本文主要是介绍NebulaGraph基础(默认看了入门篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
感谢阅读
- 官方链接
- 运算符
- 比较运算符
- 布尔符
- 管道符
- 集合运算符
- UNION、UNION DISTINCT、UNION ALL
- 官方示例代码(并集)
- INTERSECT
- 官方示例代码(交集)
- MINUS
- 字符串运算符
- 官方代码(字符串)
- 列表运算符
- 算术运算符
- NebulaGraph的额外函数
- 谓词函数
- 谓词函数官方代码
- geo 函数
- geo函数官方示例代码
- 查询语句
- 核心语句
- FETCH
- 获取点的属性值
- 官方代码(获取多个点的属性值)
- 基于多个 Tag 获取点的属性值(官方代码)
- 获取边的属性值
- 基于 rank 获取属性值(官方代码)
- MATCH
- 匹配路径(官方代码)
- LOOKUP
- 统计点或边(官方代码)
- GO
- 查询起始点的直接邻居点(官方代码)
- 查询指定跳数内的点(官方代码)
- show系列
- 显示当前的字符集
- 显示建库(官方称图空间,实际上类似database)语句
- 显示集群信息
- 官方代码(show hosts)
- SHOW ROLES
- 官方查询角色代码
- 展示图空间
- 显示用户信息。
- FIND PATH
- 官方代码(查找各种路径)
- GET SUBGRAPH
- 图计算
官方链接
点我跳转
本文仅对官方文档和论文进行排序和总结并加上个人观点,如有需要可以看官方文档
运算符
比较运算符

补充说明
字符串比较时,会区分大小写。不同类型的值不相等。
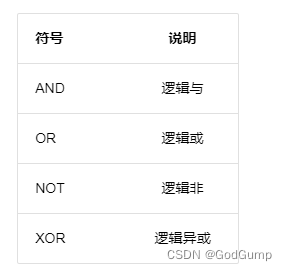
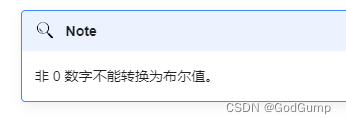
布尔符
管道符
nGQL 支持使用管道符(|)将多个查询组合起来。
openCypher 兼容性¶
管道符仅适用于原生 nGQL。
语法¶
nGQL 和 SQL 之间的一个主要区别是子查询的组成方式。
在 SQL 中,子查询是嵌套在查询语句中的。
在 nGQL 中,子查询是通过类似 shell 中的管道符(|)实现的。
集合运算符
合并多个请求时,可以使用集合运算符,包括UNION、UNION ALL、INTERSECT和MINUS。
所有集合运算符的优先级相同,如果一个 nGQL 语句中有多个集合运算符,NebulaGraph 会从左到右进行计算,除非用括号指定顺序。
集合运算符前后的查询语句中定义的变量名及顺序必需保持一致,例如RETURN a,b,c UNION RETURN a,b,c中的a,b,c的名称及顺序需要保持一致。
UNION、UNION DISTINCT、UNION ALL
<left> UNION [DISTINCT | ALL] <right> [ UNION [DISTINCT | ALL] <right> ...]运算符UNION DISTINCT(或使用缩写UNION)返回两个集合 A 和 B 的并集,不包含重复的元素。
运算符UNION ALL返回两个集合 A 和 B 的并集,包含重复的元素。
left和right必须有相同数量的列和数据类型。
官方示例代码(并集)
# 返回两个查询结果的并集,不包含重复的元素。
nebula> GO FROM "player102" OVER follow YIELD dst(edge) \UNION \GO FROM "player100" OVER follow YIELD dst(edge);
+-------------+
| dst(EDGE) |
+-------------+
| "player100" |
| "player101" |
| "player125" |
+-------------+# 查询 Tag 为 player 的点,根据名称排序后获取前 3 条数据,并与数组合并返回,不包含重复的元素。
nebula> MATCH (v:player) \WITH v.player.name AS n \RETURN n ORDER BY n LIMIT 3 \UNION \UNWIND ["Tony Parker", "Ben Simmons"] AS n \RETURN n;
+---------------------+
| n |
+---------------------+
| "Amar'e Stoudemire" |
| "Aron Baynes" |
| "Ben Simmons" |
| "Tony Parker" |
+---------------------+# 返回两个查询结果的并集,包含重复的元素。
nebula> GO FROM "player102" OVER follow YIELD dst(edge) \UNION ALL \GO FROM "player100" OVER follow YIELD dst(edge);
+-------------+
| dst(EDGE) |
+-------------+
| "player100" |
| "player101" |
| "player101" |
| "player125" |
+-------------+# 查询 Tag 为 player 的点,根据名称排序后获取前 3 条数据,并与数组合并返回,包含重复的元素。
nebula> MATCH (v:player) \WITH v.player.name AS n \RETURN n ORDER BY n LIMIT 3 \UNION ALL \UNWIND ["Tony Parker", "Ben Simmons"] AS n \RETURN n;
+---------------------+
| n |
+---------------------+
| "Amar'e Stoudemire" |
| "Aron Baynes" |
| "Ben Simmons" |
| "Tony Parker" |
| "Ben Simmons" |
+---------------------+# UNION 也可以和 YIELD 语句一起使用,去重时会检查每一行的所有列,每列都相同时才会去重。
nebula> GO FROM "player102" OVER follow \YIELD dst(edge) AS id, properties(edge).degree AS Degree, properties($$).age AS Age \UNION /* DISTINCT */ \GO FROM "player100" OVER follow \YIELD dst(edge) AS id, properties(edge).degree AS Degree, properties($$).age AS Age;
+-------------+--------+-----+
| id | Degree | Age |
+-------------+--------+-----+
| "player100" | 75 | 42 |
| "player101" | 75 | 36 |
| "player101" | 95 | 36 |
| "player125" | 95 | 41 |
+-------------+--------+-----+INTERSECT
<left> INTERSECT <right>运算符INTERSECT返回两个集合 A 和 B 的交集。
left和right必须有相同数量的列和数据类型。
官方示例代码(交集)
# 返回两个查询结果的交集。
nebula> GO FROM "player102" OVER follow \YIELD dst(edge) AS id, properties(edge).degree AS Degree, properties($$).age AS Age \INTERSECT \GO FROM "player100" OVER follow \YIELD dst(edge) AS id, properties(edge).degree AS Degree, properties($$).age AS Age;
+----+--------+-----+
| id | Degree | Age |
+----+--------+-----+
+----+--------+-----+# 返回 player102 的邻居和边数据与 player100 的邻居和边数据之间的交集。
nebula> MATCH (v:player)-[e:follow]->(v2) \WHERE id(v) == "player102" \RETURN id(v2) As id, e.degree As Degree, v2.player.age AS Age \INTERSECT \MATCH (v:player)-[e:follow]->(v2) \WHERE id(v) == "player100" \RETURN id(v2) As id, e.degree As Degree, v2.player.age AS Age;
+----+--------+-----+
| id | Degree | Age |
+----+--------+-----+
+----+--------+-----+# 返回 [1,2] 与 [1,2,3,4] 的交集。
nebula> UNWIND [1,2] AS a RETURN a \INTERSECT \UNWIND [1,2,3,4] AS a \RETURN a;
+---+
| a |
+---+
| 1 |
| 2 |
+---+MINUS
<left> MINUS <right>运算符MINUS返回两个集合 A 和 B 的差异,即A-B。请注意left和right的顺序,A-B表示在集合 A 中,但是不在集合 B 中的元素。
字符串运算符
NebulaGraph 支持使用字符串运算符进行连接、搜索、匹配运算。支持的运算符如下。
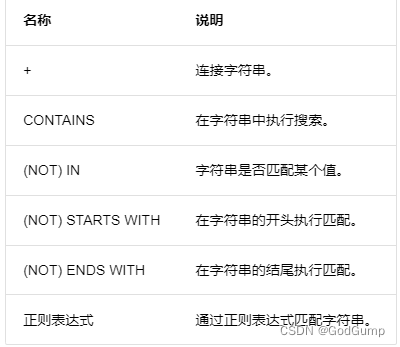
所有搜索或匹配都区分大小写。
官方代码(字符串)
# 返回是否以某个字符串结尾。
nebula> RETURN 'apple' ENDS WITH 'app', 'apple' ENDS WITH 'e', 'apple' ENDS WITH 'E', 'apple' ENDS WITH 'b';
+---------------------------+-------------------------+-------------------------+-------------------------+
| ("apple" ENDS WITH "app") | ("apple" ENDS WITH "e") | ("apple" ENDS WITH "E") | ("apple" ENDS WITH "b") |
+---------------------------+-------------------------+-------------------------+-------------------------+
| false | true | false | false |
+---------------------------+-------------------------+-------------------------+-------------------------+列表运算符
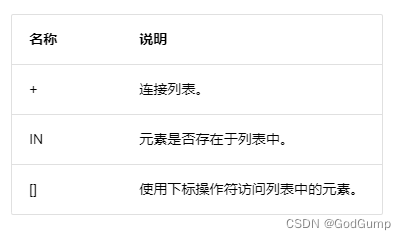
算术运算符

NebulaGraph的额外函数
谓词函数
谓词函数只返回true或false,通常用于WHERE子句中。
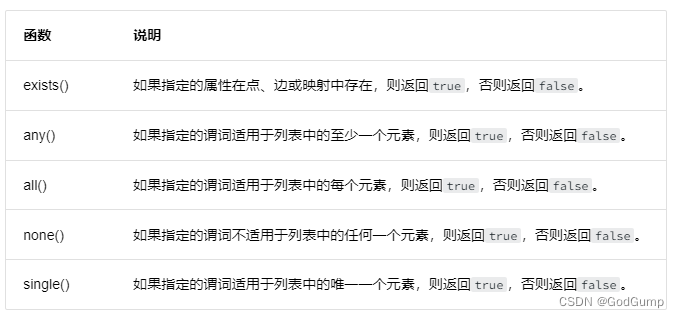
<predicate>(<variable> IN <list> WHERE <condition>)谓词函数官方代码
nebula> RETURN any(n IN [1, 2, 3, 4, 5, NULL] \WHERE n > 2) AS r;
+------+
| r |
+------+
| true |
+------+nebula> RETURN single(n IN range(1, 5) \WHERE n == 3) AS r;
+------+
| r |
+------+
| true |
+------+nebula> RETURN none(n IN range(1, 3) \WHERE n == 0) AS r;
+------+
| r |
+------+
| true |
+------+nebula> WITH [1, 2, 3, 4, 5, NULL] AS a \RETURN any(n IN a WHERE n > 2);
+-------------------------+
| any(n IN a WHERE (n>2)) |
+-------------------------+
| true |
+-------------------------+nebula> MATCH p = (n:player{name:"LeBron James"})<-[:follow]-(m) \RETURN nodes(p)[0].player.name AS n1, nodes(p)[1].player.name AS n2, \all(n IN nodes(p) WHERE n.player.name NOT STARTS WITH "D") AS b;
+----------------+-------------------+-------+
| n1 | n2 | b |
+----------------+-------------------+-------+
| "LeBron James" | "Danny Green" | false |
| "LeBron James" | "Dejounte Murray" | false |
| "LeBron James" | "Chris Paul" | true |
| "LeBron James" | "Kyrie Irving" | true |
| "LeBron James" | "Carmelo Anthony" | true |
| "LeBron James" | "Dwyane Wade" | false |
+----------------+-------------------+-------+nebula> MATCH p = (n:player{name:"LeBron James"})-[:follow]->(m) \RETURN single(n IN nodes(p) WHERE n.player.age > 40) AS b;
+------+
| b |
+------+
| true |
+------+nebula> MATCH (n:player) \RETURN exists(n.player.id), n IS NOT NULL;
+---------------------+---------------+
| exists(n.player.id) | n IS NOT NULL |
+---------------------+---------------+
| false | true |
...nebula> MATCH (n:player) \WHERE exists(n['name']) \RETURN n;
+---------------------------------------------------------------+
| n |
+---------------------------------------------------------------+
| ("player105" :player{age: 31, name: "Danny Green"}) |
| ("player109" :player{age: 34, name: "Tiago Splitter"}) |
| ("player111" :player{age: 38, name: "David West"}) |
...geo 函数
geo 函数用于生成地理空间(GEOGRAPHY)数据类型的值或对其执行操作。
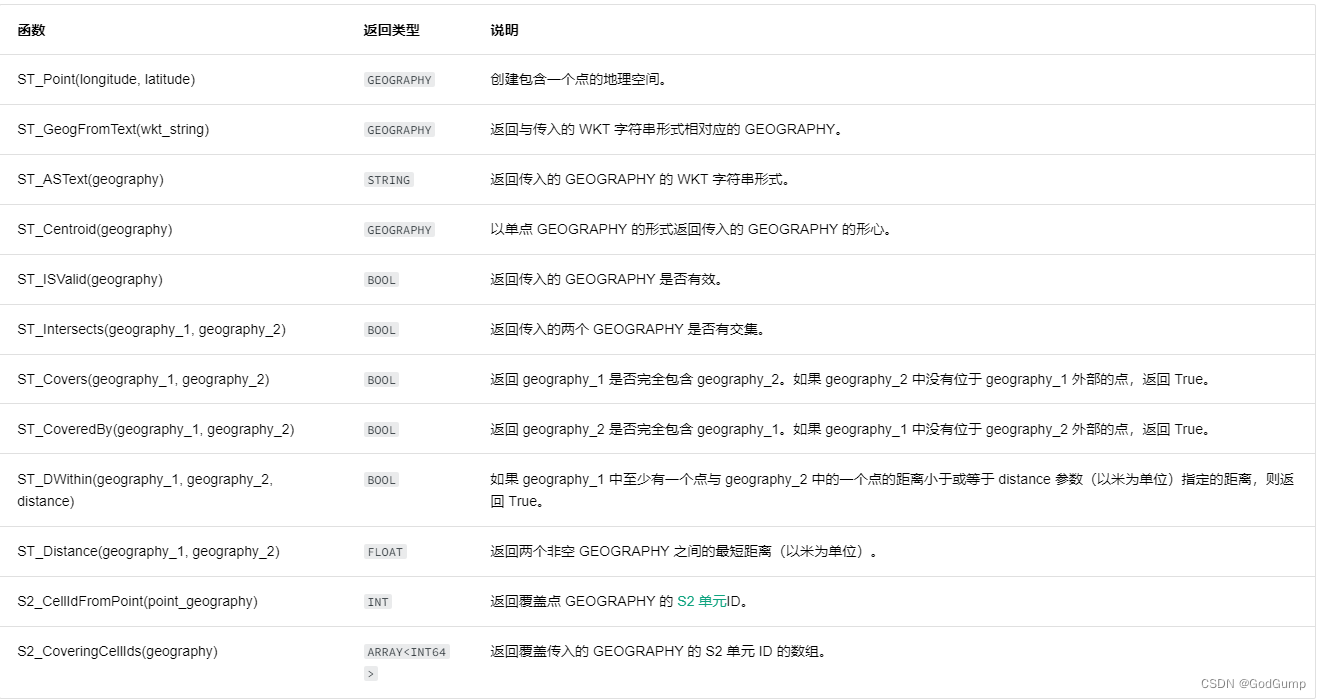
geo函数官方示例代码
nebula> RETURN ST_ASText(ST_Point(1,1));
+--------------------------+
| ST_ASText(ST_Point(1,1)) |
+--------------------------+
| "POINT(1 1)" |
+--------------------------+nebula> RETURN ST_ASText(ST_GeogFromText("POINT(3 8)"));
+------------------------------------------+
| ST_ASText(ST_GeogFromText("POINT(3 8)")) |
+------------------------------------------+
| "POINT(3 8)" |
+------------------------------------------+nebula> RETURN ST_ASTEXT(ST_Centroid(ST_GeogFromText("LineString(0 1,1 0)")));
+----------------------------------------------------------------+
| ST_ASTEXT(ST_Centroid(ST_GeogFromText("LineString(0 1,1 0)"))) |
+----------------------------------------------------------------+
| "POINT(0.5000380800773782 0.5000190382261059)" |
+----------------------------------------------------------------+nebula> RETURN ST_ISValid(ST_GeogFromText("POINT(3 8)"));
+-------------------------------------------+
| ST_ISValid(ST_GeogFromText("POINT(3 8)")) |
+-------------------------------------------+
| true |
+-------------------------------------------+nebula> RETURN ST_Intersects(ST_GeogFromText("LineString(0 1,1 0)"),ST_GeogFromText("LineString(0 0,1 1)"));
+----------------------------------------------------------------------------------------------+
| ST_Intersects(ST_GeogFromText("LineString(0 1,1 0)"),ST_GeogFromText("LineString(0 0,1 1)")) |
+----------------------------------------------------------------------------------------------+
| true |
+----------------------------------------------------------------------------------------------+nebula> RETURN ST_Covers(ST_GeogFromText("POLYGON((0 0,10 0,10 10,0 10,0 0))"),ST_Point(1,2));
+--------------------------------------------------------------------------------+
| ST_Covers(ST_GeogFromText("POLYGON((0 0,10 0,10 10,0 10,0 0))"),ST_Point(1,2)) |
+--------------------------------------------------------------------------------+
| true |
+--------------------------------------------------------------------------------+nebula> RETURN ST_CoveredBy(ST_Point(1,2),ST_GeogFromText("POLYGON((0 0,10 0,10 10,0 10,0 0))"));
+-----------------------------------------------------------------------------------+
| ST_CoveredBy(ST_Point(1,2),ST_GeogFromText("POLYGON((0 0,10 0,10 10,0 10,0 0))")) |
+-----------------------------------------------------------------------------------+
| true |
+-----------------------------------------------------------------------------------+nebula> RETURN ST_dwithin(ST_GeogFromText("Point(0 0)"),ST_GeogFromText("Point(10 10)"),20000000000.0);
+---------------------------------------------------------------------------------------+
| ST_dwithin(ST_GeogFromText("Point(0 0)"),ST_GeogFromText("Point(10 10)"),20000000000) |
+---------------------------------------------------------------------------------------+
| true |
+---------------------------------------------------------------------------------------+nebula> RETURN ST_Distance(ST_GeogFromText("Point(0 0)"),ST_GeogFromText("Point(10 10)"));
+----------------------------------------------------------------------------+
| ST_Distance(ST_GeogFromText("Point(0 0)"),ST_GeogFromText("Point(10 10)")) |
+----------------------------------------------------------------------------+
| 1.5685230187677438e+06 |
+----------------------------------------------------------------------------+nebula> RETURN S2_CellIdFromPoint(ST_GeogFromText("Point(1 1)"));
+---------------------------------------------------+
| S2_CellIdFromPoint(ST_GeogFromText("Point(1 1)")) |
+---------------------------------------------------+
| 1153277837650709461 |
+---------------------------------------------------+nebula> RETURN S2_CoveringCellIds(ST_GeogFromText("POLYGON((0 1, 1 2, 2 3, 0 1))"));
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| S2_CoveringCellIds(ST_GeogFromText("POLYGON((0 1, 1 2, 2 3, 0 1))")) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| [1152391494368201343, 1153466862374223872, 1153554823304445952, 1153836298281156608, 1153959443583467520, 1154240918560178176, 1160503736791990272, 1160591697722212352] |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+查询语句
核心语句
FETCH PROP ON
LOOKUP ON
GO
MATCH
FIND PATH
GET SUBGRAPH
SHOW
FETCH
FETCH可以获取指定点或边的属性值。
获取点的属性值
FETCH PROP ON {<tag_name>[, tag_name ...] | *}
<vid> [, vid ...]
YIELD [DISTINCT] <return_list> [AS <alias>];官方代码(获取多个点的属性值)
# 获取 Tag 为 player,且 ID 为 player101,player102,player103 三个点数据的属性值。
nebula> FETCH PROP ON player "player101", "player102", "player103" YIELD properties(vertex);
+--------------------------------------+
| properties(VERTEX) |
+--------------------------------------+
| {age: 33, name: "LaMarcus Aldridge"} |
| {age: 36, name: "Tony Parker"} |
| {age: 32, name: "Rudy Gay"} |
+--------------------------------------+基于多个 Tag 获取点的属性值(官方代码)
# 创建新 Tag t1。
nebula> CREATE TAG IF NOT EXISTS t1(a string, b int);# 为点 player100 添加 Tag t1。
nebula> INSERT VERTEX t1(a, b) VALUES "player100":("Hello", 100);# 基于 Tag player 和 t1 获取点 player100 上的属性值。
nebula> FETCH PROP ON player, t1 "player100" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
+----------------------------------------------------------------------------+获取边的属性值
FETCH PROP ON <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid> ...]
YIELD <output>;
基于 rank 获取属性值(官方代码)
如果有多条边,起始点、目的点和 Edge type 都相同,可以通过指定 rank 获取正确的边属性值。
# 插入不同属性值、不同 rank 的边。
nebula> insert edge serve(start_year,end_year) \values "player100"->"team204"@1:(1998, 2017);nebula> insert edge serve(start_year,end_year) \values "player100"->"team204"@2:(1990, 2018);# 默认返回 rank 为 0 的边。
nebula> FETCH PROP ON serve "player100" -> "team204" YIELD edge AS e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player100"->"team204" @0 {end_year: 2016, start_year: 1997}] |
+-----------------------------------------------------------------------+# 要获取 rank 不为 0 的边,请在 FETCH 语句中设置 rank。
nebula> FETCH PROP ON serve "player100" -> "team204"@1 YIELD edge AS e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player100"->"team204" @1 {end_year: 2017, start_year: 1998}] |
+-----------------------------------------------------------------------+MATCH
MATCH语句提供基于模式(Pattern)匹配的搜索功能,其通过定义一个或多个模式,允许在 NebulaGraph 中查找与模式匹配的数据。在检索到匹配的数据后,用户可以使用 RETURN 子句将其作为结果返回。
MATCH语句的语法相较于其他查询语句(如GO和LOOKUP)更具灵活性。在进行查询时,MATCH语句使用的路径类型是trail,这意味着点可以重复出现,但边不能重复。
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];pattern:MATCH语句支持匹配一个或多个模式,多个模式之间用英文逗号(,)分隔。例如(a)-[]->(b),©-[]->(d)。。
clause_1:支持WHERE、WITH、UNWIND、OPTIONAL MATCH子句,也可以使用MATCH作为子句。
output:定义需要返回输出结果的列表名称。可以使用AS设置列表的别名。
clause_2:支持ORDER BY、LIMIT子句。
匹配路径(官方代码)
连接起来的点和边构成了路径。用户可以使用自定义变量命名路径。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-->(v2) \RETURN p;
+--------------------------------------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:serve@0 {end_year: 2016, start_year: 1997}]->("team204" :team{name: "Spurs"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})> |
+--------------------------------------------------------------------------------------------------------------------------------------+LOOKUP
LOOKUP根据索引遍历数据。用户可以使用LOOKUP实现如下功能:
根据WHERE子句搜索特定数据。
通过 Tag 列出点:检索指定 Tag 的所有点 ID。
通过 Edge type 列出边:检索指定 Edge type 的所有边的起始点、目的点和 rank。
统计包含指定 Tag 的点或属于指定 Edge type 的边的数量。
LOOKUP ON {<vertex_tag> | <edge_type>}
[WHERE <expression> [AND <expression> ...]]
YIELD [DISTINCT] <return_list> [AS <alias>]
[<clause>];<return_list><prop_name> [AS <col_alias>] [, <prop_name> [AS <prop_alias>] ...];请确保LOOKUP语句有至少一个索引可用。
如果已经存在相关的点、边或属性,必须在新创建索引后重建索引,才能使其生效。
参数含义
WHERE <expression>:指定遍历的过滤条件,还可以结合布尔运算符 AND 和 OR 一起使用。
YIELD:定义需要返回的输出。详情请参见 YIELD。
DISTINCT:聚合输出结果,返回去重后的结果集。
AS:设置别名。
clause:支持ORDER BY、LIMIT子句。
统计点或边(官方代码)
统计 Tag 为player的点和 Edge type 为follow的边。
# 统计 Tag 为 player 的点总数。
nebula> LOOKUP ON player YIELD id(vertex)|\YIELD COUNT(*) AS Player_Number;
+---------------+
| Player_Number |
+---------------+
| 51 |
+---------------+# 统计 Edge type 为 follow 的边总数。
nebula> LOOKUP ON follow YIELD edge AS e| \YIELD COUNT(*) AS Follow_Number;
+---------------+
| Follow_Number |
+---------------+
| 81 |
+---------------+使用 SHOW STATS命令也可以统计点和边。
GO
GO语句是 NebulaGraph 图数据库中用于从给定起始点开始遍历图的语句。GO语句采用的路径类型是walk,即遍历时点和边都可以重复。本文的GO操作仅适用于原生 nGQL。
GO [[<M> TO] <N> {STEP|STEPS} ] FROM <vertex_list>
OVER <edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
YIELD [DISTINCT] <return_list>
[{ SAMPLE <sample_list> | <limit_by_list_clause> }]
[| GROUP BY {<col_name> | expression> | <position>} YIELD <col_name>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset>,] <number_rows>];<vertex_list> ::=<vid> [, <vid> ...]<edge_type_list> ::=<edge_type> [, <edge_type> ...]| *<return_list> ::=<col_name> [AS <col_alias>] [, <col_name> [AS <col_alias>] ...]参数含义如下
<N> {STEP|STEPS}:指定跳数。如果没有指定跳数,默认值N为1。如果N为0,NebulaGraph 不会检索任何边。
M TO N {STEP|STEPS}:遍历M~N跳的边。如果M为0,输出结果和M为1相同,即GO 0 TO 2和GO 1 TO 2是相同的。
<vertex_list>:用逗号分隔的点 ID 列表。
<edge_type_list>:遍历的 Edge type 列表。
REVERSELY | BIDIRECT:默认情况下检索的是<vertex_list>的出边(正向),REVERSELY表示反向,即检索入边;BIDIRECT 为双向,即检索正向和反向。可通过YIELD返回<edge_type>._type字段判断方向,其正数为正向,负数为反向。
WHERE <conditions>:指定遍历的过滤条件。用户可以在起始点、目的点和边使用WHERE子句,还可以结合AND、OR、NOT、XOR一起使用
YIELD [DISTINCT] <return_list>:定义需要返回的输出。<return_list>建议使用 Schema 相关函数指定返回信息,当前支持src(edge)、dst(edge)、type(edge)等,暂不支持嵌套函数。。
SAMPLE <sample_list>:用于在结果集中取样。
<limit_by_list_clause>:用于在遍历过程中逐步限制输出数量。
GROUP BY:根据指定属性的值将输出分组。分组后需要再次使用YIELD定义需要返回的输出。
ORDER BY:指定输出结果的排序规则。
LIMIT [<offset>,] <number_rows>]:限制输出结果的行数。查询起始点的直接邻居点(官方代码)
场景:查询某个点的直接相邻点,例如查询一个人所属队伍。
# 返回 player102 所属队伍。
nebula> GO FROM "player102" OVER serve YIELD dst(edge);
+-----------+
| dst(EDGE) |
+-----------+
| "team203" |
| "team204" |
+-----------+查询指定跳数内的点(官方代码)
场景:查询一个点在指定跳数内的所有点,例如查询一个人两跳内的朋友。
# 返回距离 player102 两跳的朋友。
nebula> GO 2 STEPS FROM "player102" OVER follow YIELD dst(edge);
+-------------+
| dst(EDGE) |
+-------------+
| "player101" |
| "player125" |
| "player100" |
| "player102" |
| "player125" |
+-------------+# 查询 player100 1~2 跳内的朋友。
nebula> GO 1 TO 2 STEPS FROM "player100" OVER follow \YIELD dst(edge) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player125" |
...# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
nebula> MATCH (v) -[e:follow*1..2]->(v2) \WHERE id(v) == "player100" \RETURN id(v2) AS destination;
+-------------+
| destination |
+-------------+
| "player100" |
| "player102" |
...show系列
这个系列从安装就在用,由于很多只列举常用的
显示当前的字符集
为啥这个常用,因为有的编码为gbk有的UTF甚至还有公司自定义编码,这是为了不乱码(目前可用的字符集为utf8和utf8mb4。默认字符集为utf8。 NebulaGraph 扩展uft8支持四字节字符,因此utf8和utf8mb4是等价的。但是,为了长远看还是检验一下)
SHOW CHARSET;显示建库(官方称图空间,实际上类似database)语句
SHOW CREATE SPACE <space_name>;显示集群信息
SHOW HOSTS语句可以显示集群信息,包括端口、状态、leader、分片、版本等信息,或者指定显示 Graph、Storage、Meta 服务主机信息。
SHOW HOSTS [GRAPH | STORAGE | META];官方代码(show hosts)
nebula> SHOW HOSTS;
+-------------+-------+----------+--------------+----------------------------------+------------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+-------------+-------+----------+--------------+----------------------------------+------------------------------+---------+
| "storaged0" | 9779 | "ONLINE" | 8 | "docs:5, basketballplayer:3" | "docs:5, basketballplayer:3" | "3.6.0" |
| "storaged1" | 9779 | "ONLINE" | 9 | "basketballplayer:4, docs:5" | "docs:5, basketballplayer:4" | "3.6.0" |
| "storaged2" | 9779 | "ONLINE" | 8 | "basketballplayer:3, docs:5" | "docs:5, basketballplayer:3" | "3.6.0" |
+-------------+-------+----------+--------------+----------------------------------+------------------------------+---------+nebula> SHOW HOSTS GRAPH;
+-----------+------+----------+---------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+-----------+------+----------+---------+--------------+---------+
| "graphd" | 9669 | "ONLINE" | "GRAPH" | "3ba41bd" | "3.6.0" |
| "graphd1" | 9669 | "ONLINE" | "GRAPH" | "3ba41bd" | "3.6.0" |
| "graphd2" | 9669 | "ONLINE" | "GRAPH" | "3ba41bd" | "3.6.0" |
+-----------+------+----------+---------+--------------+---------+nebula> SHOW HOSTS STORAGE;
+-------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+-------------+------+----------+-----------+--------------+---------+
| "storaged0" | 9779 | "ONLINE" | "STORAGE" | "3ba41bd" | "3.6.0" |
| "storaged1" | 9779 | "ONLINE" | "STORAGE" | "3ba41bd" | "3.6.0" |
| "storaged2" | 9779 | "ONLINE" | "STORAGE" | "3ba41bd" | "3.6.0" |
+-------------+------+----------+-----------+--------------+---------+nebula> SHOW HOSTS META;
+----------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+----------+------+----------+--------+--------------+---------+
| "metad2" | 9559 | "ONLINE" | "META" | "3ba41bd" | "3.6.0" |
| "metad0" | 9559 | "ONLINE" | "META" | "3ba41bd" | "3.6.0" |
| "metad1" | 9559 | "ONLINE" | "META" | "3ba41bd" | "3.6.0" |
+----------+------+----------+--------+--------------+---------+SHOW ROLES
SHOW ROLES语句显示分配给用户的角色信息。
根据登录的用户角色,返回的结果也有所不同:
如果登录的用户角色是GOD,或者有权访问该图空间的ADMIN,则返回该图空间内除GOD之外的所有用户角色信息。
如果登录的用户角色是有权访问该图空间DBA、USER或GUEST,则返回自身的角色信息。
如果登录的用户角色没有权限访问该图空间,则返回权限错误。
SHOW ROLES IN <space_name>;官方查询角色代码
nebula> SHOW ROLES in basketballplayer;
+---------+-----------+
| Account | Role Type |
+---------+-----------+
| "user1" | "ADMIN" |
+---------+-----------+展示图空间
SHOW SPACES;
显示用户信息。
SHOW USERS;
FIND PATH
FIND PATH语句查找指定起始点和目的点之间的路径。
用户可在配置文件nebula-graphd.conf中添加num_operator_threads参数提高FIND PATH的查询性能。num_operator_threads的取值为2~10,该值不能超过 Graph 服务所在机器的 CPU 核心个数,建议设置为 Graph 服务所在机器的 CPU 核心个数.
FIND { SHORTEST | ALL | NOLOOP } PATH [WITH PROP] FROM <vertex_id_list> TO <vertex_id_list>
OVER <edge_type_list> [REVERSELY | BIDIRECT]
[<WHERE clause>] [UPTO <N> {STEP|STEPS}]
YIELD path as <alias>
[| ORDER BY $-.path] [| LIMIT <M>];<vertex_id_list> ::=[vertex_id [, vertex_id] ...]
官方代码(查找各种路径)
返回的路径格式类似于(<vertex_id>)-[:<edge_type_name>@]->(<vertex_id)。
# 查找并返回带属性值的 team204 到 player100 的最短反向路径。
nebula> FIND SHORTEST PATH WITH PROP FROM "team204" TO "player100" OVER * REVERSELY YIELD path AS p;
+--------------------------------------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------------------------------------+
| <("team204" :team{name: "Spurs"})<-[:serve@0 {end_year: 2016, start_year: 1997}]-("player100" :player{age: 42, name: "Tim Duncan"})> |
+--------------------------------------------------------------------------------------------------------------------------------------+# 查找并返回起点为 player100,player130 而终点为 player132,player133 的 18 跳之内双向最短路径。
nebula> FIND SHORTEST PATH FROM "player100", "player130" TO "player132", "player133" OVER * BIDIRECT UPTO 18 STEPS YIELD path as p;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| p |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| <("player100")<-[:follow@0 {}]-("player144")<-[:follow@0 {}]-("player133")> |
| <("player100")-[:serve@0 {}]->("team204")<-[:serve@0 {}]-("player138")-[:serve@0 {}]->("team225")<-[:serve@0 {}]-("player132")> |
| <("player130")-[:serve@0 {}]->("team219")<-[:serve@0 {}]-("player112")-[:serve@0 {}]->("team204")<-[:serve@0 {}]-("player114")<-[:follow@0 {}]-("player133")> |
| <("player130")-[:serve@0 {}]->("team219")<-[:serve@0 {}]-("player109")-[:serve@0 {}]->("team204")<-[:serve@0 {}]-("player114")<-[:follow@0 {}]-("player133")> |
| <("player130")-[:serve@0 {}]->("team219")<-[:serve@0 {}]-("player104")-[:serve@20182019 {}]->("team204")<-[:serve@0 {}]-("player114")<-[:follow@0 {}]-("player133")> |
| ... |
| <("player130")-[:serve@0 {}]->("team219")<-[:serve@0 {}]-("player112")-[:serve@0 {}]->("team204")<-[:serve@0 {}]-("player138")-[:serve@0 {}]->("team225")<-[:serve@0 {}]-("player132")> |
| <("player130")-[:serve@0 {}]->("team219")<-[:serve@0 {}]-("player109")-[:serve@0 {}]->("team204")<-[:serve@0 {}]-("player138")-[:serve@0 {}]->("team225")<-[:serve@0 {}]-("player132")> |
| ... |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+# 查找所有从 player100 到 team204 无环路径。
nebula> FIND NOLOOP PATH FROM "player100" TO "team204" OVER * YIELD path AS p;
+--------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------+
| <("player100")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:serve@0 {}]->("team204")> |
| ... |
+--------------------------------------------------------------------------------------------------------+GET SUBGRAPH
GET SUBGRAPH语句查询并返回一个通过从指定点出发对图进行游走而生成的子图。在GET SUBGRAPH语句中,用户可以指定游走的步数以及游走所经过的边的类型或方向。
GET SUBGRAPH [WITH PROP] [<step_count> {STEP|STEPS}] FROM {<vid>, <vid>...}
[{IN | OUT | BOTH} <edge_type>, <edge_type>...]
[WHERE <expression> [AND <expression> ...]]
YIELD [VERTICES AS <vertex_alias>] [, EDGES AS <edge_alias>];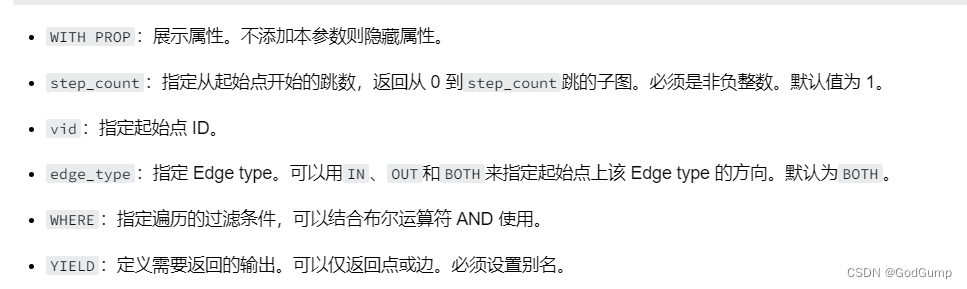
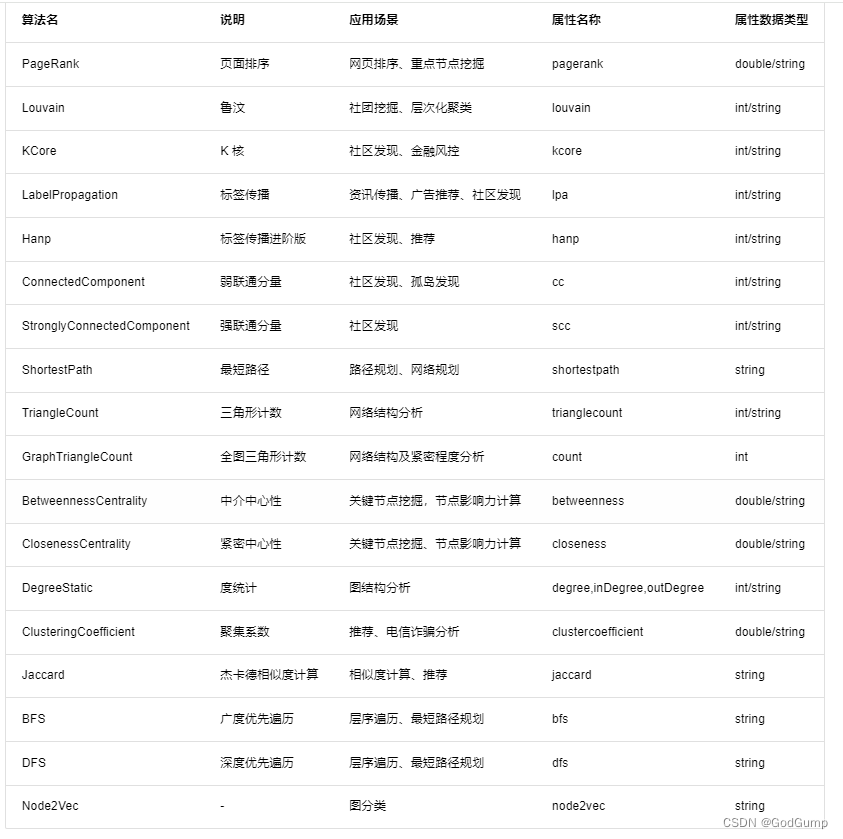
图计算
该图数据库目前支持的算法
这篇关于NebulaGraph基础(默认看了入门篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






