本文主要是介绍C#使用iText7将多个PDF文档合并为单个文档,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用HtmlAgilityPack抓取并分析网页内容,然后再调用PuppeteerSharp将网页生成PDF文件,最终的成果如下图所示,得到将近120个pdf文档。能看,但是不方便,需要逐个打开文档才能看到所需的内容,最好能将这些文档合并成单个文档,便于查看与保存。
百度"C# 合并pdf文档",最终决定使用IText7,其GitHub主页介绍特点时就提到支持合并PDF文件,如下图所示:

新建Winform项目,在Nuget包管理器中搜索并安装iText7,如下图所示。注意这里与iText相关的包有很多个,最初测试时错装了iTextSharp,关键类的名字和用法都差不多,直到编译和调试时才发现包装错了。
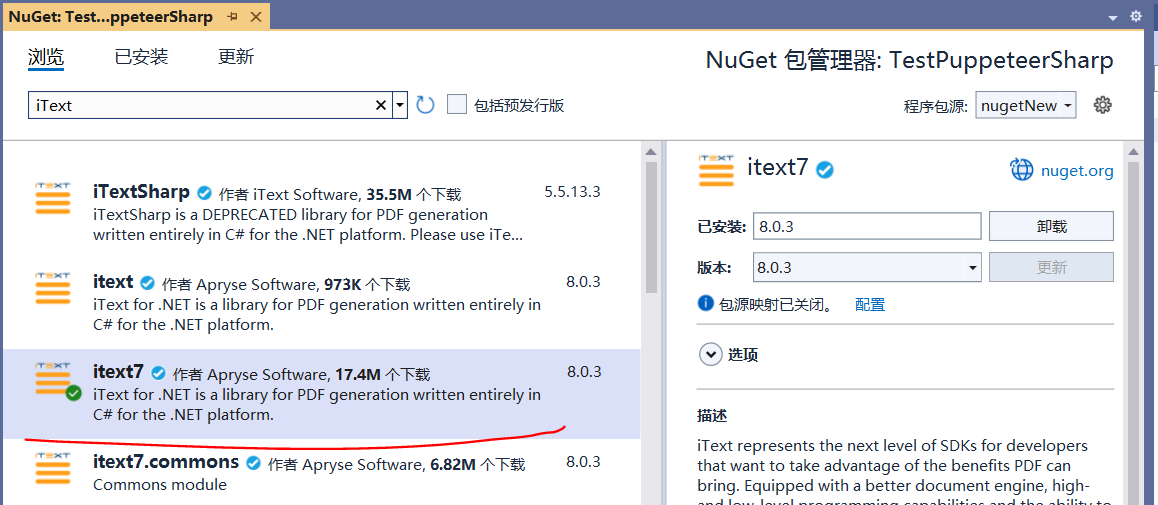
合并PDF文档最关键的类是PdfDocument和PdfMerger,前者用于打开PDF文档,后者则用于将多个文档合并到指定文档,关键代码如下所示,参照自iText7的GitHub主页示例(参考文献)。
private void button2_Click(object sender, EventArgs e)
{PdfDocument pdfDoc = new PdfDocument(new PdfWriter(txtOutputFileName.Text));PdfMerger merger = new PdfMerger(pdfDoc);merger.SetCloseSourceDocuments(true);List<PdfDocument> pdfFiles = GetSourceDocuments();foreach (PdfDocument doc in pdfFiles){merger.Merge(doc, 1, doc.GetNumberOfPages());}pdfDoc.Close();foreach(PdfDocument doc in pdfFiles){doc.Close();}
}private List<PdfDocument> GetSourceDocuments()
{List<PdfDocument> list = new List<PdfDocument>();foreach(ListViewItem item in listView1.Items){list.Add(new PdfDocument(new PdfReader(item.Tag.ToString())));}return list;
}
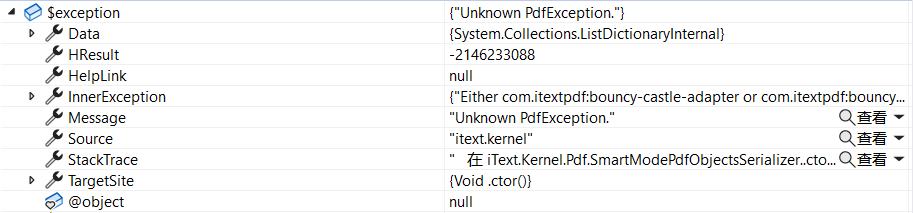
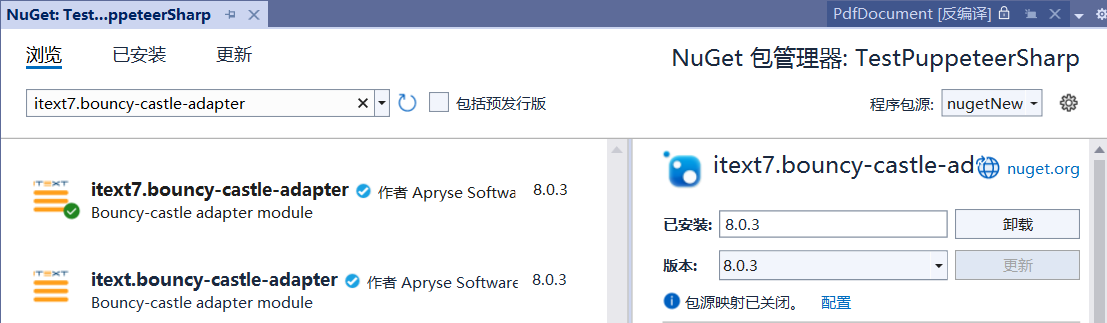
实际运行过程中还出现如下错误,百度错误信息找到参考文献5,原因是漏装了itext7.bouncy-castle-adapter包,安装后即可正常运行程序。
InnerException {"Either com.itextpdf:bouncy-castle-adapter or
com.itextpdf:bouncy-castle-fips-adapter
dependency must be added in order to use BouncyCastleFactoryCreator"}
System.Exception {System.NotSupportedException}
最后是程序运行效果及合并后的文档效果,如下图所示:
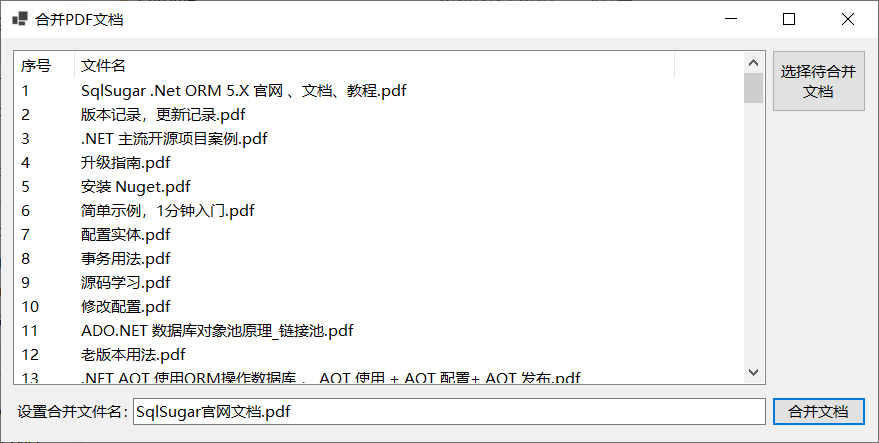
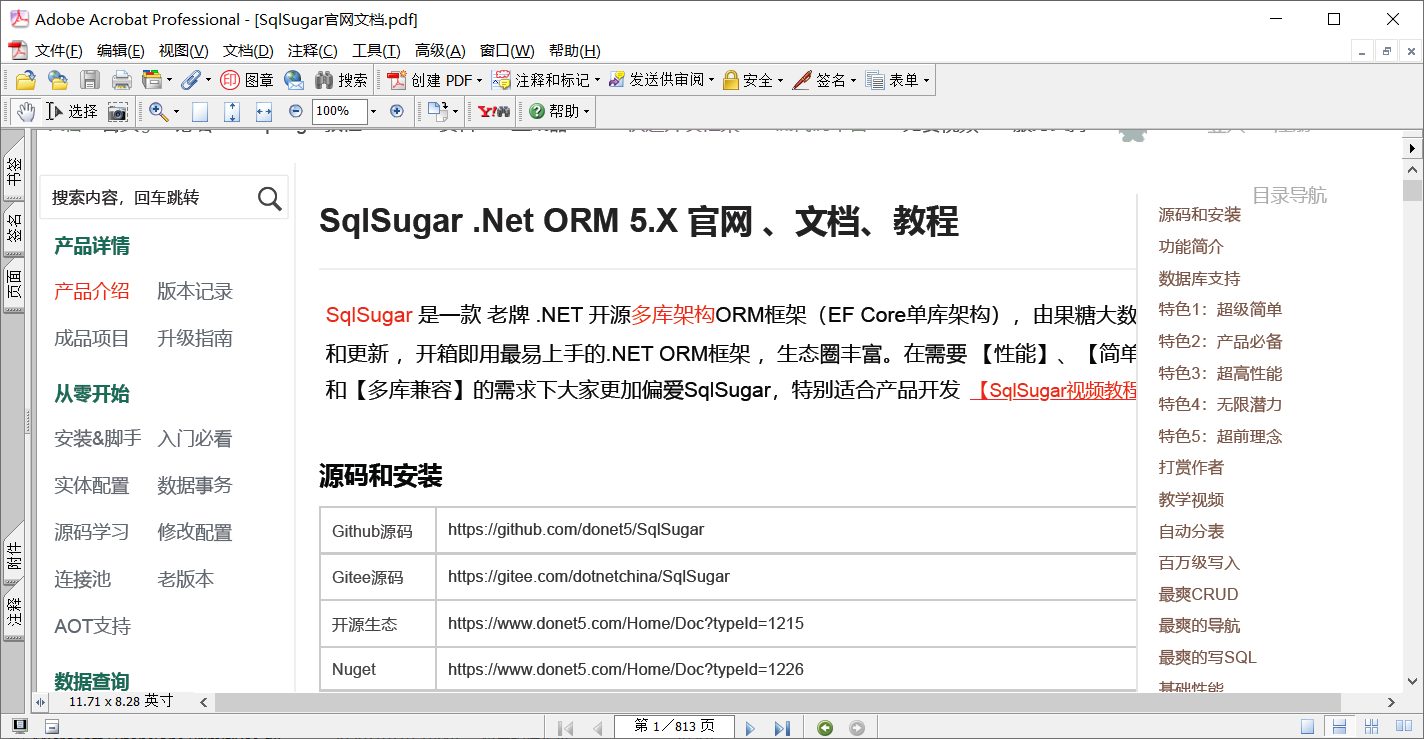
还存在很多不足之处,比如没有书签,从八百多页中查找内容并跳转到指定内容处不方便,后续还会学习iText7的用法,完善合并PDF文档功能。
参考文献:
[1]https://itextpdf.com/
[2]https://github.com/itext/itext-dotnet
[3]https://blog.csdn.net/qq_38628970/article/details/135478244
[4]https://github.com/itext/itext-publications-samples-dotnet/blob/master/itext/itext.samples/itext/samples/sandbox/merge/PdfDenseMergeExample.cs
[5]https://blog.csdn.net/rebecca_cao/article/details/135185043
这篇关于C#使用iText7将多个PDF文档合并为单个文档的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





