本文主要是介绍【CS 61B】Data Structures, Spring 2021 -- Week 2(3. Testing 4. IntLists 5. SLLists ),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
61B 2021 Lecture 3 - Testing
[Testing, Video 1] - A New Way (本章简介)
[Testing, Video 2] Ad Hoc Testing is Not Fun (随机测试)
1、一定不要使用“==”运算符检测两个字符串是否相等!
2、补充说明
[Testing, Video 3] A Simple JUnit Test (单元测试)
[Testing, Video 4] How Selection Sort Works (选择排序)
[Testing, Video 5] Find Smallest and the Glory of Stack Overflow (找到最小项)
[Testing, Video 6] Swap (交换项目)
[Testing, Video 7] Revising Find Smallest, Overview So Far (修改findSmallest方法)
[Testing, Video 8] Recursive Array Helper Methods (递归辅助方法)
[Testing, Video 9] Debugging and Testing, BFFs (代码调试)
[Testing, Video 10] Reflections on the Process (对开发过程的思考)
[Testing, Video 11] Better JUnit (简化JUnit测试)
1、使用 JUnit 注解,使其可以被独立运行
2、导入JUnit测试包,用来消除包名前缀
[Testing, Video 12] Testing Philosophy (测试的哲学)
Correctness Tool #1: Autograder (自动评分器)
Correctness Tool #2: Unit Tests (单元测试)
Correctness Tool #3: Integration Testing (集成测试)
Testing Study Guide (小结 ⭐)
Discussion(习题课)
1、Introduction To Java
A、斐波那契数列(fib)
2、Scope, Pass by Value, Static (Exam Prep)
A、基本类型与引用类型
B、static 与 non-static
61B 2021 Lecture 4 - References, Recursion, and Lists
[Lists1, Video 1] The Mystery of the Walrus (海象的奥秘)
[Lists1, Video 2] Primitive Types (基本类型)
1、Declaring a Variable (Simplified) (声明变量)
2、Simplified Box Notation (简单的盒子表示法)
3、“=”的黄金法则(GRoE)
[Lists1, Video 3] Reference Types (引用类型)
1、Object Instantiation(对象实例化)
2、Reference Type Variable Declarations (引用变量声明)
3、Box and Pointer Notation (盒子和指针表示法)
4、Resolving the Mystery of the Walrus (解开海象之谜)
[Lists1, Video 4] Parameter Passing(参数传递)
[Lists1, Video 5] Test Your Understanding of the GRoE(测试你的理解力)
[Lists1, Video 6] Instantiating Arrays(数组的实例化)
1、The Law of the Broken Futon(Broken Futon法则)
[Lists1, Video 7] Introducing IntLists(整数列表)
[Lists1, Video 8] IntList size(递归法求列表大小)
[Lists1, Video 9] IntList iterativeSize(迭代法求列表大小)
[Lists1, Video 10] More IntList Exercises(更多练习)
Lab 2: JUnit Tests and Debugging(单元测试与Debug)
1、Pre-lab(实验准备)
2、Debugger Basics(Debugger基础)
A、Breakpoints and Step Into (断点和步进)
B、Recap: Debugging(回顾:调试)
3、JUnit and Unit Testing(单元测试)
A、JUnit 语法
4、Application: IntLists(整数递归链表)
入门代码
A、IntList Iteration(IntList 迭代)
B、Nested Helper Methods and Refactoring for Debugging(用于调试的嵌套辅助方法和重构)
C、Tricky IntLists (棘手的 IntLists)!
5、Submission & Recap(提交与回顾)
A、Result(结果)
B、Recap(回顾)
61B 2021 Lecture 5 - SLLists, Nested Classes, Sentinel Nodes(SLLists,嵌套类,哨兵节点)
[Lists2, Video 1A-7] SLList
1、Improvement #1: Rebranding(重塑IntNode)
2、Improvement #2: Bureaucracy(等级制度)
addFirst 和 getFirst
3、Improvement #3: Public vs. Private(公共与私人)
4、Improvement #4: Nested Classes(嵌套类)
addLast() 和 size()
5、Improvement #5: Caching(缓存)
6、Improvement #6: The Empty List(空列表)
7、Improvement #6b: Sentinel Nodes(哨兵节点)
Invariants (不变量)
Lists2 Study Guide(Lists2 学习指南)
1、Overview(概述)
2、Exercises(练习

61B 2021 Lecture 3 - Testing
中高级程序员可以拥有的最重要的技能之一是判断代码何时正确的能力。在本章中,我们将讨论如何编写测试来评估代码的正确性。在此过程中,我们还将讨论一种称为选择排序的排序算法。
[Testing, Video 1] - A New Way (本章简介)

(学习如何构建测试)
老方法:通过自动评分器进行测试

新方法:在我们甚至还没考虑如何排序之前,我们要先写 testSort(),只有在完成测试后,我们才会继续编写实际的排序代码
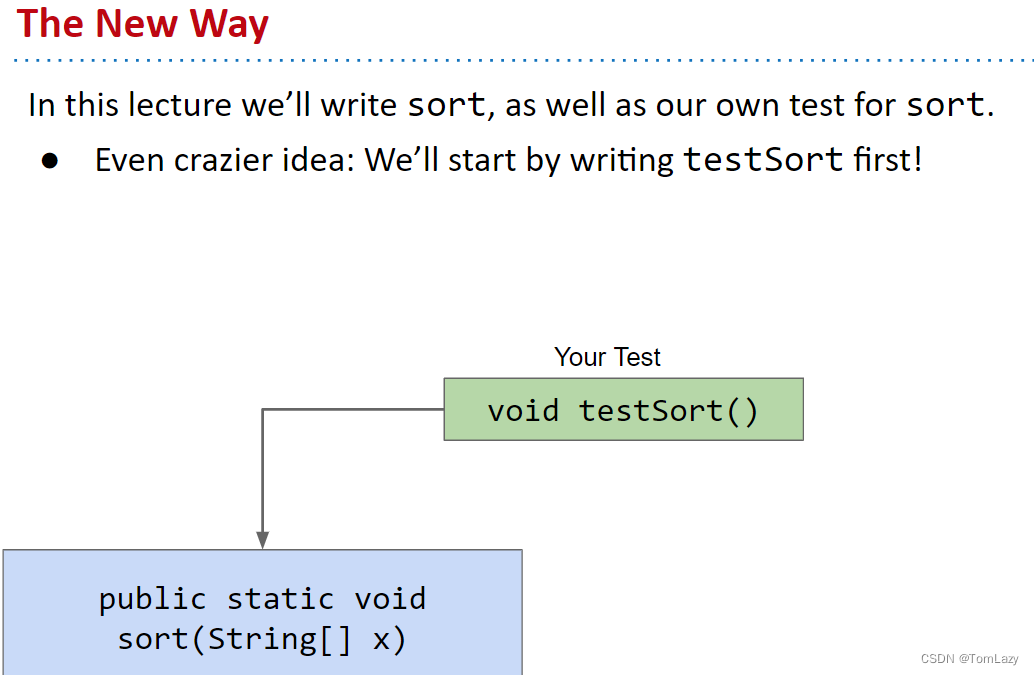
[Testing, Video 2] Ad Hoc Testing is Not Fun (随机测试)
工具:Random Word Generator(在线单词随机生成器)
1、一定不要使用“==”运算符检测两个字符串是否相等!
推荐使用 equals() 方法
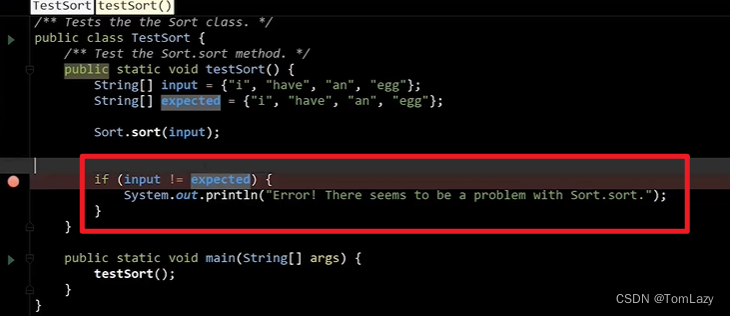
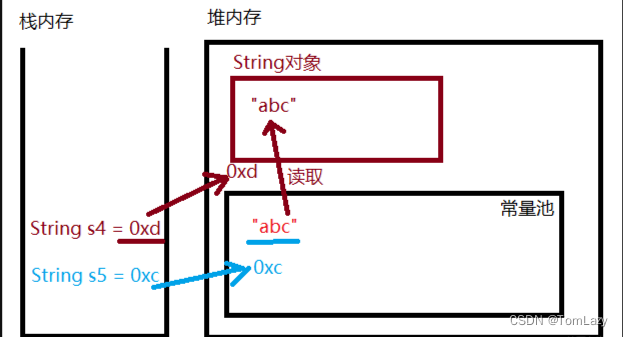
通过 Java Visualizer 我们可以看到:(虽然 input 和 expected 两个字符串数组中元素完全相同,但关系运算符“==”却认为它们不相等。这个的原因就在于:对于引用类型的变量来说,“==”运算符只能够确定两个变量是否存放在同一个位置上 ,很明显这里是两个截然不同的引用变量。)
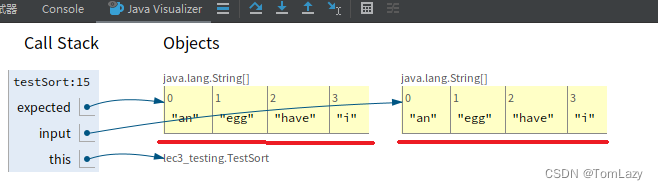
而当我们修改代码为 expected = input 时,通过 Java Visualizer 我们可以看到,此时两个变量指向的是同一个对象,这个时候两者通过“==”判断才会是相等的:
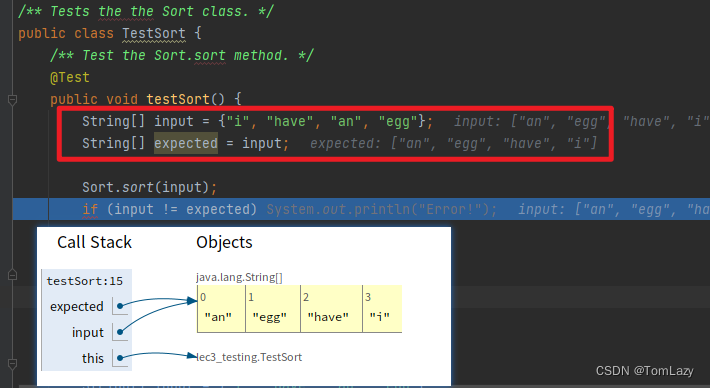
2、补充说明
| 补充说明: | ||||
| 1、字符串字面量(stringliteral):是指双引号引住的一系列字符,双引号中可以没有字符,可以只有一个字符,也可以有很多个字符。实际上在Java中,也只有字符串字面量会共享。而像通过拼接、 截取等获得的字符串均不会被共享。 | ||||
| 2、字符串常量池(StringTable):StringTable也叫串池,用于存放字符串常量,这样当我们使用相同的字符串对象时,就可以直接从StringTable中获取而不用重新创建对象。类似于IntegerCache,但区别在于一个是提前创建,一个是运行时不存在才创建。 | ||||
| 3、字符串内存模型: 只有直接赋值的字符串才会存入 StringTable,如果是new出来的则不会。
更多细节可参考:笔试题总结——String类的两种实例化方式 | ||||
| 4、打印String对象的地址
|

[Testing, Video 3] A Simple JUnit Test (单元测试)
通过使用 Junit 可以用来省略自己实现测试时大量枯燥乏味的循环判断
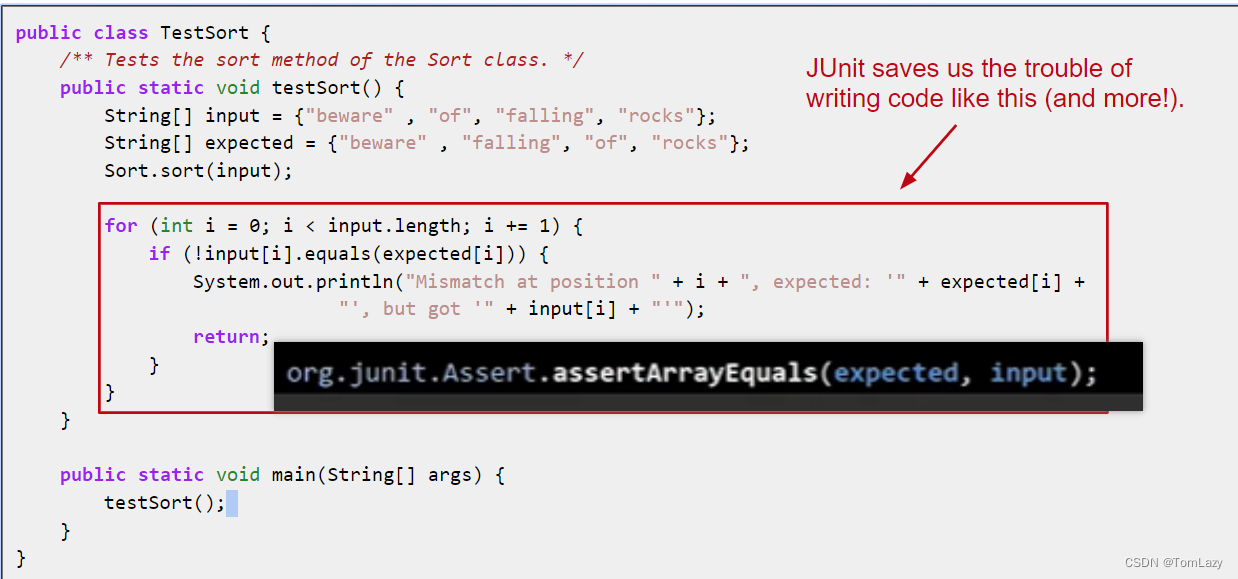
如上图所示,我们可以通过黑色背景中的那一段代码来替换掉红色框住的for循环代码,从而使得测试方法更加简单
[Testing, Video 4] How Selection Sort Works (选择排序)

选择排序的原理分为3步:
|
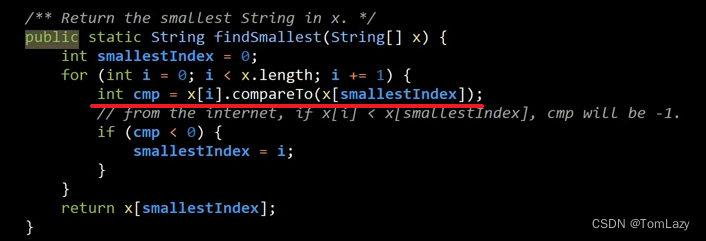
[Testing, Video 5] Find Smallest and the Glory of Stack Overflow (找到最小项)
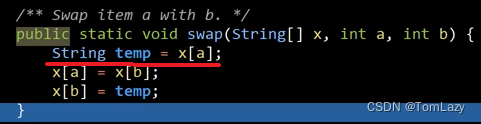
[Testing, Video 6] Swap (交换项目)
添加临时变量 temp 用于实现 Swap():
[Testing, Video 7] Revising Find Smallest, Overview So Far (修改findSmallest方法)
修改 findSmallest 方法(红线处为前后改动),让其返回当前最小项的索引:

截止目前我们已经完成:

[Testing, Video 8] Recursive Array Helper Methods (递归辅助方法)
在Python中,我们可以使用切片 x[1:] 来截取数组中除第一个元素外的所有元素,这样就保证了我们每次排序调用中,都会取掉比上一次数组少一个首元素的数组。而很遗憾的是,在Java中并不存在这样的切片方法供我们直接使用。在Java中典型的解决方案是创建一个私有的辅助方法。
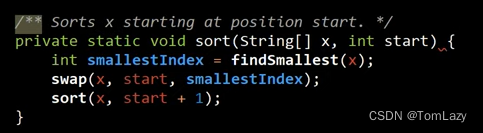
之后,我们只需要将起始值设置为0( sort(x, 0);),就能有效地对整个数组进行排序。当试图在非固有递归的数据结构(例如数组)上使用递归时,这种方法非常常见。
[Testing, Video 9] Debugging and Testing, BFFs (代码调试)
| Tips:
|
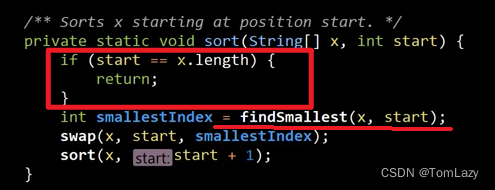
1、根据 Base Case,修复 sort辅助方法的错误:(如果不对 start 加以限制,start 就会超出数组范围,导致数组索引越界问题),之后根据 findSmallest 方法的修改,再回过头来修改 sort 方法:
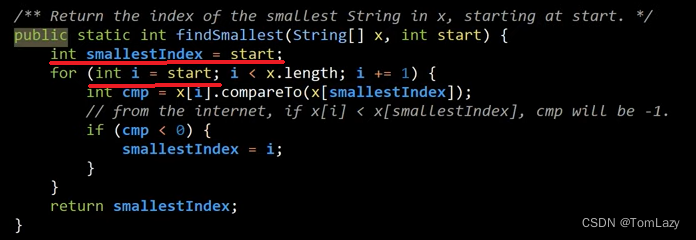
2、smallestIndex索引错误,返回了已经排序好的最小元素(首元素),我们需要它从一个特定起点开始寻找,修改代码后:
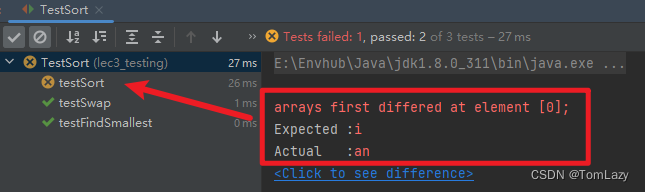
[Testing, Video 10] Reflections on the Process (对开发过程的思考)
| 通常,开发是一个渐进的过程,涉及大量的任务切换和即时的设计修改。
|
[Testing, Video 11] Better JUnit (简化JUnit测试)
| JUnit可以做得更多:
|
1、使用 JUnit 注解,使其可以被独立运行 |
| JUnit 输出的信息有点难看,而且手动调用每个测试是很烦人的,我们可以通过 New Syntax #2 来解决 |
| New Syntax #2 (just trust me):
|
2、导入JUnit测试包,用来消除包名前缀 |
| 反复输入库的名称让人心烦,例如org.junit.Test 和 org.junit.Assert.assertEquals。 |
| New Syntax #3: 为了避免这种情况,我们在每个测试文件的开头都要写上: import org.junit.Test; import static org.junit.Assert.*; 这将神奇地消除掉输入 "org.junit "或 "org.junit.Assert "的需要(在期中考试后会有更多关于这些导入的真正含义的内容)。 |
[Testing, Video 12] Testing Philosophy (测试的哲学)
Correctness Tool #1: Autograder (自动评分器)

Autograder Driven Development (ADD) 自动评分器驱动开发
自动评分器在现实世界中并不存在,依赖自动评分器会养成坏习惯。如果出现了这种情况,请及时调整和避免。
Correctness Tool #2: Unit Tests (单元测试)
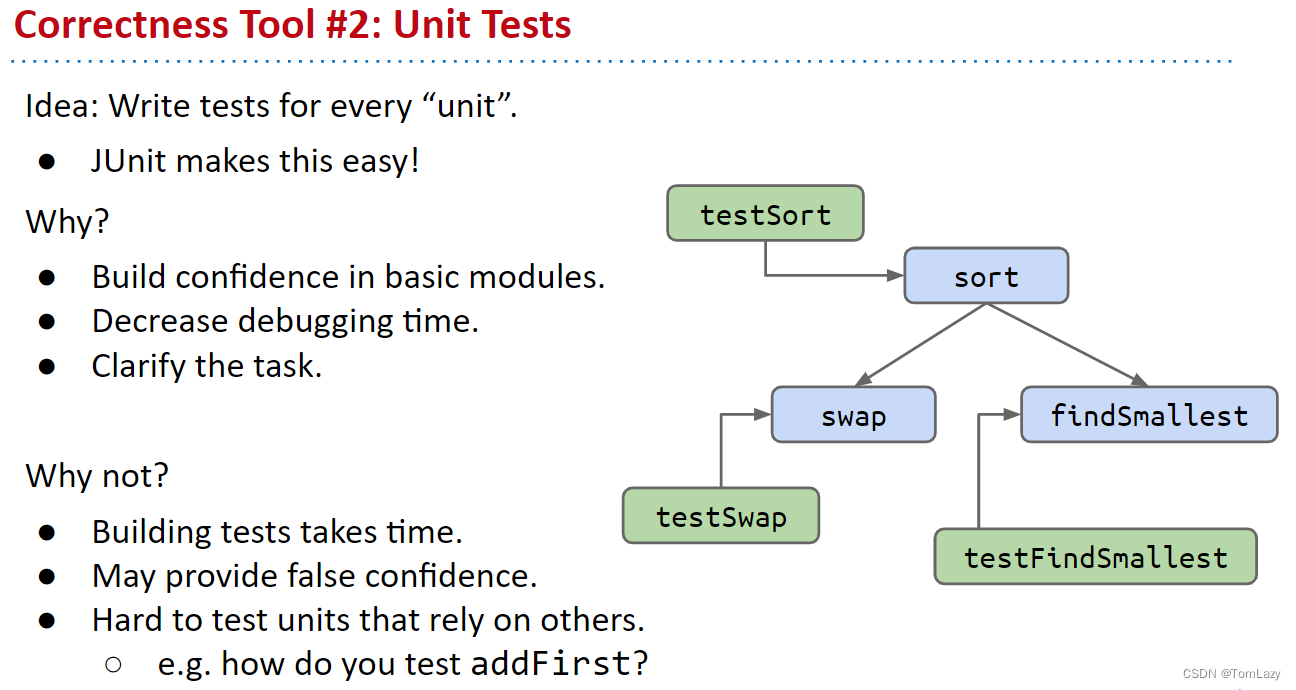
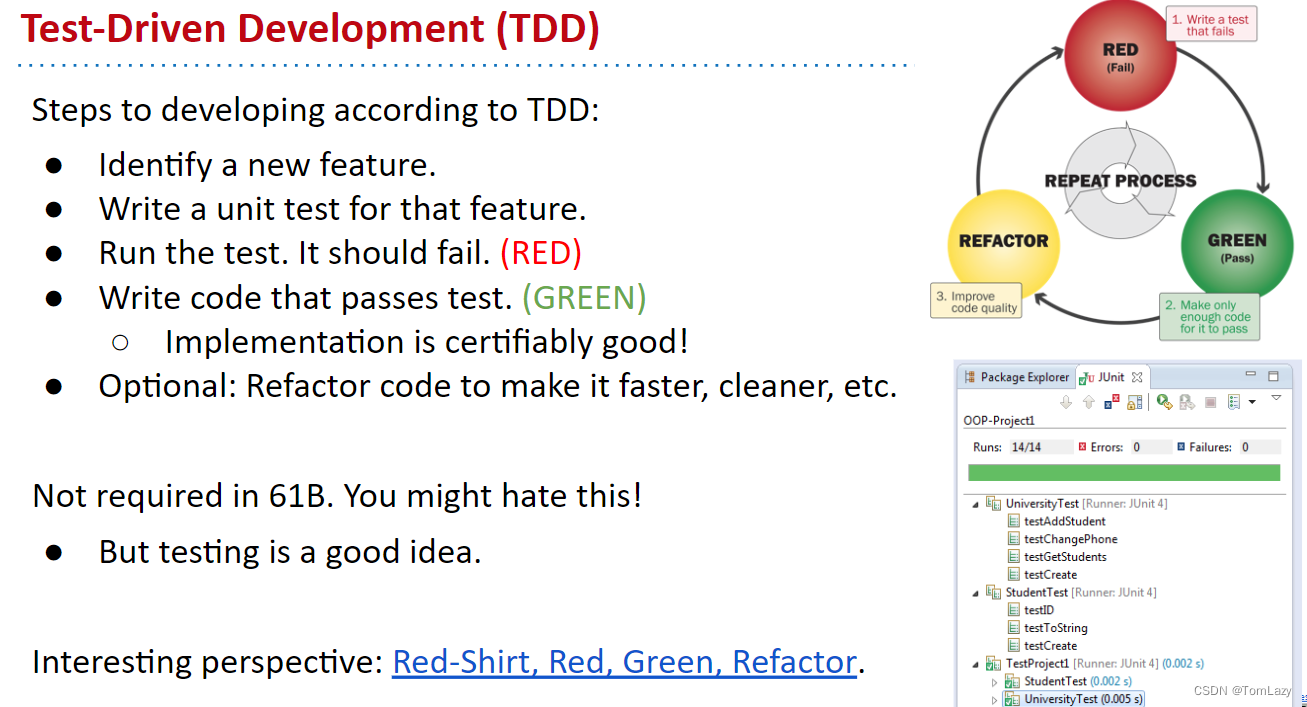
Test-Driven Development (TDD) 测试驱动开发
DD是对原始的工作流程的一种极端背离,对你来说,最好的办法可能是在中间。总的来说,还是推荐养成测试的好习惯的。
Correctness Tool #3: Integration Testing (集成测试)

在实验3、项目1B 和 项目2 将给你带来测试练习!
Testing Study Guide (小结 ⭐)
1、为什么要测试代码?在现实世界中,你很可能没有一个自动测试器。当你的代码被部署到生产中时,重要的是你要知道它对简单的情况和奇怪的边缘情况都能工作。
2、测试驱动开发。当提供给学生一个自动测试器时,很容易出现 "autograder happy"的情况。一个学生不是真正理解项目的规格和要求,而是写一些基本的实现,把他们的代码砸在自动测试器上,修正一些部分,然后重复直到测试通过。这个过程往往有点冗长,真的不是对时间的最佳利用。我们将介绍一种新的编程方法,即测试驱动开发(TDD),程序员在编写实际的函数之前就为该函数写好测试。由于单元测试是在函数之前编写的,因此,隔离代码中的错误就变得更加容易。此外,编写单元测试需要你对你正在进行的任务有一个相对坚实的理解。这种方法的一个缺点是,它可能相当慢,而且很容易忘记测试函数之间的交互方式。(所以,最好的方式是站在中间,只对必要的方法进行测试,而不是在一开始就编写大量的测试)
3、JUnit测试。JUnit是一个用于调试Java程序的包。一个来自JUnit的例子函数是assertEquals(expected, actual)。这个函数断言预期和实际具有相同的值。还有一堆其他的JUnit函数,如assertEquals、assertFalse和assertNotNull。
在编写JUnit测试时,在测试的函数上方写上"@Test "是个好的做法。这允许你的所有测试方法以非静态方式运行。
Discussion(习题课)
Discussion主要是一些练习题,相当于习题课,会有配套的助教在线讲题,并附有答案,答案解释的很详细。
1、Introduction To Java
不得不说助教 Allyson 是真滴可爱!
这期 Discussion 比较基础,这里仅记录最后一题,斐波那契数列的代码实现。
A、斐波那契数列(fib)
| // 自底向上,效率更高,没有重复 (⭐) public static int fib(int n, int k, int f0, int f1) { if (n == k) { return f0; } else { // fib(n) -> fib(n-1) + fib(n-2) return fib(n, k+1, f1, f0 + f1); } }
// 自顶向下 public static int fib2(int n) { if (n <= 1) { return n; } else { return fib2(n-1) + fib2(n-2); } } |
2、Scope, Pass by Value, Static (Exam Prep)
需要记住的主要有以下两点:
A、基本类型与引用类型
在Java中,值类型的只有short,char,byte,int,long,double,float,boolean八大基本类型,其他的所有类型都是引用类型。一个数组既可以存放基本类型值(如int,char,...),也可以存放对象的引用(比如指针)。Java数组可以被这样理解:数组是一种引用数据类型,数组变量并不是数组本身,而是指向堆内存中存放的数组对象。当使用"new"关键字创建一个对象时,JVM会在堆中会分配一段内存空间,并返回一个引用。
数组内存图:(由于数组是引用数据类型,即变量 x 在栈中存储的是堆中数组的引用)
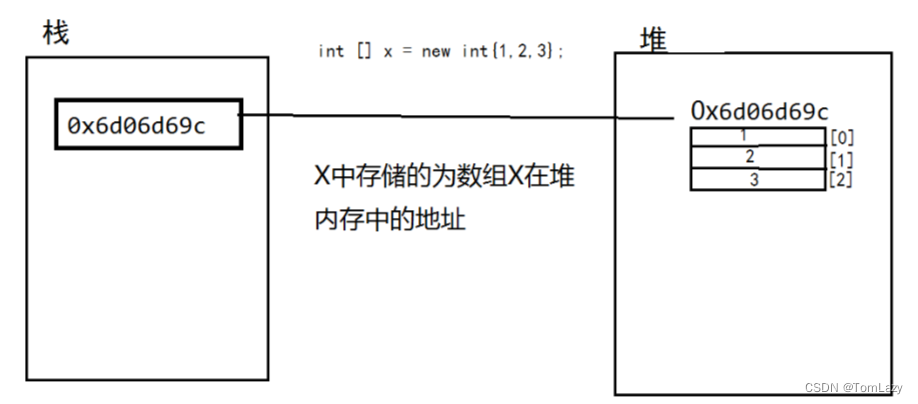
参考资料:
[1] java数组与存储方式_Arckal的CSDN博客
B、static 与 non-static
静态变量会随着类加载被分配在方法区的静态区域,一个static变量只会有一个内存空间,虽然可能会有多个类实例,但这些类实例中的这个static变量会共享同一个内存空间;而当类中的某一个实例改变了静态变量的值,其他同类的实例变量读到的就是修改后的值;此外静态变量可以直接通过类名调用,且不推荐使用类的实例调用;最后,静态成员不能访问非静态成员。
参考资料:
[1] Java中类变量(静态变量)和实例变量区别_墨痕诉清风的CSDN博客
[2] 类实例调用静态方法(Java) - Jeffcky - 博客园
61B 2021 Lecture 4 - References, Recursion, and Lists
[Lists1, Video 1] The Mystery of the Walrus (海象的奥秘)
[Lists1, Video 2] Primitive Types (基本类型)
信息以1和0的序列形式存储在存储器中,每种Java类型都有不同的方式来解释这些比特:
- Java中的8种原始类型:byte, short, int, long, float, double, boolean, char
1、Declaring a Variable (Simplified) (声明变量)
| 你的计算机预留了恰好足够的比特来容纳这种类型的东西:例如:
Java创建了一个内部表格,并将每个变量名称映射到一个位置。Java不会在保留的 "box"里写任何东西。此外,为了安全起见,Java不会允许访问一个未初始化的变量。 |

2、Simplified Box Notation (简单的盒子表示法)
用人类可读的符号来写内存盒中的内容,而不是用二进制来写。

3、“=”的黄金法则(GRoE)
当你编写 y = x 时,你这是在告诉 Java 解释器将比特从 x 复制到 y。这个简单的复制比特的想法对Java中使用=的任何赋值都是正确的。

[Lists1, Video 3] Reference Types (引用类型)
所有不属于基本数据类型(byte, short, int, long, float, double, boolean, char)的类型,包括数组,都是引用类型。
1、Object Instantiation(对象实例化)
当我们使用new来实例化一个对象时(例如 Dog, Walrus, Planet),Java首先为该类的每个实例变量分配一个盒子,并将其填入一个默认值。然后,构造函数通常(但不总是)用其他的值来填充每个盒子。
例如,假设我们的 Walrus 类如下所示:
| public static class Walrus { public int weight; public double tuskSize;
public Walrus(int w, double ts) { weight = w; tuskSize = ts; } } |
而我们使用new Walrus(1000, 8.3); 创建一个 Walrus,那么我们最终会得到一个分别由32和64位的两个盒子组成的 Walrus(此时,我们创建的 Walrus 是匿名的,因为它已经被创建,但它没有存储在任何变量中。):
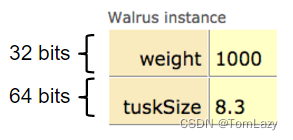
在Java编程语言的实际实现中,任何对象实际上都有一些额外的开销,所以一个Walrus需要比96比特多一些。然而,为了我们的目的,我们将忽略这种开销,因为我们永远不会与它直接互动。
2、Reference Type Variable Declarations (引用变量声明)
当我们声明一个任何引用类型的变量时(Walrus、Dog、Planet、array 等),Java会分配一个64位的盒子,无论什么类型的对象。
这个 64 位的盒子中包含的不是关于 Walrus 的数据,而是 Walrus 在内存中的地址。
例如,假设我们调用:
| Walrus someWalrus; someWalrus = new Walrus(1000, 8.3); |
第一行将创建一个64位的盒子。第二行将创建一个新的Walrus,地址由new操作符返回。然后根据 GRoE 将这些比特复制到someWalrus的盒子中。

我们也可以将特殊值null分配给一个引用变量,对应于全0:

3、Box and Pointer Notation (盒子和指针表示法)
| 就像以前一样,很难解释引用变量内部的一堆比特,所以我们将为引用变量创建一个简化的盒式符号,如下所示:
这有时也被称为 "盒子和指针 "表示法。
|
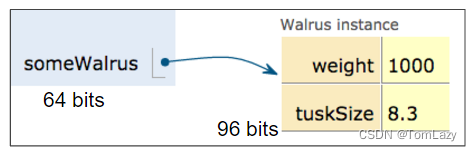
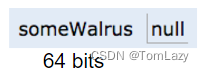
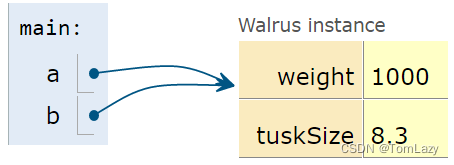
4、Resolving the Mystery of the Walrus (解开海象之谜)
以下面的例子为例:
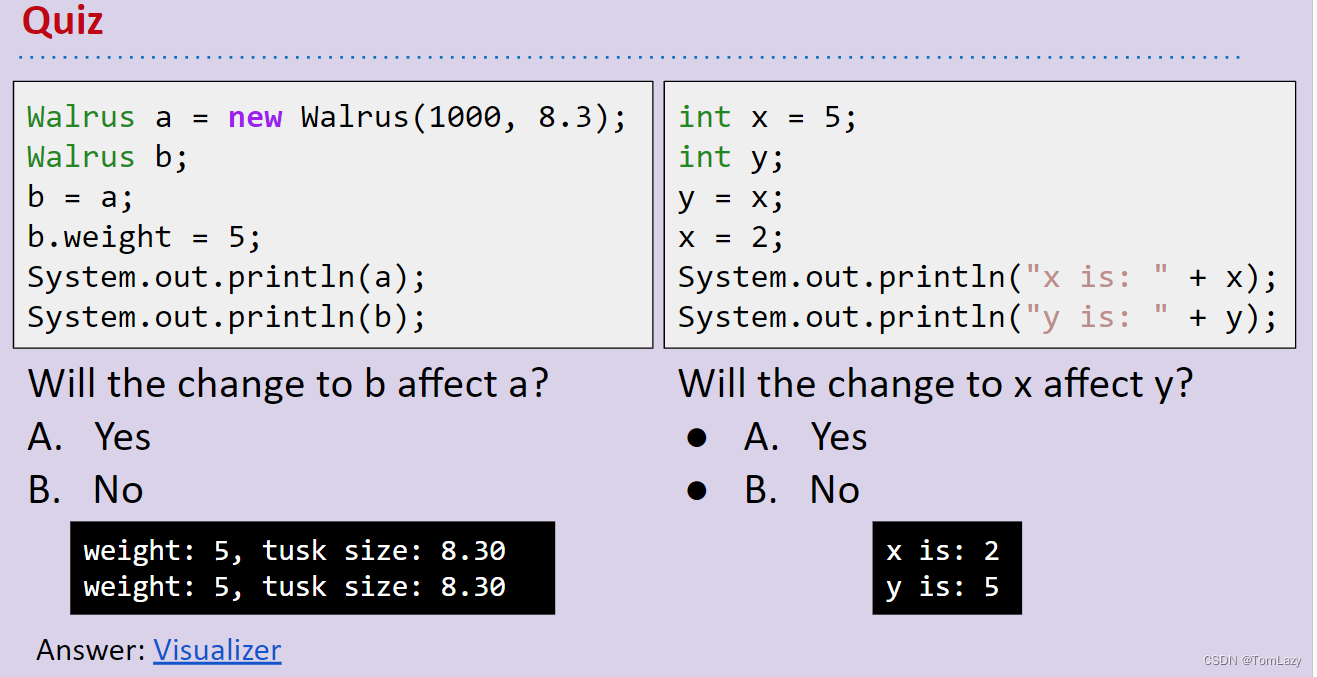
| Walrus a = new Walrus(1000, 8.3); Walrus b; b = a; |
第一行执行后,我们有:
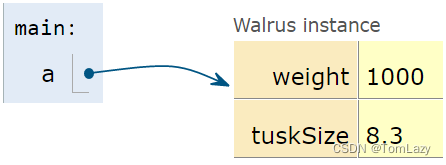
第二行执行后,我们有:

请注意,上面的b是未定义的,而不是 nul
根据GRoE,最后一行只是将a框中的比特复制到b框中。或者根据我们的视觉隐喻而言,这意味着b将完全复制a中的箭头,现在显示的是一个指向同一物体的箭头
[Lists1, Video 4] Parameter Passing(参数传递)
当你向一个函数传递参数时,你也是在简单地复制比特。换句话说,GRoE也适用于参数传递。复制比特通常被称为 "按值传递"。在Java中,我们总是按值传递。
例如,当我们在 main 函数中调用 average 方法时,average 将产生自己的作用域,有两个新的盒子,分别标为a和b,比特被简单地复制进来。这种比特的复制就是我们所说的 "按值传递"。
而如果 average 方法中要修改 a 的值,那么 main 中的 x 不会发生任何变化,因为 GRoE 告诉我们,我们只是在标有a的盒子里填入新的比特。

[Lists1, Video 5] Test Your Understanding of the GRoE(测试你的理解力)
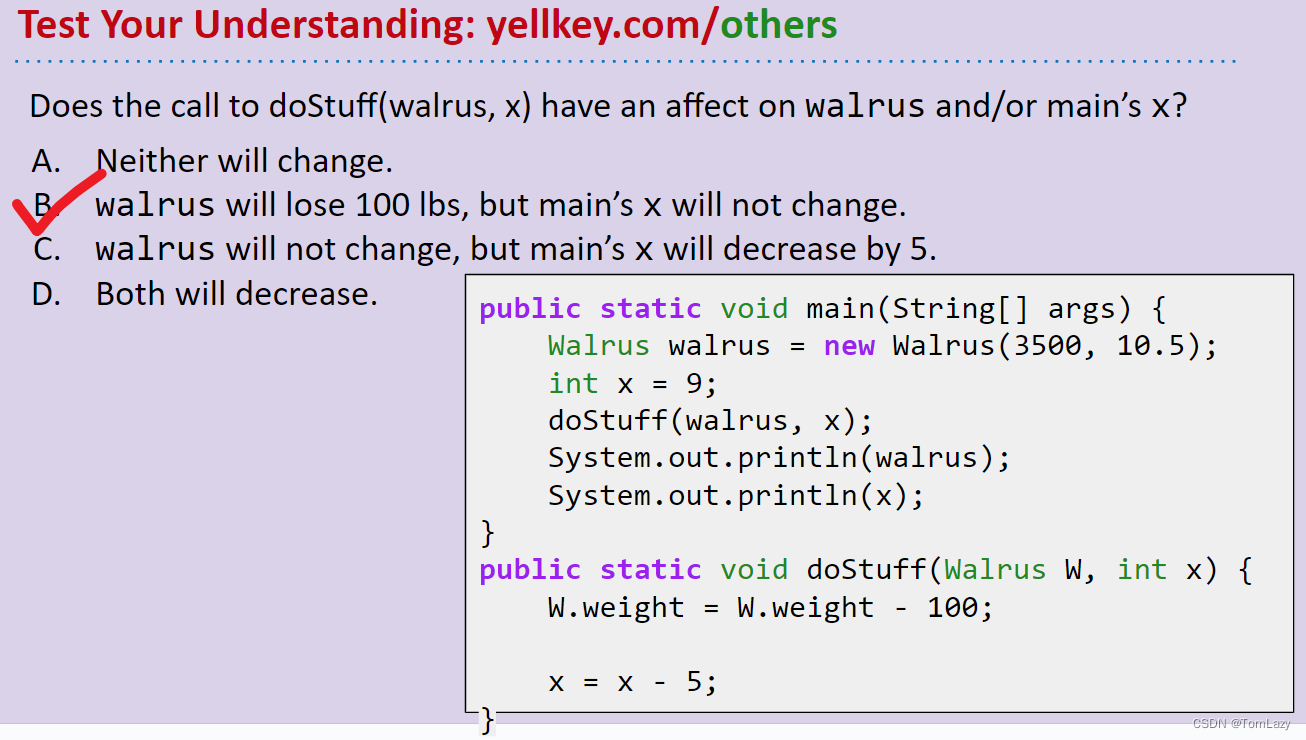
即:weight: 3400,x: 9
[Lists1, Video 6] Instantiating Arrays(数组的实例化)
如上所述,存储数组的变量和其他变量一样是引用变量。例如,考虑以下声明:
| int[] x; Planet[] planets; |
这两个声明都创建了64位的内存盒。x只能容纳一个int数组的地址,而planets只能容纳一个Planet数组的地址。
实例化一个数组与实例化一个对象非常相似。例如,如果我们创建一个大小为5的整数数组,如下所示:
| x = new int[]{0, 1, 2, 95, 4}; |
那么new关键字创建了5个盒子,每个盒子有32位,并返回整体对象的地址,用于赋值给x。
1、The Law of the Broken Futon(Broken Futon法则)
| 破卧榻法则: 我们把正确的答案看得比深刻的推理更重要,从而创造了它。我们通过说:"只有聪明的人才会得到它;其他人只需要能够做到这一点 "来创造它。我们通过在语言或行动上说:"不明白也没关系。只要按照这些步骤,在后面检查你的答案。" 我们可能成功地将被褥搬上楼梯。但在这一过程中,我们失去了一些东西。在没有关键理解的情况下前进,就像在没有替换弹药的情况下进军战场。你可能会发射几发子弹,但当你意识到缺少什么时,再想恢复就太晚了。 一个能回答问题但不理解问题的学生是一个有局限的学生。 |
[Lists1, Video 7] Introducing IntLists(整数列表)
一个基本的列表类,如下所示:
| public class IntList { public int first; public IntList rest;
public IntList(int f, IntList r) { first = f; rest = r; } } |
虽然原则上你可以用IntList来存储任何整数的列表,但由此产生的代码会相当难看,而且容易出错。我们将采用常规的面向对象的编程策略,在我们的类中添加辅助方法来执行基本任务。
[Lists1, Video 8] IntList size(递归法求列表大小)
我们想在IntList类中添加一个size方法,这样如果你调用L.size(),你就会得到L中的项目数。
size方法,如下所示:
| /** Return the size of the list using... recursion! */ public int size() { if (rest == null) { return 1; } return 1 + this.rest.size(); } |
关于递归代码,需要记住的关键一点是你需要一个基本情况(Base Case)。在这种情况下,最合理的基本情况是 rest 是null,这将得到一个大小为1的列表。
Exercise:你可能会想,为什么我们不做类似if (this == null) return 0;的事情。为什么不这样做呢?
Answer: 想想当你调用size时会发生什么。你是在一个对象上调用它,例如 L.size()。如果L是空的,那么你会得到一个 NullPointer 的错误
[Lists1, Video 9] IntList iterativeSize(迭代法求列表大小)
iterativeSize方法,如下所示:(我的 iterativeSize 方法如下所示。我建议当你写迭代数据结构代码时,使用 p 这个变量名来提醒自己,这个变量是持有一个指针的。你需要这个指针,因为在Java中你不能对 "this" 重新赋值{this是一个java关键字,它总是指的是当前对象}。这篇Stack Overflow帖子的后续内容对其原因作了简要的解释。)
| /** Return the size of the list using no recursion! */ public int iterativeSize() { IntList p = this; int totalSize = 0; while (p != null) { totalSize += 1; p = p.rest; } return totalSize; } |
[Lists1, Video 10] More IntList Exercises(更多练习)
虽然size方法可以让我们得到一个列表的大小,但我们没有简单的方法来得到列表的第i个元素。
| Exercise: 写一个 get(int i) 方法,返回列表中的第 i 项。 例如,如果 L 是 5 -> 10 -> 15,那么 L.get(0) 应该返回 5,L.get(1) 应该返回 10,而 L.get(2) 应该返回 15。而对于无效的i(越界),你的代码如何表现则无关紧要。 请注意,我们所写的方法需要线性时间! |
解题代码:
| /** Returns the ith item of this IntList. */ public int get(int i){ if (i == 0) { return first; } // Improvement: prevent NullPointerException if (rest == null) return -1;
return rest.get(i-1); }
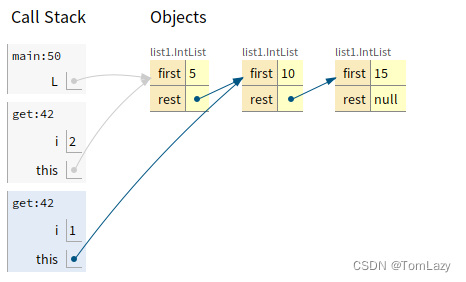
public static void main(String[] args) { // 倒序建立列表 IntList L = new IntList(15, null); L = new IntList(10, L); L = new IntList(5, L); System.out.println(L.get(2)); } |
内存图:
Lab 2: JUnit Tests and Debugging(单元测试与Debug)
在这个实验中,你将学习如何使用 IntelliJ debugger 以及如何在 IntelliJ 中使用 JUnit 测试。
1、Pre-lab(实验准备)
|
2、Debugger Basics(Debugger基础)
打开lab2项目:
A、Breakpoints and Step Into (断点和步进)
| Step into、Step over、Step out的区别 |
|
| 💡 Note:当前突出显示的行是即将执行的行,而不是刚刚执行的行。 |
![]() 练习题1:DebugExercise1
练习题1:DebugExercise1
![]() 练习题2:DebugExercise2
练习题2:DebugExercise2
B、Recap: Debugging(回顾:调试)
| 到此为止,你应该了解以下工具: |
|
| 更多内容请查看:Debugging Guide |
3、JUnit and Unit Testing(单元测试)
A、JUnit 语法
| JUnit 测试步骤: |
|
| 💡 Note:所有测试都必须是非静态的。 |
![]() 练习题1:ArithmeticTest
练习题1:ArithmeticTest
4、Application: IntLists(整数递归链表)
IntList是我们CS61B的实现,是一个赤裸裸的整数递归链表。每个IntList都有一个first和rest变量。第一个是节点所包含的int元素,其余的是列表中的下一个链(另一个IntList!)
入门代码
新增方法:of(int ...argList),它可以用来快速创建和初始化一个 IntList 元素。
A、IntList Iteration(IntList 迭代)
在这一小节,我们需要取调试 IntListExercises.java 中的 addConstant 方法,该方法旨在接收一个IntList常量并向列表的每个元素添加一个常量。
| /* Expected Behavior */
IntList lst = IntList.of(1, 2, 3);
addConstant(lst, 1); System.out.println(lst.toString()); // Output: 2 -> 3 -> 4
addConstant(lst, 4); System.out.println(lst.toString()); // Output: 6 -> 7 -> 8 |
🐲 Fix1:将 head.rest!= null 修改为 head != null,即可解决错误问题(最后一个数字没有被添加常量值)
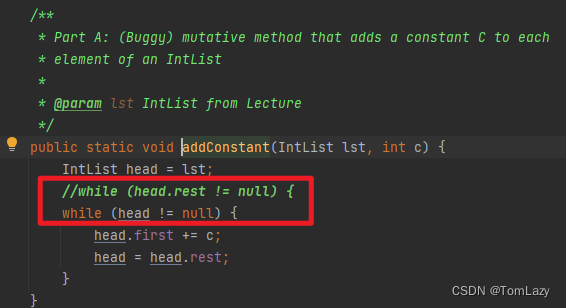
B、Nested Helper Methods and Refactoring for Debugging(用于调试的嵌套辅助方法和重构)
在这一部分,我们将对 IntListExercises.java 中的 setToZeroIfMaxFEL 方法进行调试,当且仅当 IntList 中从某一节点开始的最大值首尾数字是否相同(FEL : “first equals last”,eg: 11、22、121、55、66之类的数字)时,该方法会将IntList中某一节点的值替换为 0。
例如:55 -> 22 -> 45 -> 44 -> 5 最终会被转化为 0 -> 22 -> 45 -> 0 -> 0;(可以将其理解为,依次遍历 IntList,查看当前List中的最大值是否首尾数字相同,如果是,则将当前位置的数字赋值为0)
💡 Note: 在实际开发中,如果你遇到了函数中具有多函数嵌套的情况,你最好先单独测试中每一个函数。
🐲 Fix1:在 firstDigitEqualsLastDigit 方法中添加对 10的幂次的条件判断,防止之类的数字被误判成首尾相等的数,从而导致错误赋值。
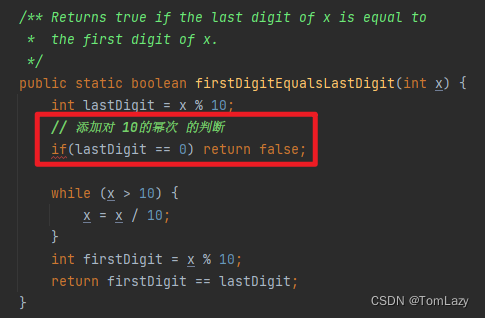
C、Tricky IntLists (棘手的 IntLists)!
在这一部分,我们将调试 IntListExercises.java 中的 squarePrimes 方法。这个方法的目的是接收一个IntList,将其所有的质数元素平方化,而不考虑复合(非质数)元素。如果至少有一个元素被平方了,它将返回true,否则返回false。
作为一个例子,考虑一个包含14、15、16、17和18元素的IntList。在运行 squarePrimes 之后,我们期望质数元素(17)被平方,而复合元素(14、15、16、18)保持不变。squarePrimes函数的输出应该为真,因为它应该将IntList修改为14、15、16、289、18。
🐲 Fix1:我们需要修改 squarePrimes 方法的返回结果,这是因为原来的返回结果是先判断 currElemIsPrime,当其值为 true 时,后续的条件将不会被除法,因此就导致了 squarePrimes 方法只将一个质数平方之后,就返回结果,结束了递归。
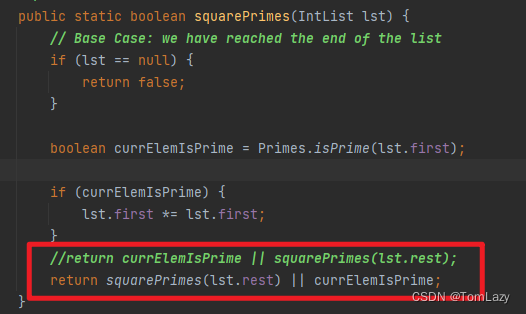
🎈 PS:100以内的质数
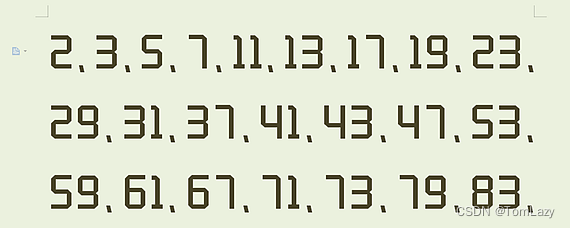
5、Submission & Recap(提交与回顾)
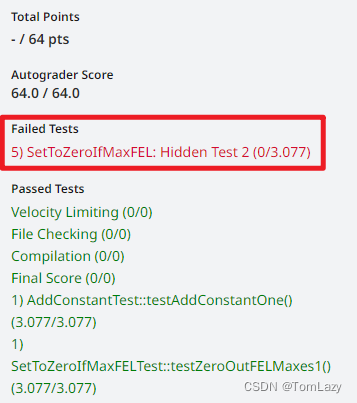
A、Result(结果)
好奇这个 SetToZeroIfMaxFEL 的 隐藏测试2 是个啥?
B、Recap(回顾)
61B 2021 Lecture 5 - SLLists, Nested Classes, Sentinel Nodes(SLLists,嵌套类,哨兵节点)
[Lists2, Video 1A-7] SLList
由于IntList是基于递归实现的数据结构,新手操作和使用起来颇有不便。因此,受IntList的经验启发,我们现在将建立一个新的 SLList 类,它更接近于程序员在现代语言中使用的列表实现。我们将通过反复添加(迭代)一连串的改进来做到这一点。
1、Improvement #1: Rebranding(重塑IntNode)
第一步将是简单地重命名所有的东西,并扔掉那些辅助方法。

2、Improvement #2: Bureaucracy(等级制度)
创建一个单独的名为SLList的类,与用户进行交互。

我们已经可以隐约感觉到为什么SLList会更好。比较一下创建一个IntList的项目和创建一个SLList的项目。
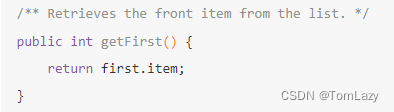
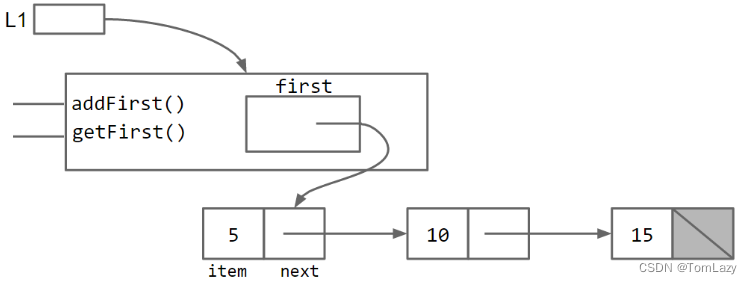
SLList向用户隐藏了存在一个空链接的细节。SLList类还不是很有用,所以让我们添加一个addFirst和getFirst方法作为简单的热身方法。在继续阅读之前,可以考虑自己试着写一下它们。
addFirst 和 getFirst

由此产生的SLList类更容易使用。比较一下:(将不必要的引用进行了隐藏)

本质上,SLList类 在列表用户和裸递归数据结构 IntList 之间充当了一个中间人。
3、Improvement #3: Public vs. Private(公共与私人)
但不幸的是,我们的 SLList 可以被绕过,我们的裸数据结构的原始数据可以被访问。程序员可以轻松地直接修改列表,而无需通过我们提供的正常途径: addFirst 方法。

为了解决这个问题,我们可以修改 SLList 类,使用 private关键字 声明 first 变量。
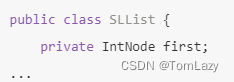
私有变量和方法只能被同一.java文件内(即 同一类内)的代码访问,这也意味着像 SLLTroubleMaker 这样的类将无法完成编译,并且会报出 first has private access in SLList 错误:

相比之下,SLList.java 文件中的任何代码都将能够访问first变量。
在大型软件工程项目中,private关键字是一个宝贵的信号,表明某些代码片段应该被终端用户忽略(因此不需要被理解)。同样地,public关键字应该被认为是一个声明,即一个方法是可用的,并将永远像现在这样工作。当你创建一个 public 成员(即方法或变量)时,要小心,因为你实际上是在承诺永远支持该成员的行为,就像现在这样。
4、Improvement #4: Nested Classes(嵌套类)
Java 为我们提供了在另一个类声明中 嵌入类声明 的能力:

拥有一个嵌套类对代码性能没有任何有意义的影响,它只是一个保持代码有序的工具。关于嵌套类的更多信息,请参见Oracle的官方文档。
如果嵌套类不需要使用SLList的任何实例方法或变量,你可以将嵌套类声明为static,如下所示:
将一个嵌套类声明为 static 意味着静态类中的方法不能访问包围类中的任何成员。在这个例子中,它意味着 IntNode 中的任何方法都不能访问 first、addFirst 或 getFirst。这就节省了一点内存,因为每个 IntNode 不再需要跟踪如何访问其包围的 SLList。

| 💡 一个简单的经验法则是,如果你不使用外层类的任何实例成员,就把嵌套类变成 static 的。 |
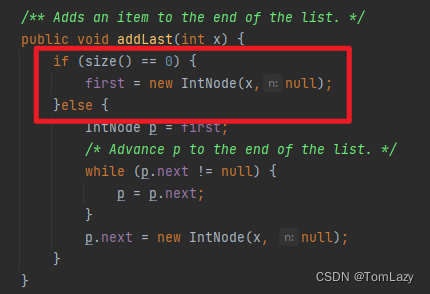
addLast() 和 size()
我将迭代地实现addLast方法,尽管你也可以递归地实现它。这个想法是相当直接的,我们创建一个指针变量p,并让它在列表中迭代到最后:

递归实现size()方法:

在这里,我们有两个方法,都叫 size。这在Java中是允许的,因为它们有不同的参数。我们说,两个方法名相同但参数列表不同的方法是重载的。关于重载方法的更多信息,请参阅Java的官方文档。
5、Improvement #5: Caching(缓存)
| 💡 Tips:为 SLList类 增加一个成员变量 size,并在每次新增节点时也随之增加,相当于 SLList 类中时刻保存着当前列表的长度,大大提高了获取列表长度的效率。 |
考虑一下我们上面写的 size 方法耗时较长,它必须遍历完所有节点才能得出答案。这对于大列表来说,拥有一个非常慢的 size 方法是不可接受的,因为我们可以做得更好,这就需要我们来重写 size 方法,使其无论在多大的列表中都花费同样的时间。
要做到这一点,我们可以简单地在SLList类中添加一个size变量,跟踪当前的大小,产生下面的代码。这种保存重要数据以加快检索速度的做法有时被称为缓存。

这样的修改使得我们的size方法快得惊人,无论列表有多大。当然,这也会使我们的addFirst和addLast方法变慢,也会增加我们的类的内存使用量,但这只是一个微不足道的量。
6、Improvement #6: The Empty List(空列表)
相比于 IntList,此时的 SLList 已经允许我们创建一个空列表了(通过构造方法指定 first 为 null):

但不幸的是,如果创建完空列表后,还想通过 addLast 方法新增数据,此时会导致空指针异常,因此还需要我们对 addLast 方法进行修改,增加列表为空的判断,防止出现空指针异常的情况。
7、Improvement #6b: Sentinel Nodes(哨兵节点)
修复addLast的一个解决方案是为空列表创建一个特殊情况,如下所示:(本质就是空列表的判断,和上图代码思想一致)

这个解决方案是可行的,但在必要时应避免像上面所示的特殊情况代码。人类只有这么多的工作记忆,因此我们要尽可能地控制复杂性。对于像SLList这样的简单数据结构,特殊情况的数量很少。而一旦是像树这样更复杂的数据结构,代码就会变得非常丑陋和臃肿。
一个更干净,但不太明显的解决方案是使所有的SLLists都是 "相同 "的,即使它们是空的。我们可以通过创建一个始终存在的特殊节点来做到这一点,我们将其称为哨兵节点(sentinel node)。哨兵节点将持有一个值,但我们不需关心这个值。
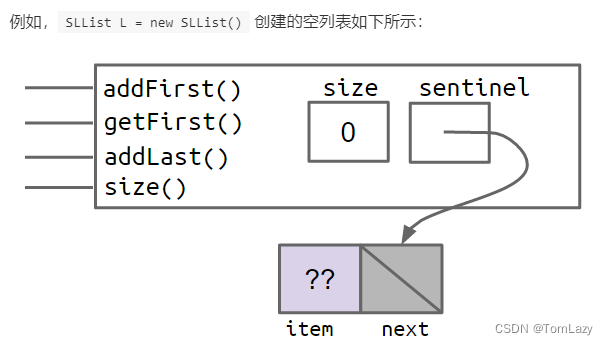
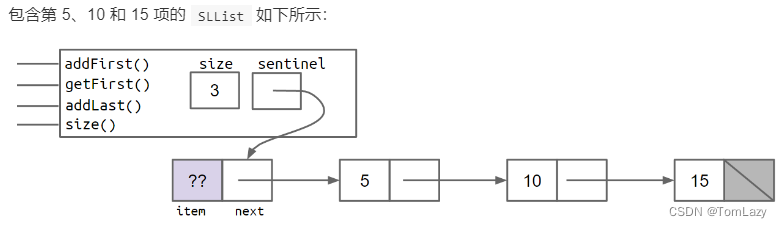
在上面的数字中,淡紫色的??值表示我们并不关心那里有什么值。由于Java不允许我们用问号来填入一个整数,所以我们只是选取一些任意的值,如-518273或63或其他的。
有了哨兵节点之后,我们就可以有效的避免空列表的出现,代码就可以精简为:

Invariants (不变量)
一个有哨兵节点的 SLList 至少有以下不变性:
|
要真正了解哨兵的便利程度,你需要真正深入研究并做一些自己的实现。你将在 Project 1: Data Structures 中获得大量练习。
Lists2 Study Guide(Lists2 学习指南)
1、Overview(概述)
| A、Naked Data Structures (IntLists) 为了正确使用IntList,程序员必须理解并利用递归,即使是与列表有关的简单任务。所以我们需要重新定义一种数据结构来提高使用的便利性。 |
| B、Adding Clothes(包装/改造IntLists) 首先,我们将 IntList 类转换为 IntNode 类。然后,我们将删除 IntNode 类中的任何方法。接下来,我们将创建一个名为 SLList 的新类,它first包含实例变量,并且该变量的类型应为 IntNode。从本质上讲,我们是用SLList“包装”了我们的IntNode。 |
| C、Using SLList(SLList的使用) 作为一个用户,为了创建一个列表,我调用SLList的构造函数,并传入我希望填充到列表中的数字。然后,SLList的构造函数将用这个数字调用IntList的构造函数,并首先设置为指向它刚刚创建的IntList。 |
| D、Improvement(改进) 注意,当创建一个只有一个值的列表时,我们写了SLList list = new SLList(1)。我们不必担心像我们的IntList那样传递一个空值。本质上,SLList类在列表用户和裸露的IntList之间充当了一个中间人。 |
| E、Public vs. Private 我们希望用户只通过SLList方法来修改我们的列表,而不是直接先修改。我们可以通过将我们的变量访问权限设置为私有来防止其他用户这样做。先写私有的IntNode;防止其他类中的代码访问和修改第一条(而类中的代码仍然可以这样做)。 |
| F、Nested Classes (嵌套类) 我们还可以将一个类移到另一个类内部,从而形成嵌套类! 你也可以将嵌套的类声明为 private 的;这样,其他类就永远不能使用这个嵌套的类。 |
| G、Static Nested Classes(静态嵌套类) 如果IntNode类从不使用SLList类的任何变量或方法,我们可以通过添加 "static "关键字将这个类变成静态的。 |
| H、Recursive Helper Methods(递归辅助方法) 如果我们想在SLList中写一个递归方法,一个常见的想法是编写一个用户可以调用的外层方法。这个方法调用一个以IntNode为参数的私有辅助方法。这个辅助方法将执行递归,并将答案返回给外层方法。 |
| I、Caching(缓存) 现在我们有了一个SLList,让我们简单地将我们列表的大小缓存为一个实例变量,可以大大提高返回列表长度的效率。 |
| J、Empty Lists(空列表) 使用SLList,我们现在可以表示一个空列表。我们只需first 设置为 null,size设置为 0。但是,我们同时也引入了一些错误,即因为first现在是null,任何尝试访问first属性的方法(如firstfirst.item)都将返回NullPointerException。 |
| K、Sentinel Nodes(哨兵节点) 为了让我们使所有的SLList对象,甚至是空列表,都是一样的,我们给每个SLList一个始终存在的哨兵节点。实际的元素在哨兵节点之后,我们所有的方法都应该尊重这个想法,即哨兵节点始终是我们列表中的第一个元素。 |
| L、Invariants(不变量) 不变量是关于数据结构的事实,它保证为真(假设您的代码中没有错误)。 |
2、Exercises(练习)
C Level 练习题
| Question1:重新解释哨点节点是什么以及为什么它很重要? |
| Answer: 哨兵值可以用来避免在每次操作中进行空值检查。这样可以提高程序的效率,同时也可以简化代码的实现。 |
| Question2: 如果你删除了哨兵,你的代码是否会出错? |
| Answer:会出错,缺少了空值判断。 |
| Question3:没有 size 变量而每次都只计算大小有什么缺点? |
| Answer:耗时较长,每次都只计算大小会导致每次调用时,都会从头遍历一遍列表,效率太低。 |
B Level 练习题
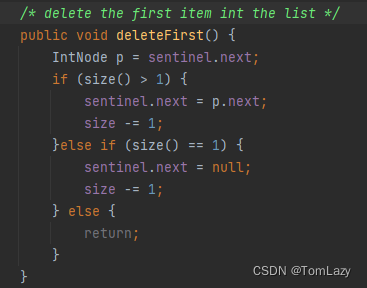
| Question1:从代码库中提供给你的SLList.java的副本开始,实现方法deleteFirst,该方法将删除SLList中的第一个元素。 |
| Answer: 代码如下所示:
|
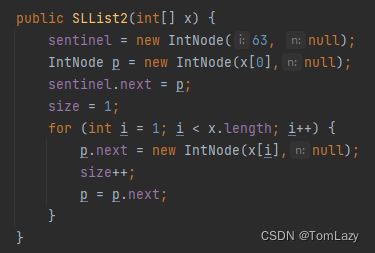
| Question2:从代码库中提供给你的SLList.java的副本开始,实现第二个构造函数,接收一个整数数组,用这些整数创建一个SLList。 |
| Answer: 代码如下所示:
|
| Question3:如果哨兵节点是一个空节点,它是否会改变什么,或者Intlist是否能够发挥作用? |
| Answer: 哨兵节点相当于一个哑单元,或者一个傀儡,作用是防止首节点为空时(first == null),出现无法指向下个节点情况。哨兵节点指向的下个单元为首节点。所以 哨兵节点应该无法为空,因为一旦哨兵节点为空,它就无法指向首节点,也无法防止首节点为空的情况了。 |
A Level 练习题
| Question1:做 Kartik textbook上期中考试的第5题(spring 23 Lists3 Metacognitive) |
| Question2:修改Intlist类,使每次添加一个值时,都要对IntList进行 "平方"。例如,在插入5时,下面的IntList将从: 1 => 2 to 1 => 1 => 2 => 4 => 5 而如果将7加入到后一个IntList中,它将变成: 1 => 1 => 1 => 1 => 2 => 4 => 4 => 16 => 5 => 25 => 7 |
| 参考:CS 61B | Part 1 | List (Linked List & Array List) | Forkercat
|

这篇关于【CS 61B】Data Structures, Spring 2021 -- Week 2(3. Testing 4. IntLists 5. SLLists )的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





