本文主要是介绍Qcom camera hal简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景
Android相机软件框架
Qcom HAL主要包括Camx和Chi两部分
Camx中Pipeline 和 node
下图是简单模型的pipeline (sensor --> IFE --> IPE --> SinkTarget)
Pipeline中的buffer管理
IFE output port的buffer在Camx中申请
IPE output port使用的buffer来自上层传入, IPE input port使用IFE的output port的buffer.
get_number_of_cameras
创建HAL工作的Environment
枚举物理camera (ProbeImageSensorModules)
解析相机信息表, 创建各种Camera ID的映射关系, 向上层返回FwCameraNums
cameraId的最终使用过程
四个文件的使用
devicetree中的xxx_camera-sensor.dtsi文件
cameraModuleData文件
sensorDriverData文件
枚举物理camera的过程 (ProbeImageSensorModules)
logicalcamerainfo文件(相机信息表)
生成 logicalCameraId
根据position使用冒泡算法进行排序
logicalcameraId 最终顺序
多个 REAR_AUX camera的排序
RoleId和fwkcameraId的对应关系
为了方便操作, fwkCameraId和logicalCameraId的对应关系会记录在全局数组m_cameraIdxToFwkId中
疑问: 最终目的是操作物理camera, 通过fwkCameraId也可以找到物理camera, 为什么还需要logicalCameraId ?
Open 接口
configure_streams
ImageBufferManager管理模型
MetdataBuffer 管理
TAG和 MetdataBuffer
Qcom Camera HAL使用了两套MetadataBuffer管理接口
Qcom的MetadataBuffer管理.
Metadata buffer的简单使用模型:
关键处理接口.
申请Buffer:
copy和merge的区别
关键数据结构
CHI中的实现
ChiMetadataManager
camx中的实现
MetaBuffer
MetadataPool
Request在Camx中的处理
Camx中node的dependency.
pipeline使用DRQ来管理Node.
简单模型的完整处理过程
代码执行过程:
Node::SetupRequest的实现
Node::SetDependencies
DRQ::AddDeferredNode
DRQ::AddDependencyEntry
DRQ::UpdateDependency
DRQ中的状态机.
DependencyUnit 结构体
Dependency结构体.
Request在Chi中的处理
Chi中的dependency.
Chi中通过FetureGraph来管理Feature.
Camx中的DRQ和Chi中的FeatureGraph管理模型的对比
相较于Qcom以前的Chi架构, Feature2有如下优势:
使用RTBayer2YUV这个FeatureGraph完成单帧拍照
代码执行过程如下:
Feature处理的状态机:
FeatureGraph中的关键处理
上行获取Feature的dependency
Camx中result返回后的处理
对上行Feature分发多个Request.
小结
背景
比较简单的整理一下Qcom Camera HAL中的主要模块和流程, 包括如下内容:
-
Android相机软件框架 :Qcom HAL主要包括Camx和Chi.
-
get_number_of_cameras :创建HAL的Environment, 枚举物理camera, 解析相机信息表. 建立cameraId映射关系。
-
Open接口 :cameraId映射关系的使用,创建HAL Device
-
configure_streams :根据场景, 配置stream. 创建pipeline, 申请ImageBuffer和metadataBuffer.
-
ImageBuffer管理 :保存图像数据的buffer, 使用MemPoolMgr(内存池)和ImagebufferManger两部分管理.
-
MetadataBuffer管理 :保存TAG的buffer, 使用ChiMetadataManager(相当于内存池)和camx中MetadataPool两部分管理
-
request 过程 :Request在Camx中处理, Request在Chi中的处理
Android相机软件框架
Camera HAL3是个per-frame Request的模型, 用一个Request来描述上层希望底层如何处理某一帧, 基本的处理框架如下所示:
调用关系: APP --> Frameworks --> cameraservice --> provider--> OEM HAL --> Qcom HAL.
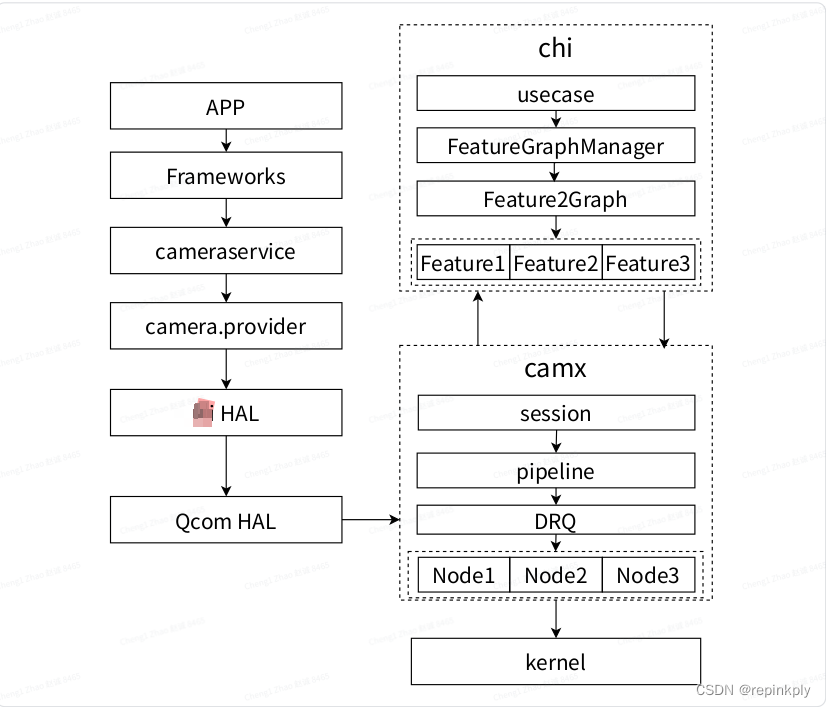
Qcom HAL主要包括Camx和Chi两部分
-
Camx中完成一条pipeline的处理, 通过DRQ完成Request在Node中的调度.
-
Chi中客制化一些Usecase, Feature, 使用Camx中的一条或者多条pipeline来实现.
Camx中Pipeline 和 node
-
高通将功能模块抽象成Node来管理. 将Node串联, 形成Pipeline. Pipeline 的输入是srcTarget, 输出是SinkTarget。
-
Node有多个Port口, 使用Link, 通过Port口将Node与Node, Node与SrcTarget, Node与SinkTarget连接起来.
下图是简单模型的pipeline (sensor --> IFE --> IPE --> SinkTarget)
-
这条pipeline包括sensor, ife, ipe三个node, 没有3A node, 仅用于调试使用.
-
Sensor输出Raw数据的信号, 经IFE处理转为YUV数据, 经IPE降噪裁剪输出到SinkTarget buffer.
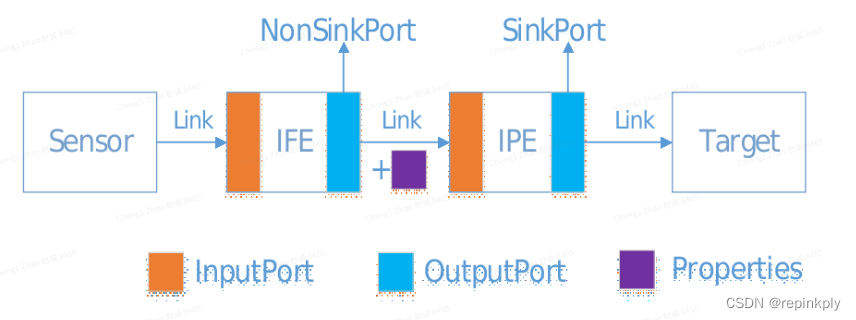
Pipeline中的buffer管理
IFE output port的buffer在Camx中申请
-
Node的non sink output port的buffer在Camx中申请.
IPE output port使用的buffer来自上层传入, IPE input port使用IFE的output port的buffer.
-
Node的sink output port的buffer上层传入.
-
Node的input port使用父node(上行) 的output port的buffer.
下面整理一些关键函数和模块的实现
get_number_of_cameras
获取当前设备中相机的总和, 包括单摄, 多摄, 虚拟Camera. 在provider启动的时候调用, 主要完成三件事, 流程如下:
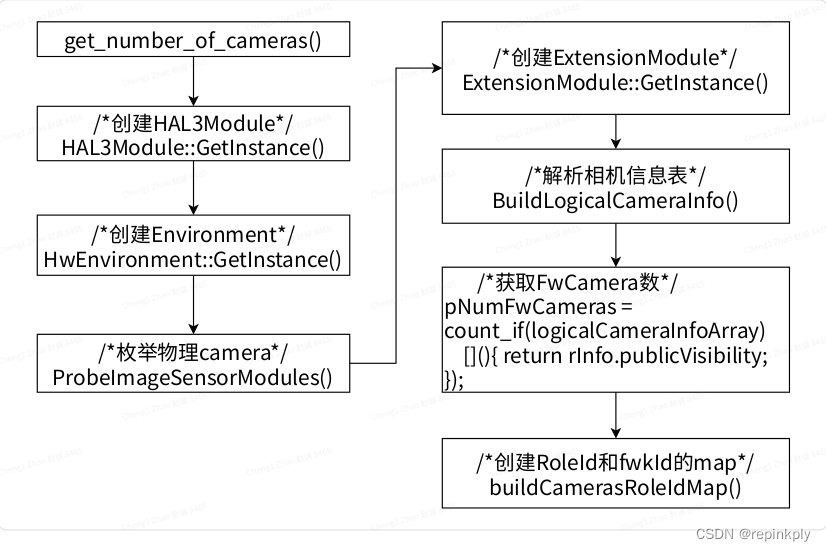
创建HAL工作的Environment
-
在Camx中创建HAL3Module, HwEnvironment.
-
在Chi中创建ExtensionModule.
-
在这个过程中, 创建了一些线程, 创建了很多static类型的数据, 相机退出的时候不会销毁.
枚举物理camera (ProbeImageSensorModules)
通过CameraModuleData和SendorDriverData文件, 结合devicetree中的sensor信息, 枚举物理camera
解析相机信息表, 创建各种Camera ID的映射关系, 向上层返回FwCameraNums
-
每个设备都有相机信息表, 描述当前设备中的单摄, 多摄, 虚拟Camera等信息
-
将fwkCameraId和物理camera的对应关系保存到全局数据区中.
-
HAL中为camera定义了RoleId, 创建RoleId和fwkCameraId的map关系, 返回给APP.
HAL中定义了多种CameraId, CameraId之间会有对应的映射关系, 先总结一下CameraId的最终使用。
cameraId的最终使用过程
App中通过RoleId, 找到对应fwkCameraId, open的时候下发给HAL.
HAL中通过fwkCameraId找到logicalCameraId, 然后通过logicalCameraId找到物理cameraId, 然后操作对应的物理设备.
四个文件的使用
在get_number_of_cameras流程中, 涉及四个文件, 下面分析四个文件的使用,
重点关注相机信息表和cameraID映射关系的建立.
devicetree中的xxx_camera-sensor.dtsi文件
代码路径: vendor/qcom/proprietary/devicetree/qcom/camera/renoir-sm7350-camera-sensor.dtsi
每个camera在dtsi文件中都有对应的配置信息.
在KMD中 probe sensor的driver时候解析, 其中用cell-index标识具体的物理camera. 假如手机有4个camera, cell-index依次为0, 1, 2, 3
// wide camera
qcom,cam-sensor0 {cell-index = <0>;compatible = "qcom,cam-sensor";csiphy-sd-index = <1>;sensor-position-roll = <90>;sensor-position-pitch = <0>;sensor-position-yaw = <180>;eeprom-src = <&eeprom_wide>;actuator-src = <&actuator_wide>;led-flash-src = <&led_flash_wide>;cam_vio-supply = <&L5I>;cam_vdig-supply = <&L1I>;cam_vana-supply = <&L6I>;cam_vaf-supply = <&L3I>;cam_clk-supply = <&cam_cc_titan_top_gdsc>;regulator-names = "cam_vio", "cam_vdig", "cam_vana", "cam_vaf","cam_clk";
};其中,cell-index = <0>; 是重点。
cameraModuleData文件
代码路径: vendor/qcom/proprietary/chi-cdk/oem/qcom/module/renoir_module/renoir_ofilm_s5kgw3_wide_module.xml
每个模组都有对应的cameraModuleData文件, 模组中包括sensor, eeprom, flash等模块的信息.
文件中的cameraId和dtsi文件中的cell-index一样, 标识具体的物理camera. 如果是同一camera, 这两个值必须一样.
通过sensorName可以找到对应的sensorDriverData.
<cameraModuleData<!--Module group can contain either 1 module or 2 modulesDual camera, stereo camera use cases contain 2 modules in the group --><moduleGroup><!--Module configuration --><moduleConfiguration description="Module configuration"><!--CameraId is the id to which DTSI node is mapped.Typically CameraId is the slot Id for non combo mode. --><cameraId>0</cameraId><!--Name of the sensor in the image sensor module --><sensorName>renoir_ofilm_s5kgw3_wide</sensorName><!--Name of the module integrator --><moduleName>renoir</moduleName> <!--Actuator name in the image sensor moduleThis is an optional element. Skip this element if actuator is not present --><actuatorName>renoir_ofilm_s5kgw3_dw9800_wide</actuatorName><!--EEPROM name in the image sensor moduleThis is an optional element. Skip this element if EEPROM is not present --><eepromName>renoir_ofilm_s5kgw3_gt24p128e_wide_eeprom</eepromName><!--Flash name is used to used to open binary.Binary name is of form flashName_flash.bin Ex:- pmic_flash.bin --><position>REAR</position><!--CSI Information --></moduleConfiguration></moduleGroup>
</cameraModuleData>重点:
<cameraId>0</cameraId><!--Name of the sensor in the image sensor module --><sensorName>renoir_ofilm_s5kgw3_wide</sensorName>sensorDriverData文件
代码目录: chi-cdk/oem/qcom/sensor/renoir_sensor/renoir_ofilm_s5kgw3_wide_sensor/gedit s5kgw3_sensor.xml
sensorDriverData文件中定义了camera sensor的I2C slaveAddress 和 sensorId等信息.
枚举物理camera的过程 (ProbeImageSensorModules)
-
传入slaveAddress, 通过I2C读取sensorId对应的寄存器,
-
读出的值与文件中的sensorId值匹配, 如果相同, 则probe sensor成功.
-
probe成功的个数就是物理camera的个数.
<sensorDriverDataxmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="../../../../../api/sensor/camxsensordriver.xsd"><module_version major_revision="1" minor_revision="0" incr_revision="0"/><!--Sensor slave information --><slaveInfo><!--Name of the sensor --><sensorName>renoir_ofilm_s5kgw3_wide</sensorName><!--8-bit or 10-bit write slave address --><slaveAddress>0x20</slaveAddress><!--Register address / data size in bytes --><regAddrType range="[1,4]">2</regAddrType><!--Register address / data size in bytes --><regDataType range="[1,4]">2</regDataType><!--Register address for sensor Id --><sensorIdRegAddr>0x0000</sensorIdRegAddr><!--Sensor Id --><sensorId>0x7309</sensorId><!--Mask for sensor id. Sensor Id may only be few bits --><sensorIdMask>0xFFFFFFFF</sensorIdMask><!--I2C frequency mode of slavelogicalcamerainfo文件(相机信息表)
路径: vendor/qcom/proprietary/chi-cdk/oem/qcom/multicamera/logicalcamerainfo/renoir/renoir.xml
每个手机都有对应的logicalcamerainfo文件, 例如K9使用renoir.xml, 文件中定义了当前手机中相机情况,
-
包括有几个单摄, 几个多摄和VT camera, 各个相机的功能是什么, 使用的fwkCameraId是什么, 对应的物理camera是什么.
-
文件中的 slotId 和 'cameraModuleData文件中的cameraId', 以及 ‘dtsi文件中的cell-index’ 一样, 标识具体的物理sensor.
-
文件中的cameraId其实是返回给APP的fwkCameraId.
-
name=“RearPhysicalCam" slotId="0" cameraId="0", 表示后置摄像头, 物理cameraId是0, fwkCameraId是0
-
“MultiCamera”用于SAT, 它fwkCameraId是4, 使用Ultra (slotId 为3) 和 Rear (slotId 为0)两个摄像头.
-
-
在BuildLogicalCameraInfo阶段, 会将文件中的信息整理保存到全局数据区m_logicalCameraInfo中.
-
文件中定义的相机的总数, 就是get_number_of_cameras返回给APP的FwkCameraNums.
<Devices<PhysicalDevice name="RearPhysicalCam" slotId="0" cameraId="0"/><PhysicalDevice name="FrontPhysicalCam" slotId="1" cameraId="1"/><PhysicalDevice name="MacroPhysicalCam" slotId="2" cameraId="2"/><PhysicalDevice name="UltraPhysicalCam" slotId="3" cameraId="3"/><LogicalDevice name="MultiCamera" cameraId="4" primaryCamName="RearPhysicalCam"><PhysicalDeviceRef>UltraPhysicalCam</PhysicalDeviceRef><PhysicalDeviceRef>RearPhysicalCam</PhysicalDeviceRef></LogicalDevice><LogicalDevice name="bokeh" cameraId="5" primaryCamName="RearPhysicalCam"><PhysicalDeviceRef>UltraPhysicalCam</PhysicalDeviceRef><PhysicalDeviceRef>RearPhysicalCam</PhysicalDeviceRef></LogicalDevice><LogicalDevice name="VTCamera" cameraId="6" primaryCamName="RearPhysicalCam"><PhysicalDeviceRef>RearPhysicalCam</PhysicalDeviceRef><PhysicalDeviceRef>UltraPhysicalCam</PhysicalDeviceRef><PhysicalDeviceRef>MacroPhysicalCam</PhysicalDeviceRef></LogicalDevice><LogicalDevice name="VTCameraFront" cameraId="7" primaryCamName="FrontPhysicalCam"><PhysicalDeviceRef>FrontPhysicalCam</PhysicalDeviceRef><PhysicalDeviceRef>RearPhysicalCam</PhysicalDeviceRef></LogicalDevice></Devices>生成 logicalCameraId
上述分析, 得到了fwkCameraId, 物理cameraId. 我们在HAL中实际使用的是logicalCameraId, 这个logicalCameraId怎么来?
把全局数组m_logicalCameraInfo的下标当做logicalcameraId.
为了统一管理, HAL中会根据camera的position的顺序, 对m_logicalCameraInfo数组进行排序.
/// @brief camera sensor role/type
typedef enum ChiSensorPositionType
{NONE = 0, /// not part of multicameraREAR = 1, /// Rear main cameraFRONT = 2, /// Front main cameraREAR_AUX = 3, /// Rear Aux CameraFRONT_AUX = 4, /// Front aux camera
} CHISENSORPOSITIONTYPE;根据position使用冒泡算法进行排序
SortSensorDataObjects()
{for (UINT i = 0; i < m_numberOfDataObjs; i++){for (UINT j = 0; j< m_numberOfDataObjs - i - 1; j++){m_ppDataObjs[j]->GetCameraPosition(&tmpPosition0);m_ppDataObjs[j+1]->GetCameraPosition(&tmpPosition1);if (tmpPosition0 > tmpPosition1){pTmpImageSensorModuleData = m_ppDataObjs[j];m_ppDataObjs[j] = m_ppDataObjs[j + 1];m_ppDataObjs[j + 1] = pTmpImageSensorModuleData;}}}
} logicalcameraId 最终顺序
-
多摄ID按照logicalcamerainfo文件中定义的顺序.
-
单摄ID顺序为: REAR (cameraId 0) -- > FRONT (cameraId 1) --> REAR_AUX(cameraId 2) --> FRONT_AUX (cameraId 3)
多个 REAR_AUX camera情况, 比如有macro和ultra, 他们的position相同 , 他们的logicalcameraId怎么确定?
多个 REAR_AUX camera的排序
-
由HAL读取cameraModuleData的bin文件的顺序决定, 先被读到的排在前面.
-
bin文件的读取顺序跟d_off的属性相关. 不同的rom版本中的bin文件的d_off属性不同, logicalCameraId的顺序也会不同.
排序只影响了logicalCameraId, 并不影响frameworkId和CameraId的对应关系.
RoleId和fwkcameraId的对应关系
HAL为相机定义了RoleId的概念, 并且建立了fwkcameraId 和 RoleId的对应关系, 如下所示:
然后将这个对应关系以TAG的形式传递给APP.
fwkcameraId RoleId
std::map<UINT32, UINT32> CameraConfigFwr2RoleId = {{0, RoleIdRearWide },{1, RoleIdFront },{2, RoleIdRearMacro2x},{3, RoleIdRearUltra },{4, RoleIdRearSat },{5, RoleIdRearBokeh },{6, RoleIdRearVt },{7, RoleIdFrontVt },
};enum CameraRoleId {RoleIdTypeNone = -1, // used for diagcheckRoleIdRearWide = 0,RoleIdFront = 1,RoleIdRearTele = 20,RoleIdRearUltra = 21,RoleIdRearMacro = 22,RoleIdRearTele4x = 23,RoleIdRearMacro2x = 24,
};为了方便操作, fwkCameraId和logicalCameraId的对应关系会记录在全局数组m_cameraIdxToFwkId中
Open的时候使用m_cameraIdxToFwkId, 通过fwkCameraId可以找到logicalCameraId.
// Fill up the camera maps
for (const LogicalCameraInfo& rLogicalCam : m_multiCameraResources.logicalCameraInfoArray)
{m_cameraIdxToFwkId[rLogicalCam.cameraId] = rLogicalCam.frameworkId;
}疑问: 最终目的是操作物理camera, 通过fwkCameraId也可以找到物理camera, 为什么还需要logicalCameraId ?
向同事咨询: 为了兼容老的机型和老的架构
Open 接口
传入frameworkId, 通过ID映射关系找到对应的logicalCameraId, 后续在HAL中使用.
创建HALDevice::Create, 返回给provider, 后续provider通过device完成对Camera HAL3的操作.
static int CamX::open(const struct hw_module_t* pHwModuleAPI,const char* pCameraIdAPI,struct hw_device_t** ppHwDeviceAPI)
{frameworkId = OsUtils::StrToUL(pCameraIdAPI, &pNameEnd, 10);for (UINT32 i = 0; i < m_numLogicalCameras; i++){if (m_cameraIdxToFwkId[i] == frameworkId){logicalCameraId = i;break;}}HALDevice* pHALDevice = HALDevice::Create(pHwModule, logicalCameraId, frameworkId);camera3_device_t* pCamera3Device = (pHALDevice->GetCameraDevice());*ppHwDeviceAPI = &pCamera3Device->common;
}configure_streams
配置当前场景的stream, 完成创建Usecase, 创建pipeline, 申请ImageBuffer, 申请MetadataBuffer等操作, 主要处理过程如下:
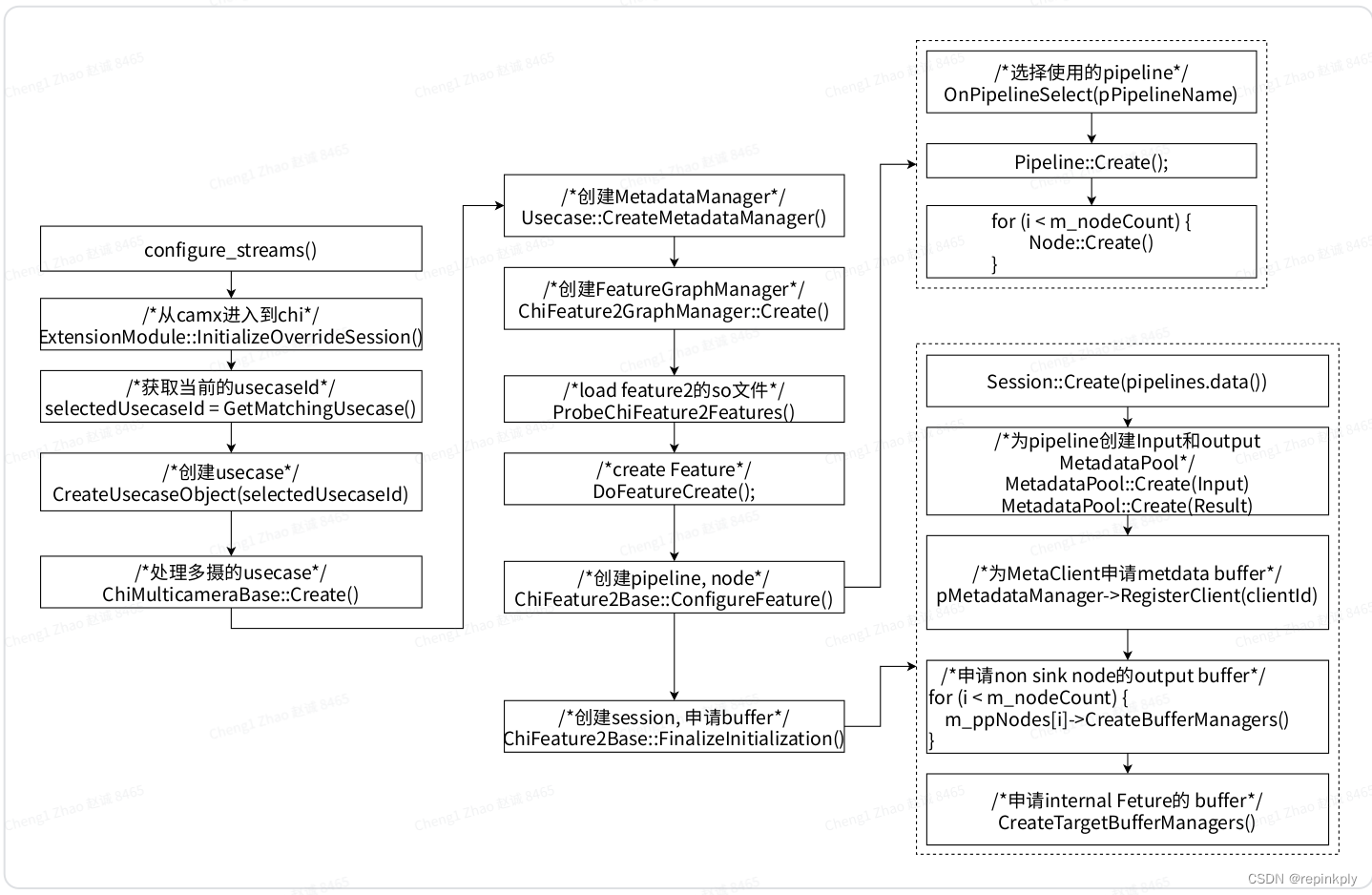
-
根据传入的operation_mode, stream个数以及 stream 的width, height, format等配置信息选取对应的 UsecaseId.
-
根据UsecaseId, 创建Usecase. (CreateUsecaseObject)
-
有文档中描述高通后续单双摄都使用ChiMulticameraBase这个Usecase.
-
-
创建MetadataManager, 后续用于申请, 管理metadata buffer.
-
加载所有的feature2的so文件, create对应的Feature对象.
-
Feature::ConfigureFeature:
-
为Feature选择使用的pipeline. 创建pipeline, 创建node.
-
-
Feature::FinalizeInitialization(申请buffer):
-
创建Session, 向KMD中发送CRM_CREATE_SESSION, 返回sesion handle.
-
创建pipeline的input, output的MetadataPool.
-
调用MetadataManager的RegisterClient为pipeline申请metadata buffer, 保存到client的数据区中.
-
为node的non sink output port申请 buffer.
-
为non sink的feature申请internal buffer, 用作pipeline的sinkTarget buffer.
-
ImageBufferManager管理模型
这部分可以参考:BufferManager-CSDN博客
MetdataBuffer 管理
TAG和 MetdataBuffer
TAG是由key值和对应的data值组成一个参数对, 用于在App和HAL间传递参数.
MetadataBuffer是TAG的集合, 保存了多个TAG的信息, 在HAL中使用内存池和vector来管理MetdataBuffer.
Qcom Camera HAL使用了两套MetadataBuffer管理接口
-
对外(与APP通信)使用Android的接口(camera_metadata.*).
-
APP下发Android接口的camera_metadata.*, 在HAL内部转换为Qcom接口的MetadataBuffer使用;
-
HAL处理完后, 将MetadataBuffer转换为Android接口的camera_metadata.*, 返回给APP;
-
-
对内使用Qcom自定义的metadata接口 (camxmetadata)
-
在Camx中完成session, pipeline, node之间数据传递;
-
高通定义了property相关的的TAG, 是node的dependency的一种, 在DQR调度node的时候使用到.
-
-
两套接口都提供了插入/删除, set/get等接口.
-
相较于Android的接口, Qcom的MetadataBuffer中key和data各自有独立的buffer区域, 分离存储. 同时使用了LinearMap, 接口更高效.
-
Qcom的MetadataBuffer管理.
Qcom使用Chi中的ChiMetadataManager和Camx中MetadataPool两部分来实现MetadataBuffer管理.
-
ChiMetadataManager中定义了MetaClient的概念, 不同的用途使用不同的Client申请metadataBuffer.
-
在configure_streams的流程中, 已经为MetaClietn申请了buffer.
-
调用RegisterClient申请num个metadataBuffer后, 使用vector(m_bufferList)来管理. Client是源头, 是内存池,
-
后续根据需要, 使用getInput或Get接口从Client的m_bufferList上取buffer使用.
-
-
在configure_streams的流程中, 为pipeline创建input MetadataPool 和output MetadataPool.
-
MetadataPool是容器, request的时候, 将Chi中下发的metadataBuffer保存到MetadataPool的slot中.
-
Metadata buffer的简单使用模型:
下图描述一个request中metadataBuffer的使用过程.
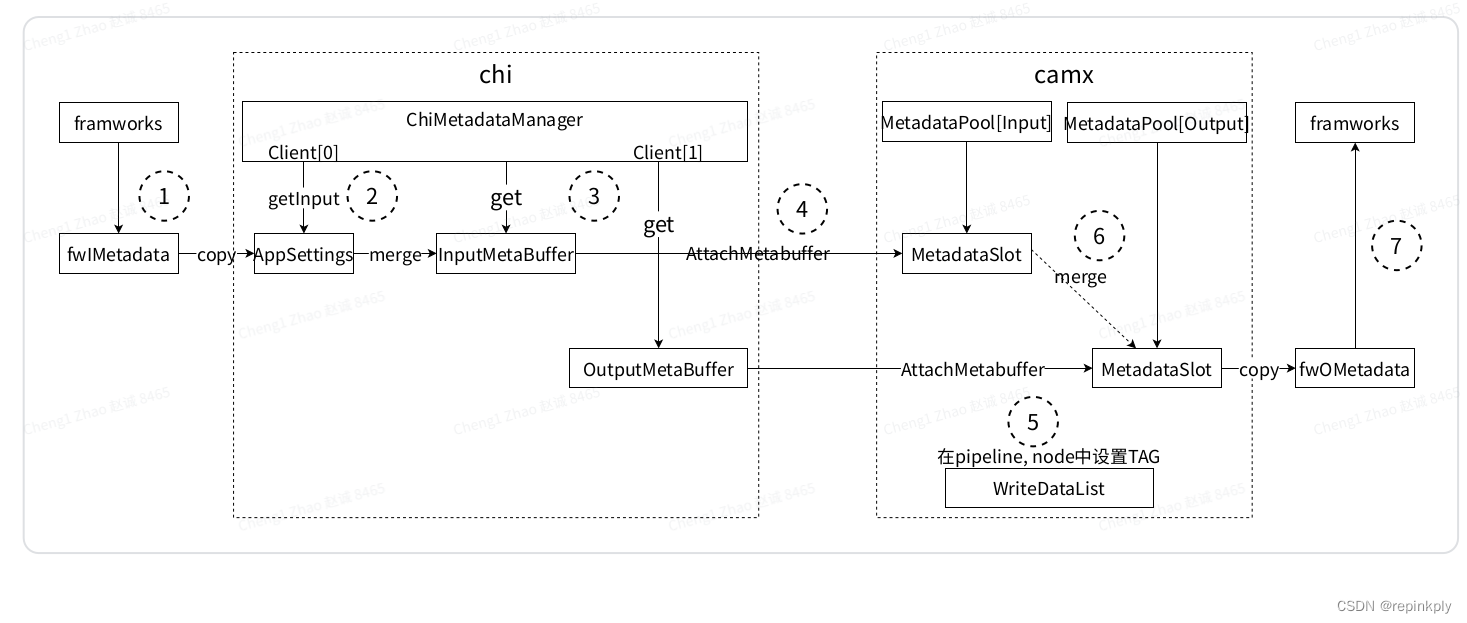
-
将APP传入的metadata保存到fwImetadata中.
-
通过GetInput()从Client[0]获取一个bufffer (AppSettings),
-
将fwImetadata copy到AppSettings中.
-
-
通过Get()从Client[1] 申请pipeline的InputMetaBuffer和OutputMetaBuffer.
-
Camx中将InputMetaBuffer和OutputMetaBuffer通过AttachMetabuffer保存到MetadataPool的slot中.
-
在pipeline和node的ProcessRequest函数中, 通过slot找到对应的metadataBuffer, 设置TAG.
-
调用WriteDataList, 更新DRQ的dependency信息.
-
-
将InputMetaBuffer merge到OutputMetaBuffer中. 将OutputMetaBuffer 拷贝到afwoMetadata中,
-
将afwoMetadata返回给APP.
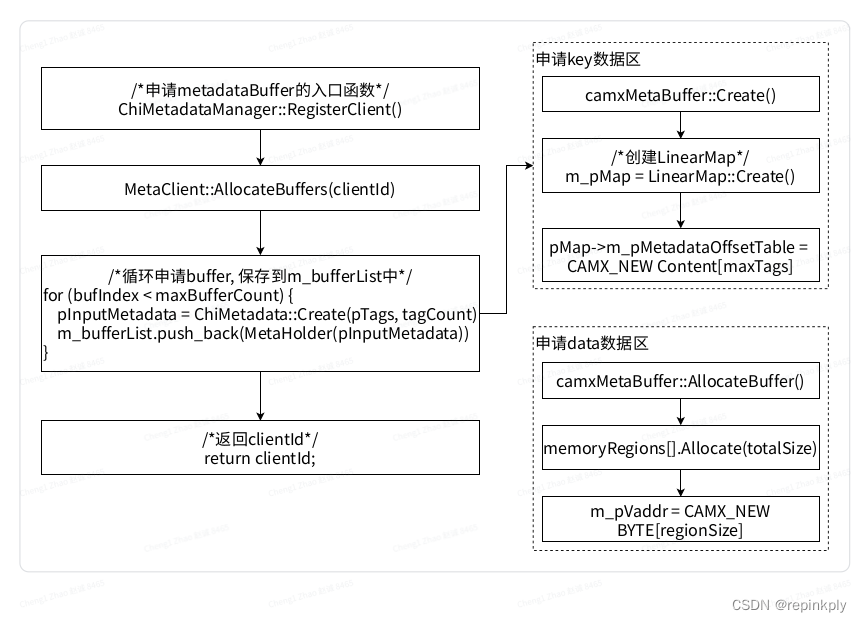
关键处理接口.
申请Buffer:
-
在chi中调用ChiMetadataManager的RegisterClient函数申请buffer.
-
创建chiMetadata, 选择MetaClient, 调用MetaClient的AllocateBuffers函数.
-
在camx中, 创建camxMetaBuffer, camxMetaBuffer不需要这个做ion映射, 所以用new申请虚拟内存就可以了.
-
new Content存储TAG的key值.
-
new Region数据区存储TAG的data值.
-
-
-
将camx中创建的MetaBuffer保存到ChiMetadata的m_metaHandle中, 将ChiMetadata挂到MetaClient的m_bufferList上.
-
返回cleintId, 后续获取buffer的时候通过clientId找到对应的client.
copy和merge的区别
-
Copy 深拷贝, 将src的数据拷贝到dst中, dst的data的数据区空间会增加.
-
Merge 浅拷贝, 将src中TAG的地址信息保存到dst的content中, dst的data的数据区空间不会增加.
-
如果采用disjoint方式merge, dst中已有的TAG不会被src覆盖.
-
关键数据结构
CHI中的实现
在chi中创建ChiMetadataManager, ChiMetadataManager中包含多个MetaClient, MetaClient中包含存放ChiMetadata的m_bufferList.
ChiMetadataManager提供RegisterClient接口, 调用Client中AllocateBuffers的接口, 最终会调用到camx中申请metadataBuffer的接口.
ChiMetadataManager
ChiMetadataManager提供RegisterClient等接口, 包括num个Client.
Client中提供Allocate ChiMetadata的接口, 同时提供挂载ChiMetadata的m_bufferList列表.
class ChiMetadataManager
{UINT32 RegisterClient();ChiMetadata* GetInput();ChiMetadata* Get();struct MetaClient{/// Allocate buffersCDKResult AllocateBuffers();struct MetaHolder{ChiMetadata* pMetadata; ///< Pointer to metadata object};std::vector<MetaHolder> m_bufferList; ///< Vector of buffersstd::array<SubClient, ChxMaxMetadataClients> m_subClient; ///< List of sub clientsUINT32 m_clientIndex; ///< Index of this client};std::array<MetaClient, 256> m_clients; ///< Array of clients
}ChiMetadata中的m_metaHandle指向camx中MetaBuffer.
class ChiMetadata
{static ChiMetadata* Create();VOID* GetTag();CDKResult SetTag();CDKResult Merge();CDKResult Copy();CHIMETADATAHANDLE m_metaHandle; ///< Metadata handleCHIMETADATACLIENTID m_metadataClientId; ///< Client Identity for CamX Metadata BufferUINT32 m_metadataManagerClientId; ///< Client identifier for the metadata manager
}camx中的实现
包括MetaBuffer和MetadataPool.
MetaBuffer
-
MetaBuffer保存TAG的key值和data数据, 主要包括Map和 memoryRegions两部分.
-
Map中使用的Content保存Tag的值, 以及Tag的data数据的大小以及在MemoryRegion中的存储位置信息.
-
MemoryRegion保存TAG对应的data数据, 是可扩展的内存块.
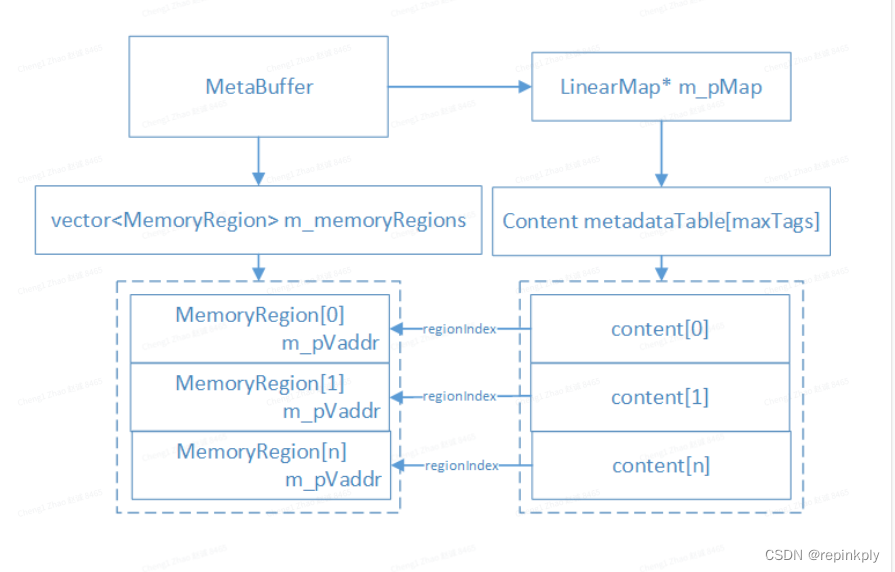
class MetaBuffer final
{CamxResult AllocateBuffer();CamxResult Merge()CamxResult Copy(); VOID* GetTag();CamxResult SetTag();class MemoryRegion{BYTE* m_pVaddr; ///< Address of buffers allocatedUINT32 m_size; ///< Size of the buffers allocatedINT32 m_fd; ///< File descriptor of the buffers allocated, if they are not heap allocated CamxResult Allocate(UINT32 regionSize);}class Content{UINT32 m_tag; ///< Tag identifierUINT32 m_regionIndex; ///< Memory region index reserved for this data in the current bufferUINT32 m_offset; ///< Offset from the memory region reserved for this bufferUINT32 m_size; ///< Size of the content. must match the tag sizeBYTE m_data[MaxInplaceTagSize]; ///< In place memory} class LinearMap final : public Map{virtual VOID Insert()virtual VOID Copy();virtual VOID Merge();Content* m_pMetadataOffsetTable; }std::vector<MemoryRegion> m_memoryRegions; ///< List of memory regionsMap* m_pMap; ///< Addressing policy container object pointer
}MetadataPool
MetadataPool 是用来存放MetadataBuffer的, 包含num个Slot. processRequest的时候将申请好的buffer保存到slot中, 后续供pipeline, node等使用.
提供接口, 监听TAG值修改, 供DRQ使用.
class MetadataPool final
{CamxResult SubscribeAll(IPropertyPoolObserver* pClient,const CHAR* pClientName);VOID NotifyClient();UINT m_numSlots; ///< Number of slots that this pool containsMetadataSlot* m_pSlots[MaxPerFramePoolWindowSize]; ///< Array of slots in the Pool
}class MetadataSlot final
{CamxResult AttachMetabuffer(MetaBuffer* pMetabuffer);CamxResult GetMetabuffer(MetaBuffer** ppMetabuffer);CamxResult PublishMetadata(); MetaBuffer* m_pMetaBuffer; ///< pointer to the metabuffer
}-
监听TAG值修改的接口.
class IPropertyPoolObserver
{virtual VOID OnPropertyUpdate();virtual VOID OnMetadataUpdate();
}在HAL中, 一个request包括在Camx和在Chi中的处理.
Request在Camx中的处理
Camx中的pipeline包括多个node, DRQ根据各个node的dependency信息, 完成Request在各个node中执行.
Camx中node的dependency.
在Camx中, pipeline中的node工作时, 相互之间有依赖关系, 用dependency表示, 主要包括多个TAG和多个buffer.
举例: IPE工作需要IFE的output buffer输入, IPE还会用到sensor和IFE的一些TAG信息, 这些是IPE的dependency.
Pipeline中至少有一个node是没有dependency的, Request在所有node中都执行完, Request流程结束.
pipeline使用DRQ来管理Node.
-
DRQ中使用ready, deferred队列和DependencyMap(保存了dependency)来控制node的执行顺序.
-
一般情况, node一个request分为sequence(0), sequence(1)两个处理阶段. node的processRequest执行两次.
-
很多平台按顺序依次执行pipeline中node的request, 只执行一次node的processRequest.
-
Qcom采用多sequence阶段处理的方式, 更灵活, 可以更好的完成Node的适配和扩展.
-
-
sequence(0): 设置node的dependency, 保存到DependencyUnit数据区中.
-
sequence(1): 配置node的input和output buffer.
-
硬件node向kernel submit packet.
-
软件node执行算法process.
-
简单模型的完整处理过程
我们使用简单模型整理Request在各个Node中间的调度过程,
sensor没有依赖, IPE依赖一些TAG和IFE返回的buffer, TAG先于buffer被满足.
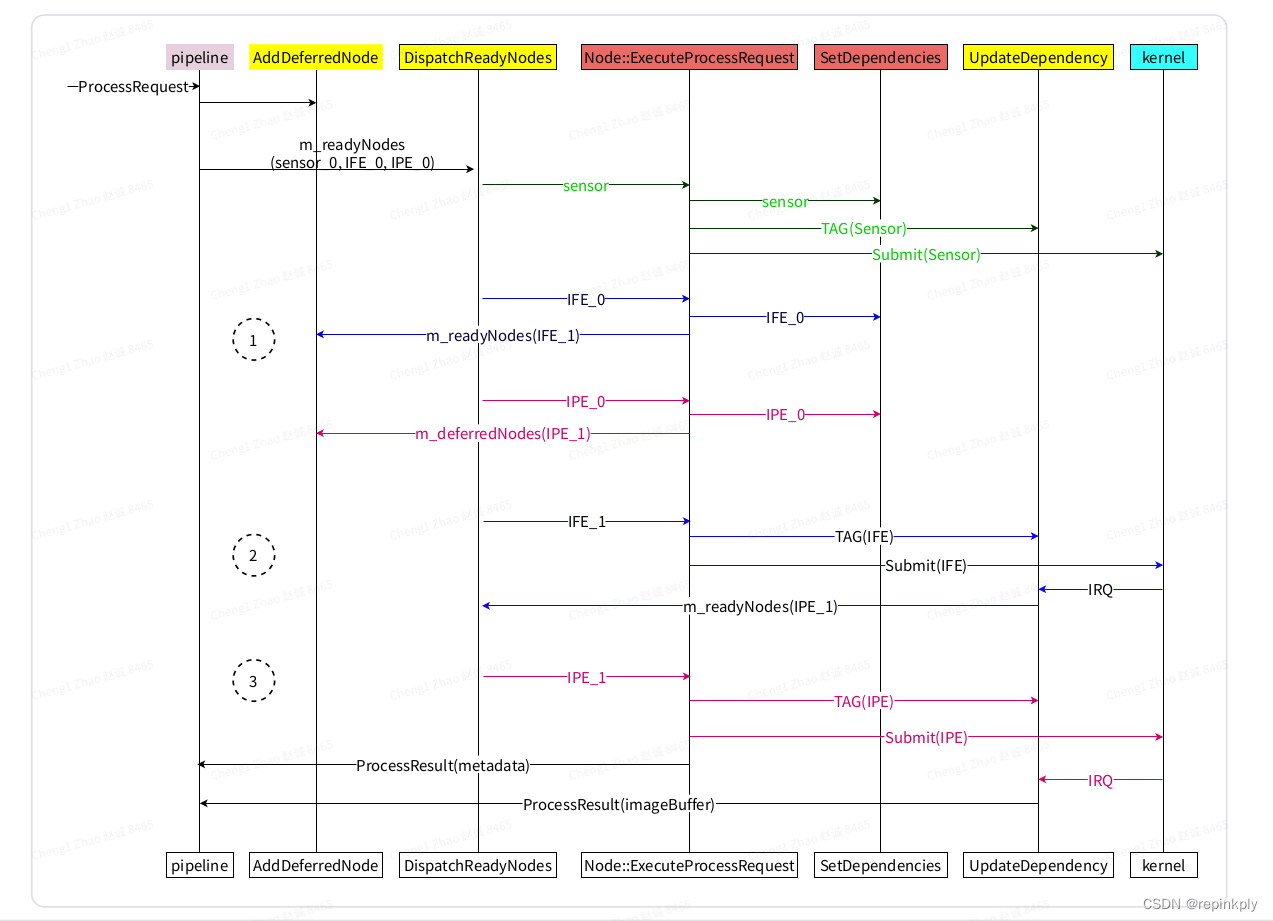
-
首先将sensor, ife, ipe都挂到ready队列, while循环处理ready队列上的node.
-
执行sensor的sequence(0)阶段, sensor没有依赖, 直接执行sequence(1)阶段, 向kernel submit packet, sensor从ready队列删除.
-
执行IFE的sequence(0)阶段, IFE没有依赖, 但设置了hasIOBufferAvailabilityDependency标志位, 继续挂到ready队列上.
-
执行IPE的sequence(0)阶段, IPE依赖IFE的buffer和其他的TAG, 会挂到deferred队列上.
-
执行IFE的sequence(1)阶段, 设置output port的buffer, 向kernel submit packet, 等待中断返回, IFE从ready队列删除.
-
IFE的中断返回后, IPE的dependency被满足.
-
执行IPE的sequence(1)阶段, 设置output port的buffer, 向kernel submit packet, 等待中断返回, IPE从ready队列删除.
-
IPE的中断返回后, 向APP发送result, 整个处理流程结束.
代码执行过程:
主要包括三个过程: 设置Node的buffer, 循环执行所有Node的sequence(0)阶段, dependency被满足后执行Node的sequence(1)阶段.
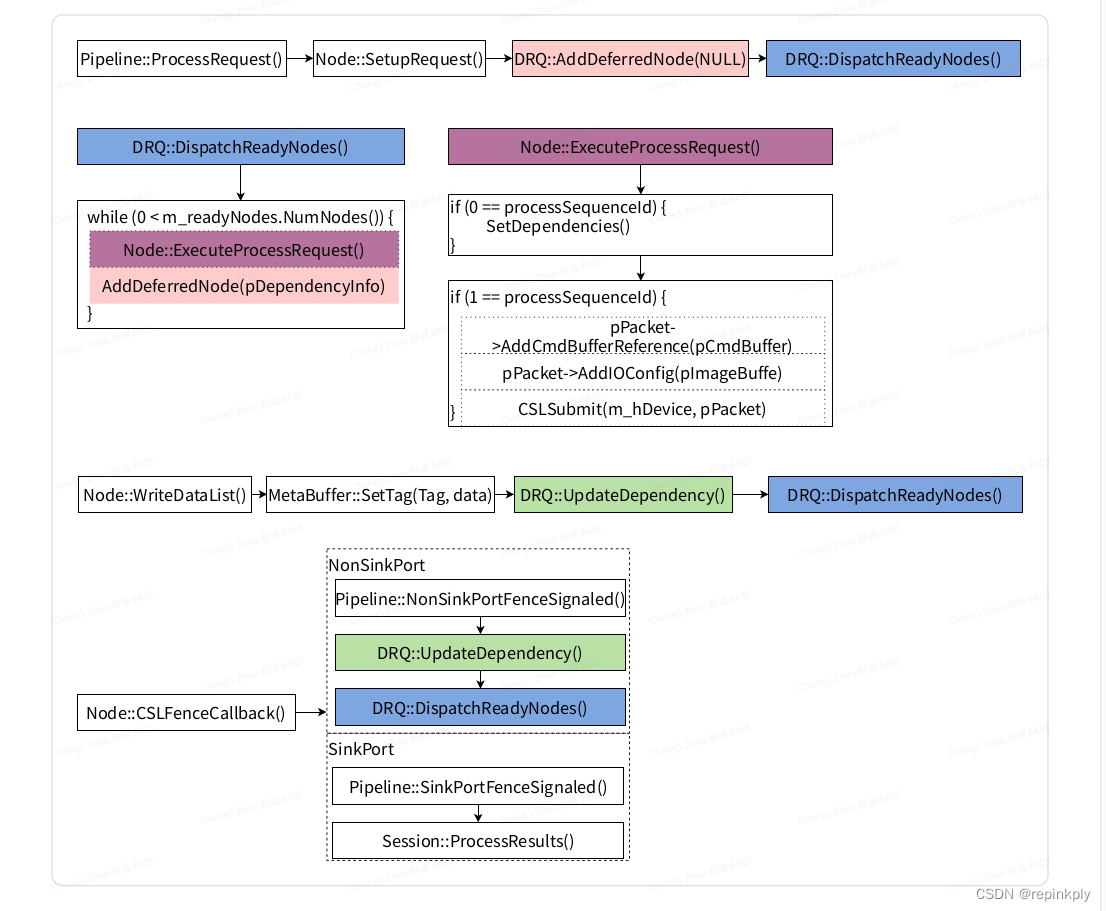
下图表示一个request在camx中的处理, 主要包括如下处理过程:
-
调用SetupRequest, 设置Node port的buffer和fence. 调用AddDeferredNode(NULL)将所有node挂到Ready队列.
-
执行Ready队列上node的ExecuteProcessRequest中的sequence(0)阶段,
-
执行完ExecuteProcessRequest后, 继续调用AddDeferredNode判断node是否有dependency.
-
如果没有dependency
-
将node挂到ready队列, 等待DRQ调度, 执行node的sequence(1)阶段:
-
-
如果有dependency:
-
将node挂到deferredNodes队列, 将dependency信息保存到DRQ的DependencyMap中, 等待dependency被满足后.
-
-
-
有TAG值更新时, 调用UpdateDependency,
-
更新DRQ的DependencyMap中的信息, 判断是否有node dependency被满足
-
如果有node的dependency被满足, 从deferred取下, 挂到ready队列, 等待DRQ调度, 执行node的sequence(1)
-
-
有buffer返回时, 判断是哪类node返回的buffer.
-
如果是nonsink node, 调用UpdateDependency,
-
更新DRQ的DependencyMap中的信息, 判断是否有node的dependency被满足
-
-
如果是sink node, 将buffer返回给chi.
-
下面分析一些关键处理函数.
Node::SetupRequest的实现
设置Node使用的ImageBuffer, 创建对应的fence, 挂载fence的回调函数CSLFenceCallback.
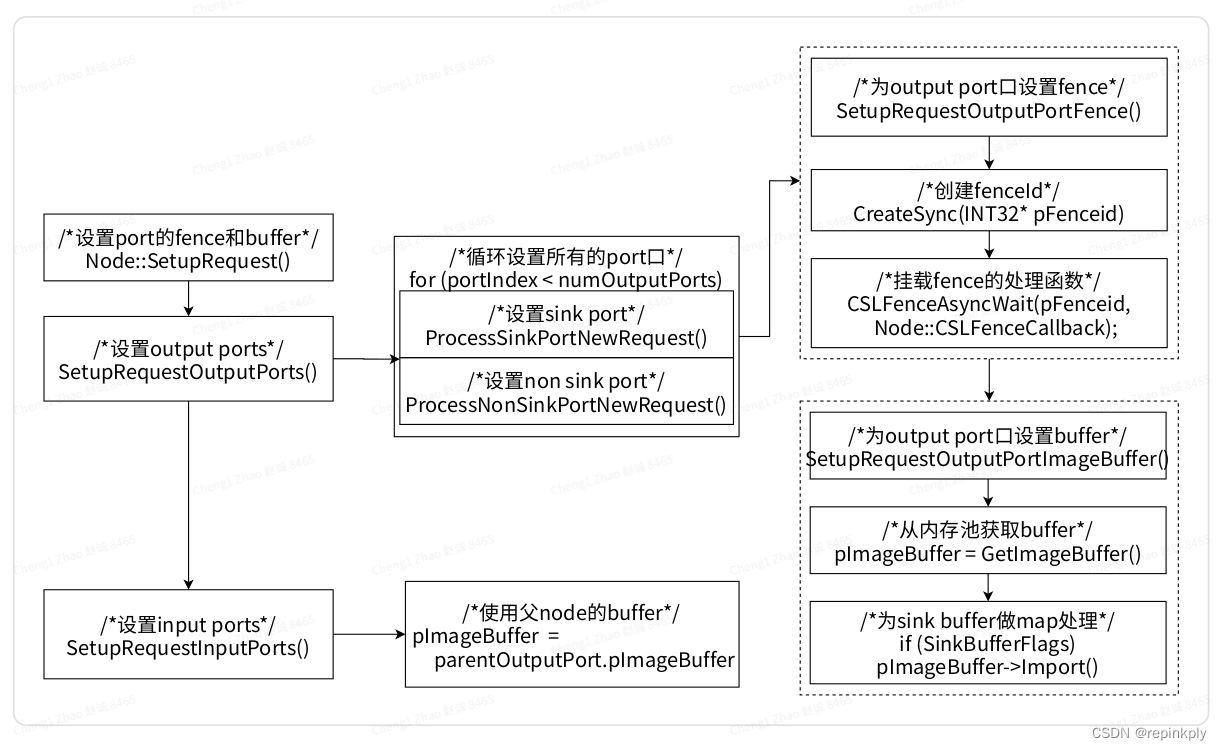
-
配置Output Ports的buffer和fence (SetupRequestOutputPorts):
-
创建Fence, 挂载Fence的处理函数.
-
Fence与buffer绑定, 通过fence可以知道buffer的处理状态.
-
-
设置port的buffer:
-
如果是non sink port, 从ImageBufferManager中获取buffer, 这个buffer在KMD中已做过IOMMU.
-
如果是Sink port, 这个buffer上层传入, 需要再KMD中做map处理.
-
-
-
配置Input Ports的buffer (SetupRequestInputPorts)
-
使用parent Node的output buffer作为当前node的Input port的buffer.
-
Node::SetDependencies
在Node中设置dependency, 包括TAG, buffer两种类型, 保存到DependencyUnit结构体中. 是个++的过程.
-
将依赖的TAG保存到DependencyUnit的properties中, 总数为count值.
-
property可以依赖当前, 过去 或者将来的数据. 使用Negate 与offsets配合实现.
-
negate为TRUE, 表示依赖将来(requestId + offset)的 property.
-
为FALSE表示依赖过去(requestId - offset)的property,
-
为0表示依赖当前request的property.
-
-
-
将依赖的buffer对应的fence值记录到DependencyUnit的phFences中, 总数为fenceCount.
-
设置完dependency后, 将processSequenceId设置为1.
VOID Node::SetDependencies(ExecuteProcessRequestData* pExecuteProcessRequestData,UINT parentNodeId)
{// 设置Node的properties的dependency.// negate为TRUE, 表示依赖将来的 property. 为FALSE表示依赖过去request的property, 为0表示依赖当前request的property.pNodeRequestData->dependencyInfo[0].propertyDependency.properties[count] = tagID;pNodeRequestData->dependencyInfo[0].propertyDependency.offsets[count] = m_lookahead;pNodeRequestData->dependencyInfo[0].propertyDependency.negate[count] = TRUE;count++;pNodeRequestData->dependencyInfo[0].propertyDependency.count = count;if (0 < pNodeRequestData->dependencyInfo[0].propertyDependency.count){pNodeRequestData->dependencyInfo[0].dependencyFlags.hasPropertyDependency = TRUE;}// 设置Input Port的fence的dependency.for (UINT portIndex = 0; portIndex < pEnabledPorts->numInputPorts; portIndex++){pDependencyUnit->bufferDependency.phFences[fenceCount] = pPort->phFence;pDependencyUnit->bufferDependency.pIsFenceSignaled[fenceCount] = pPort->pIsFenceSignaled;fenceCount++;}if (0 < fenceCount){pDependencyUnit->bufferDependency.fenceCount = fenceCount;pDependencyUnit->dependencyFlags.hasInputBuffersReadyDependency = TRUE;}// 增加 processSequenceIdpNodeRequestData->dependencyInfo[0].processSequenceId = 1;
}DRQ::AddDeferredNode
-
解析DependencyUnit中的properties和fence等参数, 保存到Dependency结构体中.
-
调用 AddDependencyEntry 函数, 根据dependency信息将node挂载ready或者deferred队列.
CamxResult DeferredRequestQueue::AddDeferredNode(UINT64 requestId,Node* pNode,DependencyUnit* pDependencyUnit)
{Dependency* pDependency = reinterpret_cast<Dependency*>(CAMX_CALLOC(sizeof(Dependency)));if (NULL != pDependency){pDependency->pInstance = this;pDependency->pNode = pNode;pDependency->requestId = requestId;if (NULL != pDependencyUnit){if (TRUE == pDependencyUnit->dependencyFlags.hasPropertyDependency){GetUnpublishedList(pDependencyUnit, pDependency, requestId);}if (TRUE == pDependencyUnit->dependencyFlags.hasInputBuffersReadyDependency){for (UINT i = 0; i < pDependencyUnit->bufferDependency.fenceCount; i++){if (0 == CamxAtomicLoadU(pDependencyUnit->bufferDependency.pIsFenceSignaled[i])){pDependency->phFences[pDependency->fenceCount++] = pDependencyUnit->bufferDependency.phFences[i];}}}if (TRUE == pDependencyUnit->dependencyFlags.hasFenceDependency){for (UINT i = 0; i < pDependencyUnit->chiFenceDependency.chiFenceCount; i++){pDependency->pChiFences[pDependency->chiFenceCount++] =pDependencyUnit->chiFenceDependency.pChiFences[i];}pDependency->pChiFenceCallback = pDependencyUnit->chiFenceDependency.pChiFenceCallback;pDependency->pUserData = pDependencyUnit->chiFenceDependency.pUserData;}pDependency->processSequenceId = pDependencyUnit->processSequenceId;pDependency->bindIOBuffers = pDependencyUnit->dependencyFlags.hasIOBufferAvailabilityDependency;pDependency->isInternalDependency = pDependencyUnit->dependencyFlags.isInternalDependency;}AddDependencyEntry(pDependency);
}DRQ::AddDependencyEntry
主要完成两件事情:
-
挂队列: 根据node的Dependency中的信息, 将node挂载到Ready或者Derfered队列.
-
propertyCount, fenceCount和chiFenceCount都为0, 则挂到ready队列
-
-
将key存Map: 根据property, fence等信息生成mapKey, 将mapKey保存到DependencyMap中.
-
property的mapKey: 由requestId和properties组成
-
Fence的mapKey: 由0和fence值组成
-
CamxResult DeferredRequestQueue::AddDependencyEntry(Dependency* pDependency)
{UINT64 requestId = pDependency->requestId;BOOL isDeferred = FALSE;LightweightDoublyLinkedListNode* pNode =CAMX_CALLOC(sizeof(LightweightDoublyLinkedListNode));pNode->pData = pDependency;if ((0 == pDependency->propertyCount) &&(0 == pDependency->fenceCount) &&(0 == pDependency->chiFenceCount)){m_readyNodes.InsertToTail(pNode);}else{isDeferred = TRUE;m_deferredNodes.InsertToTail(pNode);}if (TRUE == isDeferred){// Add dependencies for all noted properties at requestIdfor (UINT i = 0; i < pDependency->propertyCount; i++){INT64 offset = (TRUE == pDependency->negate[i]) ? (-1 * static_cast<INT64>(pDependency->offsets[i])): pDependency->offsets[i];INT64 intReq = static_cast<INT64>(requestId);UINT64 request = (intReq - offset <= 0) ? FirstValidRequestId : (intReq - offset);DependencyKey mapKey ={request, pDependency->pipelineIds[i], pDependency->properties[i], pDependency->typeIds[i], NULL, NULL};LightweightDoublyLinkedList* pList = CAMX_NEW LightweightDoublyLinkedList();pNode = reinterpret_cast<LightweightDoublyLinkedListNode*>(CAMX_CALLOC(sizeof(LightweightDoublyLinkedListNode)));pNode->pData = pDependency;pList->InsertToTail(pNode);m_pDependencyMap->Put(&mapKey, &pList);}// Add dependencies for all noted buffer fences at requestIdfor (UINT i = 0; i < pDependency->fenceCount; i++){DependencyKey mapKey = {0, 0, PropertyIDInvalid, TypeIDInvalid, pDependency->phFences[i], NULL};LightweightDoublyLinkedList* pList = CAMX_NEW LightweightDoublyLinkedList();pNode = reinterpret_cast<LightweightDoublyLinkedListNode*>(CAMX_CALLOC(sizeof(LightweightDoublyLinkedListNode)));pNode->pData = pDependency;pList->InsertToTail(pNode);m_pDependencyMap->Put(&mapKey, &pList);}// Add dependencies for all noted Chi Fences at requestIdfor (UINT i = 0; i < pDependency->chiFenceCount; i++){DependencyKey mapKey = {0, 0, PropertyIDInvalid, TypeIDInvalid, NULL, pDependency->pChiFences[i]};LightweightDoublyLinkedList* pList = CAMX_NEW LightweightDoublyLinkedList();pNode = reinterpret_cast<LightweightDoublyLinkedListNode*>(CAMX_CALLOC(sizeof(LightweightDoublyLinkedListNode)));pNode->pData = pDependency;pList->InsertToTail(pNode);m_pDependencyMap->Put(&mapKey, &pList);}}
}DRQ::UpdateDependency
有TAG更新或者有buffer返回, 会调用UpdateDependency, 更新m_pDependencyMap中的信息, 是个--的过程.
-
生成property和fence对应的mapKey, 去m_pDependencyMap中查找, 更新publishedCount和signaledCount的值.
-
如果publishedCount等于propertyCount, 则表示property都被满足.
-
如果signaledCount等于fenceCount, 表示fence都被满足.
-
-
如果property和fence全部被满足, 则将node从deferred队列取下, 挂到ready队列上.
BOOL DeferredRequestQueue::UpdateDependency(PropertyID propertyId,UINT32 typeId,CSLFence* phFence,ChiFence* pChiFence,UINT64 requestId,UINT pipelineId,BOOL isSuccess,BOOL isFlush)
{if (propertyId == PropertyIDInvalid){DependencyKey pMapKey ={0,pipelineId,propertyId,typeId,phFence,pChiFence};}else{DependencyKey pMapKey ={requestId,pipelineId,propertyId,typeId,phFence,pChiFence};}m_pDependencyMap->Get(pMapKey, reinterpret_cast<VOID**>(&pList));if (NULL != pList){LightweightDoublyLinkedListNode* pNode = pList->Head();while (NULL != pNode){LightweightDoublyLinkedListNode* pNext = LightweightDoublyLinkedList::NextNode(pNode);Dependency* pDependency = static_cast<Dependency*>(pNode->pData);if (PropertyIDInvalid != pMapKey->dataId){pDependency->publishedCount++;}else if (NULL != pMapKey->pFence){pDependency->signaledCount++;}else if (NULL != pMapKey->pChiFence){pDependency->chiSignaledCount++;}if ((pDependency->propertyCount == pDependency->publishedCount) &&(pDependency->fenceCount == pDependency->signaledCount) &&(pDependency->chiFenceCount == pDependency->chiSignaledCount)){CAMX_LOG_DRQ("Node: %s - all satisfied. request %llu",pDependency->pNode->NodeIdentifierString(),pDependency->requestId);m_deferredNodes.RemoveNode(pDeferred);m_readyNodes.InsertToTail(pDeferred);}pNode = pNext;}}
}DRQ中的状态机.
HAL中通过状态机标识request在node中的执行阶段, 可以根据状态机确认当前node执行的阶段.
下面是对DependencyUnit 和Dependency结构体介绍.
DependencyUnit 结构体
-
property保存到propertyDependency中. fence保存到bufferDependency中. Chi fence保存到chiFenceDependency中.
-
当前node是否有dependency, 可以通过dependencyFlags来判断.
struct DependencyUnit
{union{struct{UINT32 hasInputBuffersReadyDependency : 1; ///< Node reports buffer dependencyUINT32 hasPropertyDependency : 1; ///< Node reports property dependencyUINT32 hasFenceDependency : 1; ///< Node reports Chi Fence dependencyUINT32 hasIOBufferAvailabilityDependency : 1;};UINT32 dependencyFlagsMask; ///< Flag mask Value} dependencyFlags;///< Set of Property dependency unitsstruct PropertyDependency{UINT32 count; ///< Number of properties in this unitPropertyID properties[MaxProperties]; ///< Property dependencies in this unitUINT32 typeIds[MaxProperties]; ///< TypeId dependency in this unitUINT64 offsets[MaxProperties]; ///< Offset from current request for dependencyBOOL negate[MaxProperties]; ///< Indicate if offsets are negative valueUINT pipelineIds[MaxProperties]; ///< Pipeline index for every Property} propertyDependency;struct{UINT fenceCount; ///< Number of fences to wait forCSLFence* phFences[MaxDependentFences]; ///< Fences to wait forUINT* pIsFenceSignaled[MaxDependentFences]; ///< Fence signal status} bufferDependency; ///< Buffer dependency unitstruct{UINT chiFenceCount; ///< Number of fences to wait forChiFence* pChiFences[MaxDependentFences]; ///< Fences to wait forBOOL* pIsChiFenceSignaled[MaxDependentFences]; ///< Fence signal statusPFNCHIFENCECALLBACK pChiFenceCallback; ///< Callback when all Chi fence dependencies satisfiedVOID* pUserData; ///< Client-provided data pointer for Chi callback} chiFenceDependency; ///< Buffer dependency unitINT32 processSequenceId; ///< SequenceId to provide back to node when dependency satisfied
};Dependency结构体.
在AddDeferredNode中, 解析DependencyUnit中的dependency, 保存到Dependency结构体中, 最终会保存到m_pDependencyMap中.
-
property的保存
-
propertyCount表示总共的property数, publishedCount表示已经满足的property数
-
所有的依赖都保存到properties[]数据结构体中.
-
-
fence的保存
-
fenceCount表示总共的fence数, signaledCount表示已经满足的fence数
-
所有的fence信息保存phFences[]结构体中.
-
struct Dependency
{DeferredRequestQueue* pInstance; ///< Instance of DRQ holding dependencyNode* pNode; ///< Pointer to the node with the dependenciesINT32 processSequenceId; ///< Identifier for the node to track its processing order///< -2, -1, and 0 are reserved for core useBOOL bindIOBuffers; ///< Flag indicating whether node requested input, output buffers/// to be available on this Dependency/*propertyCount表示总共的property数, publishedCount表示已经满足的property数*/ UINT32 propertyCount; ///< Number of properties it is dependant onUINT32 publishedCount; ///< Number of properties that are publishedPropertyID properties[MaxProperties]; ///< Properties which it is dependant onUINT32 typeIds[MaxProperties]; ///< TypeId dependency in this unitUINT64 offsets[MaxProperties]; ///< Offsets from the current request for property dependencyBOOL negate[MaxProperties]; ///< Indicate if offsets are negative valueUINT pipelineIds[MaxProperties]; ///< Pipeline index for the Properties/*fenceCount表示总共的fence数, signaledCount表示已经满足的fence数*/ UINT32 fenceCount; ///< Number of fences it is dependant onUINT32 signaledCount; ///< Number of fences that are signaledCSLFence* phFences[MaxDependentFences]; ///< Fences to wait forUINT64 requestId; ///< Id for requestChiFence* pChiFences[MaxDependentFences]; ///< Chi Fences to wait forUINT32 chiFenceCount; ///< Number of Chi fences it is dependant onUINT32 chiSignaledCount; ///< Number of Chi fences that are signaledPFNCHIFENCECALLBACK pChiFenceCallback; ///< Callback when all Chi fence dependencies satisfiedVOID* pUserData; ///< Client-provided data pointer for Chi callbackBOOL preemptable; ///< Can this dependency be preemptedBOOL isInternalDependency; ///< Is this dependency internal to the base Camx Node?
};Request在Chi中的处理
FetureGraph中包括一个或多个Feature, 根据各个Feature的dependency信息, 调度Request在各个Feature中执行.
FetureGraph中有多个Feature级联的时候, 至少有一个Feature是没有dependency的, 所有Feature的request都执行完, 流程结束.
Chi中的dependency.
在Chi中, 有多个Feature级联的时候, Feature之间有相互依赖关系,
在Feature的StageDescriptor中定义了Feature的dependency, 包括一个metadata和多个buffer.
比如在RTBayer2YUV这个FeatureGraph中, Feature Bayer2YUV依赖于Feature RT的metadata和RDI.
Chi中通过FetureGraph来管理Feature.
-
Feature中虚拟出多个port口. 使用GraphLink, 通过Port口将Feature与Feature, Feature与SrcTarget, Feature与SinkTarget连接起来.
-
Feature与Feature间的Link是InternalLink, Feature与SrcTarget的Link是extSrcLink, Feature与SinkTarget的Link是extSinkLink, 将这些Link保存到全局数据区中.
-
FetureGraph中的GraphLink的状态:
-
初始化的时候将Link的状态设置为NotVisited状态.
-
访问到的Port口对应的Link会被设置为OutputPending状态, 没有访问到的port口对应的Link会被设置为Diabled状态.
-
-
FetureGraph中使用GraphLink和Feature的dependency信息来控制Feature的执行顺序.
-
从SinkLink开始访问, 使用类似于 '深度优先搜索' 的方式, 上行执行Ready的Feature, 直到所有Feature都被执行.
-
一般情况, Feature的一个request分为sequence(-1), sequence(0)两个处理阶段. Feature的processRequest执行两次.
-
-
sequence(-1): 设置Feature的dependency, 保存到DependencyConfigInfo数据区中.
-
sequence(0): 配置Feature的 input和output buffer, 向camx发送request, 等待result返回.
Camx中的DRQ和Chi中的FeatureGraph管理模型的对比
-
DRQ中依赖很多个TAG. FetatureGraph中依赖一个metadatabuffer.
-
DRQ通过ready, deferered队列以及m_pDependencyMap来管理Node.
-
DRQ中的ready和deferered上的node是没有顺序的, 依次执行ready队列上的node.
-
Node间依赖顺序在m_pDependencyMap中定义.
-
-
FetureGraph通过GraphLink和Feature文件中的InputDependency来管理Feature.
-
Linkt通过port找到对应的Feature, 从SinkLink开始访问, 被访问的Feature是有顺序关系的.
-
结合InputDependency信息控制Feature的调度.
-
相较于Qcom以前的Chi架构, Feature2有如下优势:
-
使用FeatureGraph管理Feature, 更好的实现Feature的级联.
-
在基类ChiFeature2Base中实现通用方法, 各个Feature派生实现各自特殊处理, 减少代码冗余.
使用RTBayer2YUV这个FeatureGraph完成单帧拍照
这个FeatureGraph包括RT和Bayer2YUV两个Feature, 有三个SinkTarget.
RT Feture包含一条realtime pipeline, 使用三个output port, 输出RAW, metadata和用于display的YUV数据.
B2Y Feature 包含一条offline pipeline, 用于将RAW转换为YUV, 使用两个output port, 输出metadata和用于拍照的YUV数据.
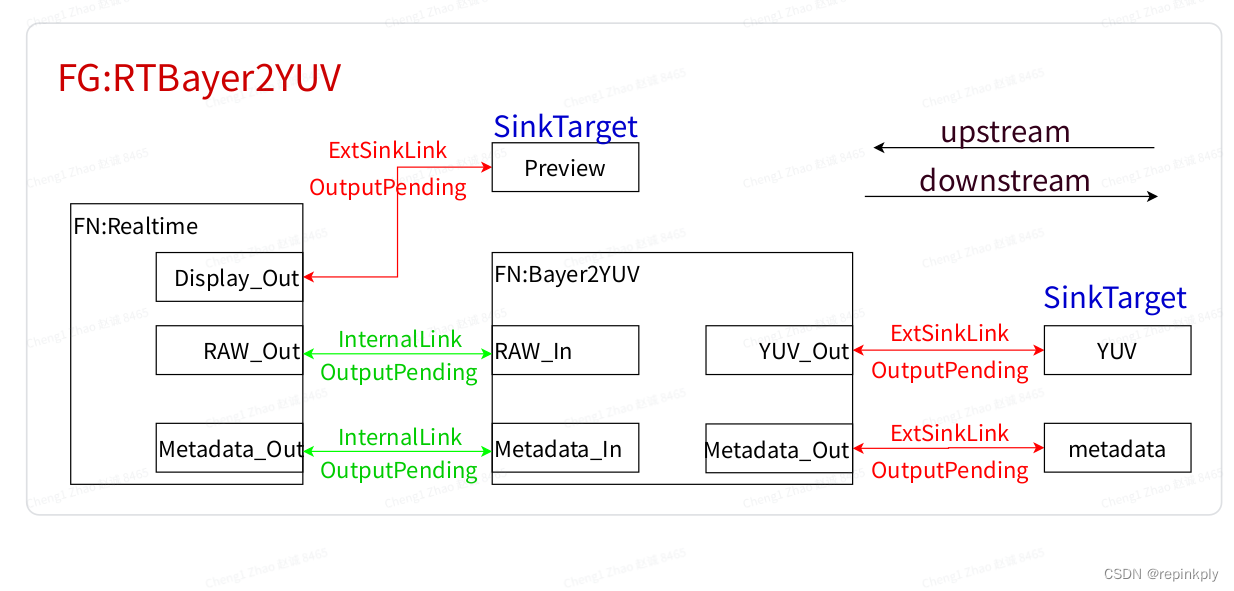
-
WalkAllExtSinkLinks
-
从ExtSinkLink开始访问, 结合Feature的output port, 判断Feature是否处于Ready状态, 具体如下:
-
Featrue B2Y使用两个port, 对应的都是ExtSinkLink, B2Y进入Ready状态, 执行sequence(-1)阶段.
-
Featrue RT使用三个port, 其中Display_Out对应的是ExtSinkLink, 其他两个port对应的Link还没有被访问, RT没有Ready, 不满足执行条件.
-
-
Feature B2Y 执行sequence(-1)阶段
-
B2Y依赖Feature RT 的RDI和Meta, 设置dependency, 执行上行Feature RT, 等待result返回.
-
将Feaure B2Y的request state设置为InputResourcePending 状态.
-
Feature RT 的RDI和Meta的两个port被访问, RT处于Ready状态, 执行Feature RT的sequence(-1)阶段.
-
-
Feature RT 的执行
-
执行sequence(-1), 设置dependency, 因为Feature RT是sensor出数据, 所以Feature RT不需要dependency.
-
执行sequence(0)阶段, 设置output buffer, 向camx发送submit, 等待result返回.
-
将Feaure RT的request state设置为OutputResourcePending状态.
-
-
Feature RT返回result.
-
RT的Meta和RDI 的result返回后, 处于InputResourcePending状态的Feature B2Y被满足
-
执行sequence(0)的阶段, 设置input和output buffer, 向camx发送submit, 等待result返回.
-
将Feaure B2Y的request state设置为OutputResourcePending状态.
-
-
Feature B2Y返回result.
-
Feature2 B2Y会返回metadata和image两个result, 将result返回给APP, 处理过程结束.
-
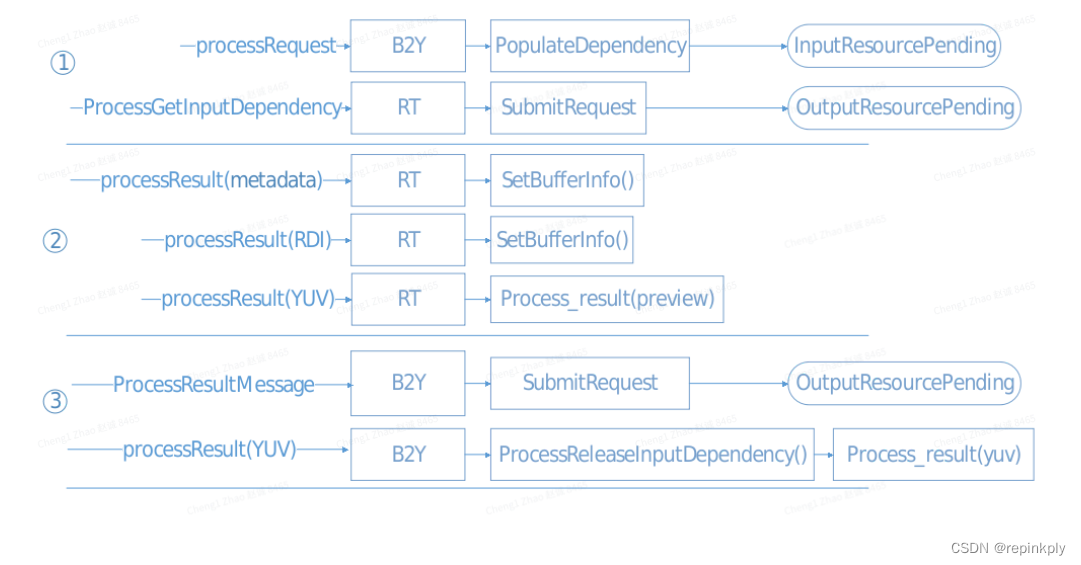
代码执行过程如下:
Feature处理的状态机:
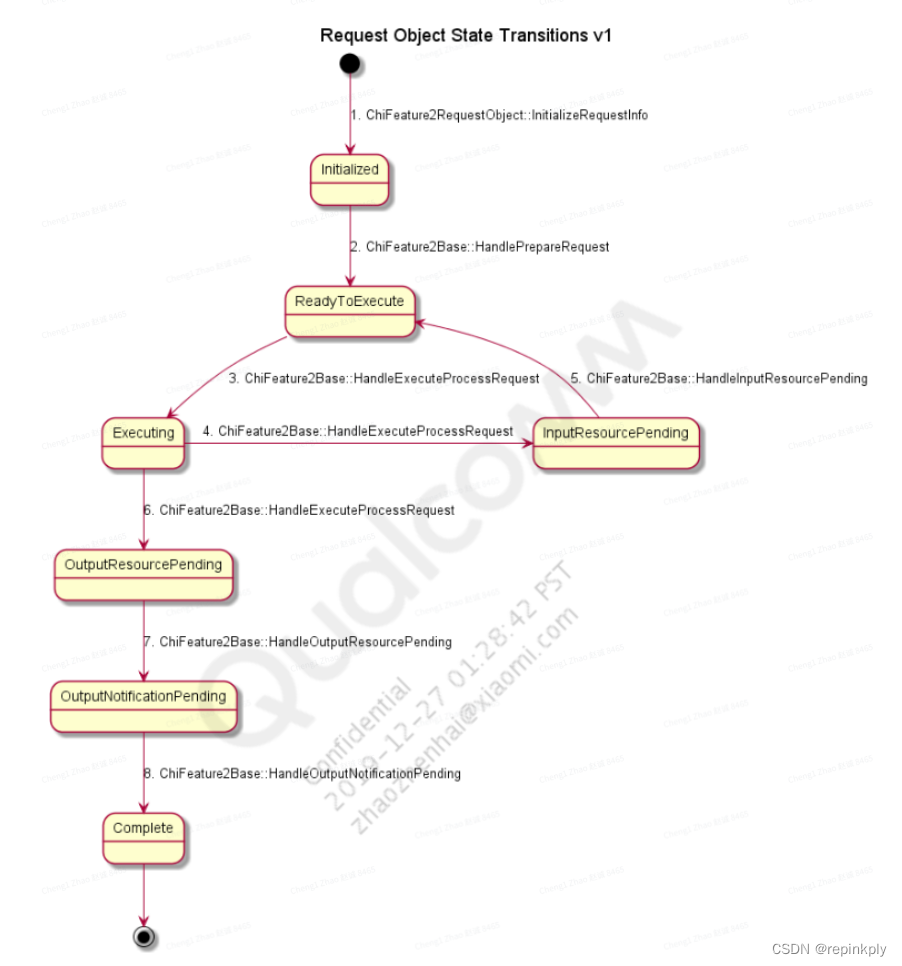
-
Initialized:
-
做一些准备工作, 进入ReadyToExecute状态.
-
-
ReadyToExecute
-
执行Feature的sequence(-1)阶段, 设置dependency, 判断是否有dependency.
-
如果有dependency, 则进入InputResourcePending状态.
-
如果没有dependency, 则进入Executing状态.
-
-
InputResourcePending:
-
等待上行Feature的result返回, 依赖被满足后, 进入Executing状态.
-
-
Executing:
-
执行sequence(0)阶段, 设置input和output buffer, 向camx发送Submit, 进入OutputResourcePending状态, 等待result..
-
-
OutputResourcePending:
-
camx的result返回, 进入OutputNotificationPending状态.
-
-
OutputNotificationPending:
-
送到下游feature处理中.
-
-
Complete:
-
feature处理完毕,释放资源
-
在现有平台中HandleOutputResourcePending没有被调用, 使用ProcessResult代替.
-
RT Feature的状态机:

-
Bay2YUV node的状态机

FeatureGraph中的关键处理
多个Feature级联的时候, 会出现下面需要跨Feature处理(上行和下行)的情况, 需要使用FeatureGraph完成.
-
当前Feature依赖上行Feature的输出, 执行上行Feature的处理 (GetInputDependencyComplete).
-
当前Feature的result返回后, 下行Feature的dependency被满足, 执行下行Feature的处理. (ProcessResultMetadataMessage).
CDKResult ChiFeature2Graph::ProcessFeatureMessage(ChiFeature2RequestObject* pFeatureRequestObj,ChiFeature2Messages* pMessages)
{// Process ChiFeature2 message typeswitch (pMessages->pFeatureMessages->messageType){case ChiFeature2MessageType::GetInputDependencyComplete:pFeatureGraph->ProcessGetInputDependencyCompleteMessage(pFeatureGraphNode);break;case ChiFeature2MessageType::ResultNotification:case ChiFeature2MessageType::MetadataNotification:result = pFeatureGraph->ProcessResultMetadataMessage(pFeatureGraphNode,rDownstreamFeatureRequestObjMap,pMessages);break;case ChiFeature2MessageType::GetInputDependency:pFeatureGraph->ProcessGetInputDependencyMessage(pFeatureGraphNode, pMessages);break; }
}上行获取Feature的dependency
循环扫描当前Feature的input Port, 找到对应的Link, 找到上行Feature, 调用WalkBackFromLink, 执行上行Feature.
CDKResult ChiFeature2Graph::ProcessGetInputDependencyCompleteMessage(ChiFeature2GraphNode* pGraphNode)
{for (UINT32 portIdIndex = 0; portIdIndex < pGraphNode->portToInputLinkIndexMap.size(); ++portIdIndex){ChiFeature2GlobalPortInstanceId* pInputPortId = &(pGraphNode->portToInputLinkIndexMap[portIdIndex].portId);// go over all the links for this input portstd::vector<ChiFeature2GraphLinkData*> inputLinkDataList = MapInputPortIdToInputLinkData(pInputPortId, pGraphNode);for (UINT32 inputLinkDataIndex = 0; inputLinkDataIndex < inputLinkDataList.size(); ++inputLinkDataIndex){ChiFeature2GraphLinkData* pInputLinkData = inputLinkDataList[inputLinkDataIndex];{if (FALSE == pInputLinkData->linkRequestTable.empty()){// We have input dependencies for this link, so move it to OutputPendingpInputLinkData->linkState = ChiFeature2GraphLinkState::OutputPending;}else{// We do not have input dependencies for this link, so move it to DisabledpInputLinkData->linkState = ChiFeature2GraphLinkState::Disabled;}// Walk back on the input link, taking the appropriate action based on the state of all output// portsWalkBackFromLink(m_pUsecaseRequestObj, pInputLinkData);}}}
}Camx中result返回后的处理
当前Feature的Request在Camx中处理完, 返回result. 和Camx中的CSLFenceCallback中的处理类似:
-
如果是Non Sink Feature, 调用SetBufferInfo, 下行Feture的dependency被满足后, 执行下行Feature的ProcessRequest.
-
如果当前Feature是Sink Feature, 将结果返回给Usecase, 然后返回App.
CDKResult ChiFeature2Graph::ProcessResultMetadataMessage(ChiFeature2GraphNode* pGraphNode,std::vector<ChiFeature2RequestObjectMap>& rDownstreamFeatureRequestObjMap,ChiFeature2Messages* pMessages)
{ // Only send the feature message through to the wrapper if there is a buffer error or no downstream nodeif (ChiFeature2GraphLinkType::ExternalSink == pOutputLinkData->linkType){if (pMessages->pFeatureMessages->messageType == ChiFeature2MessageType::ResultNotification){if (ChiFeature2PortType::ImageBuffer == outputPortInstanceId.portId.portType){NotifyExtSinkResult(pGraphNode, m_pUsecaseRequestObj, outputPortInstanceId, pBufferMetadataInfo);}}}else{ if (pMessages->pFeatureMessages->messageType == ChiFeature2MessageType::ResultNotification){ pDownstreamFeatureRequestObj->SetBufferInfo(ChiFeature2RequestObjectOpsType::InputDependency,&sinkPortId.portId,pBufferMetadataInfo->hBuffer,pBufferMetadataInfo->key,FALSE,pLinkRequestMap->batchIndex,pLinkRequestMap->dependencyIndex,isExclusive);ChiFeature2Base* pFeatureBaseObj = pOutputLinkData->pSinkGraphNode->pFeatureBaseObj;TriggerProcessRequest(pFeatureBaseObj, pDownstreamFeatureRequestObj, ChiFeature2RequestCommands::InputResource);}}
}对上行Feature分发多个Request.
比如8帧的MFSR拍照场景下, 对Feature MFSR下发一个request, 但需要对上行Feature下发8个request.,
代码如下,核心是通过三个for循环, 计算requestIndex的过程, 确定上行Feature的Request个数.
requestIndex 0表示有一个request, requestIndex 1 表示有俩个request, 以此类推.
CDKResult ChiFeature2Graph::ProcessGetInputDependencyMessage(ChiFeature2GraphNode* pGraphNode,ChiFeature2Messages* pMessages)
{for (UINT8 depIndex = 0; depIndex < numDependencies; ++depIndex){// Iterate through all input ports in the messagefor (UINT inputPortIndex = 0; inputPortIndex < numInputPorts; inputPortIndex++){for (UINT32 inputLinkDataIndex = 0; inputLinkDataIndex < inputLinkDataList.size(); ++inputLinkDataIndex){// Add the downstream FRO to the upstream node's list if it is not already in itfor (UINT featureRequestObjIndex = 0;featureRequestObjIndex < pSrcGraphNode->downstreamFeatureRequestObjMap.size();++featureRequestObjIndex){if (pDownstreamFeatureRequestObj ==pSrcGraphNode->downstreamFeatureRequestObjMap[featureRequestObjIndex].pFeatureRequestObj){mapIndex = featureRequestObjIndex;break;}}auto& rBatchRequestMap = pSrcGraphNode->downstreamFeatureRequestObjMap[mapIndex].batchRequestIndexMap;if ((batchIndex + 1) >= rBatchRequestMap.size()){if (TRUE == rBatchRequestMap.empty()){// For every link, requestIndex starts from 0rBatchRequestMap.push_back(0);}// Next batch requestIndex starts from sum of current offset and current numDependenciesrBatchRequestMap.push_back(rBatchRequestMap[batchIndex] + numDependencies);}requestIndex = rBatchRequestMap[batchIndex] + depIndex;// Store the request mapping in the link's tableChiFeature2GraphLinkRequestMap linkRequestMap = {};linkRequestMap.requestIndex = requestIndex;linkRequestMap.batchIndex = batchIndex;linkRequestMap.dependencyIndex = depIndex;linkRequestMap.inputDependencyReleased = FALSE;linkRequestMap.position = pInputLinkData->linkRequestTable.size();pInputLinkData->linkRequestTable.push_back(linkRequestMap);pInputLinkData->numDependenciesPerBatchList[batchIndex] = numDependencies;ProcessInputDepsForUpstreamFeatureRequest(m_pUsecaseRequestObj, pInputLinkData, requestIndex);}}}
}小结
个人能力有限, 只是大概的解释了一下 QCOM Camera HAL关键模块的流程机制, 内容难免有不足之处,欢迎交流学习。
这篇关于Qcom camera hal简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








