS 过程指定粒度参数。 Oracle 建议将粒度设置为默认值 AUTO 以收集子分区、分区或全局统计信息,具体取决于分区类型。 ALL 设置收集所有类型的统计信息。
13.3.2.4 Guideline for Frequently Changing Objects
当表被频繁修改时,要经常收集统计信息,以免它们过时,但不要太频繁,因为收集开销会降低性能。
您可能只需要每周或每月收集新的统计数据。 最佳实践是使用脚本或作业调度程序定期运行 DBMS_STATS.GATHER_SCHEMA_STATS 和 DBMS_STATS.GATHER_DATABASE_STATS 过程。
13.3.2.5 Guideline for External Tables
因为数据库不允许对外部表进行数据操作,所以数据库永远不会将外部表上的统计信息标记为过时。 如果外部表需要新的统计信息,例如,因为基础数据文件发生更改,则重新收集统计信息。
对于外部表,使用与内部表相同的 DBMS_STATS 过程。 请注意,DBMS_STATS.SET_TABLE_STATS 和 DBMS_STATS.GET_TABLE_STATS 的 scanrate 参数指定 Oracle 数据库扫描表中数据的速率(以 MB/s 为单位),并且仅与外部表相关。 SCAN_RATE 列出现在 DBA_TAB_STATISTICS 和 DBA_TAB_PENDING_STATS 数据字典视图中。
13.3.3 Determining When Optimizer Statistics Are Stale
表的陈旧统计信息不能准确反映其数据。 为了帮助您确定数据库对象何时需要新的统计信息,数据库提供了一个表监控工具。
监控跟踪表上 DML 操作的大致数量以及自最近一次统计信息收集以来该表是否已被截断。 要检查统计信息是否过时,请查询 DBA_TAB_STATISTICS 和 DBA_IND_STATISTICS 中的 STALE_STATS 列。 此列基于 DBA_TAB_MODIFICATIONS 视图中的数据和 DBMS_STATS 的 STALE_PERCENT 首选项。
注意:从 Oracle Database 12c 第 2 版 (12.2) 开始,您不再需要使用 DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO 来确保视图元数据是最新的。 DBA_TAB_STATISTICS、DBA_IND_STATISTICS 和 DBA_TAB_MODIFICATIONS 视图中显示的统计信息是从磁盘和内存中获取的。
STALE_STATS 列具有以下可能值:
- YES
统计数据是陈旧的。 - NO
统计数据并不过时。 - null
不收集统计信息。
使用 GATHER AUTO 选项执行 GATHER_SCHEMA_STATS 或 GATHER_DATABASE_STATS 只会收集没有统计信息或过时统计信息的对象的统计信息。
例如:
COL PARTITION_NAME FORMAT a15SELECT PARTITION_NAME, STALE_STATS
FROM DBA_TAB_STATISTICS
WHERE TABLE_NAME = 'SALES'
AND OWNER = 'SH'
ORDER BY PARTITION_NAME;PARTITION_NAME STA
--------------- ---
SALES_1995 NO
SALES_1996 NO
SALES_H1_1997 NO
SALES_H2_1997 NO
SALES_Q1_1998 YES
...
13.3.4 Gathering Schema and Table Statistics
使用 GATHER_TABLE_STATS 收集表统计信息,并使用 GATHER_SCHEMA_STATS 收集模式中所有对象的统计信息。
例如:
-- degree表示并行度
BEGINDBMS_STATS.GATHER_TABLE_STATS ( ownname => 'sh'
, tabname => 'customers'
, degree => 2
);
END;
/
13.3.5 Gathering Statistics for Fixed Objects
固定对象是动态性能表及其索引。 这些对象记录当前的数据库活动。
与其他数据库表不同,当缺少优化器统计信息时,数据库不会自动对引用 X$ 表的 SQL 语句使用动态统计信息。 相反,优化器使用预定义的默认值。 这些默认值可能不具有代表性,并且可能导致次优的执行计划。 因此,保持固定对象统计信息是最新的很重要。
如果以前没有收集过固定对象统计信息,则 Oracle 数据库会自动收集固定对象统计信息,作为自动统计信息收集的一部分。 您还可以通过调用 DBMS_STATS.GATHER_FIXED_OBJECTS_STATS 手动收集有关固定对象的统计信息。 Oracle 建议您在数据库具有代表性活动时收集统计信息。
先决条件:您必须具有 SYSDBA 或 ANALYZE ANY DICTIONARY 系统特权才能执行此过程。
例如:
BEGINDBMS_STATS.GATHER_FIXED_OBJECTS_STATS;
END;
/
13.3.6 Gathering Statistics for Volatile Tables Using Dynamic Statistics
易失性表的统计信息,即在白天被显著修改的表,很快就会过时。 例如,一个表可能被删除或截断,然后重建。
当您将 易失性对象的统计信息设置为 null 时,Oracle 数据库会在优化期间使用动态统计信息动态收集必要的统计信息。 OPTIMIZER_DYNAMIC_SAMPLING 初始化参数控制这个特性。
假设:
- oe.orders 表非常不稳定。
- 您想删除然后锁定订单表上的统计信息,以防止数据库收集该表上的统计信息。 通过这种方式,数据库可以动态收集必要的统计信息,作为查询优化的一部分。
- oe 用户具有查询 DBMS_XPLAN.DISPLAY_CURSOR 的必要权限。
exec DBMS_STATS.DELETE_TABLE_STATS('OE','ORDERS');exec DBMS_STATS.LOCK_TABLE_STATS('OE','ORDERS');SELECT COUNT(order_id) FROM orders;
SET LINESIZE 150
SET PAGESIZE 0SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 2 (100)| |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FAST FULL SCAN| ORDER_PK | 105 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------Note
------ dynamic statistics used: dynamic sampling (level=2)-- reset
exec DBMS_STATS.UNLOCK_TABLE_STATS('OE','ORDERS');
上述执行计划中的 Note 表明数据库对 SELECT 语句使用了动态统计信息。
13.3.7 Gathering Optimizer Statistics Concurrently
Oracle 数据库可以同时收集多个表或分区的统计信息。
13.3.7.1 About Concurrent Statistics Gathering
默认情况下,分区表的每个分区是按顺序收集的。
当启用并发统计收集模式时,数据库可以同时收集模式中多个表的优化器统计信息,或者一个表中的多个分区或子分区。 并发可以通过使数据库充分使用多个处理器来减少收集统计信息所需的总时间。
注意:并发统计收集模式不依赖于并行查询处理,但可以使用它。
13.3.7.1.1 How DBMS_STATS Gathers Statistics Concurrently
Oracle 数据库采用多种工具和技术来同时创建和管理多个统计信息收集作业。
数据库使用以下手段:
- Oracle 调度程序
- Oracle 数据库高级队列 (AQ)
- Oracle 数据库资源管理器(Resource Manager)
通过使用 DBMS_STATS.SET_GLOBAL_PREF 设置 CONCURRENT 首选项来启用并发统计信息收集。
数据库运行尽可能多的并发作业。 Job Scheduler 决定并发执行多少作业以及排队执行多少作业。随着正在运行的作业完成,调度程序会出列并运行更多作业,直到数据库收集到所有表、分区和子分区的统计信息。最大作业数受 JOB_QUEUE_PROCESSES 初始化参数和可用系统资源的限制。
在大多数情况下,DBMS_STATS 过程为每个表分区或子分区创建一个单独的作业。但是,如果分区或子分区为空或非常小,那么数据库可能会自动将该对象与其他小对象批处理为单个作业,以减少作业维护的开销。
下图说明了不同级别的作业创建,其中表 3 为分区表,其他表为非分区表。作业 3 充当表 3 的协调作业,并为该表中的每个分区创建一个作业,并为表 3 的全局统计信息创建一个单独的作业。此示例假定禁用增量统计信息收集;如果启用,则数据库会在分区作业完成后从分区级别的统计信息中获取全局统计信息。

13.3.7.1.2 Concurrent Statistics Gathering and Resource Management
DBMS_STATS 包不明确管理并发统计信息收集作业使用的资源,这些作业是用户发起的统计信息收集调用的一部分。
因此,数据库可以在并发统计收集期间充分使用系统资源。 要解决这种情况,请使用资源管理器来限制并发统计收集作业所消耗的资源。 必须启用资源管理器才能同时收集统计信息。
系统提供的消费者组 ORA A U T O T A S K 注 册 所 有 统 计 信 息 收 集 作 业 。 您 可 以 为 O R A AUTOTASK 注册所有统计信息收集作业。 您可以为 ORA AUTOTASK注册所有统计信息收集作业。您可以为ORAAUTOTASK 创建具有适当资源分配的资源计划,以防止并发统计信息收集消耗所有可用资源。 如果您缺少自己的资源计划,并且选择不创建资源计划,请考虑使用系统提供的 DEFAULT_PLAN 激活资源管理器。
注意:ORA$AUTOTASK 消费者组与维护窗口期间自动运行的维护任务共享。 因此,当为自动统计收集激活并发时,数据库会自动管理资源,无需额外步骤。
13.3.7.2 Enabling Concurrent Statistics Gathering
要启用并发统计信息收集,请使用 DBMS_STATS.SET_GLOBAL_PREFS 过程来设置 CONCURRENT 首选项。
可能的值如下:
- MANUAL
仅对手动统计信息收集启用并发。 - AUTOMATIC
仅对自动统计信息收集启用并发。 - ALL
为手动和自动统计收集启用并发。 - OFF
手动和自动统计收集的并发性被禁用。 这是默认值。
本节中的本教程解释了如何启用并发统计信息收集。
本教程具有以下先决条件:
- 除了收集统计数据的标准权限外,您还必须具有以下权限:
CREATE JOB
MANAGE SCHEDULER
MANAGE ANY QUEUE - SYSAUX 表空间必须在线,因为调度程序将其内部表和视图存储在此表空间中。
- JOB_QUEUE_PROCESSES 初始化参数必须至少设置为 4。
- 必须启用资源管理器。
默认情况下,资源管理器处于禁用状态。 如果您没有资源计划,请考虑使用系统提供的 DEFAULT_PLAN 启用资源管理器。
本教程假定您要执行以下操作:
- 启用并发统计信息收集
- 收集 sh 模式的统计信息
- 监控 sh 统计信息的收集
ALTER SYSTEM SET RESOURCE_MANAGER_PLAN = 'DEFAULT_PLAN';
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=8;BEGINDBMS_STATS.SET_GLOBAL_PREFS('CONCURRENT','ALL');
END;
/SELECT DBMS_STATS.GET_PREFS('CONCURRENT') FROM DUAL;DBMS_STATS.GET_PREFS('CONCURRENT')
----------------------------------
ALLEXEC DBMS_STATS.GATHER_SCHEMA_STATS('SH');SET LINESIZE 1000COLUMN TARGET FORMAT a8
COLUMN TARGET_TYPE FORMAT a25
COLUMN JOB_NAME FORMAT a14
COLUMN START_TIME FORMAT a40SELECT TARGET, TARGET_TYPE, JOB_NAME, TO_CHAR(START_TIME, 'dd-mon-yyyy hh24:mi:ss')
FROM DBA_OPTSTAT_OPERATION_TASKS
WHERE STATUS = 'IN PROGRESS'
AND OPID = (SELECT MAX(ID) FROM DBA_OPTSTAT_OPERATIONS WHERE OPERATION = 'gather_schema_stats');TARGET TARGET_TYPE JOB_NAME TO_CHAR(START_TIME,'DD-MON-YY
------------------------------ ------------------------- -------------- -----------------------------
"SH"."SALES" TABLE ST$SD130_1_B10 05-jun-2022 22:14:33
"SH"."SALES"."SALES_Q4_1999" TABLE PARTITION ST$SD130_1_B10 05-jun-2022 22:14:34 EXEC DBMS_STATS.SET_GLOBAL_PREFS('CONCURRENT','OFF');
13.3.7.3 Monitoring Statistics Gathering Operations
您可以使用数据字典视图监控统计数据收集作业。
以下是相关视图:
- DBA_OPTSTAT_OPERATION_TASKS
此视图包含作为统计信息收集操作的一部分执行或当前正在进行的任务的历史记录(记录在 DBA_OPTSTAT_OPERATIONS 中)。 每个任务代表一个在相应父操作中要处理的目标对象。 - DBA_OPTSTAT_OPERATIONS
此视图包含使用 DBMS_STATS 包在表、模式和数据库级别执行或当前正在进行的统计操作的历史记录。
前面视图中的 TARGET 列显示了该统计信息收集作业的目标对象,格式如下:
OWNER.TABLE_NAME.PARTITION_OR_SUBPARTITION_NAME
所有收集作业名称的统计信息都以字符串 ST$ 开头。
显示当前正在运行的统计任务和作业:
SELECT OPID, TARGET, JOB_NAME, (SYSTIMESTAMP - START_TIME) AS elapsed_time
FROM DBA_OPTSTAT_OPERATION_TASKS
WHERE STATUS = 'IN PROGRESS';OPID TARGET JOB_NAME ELAPSED_TIME
---- ------------------------- ------------- --------------------------981 SH.SALES.SALES_Q4_1998 ST$T82_1_B29 +000000000 00:00:00.596321981 SH.SALES ST$SD80_1_B10 +000000000 00:00:27.972033
要显示已完成的统计任务和作业:
VARIABLE id NUMBER
EXEC :id := 679SELECT TARGET, JOB_NAME, (END_TIME - START_TIME) AS ELAPSED_TIME
FROM DBA_OPTSTAT_OPERATION_TASKS
WHERE STATUS <> 'IN PROGRESS'
AND OPID = :id;TARGET JOB_NAME ELAPSED_TIME
------------------------------ -------------- -------------------
"SH"."CAL_MONTH_SALES_MV" +00 00:00:00.012363
"SH"."CHANNELS" +00 00:00:00.020443
"SH"."CHANNELS_PK" +00 00:00:00.004418
"SH"."COSTS" +00 00:00:00.320031
"SH"."COSTS"."COSTS_1995" +00 00:00:00.001306
"SH"."COSTS"."COSTS_1996" +00 00:00:00.001292
"SH"."COSTS"."COSTS_H1_1997" +00 00:00:00.001050
...
要显示统计信息收集失败的任务和作业:
SET LONG 10000SELECT TARGET, JOB_NAME AS NM,(END_TIME - START_TIME) AS ELAPSED_TIME, NOTES
FROM DBA_OPTSTAT_OPERATION_TASKS
WHERE STATUS = 'FAILED';TARGET NM ELAPSED_TIME NOTES
"SYS"."X$LOGMNR_CONTENTS" +00 00:00:00.066861 <error>ORA-20000: Unable to analyze TABLE "SYS"."X$LOGMNR_CONTENTS", log miner or data guard must be started before analyzing this fixed table"</error>
"SYS"."X$LOGMNR_CONTENTS" +00 00:00:00.085986 <error>ORA-20000: Unable to analyze TABLE "SYS"."X$LOGMNR_CONTENTS", log miner or data guard must be started before analyzing this fixed table"</error>
"SYS"."X$LOGMNR_CONTENTS" +00 00:00:00.080483 <error>ORA-20000: Unable to analyze TABLE "SYS"."X$LOGMNR_CONTENTS", log miner or data guard must be started before analyzing this fixed table"</error>
"SYS"."X$LOGMNR_CONTENTS" +00 00:00:00.068355 <error>ORA-20000: Unable to analyze TABLE "SYS"."X$LOGMNR_CONTENTS", log miner or data guard must be started before analyzing this fixed table"</error>
"SYS"."X$LOGMNR_CONTENTS" +00 00:00:00.045837 <error>ORA-20000: Unable to analyze TABLE "SYS"."X$LOGMNR_CONTENTS", log miner or data guard must be started before analyzing this fixed table"</error>
"SYS"."X$LOGMNR_CONTENTS" +00 00:00:00.078051 <error>ORA-20000: Unable to analyze TABLE "SYS"."X$LOGMNR_CONTENTS", log miner or data guard must be started before analyzing this fixed table"</error>
13.3.8 Gathering Incremental Statistics on Partitioned Objects
增量统计仅扫描更改的分区。 通过从分区级别的统计信息派生全局统计信息来收集大型分区表的统计信息时,增量统计信息维护可以提高性能。
13.3.8.1 Purpose of Incremental Statistics
在典型情况下,应用程序将数据加载到范围分区表的新分区中。随着应用程序添加新分区并加载数据,数据库必须收集有关新分区的统计信息并保持全局统计信息为最新。
通常,数据仓库应用程序访问大型分区表。通常这些表是按日期列分区的,只有最近的分区会经常发生 DML 更改。如果没有增量统计,统计信息收集通常使用两遍方法:
- 数据库扫描表以收集全局统计信息。
对表进行全局统计收集的全扫描可能非常昂贵,具体取决于表的大小。随着表添加分区,GATHER_TABLE_STATS 的执行时间越长,因为全局统计需要全表扫描。即使只有一小部分分区发生更改,数据库也必须执行整个表的扫描。 - 数据库扫描更改的分区以收集其分区级别的统计信息。
增量维护为数据仓库应用程序提供了巨大的性能优势,原因如下:
- 数据库必须只扫描一次表以收集分区统计信息并通过聚合分区级别的统计信息来导出全局统计信息。 因此,数据库避免了不使用增量统计时所需的两次全扫描:一次扫描分区级统计信息,另一次扫描全局级统计信息。
在后续的统计信息收集中,数据库只需要扫描过时的分区并更新它们的统计信息(包括概要)。 数据库可以从新的分区统计信息中获取全局统计信息,从而节省了全表扫描。 - 使用增量统计时,数据库仍必须收集任何分区上的统计信息,这些分区将更改全局或表级统计信息。 增量统计维护产生与从头开始收集表统计信息相同的统计信息,但性能更好。
13.3.8.2 How DBMS_STATS Derives Global Statistics for Partitioned tables
启用增量统计维护时,DBMS_STATS 仅收集统计信息并为更改的分区创建概要。 数据库还自动将分区级概要合并到全局概要中,并从分区级统计和全局概要中导出全局统计。
数据库在计算全局统计信息时通过从分区级别的统计信息导出一些全局统计信息来避免全表扫描。 例如,全局级别的行数是分区行数的总和。 甚至全局直方图也可以从分区直方图导出。
但是,数据库无法从分区级别的统计信息中导出所有统计信息,包括列的 NDV。 以下示例显示了表中两个分区的 NDV:
| 对象 | 列值 | NDV |
|---|---|---|
| Partition 1 | 1,3,3,4,5 | 4 |
| Partition 2 | 2,3,4,5,6 | 5 |
通过添加各个分区的 NDV 来计算表中的 NDV,得到的 NDV 为 9,这是不正确的。 因此,需要一种更准确的技术:概要。
13.3.8.2.1 Partition-Level Synopses
概要是一种特殊类型的统计数据,用于跟踪分区中每列的不同值 (NDV) 的数量。您可以将概要视为对不同值进行采样的内部管理结构。
数据库可以通过合并分区级别的概要,准确地得出每列的全局级别 NDV。在表 13-3 所示的示例中,数据库可以使用概要计算列的 NDV 为 6。
每个分区都以增量模式维护一个概要。将新分区添加到表中时,您只需收集新分区的统计信息。数据库通过将新分区概要与现有分区的概要聚合来自动更新全局统计信息。随后的统计信息收集操作比不使用概要时更快。
数据库将概要存储在 SYSAUX 表空间中的数据字典表 WRI$_OPTSTAT_SYNOPSIS_HEAD$ 和 WRI$_OPTSTAT_SYNOPSIS$ 中。 DBA_PART_COL_STATISTICS 字典视图包含分区中的列统计信息。如果 NOTES 列包含关键字 INCREMENTAL,则此列具有概要。
13.3.8.2.2 NDV Algorithms: Adaptive Sampling and HyperLogLog
从 Oracle Database 12c 第 2 版 (12.2) 开始,HyperLogLog 算法可以提高 NDV(不同值的数量)计算性能,还可以减少概要所需的存储空间。
计算 NDV 的传统算法使用自适应采样。 概要是不同值的样本。 在计算 NDV 时,数据库最初将每个不同的值存储在哈希表中。 每个不同的值占用一个不同的哈希桶,因此具有 5000 个不同值的列有 5000 个哈希桶。 然后数据库将哈希桶的数量减半,然后继续将结果减半,直到剩下少量的桶。 该算法是“自适应的”,因为采样率根据哈希表拆分的数量而变化。
为了计算列的 NDV,数据库使用以下公式,其中 B 是执行所有拆分后剩余的哈希桶数,S 是拆分数:
NDV = B * 2^S
自适应采样会产生准确的 NDV 统计数据,但会产生以下后果:
- 概要占用大量磁盘空间,尤其是当表具有许多列和分区,并且每列中的 NDV 很高时。
例如,一个 60 列的表可能有 300,000 个分区,平均每列 NDV 为 5,000。 在此示例中,每个分区有 300,000 个条目 (60 x 5000)。 概要表总共有 900 亿个条目(300,000 平方),占用至少 720 GB 的存储空间。 - 概要的批量处理会对性能产生负面影响。
在数据库重新收集关于陈旧分区的统计信息之前,它必须删除相关的概要。 批量删除可能会很慢,因为它会生成大量的撤消和重做数据。
与动态采样相比,HyperLogLog 算法使用随机化技术。虽然算法很复杂,但基本观点是,在随机值流中,n 个不同的值将平均间隔 1/n。因此,如果您知道流中的最小值,则可以粗略估计不同值的数量。例如,如果值的范围是 0 到 1,并且如果观察到的最小值是 0.2,那么这些数字将平均间隔 0.2,因此 NDV 估计值为 5。
HyperLogLog 算法扩展并修正了原始估计。数据库将散列函数应用于每个列值,从而产生一组与列具有相同基数的散列值。对于基本估计,NDV 等于 2n,其中 n 是在哈希值的二进制表示中观察到的尾随零的最大数量。数据库通过使用部分输出将值拆分到不同的哈希桶中来优化其 NDV 估计。
HyperLogLog 算法相对于自适应采样的优点是:
- 新算法的准确性与原算法相似。
- 所需的内存显著降低,这通常会导致概要大小的大幅减少。
当存在许多分区并且它们具有许多具有高 NDV 的列时,概要可能会变得很大。 使用 HyperLogLog 算法的概要更紧凑。 创建和删除概要会影响批处理运行时间。 任何管理分区的操作过程都会减少运行时间。
DBMS_STATS 首选项 APPROXIMATE_NDV_ALGORITHM 确定数据库用于 NDV 计算的算法。
13.3.8.2.3 Aggregation of Global Statistics Using Synopses: Example
在此示例中,数据库收集 sales 表的前六个分区的统计信息,然后为每个分区(S1、S2 等)创建概要。 数据库通过聚合分区级别的统计信息和概要来创建全局统计信息。

下图显示了一个新分区,其中包含 5 月 24 日的数据,它被添加到 sales 表中。 数据库为新添加的分区收集统计信息,检索其他分区的概要,然后聚合概要以创建全局统计信息。

13.3.8.3 Gathering Statistics for a Partitioned Table: Basic Steps
本节说明如何收集分区表的优化器统计信息。
13.3.8.3.1 Considerations for Incremental Statistics Maintenance
启用增量统计维护有几个后果。
具体来说,请注意以下几点:
- 如果表使用复合分区,那么数据库只收集修改过的子分区的统计信息。数据库不会在子分区级别收集未修改子分区的统计信息。这样,数据库通过跳过未修改的分区来减少工作量。
- 如果表使用增量统计,并且该表具有本地分区索引,则数据库会在全局级别收集索引统计信息并针对已修改(而非未修改)的索引分区。数据库不会从分区级索引统计信息中生成全局索引统计信息。相反,数据库通过执行全索引扫描来收集全局索引统计信息。
- 混合分区表包含内部和外部分区。仅对于内部分区,DDL 更改调用单个分区和表本身的增量统计维护。例如,如果june18是内部分区,则ALTER TABLE … MODIFY PARTITION jun18 …在统计收集期间触发增量统计维护;但是,如果 June18 是外部分区,则不会发生增量维护。
- SYSAUX 表空间消耗额外的空间来维护分区表的全局统计信息。
13.3.8.3.2 Enabling Incremental Statistics Using SET_TABLE_PREFS
要为分区表启用增量统计信息维护,请使用 DBMS_STATS.SET_TABLE_PREFS 将 INCREMENTAL 值设置为 true。 当 INCREMENTAL 设置为 false(默认值)时,数据库使用全表扫描来维护全局统计信息。
数据库要通过仅扫描已更改的分区来增量更新全局统计信息,必须满足以下条件:
- 分区表的 PUBLISH 值为 true。
- 分区表的 INCREMENTAL 值为 true。
- 统计信息收集过程必须为 ESTIMATE_PERCENT 指定 AUTO_SAMPLE_SIZE,为 GRANULARITY 指定 AUTO。
假设分区表 sh.sales 的 PUBLISH 值为 true。 以下程序启用此表的增量统计:
EXEC DBMS_STATS.SET_TABLE_PREFS('sh', 'sales', 'INCREMENTAL', 'TRUE');
13.3.8.3.3 About the APPROXIMATE_NDV_ALGORITHM Settings
DBMS_STATS.APPROXIMATE_NDV_ALGORITHM 首选项指定概要生成算法,HyperLogLog 或自适应采样。 INCREMENTAL_STALENESS 首选项控制数据库何时重新格式化使用自适应采样格式的概要。
APPROXIMATE_NDV_ALGORITHM 首选项具有以下可能值:
- REPEAT 或 HYPERLOGLOG
这是默认设置。 如果在表上启用了 INCREMENTAL,则数据库会保留使用自适应采样算法的任何现有概要的格式。 但是,数据库会以 HyperLogLog 格式创建任何新的概要。 当现有性能可以接受并且您不希望因重新格式化遗留内容而产生性能成本时,这种方法很有吸引力。 - ADAPTIVE SAMPLING
数据库对所有概要使用自适应采样算法。 这是最保守的选择。 - HYPERLOGLOG
数据库对所有新的和陈旧的概要使用 HyperLogLog 算法。
INCREMENTAL_STALENESS 首选项控制概要何时被认为是陈旧的。当 APPROXIMATE_NDV_ALGORITHM 首选项设置为 HYPERLOGLOG 时,将应用以下 INCREMENTAL_STALENESS 设置:
- ALLOW_MIXED_FORMAT
这是默认设置。如果指定了此值,并且满足以下条件,则数据库不会将现有的自适应采样概要视为陈旧:- 概要较新。
- 您手动收集统计信息。
因此,旧版和 HyperLogLog 格式的概要可以共存。但是,随着时间的推移,自动统计收集作业会重新收集使用旧格式的概要的统计信息,并将其替换为 HyperLogLog 格式的概要。这样,自动统计收集作业逐渐淘汰旧格式。手动统计收集作业不会重新格式化使用自适应采样格式的概要。
- Null
任何带有旧格式概要的分区都被认为是过时的,这会立即触发数据库重新收集过时概要的统计信息。优点是性能成本只发生一次。缺点是重新收集大型表上的所有统计信息可能会占用大量资源。
13.3.8.3.4 Configuring Synopsis Generation: Examples
这些示例显示了将概要切换到新的 HyperLogLog 格式的不同方法,包括保守的和激进的。
示例 13-4 采用保守方法重新格式化概要
在此示例中,您允许 sh.sales 表共存混合格式的提要。 混合格式产生不太准确的统计数据。 但是,您不需要重新收集表的所有分区的统计信息。
要确保所有新的和陈旧的概要都使用 HyperLogLog 算法,请将 APPROXIMATE_NDV_ALGORITHM 首选项设置为 HYPERLOGLOG。 为了确保自动统计收集作业随着时间的推移逐渐重新格式化陈旧的概要,请将 INCREMENTAL_STALENESS 首选项设置为 ALLOW_MIXED_FORMAT。
BEGINDBMS_STATS.SET_TABLE_PREFS( ownname => 'sh', tabname => 'sales', pname => 'approximate_ndv_algorithm', pvalue => 'hyperloglog' );DBMS_STATS.SET_TABLE_PREFS( ownname => 'sh', tabname => 'sales', pname => 'incremental_staleness', pvalue => 'allow_mixed_format' );
END;
示例 13-5 采用激进的方法重新格式化提要
在此示例中,您强制所有概要对 sh.sales 表使用 HyperLogLog 算法。 在这种情况下,数据库必须重新收集表的所有分区的统计信息。
要确保所有新的和陈旧的概要都使用 HyperLogLog 算法,请将 APPROXIMATE_NDV_ALGORITHM 首选项设置为 HYPERLOGLOG。 要强制数据库立即重新收集表中所有分区的统计信息并以新格式存储它们,请将 INCREMENTAL_STALENESS 首选项设置为 null。
BEGINDBMS_STATS.SET_TABLE_PREFS( ownname => 'sh', tabname => 'sales', pname => 'approximate_ndv_algorithm', pvalue => 'hyperloglog' );DBMS_STATS.SET_TABLE_PREFS( ownname => 'sh', tabname => 'sales', pname => 'incremental_staleness', pvalue => 'null' );
END;
13.3.8.4 Maintaining Incremental Statistics for Partition Maintenance Operations
分区维护操作是与分区相关的操作,例如添加、交换、合并或拆分表分区。
Oracle 数据库为增量统计维护提供以下支持:
- 如果分区维护操作触发了统计信息收集,那么数据库可以重用以前与旧段一起删除的概要。
- DBMS_STATS 可以在非分区表上创建概要。 概要使数据库能够将增量统计信息作为分区交换操作的一部分进行维护,而无需在交换后显式收集有关分区的统计信息。
当 DBMS_STATS 首选项 INCREMENTAL 在表上设置为 true 时,INCREMENTAL_LEVEL 首选项控制收集哪些概要以及何时收集。 此首选项采用以下值:
- TABLE
DBMS_STATS 收集此表的表级概要。 您只能在表级别将 INCREMENTAL_LEVEL 设置为 TABLE,而不能在架构、数据库或全局级别设置。 - PARTITION (默认)
DBMS_STATS 仅在分区表的分区级别收集概要。
执行分区交换时,要在交换分区后获得概要,请将要与分区交换的表上的 INCREMENTAL 设置为 true,并将 INCREMENTAL_LEVEL 设置为 TABLE。
本教程假定以下内容:
- 您想在销售表中加载数据到空分区 p_sales_01_2010。
- 您创建一个临时表 t_sales_01_2010,然后填充该表。
- 您希望数据库维护增量统计信息作为分区交换操作的一部分,而不必在交换后显式收集有关分区的统计信息。
为临时表 t_sales_01_2010 设置增量统计首选项。
BEGINDBMS_STATS.SET_TABLE_PREFS ( ownname => 'sh'
, tabname => 't_sales_01_2010'
, pname => 'INCREMENTAL'
, pvalue => 'true'
); DBMS_STATS.SET_TABLE_PREFS ( ownname => 'sh'
, tabname => 't_sales_01_2010'
, pname => 'INCREMENTAL_LEVEL'
, pvalue => 'table'
);
END;
收集临时表 t_sales_01_2010 的统计信息:
-- DBMS_STATS 收集 t_sales_01_2010 的表级概要。
BEGINDBMS_STATS.GATHER_TABLE_STATS ( ownname => 'SH'
, tabname => 'T_SALES_01_2010'
);
END;
/
确保 sh.sales 表上的 INCREMENTAL 首选项为真。
BEGINDBMS_STATS.SET_TABLE_PREFS (ownname => 'sh'
, tabname => 'sales'
, pname => 'INCREMENTAL'
, pvalue => 'true'
);
END;
/
如果您之前从未在 INCREMENTAL 设置为 true 的情况下收集过有关 sh.sales 的统计信息,那么请收集有关要交换的分区的统计信息。
BEGINDBMS_STATS.GATHER_TABLE_STATS (ownname => 'sh'
, tabname => 'sales'
, pname => 'p_sales_01_2010'
, pvalue => granularity=>'partition'
);
END;
/
执行分区交换。
ALTER TABLE sales EXCHANGE PARTITION p_sales_01_2010 WITH TABLE t_sales_01_2010;
13.3.8.5 Maintaining Incremental Statistics for Tables with Stale or Locked Partition Statistics
从 Oracle Database 12c 开始,增量统计信息可以自动计算分区表的全局统计信息,即使分区或子分区统计信息已过时且已锁定。
在 Oracle Database 12c 之前的版本中启用增量统计时,如果分区上发生任何 DML,则优化器会认为该分区上的统计信息已过时。 因此,DBMS_STATS 必须再次收集统计信息以准确聚合全局统计信息。 此外,如果 DML 发生在其统计信息被锁定的分区上,则 DBMS_STATS 无法重新收集该分区上的统计信息,因此全表扫描是收集全局统计信息的唯一方法。 重新收集统计信息会产生性能开销。
在 Oracle Database 12c 中,统计信息首选项 INCREMENTAL_STALENESS 控制数据库如何确定分区或子分区上的统计信息是否过时。此首选项采用以下值:
- USE_STALE_PERCENT
如果 DML 更改小于为表指定的 STALE_PERCENT 首选项,则不会将分区或子分区视为陈旧。 STALE_PERCENT 的默认值为 10,这意味着如果 DML 导致超过 10% 的行更改,则该表被认为是陈旧的。 - USE_LOCKED_STATS
无论 DML 更改如何,锁定的分区或子分区统计信息都不会被视为陈旧。 - NULL(默认)
如果分区或子分区有任何 DML 更改,则将其视为陈旧。此行为与 Oracle Database 11g 行为相同。使用默认值时,保证以增量方式收集的统计信息与以非增量方式收集的统计信息相同。使用非默认值时,以增量模式收集的统计信息可能不如以非增量模式收集的统计信息准确。
您可以同时指定 USE_STALE_PERCENT 和 USE_LOCKED_STATS。 例如:
BEGINDBMS_STATS.SET_TABLE_PREFS (ownname => null
, table_name => 't'
, pname => 'incremental_staleness'
, pvalue => 'use_stale_percent,use_locked_stats'
);
END;
13.4 Gathering System Statistics Manually
系统统计信息向优化器描述硬件特性,例如 I/O 和 CPU 性能和利用率。
13.4.1 About System Statistics
系统统计信息测量 CPU 和存储的性能,以便优化器在评估计划时可以使用这些输入。
当查询执行时,它会消耗 CPU。 在许多情况下,查询也会消耗存储子系统资源。 典型查询中的每个计划可能会消耗不同比例的 CPU 和 I/O。 使用成本度量,优化器选择它估计执行最快的计划。 如果优化器知道 CPU 和存储的速度,那么它可以对每个备选方案的成本做出更精细的判断。
下图显示了具有三个可能计划的查询。 每个计划使用不同数量的 CPU 和 I/O。 在本示例中,优化器已为计划 1 分配了最低成本。

数据库在第一次启动时自动收集基本的系统统计信息,称为无工作负载统计信息。 通常,这些特性仅在硬件配置的某些方面升级时才会发生变化。
下图是添加高性能存储后的同一个数据库。 收集系统统计信息使优化器能够将存储性能考虑在内。 在此示例中,高性能存储显着降低了计划 2 和计划 3 的相对成本。 计划 1 只显示了边际改进,因为它使用了更少的 I/O。 计划 3 现在已分配最低成本。

在具有快速 I/O 基础架构的系统上,系统统计信息增加了查询选择表扫描而不是索引访问方法的可能性。
13.4.2 Guidelines for Gathering System Statistics
除非有充分的理由手动收集,否则 Oracle 建议对系统统计信息使用默认值。
系统统计信息对性能很重要,因为它们会影响数据库中执行的每条 SQL 语句。 更改系统统计信息可能会更改 SQL 执行计划,可能以意想不到或不需要的方式。 因此,Oracle 建议在更改系统统计信息之前仔细考虑这些选项。
何时考虑手动收集系统统计信息
如果您正在使用 Oracle Exadata,并且如果数据库正在运行纯数据仓库负载,那么在某些情况下使用 EXADATA 选项收集系统统计信息有助于提高性能,因为表扫描更受青睐。 但是,即使在 Exadata 上,默认值也最适合大多数工作负载。
如果您不使用 Oracle Exadata,并且选择手动收集系统统计信息,那么 Oracle 建议如下:
- 当您的环境发生物理变化时收集系统统计信息,例如,服务器获得更快的 CPU、更多内存或不同的磁盘存储。 Oracle 建议您在未由任何其他表空间使用的存储上创建新表空间后收集 noworkload 统计信息。
- 当系统具有最常见的工作负载时捕获统计信息。 收集工作负载统计信息不会产生额外的开销。
何时考虑使用默认统计信息
Oracle 建议在大多数情况下使用默认的系统统计信息。 要将系统统计信息重置为其默认值,请执行 DBMS_STATS.DELETE_SYSTEM_STATS,然后关闭并重新打开数据库。 为确保使用适当的默认值,还建议在新创建的数据库上执行此步骤。
13.4.3 Gathering System Statistics with DBMS_STATS
要手动收集系统统计信息,请使用 DBMS_STATS.GATHER_SYSTEM_STATS 过程。
13.4.3.1 About the GATHER_SYSTEM_STATS Procedure
DBMS_STATS.GATHER_SYSTEM_STATS 过程分析指定时间段内的活动(工作负载统计)或模拟工作负载(无工作负载统计)。
DBMS_STATS.GATHER_SYSTEM_STATS 的输入参数是:
- NOWORKLOAD
优化器仅根据系统特征收集统计信息,而不考虑工作负载。 - INTERVAL
经过指定的分钟数后,优化器会在数据字典或备用表(由 stattab 指定)中更新系统统计信息。统计信息基于指定时间间隔内的系统活动。 - START 和 STOP
START 开始收集统计信息。 STOP 计算经过时间段的统计信息(自 START 以来)并刷新数据字典或替代表(由 stattab 指定)。优化器忽略 INTERVAL。 - EXADATA
系统统计数据考虑了使用 Exadata 提供的独特功能,例如大 I/O 大小和高 I/O 吞吐量。优化器设置多块读取计数和 I/O 吞吐量统计信息以及 CPU 速度。
表 13-4 DBMS_STATS 包中的优化器系统统计信息
| 参数名 | 描述 | 初始化 | 收集或设置统计信息的选项 | 单位 |
|---|---|---|---|---|
| cpuspeedNW | 表示无负载 CPU 速度。 CPU 速度是每秒平均 CPU 周期数。 | 系统启动时 | 设置 aggregation_mode = NOWORKLOAD 或手动设置统计信息。 | 百万/秒 |
| ioseektim | 表示定位磁头以读取数据所需的时间。 I/O 寻道时间等于寻道时间 + 延迟时间 + 操作系统开销时间。 | 系统启动时 10(默认) | 设置 aggregation_mode = NOWORKLOAD 或手动设置统计信息。 | 毫秒 |
| iotfrspeed | 表示 Oracle 数据库可以在单个读取请求中读取数据的速率。 | 系统启动时 4096(默认) | 设置 aggregation_mode = NOWORKLOAD 或手动设置统计信息。 | 字节/毫秒 |
| cpuspeed | 表示工作负载 CPU 速度。 CPU 速度是每秒平均 CPU 周期数。 | 无 | 设置 aggregation_mode = NOWORKLOAD、INTERVAL 或 START | STOP,或手动设置统计信息。 |
| maxthr | 最大 I/O 吞吐量是 I/O 子系统可以提供的最大吞吐量。 | 无 | 设置 aggregation_mode = NOWORKLOAD、INTERVAL 或 START | STOP,或手动设置统计信息。 |
| slavethr | 从属 I/O 吞吐量是平均并行执行服务器 I/O 吞吐量。 | 无 | 设置 aggregation_mode = INTERVAL 或 START | STOP,或手动设置统计信息。 |
| sreadtim | 单块读取时间是随机读取单个块的平均时间。 | 无 | 设置 aggregation_mode = INTERVAL 或 START | STOP,或手动设置统计信息。 |
| mreadtim | 多块读取是顺序读取多块的平均时间。 | 无 | 设置 aggregation_mode = INTERVAL 或 START | STOP,或手动设置统计信息。 |
| mbrc | 多块计数是顺序的平均多块读取计数。 | 无 | 设置 aggregation_mode = INTERVAL 或 START | STOP,或手动设置统计信息。 |
13.4.3.2 Gathering Workload Statistics
Oracle 建议您在数据库具有最典型的工作负载时使用 DBMS_STATS.GATHER_SYSTEM_STATS 来捕获统计信息。
例如,数据库应用程序可以在白天处理 OLTP 事务并在晚上生成 OLAP 报告。
13.4.3.2.1 About Workload Statistics
工作负载统计分析指定时间段内的活动。
工作负载统计包括表 13-4 中列出的以下统计:
- 单块 (sreadtim) 和多块 (mreadtim) 读取时间
- 多块计数 (mbrc)
- CPU 速度 (cpuspeed)
- 最大系统吞吐量 (maxthr)
- 平均并行执行吞吐量(slavethr)
数据库通过比较从工作负载开始到结束的两个时间点之间的物理顺序读取和随机读取的数量来计算 sreadtim、mreadtim 和 mbrc。 数据库通过在缓冲区高速缓存完成同步读取请求时更改的计数器来实现这些值。
因为计数器在缓冲区缓存中,它们不仅包括 I/O 延迟,还包括与锁存器争用和任务切换相关的等待。 因此,工作负载统计取决于工作负载窗口期间的系统活动。 如果系统受 I/O 限制(闩锁争用和 I/O 吞吐量),则在数据库使用统计信息后,统计信息会倾向于I/O 密集度较低的计划。
如图 13-4 所示,如果您收集工作负载统计信息,那么优化器将使用为工作负载统计信息收集的 mbrc 值来估计全表扫描的成本。

在收集工作负载统计信息时,如果在串行工作负载期间没有发生表扫描,数据库可能不会收集 mbrc 和 mreadtim 值,这是 OLTP 系统的典型情况。 但是,全表扫描在 DSS 系统上经常发生。 这些扫描可以并行运行并绕过缓冲区缓存。 在这种情况下,数据库仍会收集 sreadtim,因为索引查找使用缓冲区缓存。
如果数据库无法收集或验证收集的 mbrc 或 mreadtim 值,但已收集 sreadtim 和 cpuspeed,则数据库仅使用 sreadtim 和 cpuspeed 进行成本计算。 在这种情况下,优化器使用初始化参数 DB_FILE_MULTIBLOCK_READ_COUNT 的值来进行全表扫描。 但是,如果 DB_FILE_MULTIBLOCK_READ_COUNT 为 0 或未设置,则优化器使用值 8 来计算成本。
使用 DBMS_STATS.GATHER_SYSTEM_STATS 过程收集工作负载统计信息。 GATHER_SYSTEM_STATS 过程刷新数据字典或包含已用时间段的统计信息的登台表。 要设置收集的持续时间,请使用以下任一技术:
- 指定 START 工作负载窗口的开头,然后指定 STOP 在工作负载窗口的结尾。
- 指定 INTERVAL 和统计信息收集自动停止前的分钟数。 如果需要,您可以使用 GATHER_SYSTEM_STATS (gathering_mode=>‘STOP’) 提前结束收集。
13.4.3.2.2 Starting and Stopping System Statistics Gathering
本教程说明如何使用 GATHER_SYSTEM_STATS 的 START 和 STOP 参数设置工作负载间隔。
本教程假定以下内容:
- 上午 10 点到 11 点之间的时间段代表了日常工作负载。
- 您打算直接在数据字典中收集系统统计信息。
上午 10 点,执行以下程序开始收集:
EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( gathering_mode => 'START' );
生成工作负载。
上午 11 点,执行以下程序结束收集:
EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( gathering_mode => 'STOP' );
优化器现在可以使用工作负载统计信息来生成在正常的日常工作负载期间有效的执行计划。
(可选)查询系统统计信息。
-- 输出中只包含3项,说明其是Noworkload Statistics
COL PNAME FORMAT a15
SELECT PNAME, PVAL1
FROM SYS.AUX_STATS$
WHERE SNAME = 'SYSSTATS_MAIN';PNAME PVAL1
--------------- ----------
CPUSPEED
CPUSPEEDNW 1512.17698
IOSEEKTIM 10
IOTFRSPEED 4096
MAXTHR
MBRC
MREADTIM
SLAVETHR
SREADTIM 9 rows selected.
13.4.3.2.3 Gathering System Statistics During a Specified Interval
本教程说明如何使用 GATHER_SYSTEM_STATS 的 INTERVAL 参数设置工作负载间隔。
本教程假定以下内容:
- 数据库应用程序在白天处理 OLTP 事务并在晚上运行 OLAP 报告。 要收集有代表性的统计数据,您需要在白天收集两个小时,然后在晚上收集两个小时。
- 您希望将统计信息存储在名为workload_stats 的表中。
- 您打算在收集的统计信息之间切换。
创建一个表来保存生产统计信息。
BEGINDBMS_STATS.CREATE_STAT_TABLE (ownname => 'dba1'
, stattab => 'workload_stats'
);
END;
/
确保 JOB_QUEUE_PROCESSES 不为 0,以便 DBMS_JOB 作业和 Oracle Scheduler 作业运行。
-- 其实可以不用执行,因为我系统默认值为40
ALTER SYSTEM SET JOB_QUEUE_PROCESSES = 1;
在白天收集统计数据。
BEGINDBMS_STATS.GATHER_SYSTEM_STATS ( interval => 120
, stattab => 'workload_stats'
, statid => 'OLTP'
);
END;
/
在晚上收集统计数据。
BEGINDBMS_STATS.GATHER_SYSTEM_STATS (interval => 120
, stattab => 'workload_stats'
, statid => 'OLAP'
);
END;
/
在白天或晚上,将适当的统计数据导入数据字典。
BEGINDBMS_STATS.IMPORT_SYSTEM_STATS (stattab => 'workload_stats'
, statid => 'OLTP'
);
END;
/BEGINDBMS_STATS.IMPORT_SYSTEM_STATS (stattab => 'workload_stats'
, statid => 'OLAP'
);
END;
/
13.4.3.3 Gathering Noworkload Statistics
无工作负载统计信息捕获 I/O 系统的特征。
默认情况下,Oracle 数据库使用无负载统计信息和 CPU 成本模型。 noworkload 统计信息的值在第一个实例启动时初始化为默认值。 您还可以使用 DBMS_STATS.GATHER_SYSTEM_STATS 过程手动收集无工作负载统计信息。
无工作负载统计信息包括表 13-4 中列出的以下系统统计信息:
- I/O 传输速度 (iotfrspeed)
- I/O 寻道时间 (ioseektim)
- CPU 速度 (cpuspeednw)
工作负载统计和无工作负载统计之间的主要区别在于收集方法。无工作负载统计通过提交对所有数据文件的随机读取来收集数据,而工作负载统计使用在数据库活动发生时更新的计数器。如果您收集工作负载统计信息,那么 Oracle 数据库将使用它们而不是无工作负载统计信息。
要收集 noworkload 统计信息,请运行不带参数或收集模式设置为 noworkload 的 DBMS_STATS.GATHER_SYSTEM_STATS。在 noworkload 统计信息的收集过程中,I/O 系统会产生开销。收集过程可能需要几秒钟到几分钟,具体取决于 I/O 性能和数据库大小。
当您收集无工作负载统计信息时,数据库会分析信息并验证其一致性。在某些情况下,noworkload 统计信息的值可能会保留其默认值。您可以再次收集统计信息,也可以使用 SET_SYSTEM_STATS 手动将值设置为 I/O 系统规范。
手动收集 noworkload 统计信息:
BEGIN DBMS_STATS.GATHER_SYSTEM_STATS ( gathering_mode => 'NOWORKLOAD'
);
END;COL PNAME FORMAT a15SELECT PNAME, PVAL1
FROM SYS.AUX_STATS$
WHERE SNAME = 'SYSSTATS_MAIN';
13.4.4 Deleting System Statistics
DBMS_STATS.DELETE_SYSTEM_STATS 过程删除系统统计信息。
此过程删除使用 INTERVAL 或 START 和 STOP 选项收集的工作负载统计信息,然后将默认设置重置为 noworkload 统计信息。 但是,如果 stattab 参数指定了用于存储统计信息的表,则子程序会从统计信息表中删除所有具有关联 statid 的系统统计信息。
如果数据库是新创建的,那么 Oracle 建议删除系统统计信息,关闭数据库,然后重新打开数据库。 这一系列步骤可确保数据库为系统统计信息建立适当的默认值。
本教程假定以下内容:
- 您收集了特定密集工作负载的统计信息,但不再希望优化器使用这些统计信息。
- 您将工作负载统计信息存储在默认位置,而不是用户指定的表中。
要删除系统统计信息:
EXEC DBMS_STATS.DELETE_SYSTEM_STATS;
13.5 Running Statistics Gathering Functions in Reporting Mode
您可以在报告模式下运行 DBMS_STATS 统计信息收集过程。
当您使用 REPORT_* 过程时,优化器实际上并不收集统计信息。 相反,如果您要使用指定的统计信息收集功能,包会报告将要处理的对象。
下表列出了 DBMS_STATS.REPORT_GATHER_*_STATS 函数。 对于所有函数,输入参数与对应的 GATHER_*_STATS 过程相同,但具有以下附加参数:detail_level 和 format。 支持的格式是 XML、HTML 和 TEXT。
- REPORT_GATHER_TABLE_STATS
- REPORT_GATHER_SCHEMA_STATS
- REPORT_GATHER_DICTIONARY_STATS
- REPORT_GATHER_DATABASE_STATS
- REPORT_GATHER_FIXED_OBJ_STATS
- REPORT_GATHER_AUTO_STATS
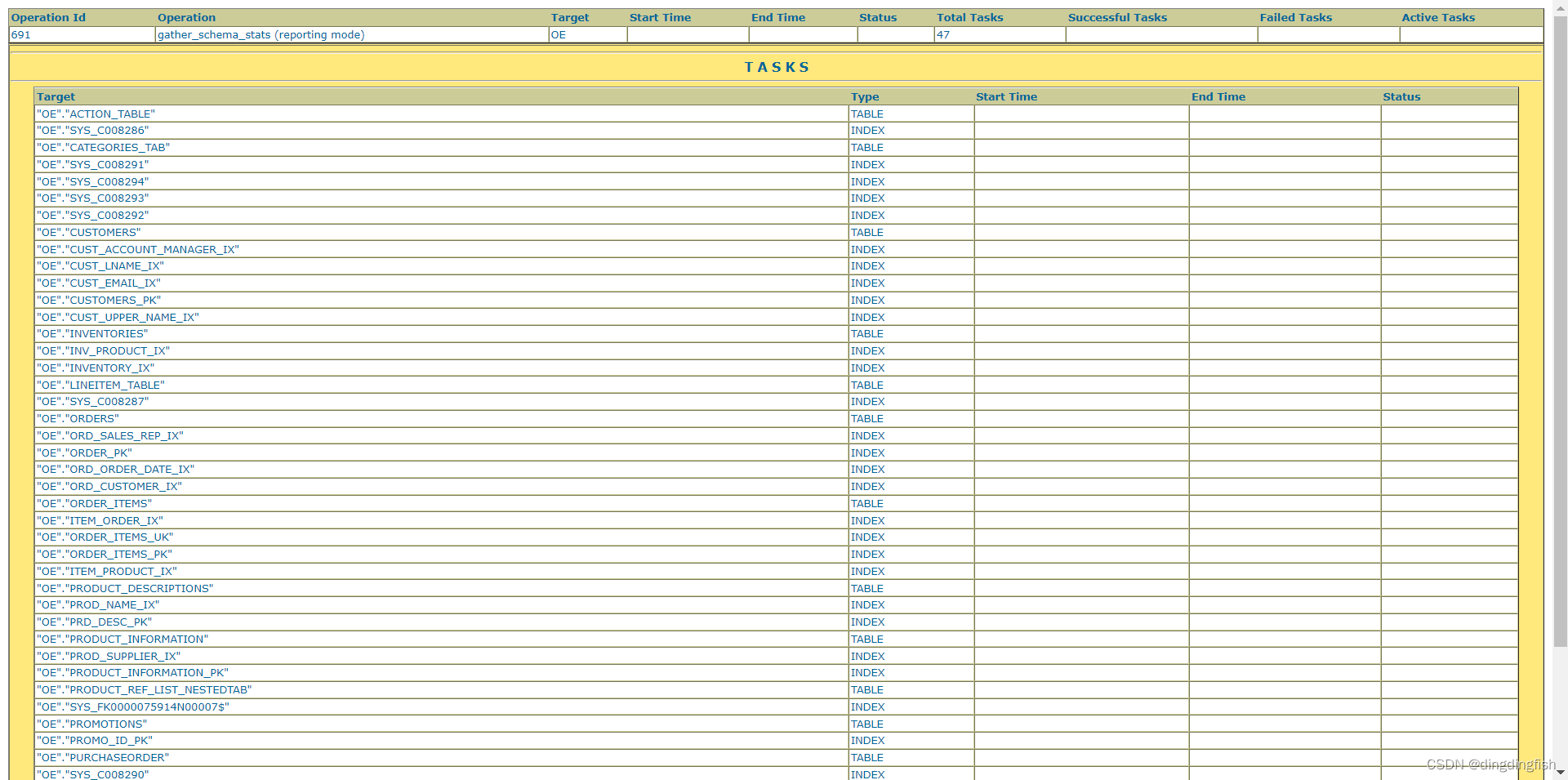
本教程假定您要生成一个 HTML 报告,其中包含在 oe 模式上运行 GATHER_SCHEMA_STATS 会影响的对象。
SET LINES 200 PAGES 0
SET LONG 100000
COLUMN REPORT FORMAT A200VARIABLE my_report CLOB;
BEGIN:my_report :=DBMS_STATS.REPORT_GATHER_SCHEMA_STATS(ownname => 'OE' , detail_level => 'TYPICAL' ,format => 'HTML' );
END;
/print my_report
这篇关于SQL调优指南笔记13:Gathering Optimizer Statistics的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




