本文主要是介绍Ubuntu22.04下安装Spark2.4.0(Local模式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、版本信息
虚拟机产品:VMware® Workstation 17 Pro 虚拟机版本:17.0.0 build-20800274
ISO映像文件:ubuntukylin-22.04-pro-amd64.iso
Hadoop版本:Hadoop 3.1.3
JDK版本:Java JDK 1.8
Spark版本:Spark 2.4.0
这里有我放的百度网盘下载链接,读者可以自行下载:
链接:https://pan.baidu.com/s/121zVsgc4muSt9rgCWnJZmw
提取码:wkk6
注意:其中的ISO映像文件为ubuntukylin-16.04.7版本的而不是22.04版本,22.04版本内存过大无法上传,见谅!!!
也可去Spark官网进行下载:Spark官方下载地址
二、安装Hadoop(伪分布式)
Spark的安装过程较为简单,在已安装好 Hadoop 的前提下,经过简单配置即可使用。
如果读者没有安装Hadoop3.1.3(伪分布式),请访问林子雨老师的Hadoop3.1.3安装教程进行Hadoop的伪分布式安装:Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)_厦大数据库实验室博客![]() https://dblab.xmu.edu.cn/blog/2441-2/
https://dblab.xmu.edu.cn/blog/2441-2/
三、安装JAVA JDK
安装Hadoop3.1.3的过程就已经要求安装JAVA JDK1.8了。如果没有,请参考林子雨老师的Hadoop安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04进行安装配置。
四、安装Spark(Local模式)
在安装Spark之前默认读者已经在虚拟机软件上安装VMware Tools,若没有安装请移步于本人的另一篇文章:真·保姆级——在VMware的Ubuntukylin上进行Hadoop单机/伪分布式安装时安装VMware Tools后虚拟机与物理机之间无法传输文件和复制粘贴的问题(附Ubuntu更改默认登录用户)-CSDN博客
1.将Spark安装包移到下载目录中
将物理机上下载的Spark安装包拖拽到读者虚拟机Ubuntu系统家目录中的下载目录中:
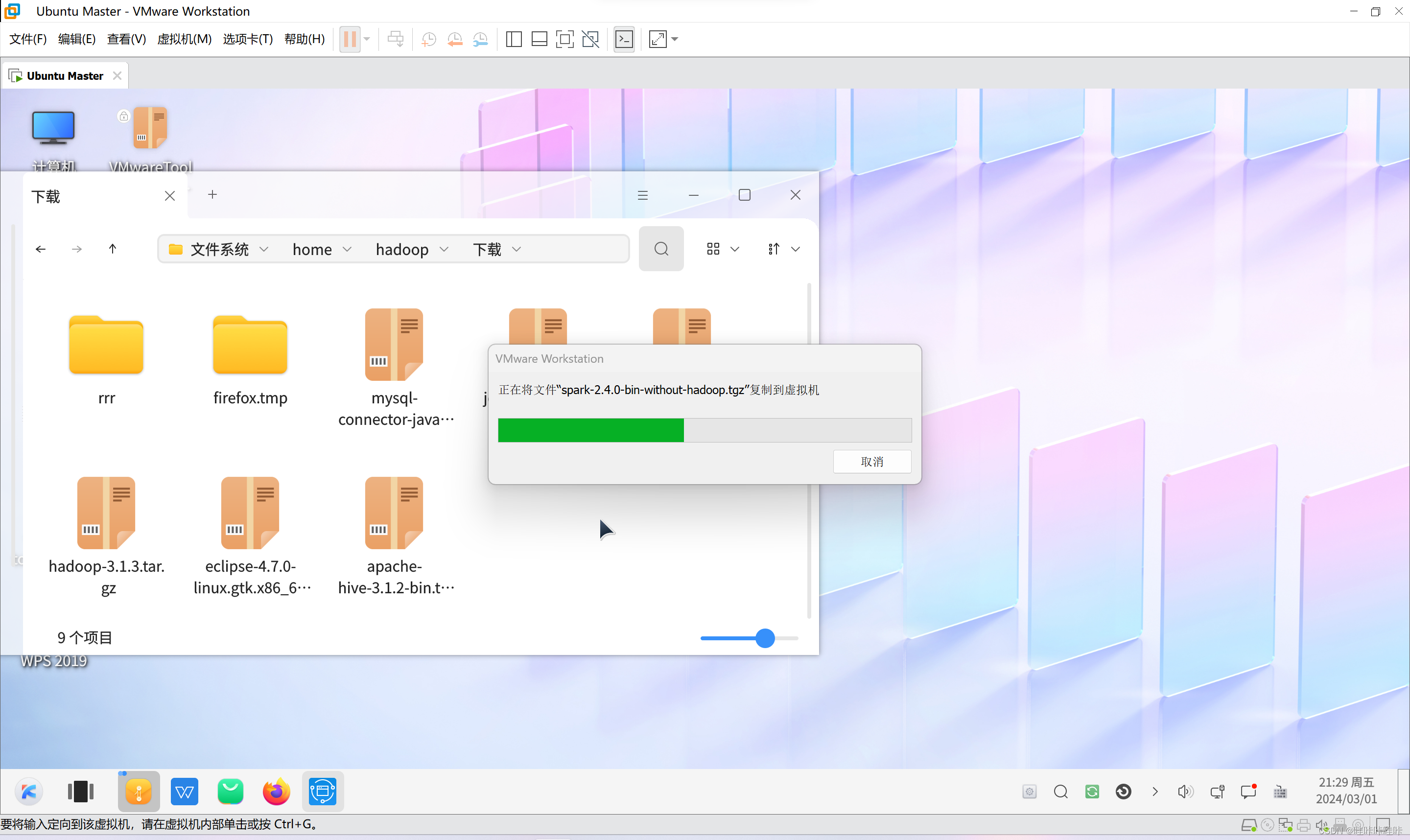
2.下载Spark并确保hadoop用户对Spark目录有操作权限
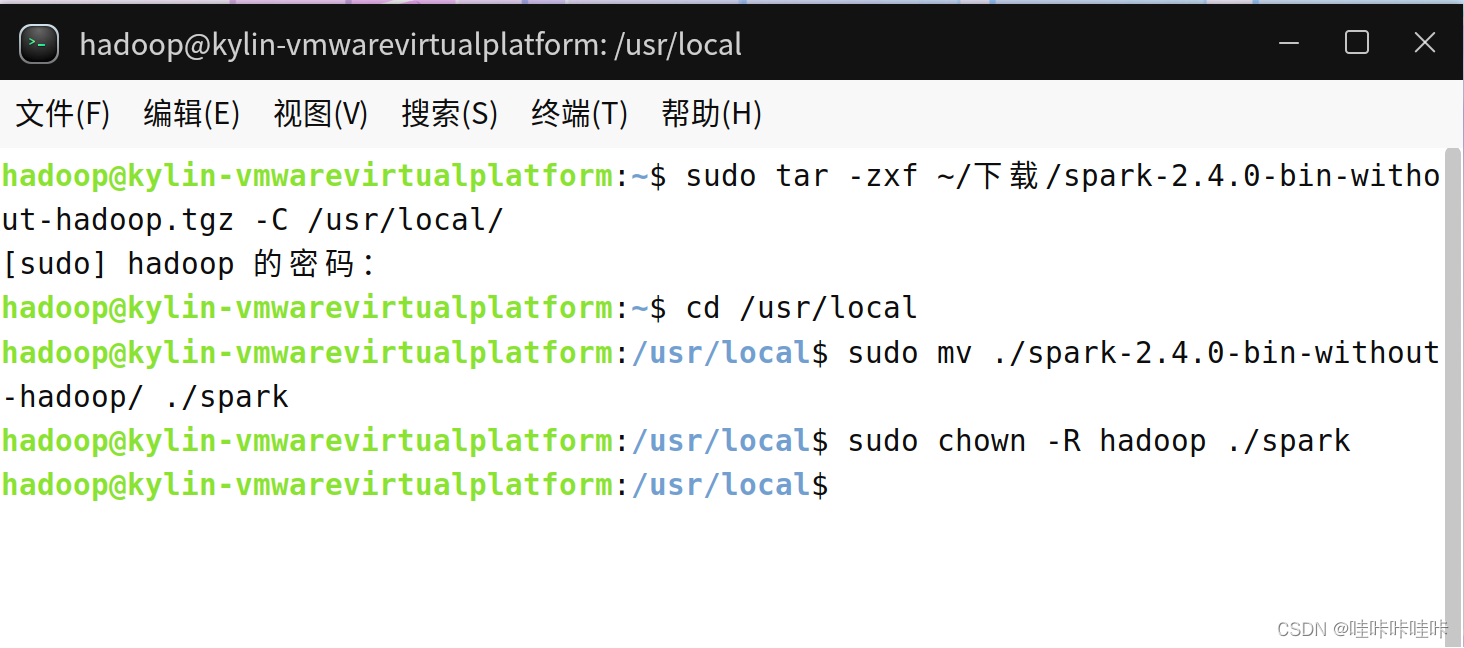
sudo tar -zxf ~/下载/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名- 将Apache Spark压缩包解压到
/usr/local/目录下 - 切换当前工作目录到
/usr/local - 将解压出来的Spark目录重命名为
spark,以便于记忆和管理 - 将
/usr/local/spark目录及其子目录和文件的所有权更改为用户hadoop,确保该用户对Spark目录有操作权限,便于后续的配置和使用
五、修改Spark的配置文件
安装Spark后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh- 切换当前工作目录到
/usr/local/spark。这个目录是Apache Spark的安装目录,之前的步骤中已经将Spark解压并重命名到这个位置 - 创建一个可编辑的环境配置文件
spark-env.sh,基于模板文件spark-env.sh.template。通过编辑这个文件,可以自定义Spark的运行环境,例如设置JVM选项、Spark的工作节点内存限制、日志配置等
编辑spark-env.sh文件:
vim ./conf/spark-env.sh
在第一行添加以下配置信息并保存:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
六、验证Spark是否安装成功
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi运行Apache Spark自带的一个示例程序 —— SparkPi。
这个示例程序计算π的值,是一个经典的计算密集型任务,常用来测试Spark集群的安装是否成功以及其基本的运行情况
下面详细解释这些命令的作用:
-
cd /usr/local/spark:这条命令将当前的工作目录切换到Apache Spark的安装目录。前提是读者已经按照之前的指导安装并配置了Spark,并且将其安装在了/usr/local/spark目录下。 -
bin/run-example SparkPi:这条命令实际上是运行Spark自带的一个示例程序。
bin/run-example是一个脚本,位于Spark安装目录下的bin文件夹中。它用于运行Spark自带的示例程序。SparkPi是要运行的示例程序的名称。这个程序通过蒙特卡洛方法计算π的值。
具体来说,这个命令的执行过程如下:
- 当执行
bin/run-example SparkPi命令时,Spark会启动一个应用程序实例,并执行计算π值的任务。 - 这个任务会被分解成多个小任务(task),并可能在一个或多个工作节点(如果读者配置了Spark集群的话)上并行执行。
- 执行完成后,程序会输出计算得到的π值。
执行时会输出非常多的运行信息,输出结果不容易找到,bin/run-example SparkPi 2>&1 | grep "Pi is"这条命令的作用是运行SparkPi示例程序,然后搜索并显示所有包含“Pi is”的输出行,显示程序计算出的π值的那一行,因此这个命令可以帮助用户直接查看计算结果,而不必手动从可能很长的程序输出中寻找相关信息。
bin/run-example SparkPi 2>&1 | grep "Pi is"下面详细解释这些命令的作用:
-
bin/run-example SparkPi:运行Spark自带的示例程序SparkPi。这个程序计算π的值,是一个用来测试Spark安装和配置是否正确的经典示例。 -
2>&1:这部分是重定向命令。2代表标准错误(stderr),1代表标准输出(stdout)。2>&1的意思是将标准错误重定向到标准输出,这样错误信息和正常输出信息都会被发送到同一个地方(即标准输出)。 -
| grep "Pi is":‘|'是管道符,它的作用是将前一个命令的输出作为后一个命令的输入。grep是一个文本搜索工具,可以根据指定的模式(pattern)搜索文本。这里,grep "Pi is"表示搜索包含“Pi is”的行。
过滤后的运行结果如下图示:

至此,Spark安装成功!!!
这篇关于Ubuntu22.04下安装Spark2.4.0(Local模式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







