本文主要是介绍Flask-Migrate数据库迁移大坑!!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
flask-migrate第一次创建新表的时候有大坑,大坑,大坑!!!重要的事情说三遍!!!
前言
今天下午在研究flask项目使用flask-migrate迁移、更新数据库表结构的时候,无意删除了public下原有的表!!!直到晚上有同事来问我数据怎么没了的时候,我才意识到情况不对了。。。
原因
意识到问题以后,我立马复现了一下整个migrate的过程,发现在flask db upgrade以后,原先public下面的表全部消失了,离谱。。。
转念一想,upgrade是在执行flask db migrate生成的脚本,于是我打开生成的脚本文件,发现upgrade函数里面最后几行竟然有drop语句。。。
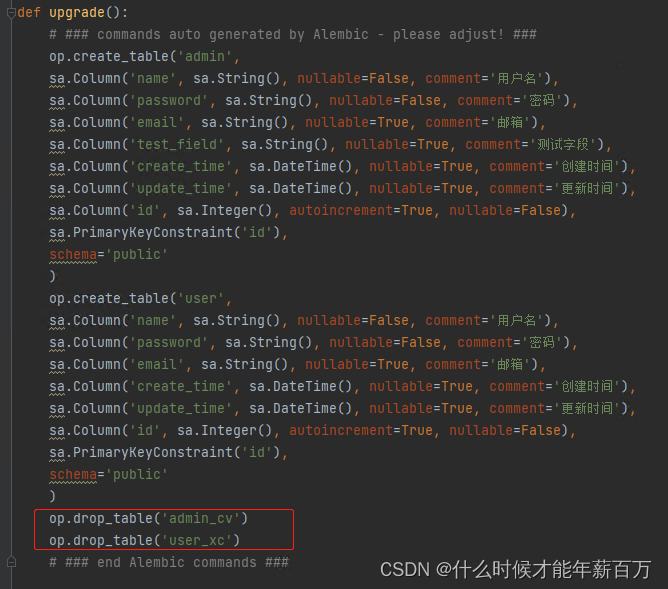
admin_cv和user_xc是public下原本就存在的表!但是它为啥会生成删除语句呢?
然后上网百度发现:在使用flask-migrate 进行数据迁移的过程中,会删除掉数据库中所有的表。因为在alembic的设定中:如果目标数据库存在不属于元数据的表,自动生成过程通常会假定这些表是数据库中的无用,并对每个表执行 Operations.drop _ table ()操作。
参考地址:https://www.cnblogs.com/q455674496/p/15830878.html
解决
第一种:修改env.py
在百度原因的时候,顺带提出了解决办法:使用 EnvironmentContext.configure.include _ name 钩子进行过滤。
文章中给出的办法是修改第一次flask db init后生成的env.py文件里面的代码
from flask import current_app
'''
target_metadata 获取当前项目中所有的表数据
在 MetaData 对象的表集合中搜索每个名称,并确保不包含不存在的名称
'''
target_metadata = current_app.extensions['migrate'].db.metadatadef include_name(name, type_, parent_names):if type_ == "table":return name in target_metadata.tableselse:return True#默认会执行 run_migrations_online()函数,在context.configure配置以下几项
context.configure(# ...target_metadata = target_metadata,include_name = include_name,include_schemas = False
)
第二种:Migrate初始化时指定include_object参数**
但是我心想,这样我在实际使用过程中还得手动去修改代码,太麻烦了,有没有什么办法可以在flask项目代码里面直接实现呢?
于是我又上网百度了一下,发现这篇文章link中提出了3种解决办法。其中第3种方法比较符合我的预期:
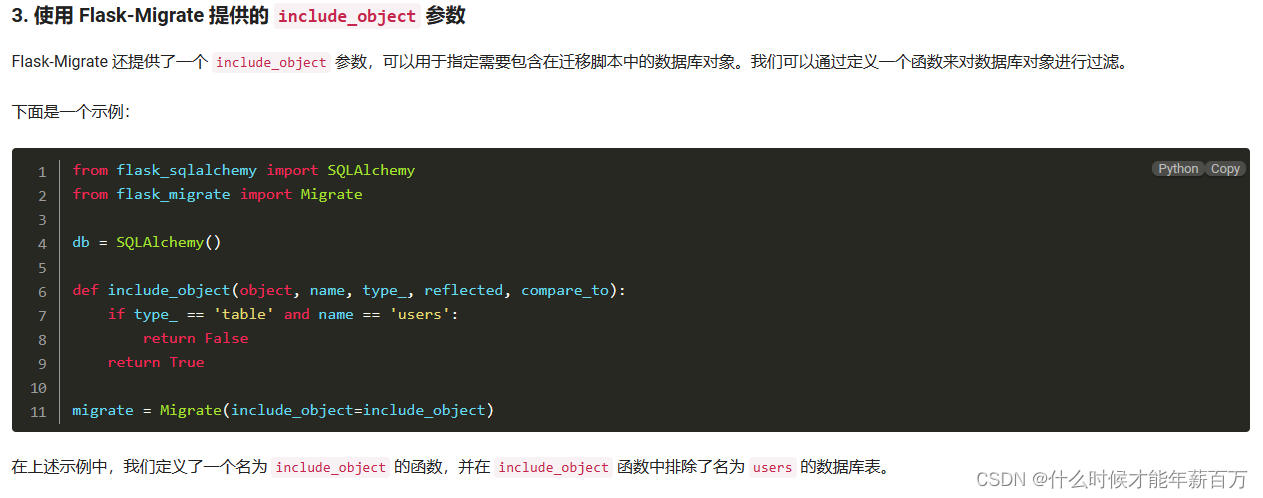
我尝试了一下,发现该方法有一个问题:如果库中已经存在表结构一致的表,那么就不会生成更新脚本,不会创建新表!
第三种:结合一和二
看了前两种方法以后,我突发奇想,是不是可以把二者结合起来呢!!!说干就干,我把env.py中要添加的代码复制粘贴到Migrate初始化上面:
# 创建app
app = create_app(Config)def include_name(name, type_, parent_names):if type_ == 'table':return Falsereturn True# 创建Migrate对象
migrate = Migrate(app=app, db=db, include_name=include_name)
然后依次执行flask db init、flask db migrate和flask db upgrade:migrate能够生成更新脚本,并且脚本内部没有删除已存在的表,upgrade以后能够生成新表!!!
留言
在使用flask-migrate的过程中还有一个问题困扰我:我指定表的schema为非public,然后每次添加或者删除字段的时候,就会重新创建表,然后就会报表已经存在的错误。。。各位的大佬有知道解决方案的话欢迎留言!!!
这篇关于Flask-Migrate数据库迁移大坑!!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




